【PyTorch实战演练】基于AlexNet的预训练模型介绍
?
文章目录
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文基于AlexNet的训练实例说明PyTorch框架中预训练模型的作用和使用方法。
如果对AlexNet不太熟悉,建议先看下【PyTorch实战演练】AlexNet网络模型构建并使用Cifar10数据集进行批量训练(附代码)了解AlexNet的网络结构。
1. 预训练介绍
1.1 预训练模型是什么?
预训练模型是一种深度学习方法,它首先在大量数据上进行预训练,以学习通用特征,然后在特定任务上进行微调。这种方法通常用于自然语言处理(NLP)和计算机视觉等领域。
预训练模型的核心理念是迁移学习(transfer learning)。通过在大量数据上预先训练一个模型,该模型能够学习到一些通用的特征表示,如边缘、颜色、纹理等,这些特征对于许多不同的视觉任务都是有用的。
1.2 预训练的好处是什么?
深度学习在图像分类、语音识别、自然语言处理等领域取得了巨大的成功。然而,从头开始训练一个深度神经网络需要大量的数据和计算资源。幸运的是,许多研究人员已经发布了他们的模型及其在大规模数据集上的预训练权重,这些权重可以作为初始化权重来帮助我们快速地训练自己的模型。预训练具有以下几个优点:
- 减少训练样本:预训练权重可以帮助我们在相对较小的数据集上更快地收敛,因为它们已经学习到了很多通用特征。
- 提高准确性:由于预训练权重已经在大规模数据集上进行了学习,因此它们往往比随机初始化的权重更能捕获有用的模式。
- 减少过拟合:预训练权重可以作为一个正则化机制,有助于防止模型过度拟合到训练数据中。
举一个简单的类比,如果我们需要一个特定专业领域的博士生,那以前的做法就是从幼儿园开始从零培养,费时费力。现在有了预训练后,社会已经标准化地帮我们培养了高中毕业生,这部分毕业生具有各行各业的通用基本知识,我们要做的就是后面的专业化培养,获得我们需求的特定领域博士生。
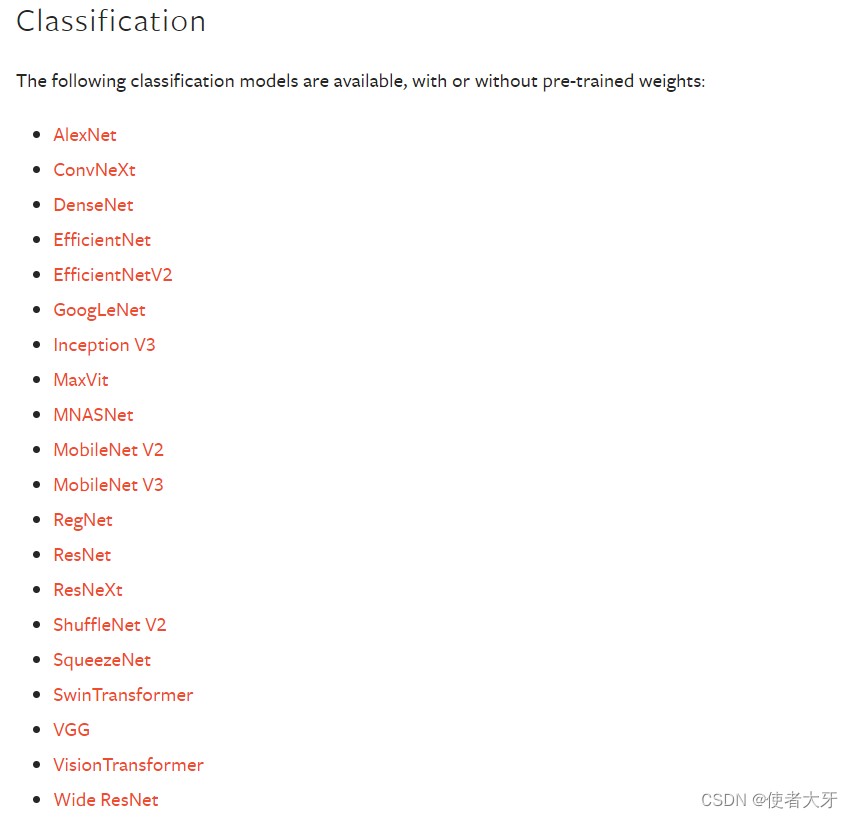
1.3 PyTorch库封装的模型及预训练权重
PyTorch在torchvision.models中提供了下列封装好的常用深度学习模型,以及部分模型的预训练权重:PyTorch官网链接
下面讲解AlexNet预训练模型的使用实例。
2. hymenoptera数据集
本实例使用hymenoptera数据集训练已经导入预训练权重的AlexNet网络模型。
hymenoptera数据集是ImageNet的一个小子集,只有’ants’和’bees’两个分类子集:
hymenoptera_dataset/
├── train #训练组
│ ├── ants #124张图像
│ └── bees #121张图像
└── val #验证组
├── ants #70张图像
└── bees #83张图像
下图是hymenoptera数据示例:hymenoptera_dataset/train/ants

3. 加载预训练的AlexNet模型
首先在代码中导入所需的库:
import torch
import torchvision.models as models
然后使用torchvision.models.alexnet函数加载预训练的AlexNet模型,设置pretrained=True以加载预训练权重:
AlexNet = models.alexnet(pretrained=True)
预训练权重文件(alexnet-owt-7be5be79.pth)会自动下载到cache中,十分建议把它拷出来放到指定路径下面,这样就不用每次都重复下载。

这样,AlexNet就包含了预训练权重。
4. 修改模型以适应新的任务
这一步是对已有模型(AlexNet)进行个性化改制,目的是解决新的训练任务(hymenoptera数据集,2分类任务)与原始的预训练任务(ImageNet数据集,1000分类任务)不同的问题。
在使用hymenoptera数据集训练时,最终输出只有2个类别。这里介绍两种方法改造AlexNet,第一种方法是直接改造AlexNet的结构:
import torchvision
import torch
AlexNet = torchvision.models.alexnet(pretrained=True)
AlexNet = torchvision.models.alexnet()
# 获取最后一个全连接层(fc)的输入维度,即4096
num_features = AlexNet.classifier[6].in_features
# 更改AlexNet,将最后的全连接层替换为一个新的线性层,输出维度为2
AlexNet.classifier[6] = torch.nn.Linear(num_features, 2)
print(AlexNet)
这一步将使绝大部分预训练权重保持不变,只改变最后一层的权重,并允许我们用新数据重新训练这部分权重。打印出网络结构可以看出最终输出的特征向量长度已经变为2。
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=2, bias=True) #AlexNet原本的out_features是1000,这里已经调整为2
)
)
我们也可以用第二种方法:在AlexNet后面再加一层全连接层。AlexNet网络模型最终输出是一个长度为1000的向量。在此实例中我们只需要输出一个长度为2的向量代表判断为’ants’和’bees’分类的置信度,这样我们就可以在AlexNet后面再加一个全连接层,转换最终输出的向量长度。
class base_alexnet(torch.nn.Module):
def __init__(self):
super(base_alexnet, self).__init__()
self.model = torch.nn.Sequential(
AlexNet,
torch.nn.Linear(in_features=1000, out_features=2), #增加一个全连接层,转换最终输出向量的长度
torch.nn.Softmax() #再加一层softmax,把输出转为判断分类的置信度
)
def forward(self,x):
return self.model(x)
在此实例中,我选用第二种方法来修改模型,因为所有教程都是选用的第一种方法,我们可以探索下第二种方法的实际效果。
5. 训练模型
现在我们可以像对待任何其他PyTorch模型一样训练这个已经导入预训练权重的模型:定义损失函数、优化器并编写训练循环来学习权重。
AlexNetBased = base_alexnet().cuda()
criterion = torch.nn.CrossEntropyLoss() #交叉熵损失函数
AlexNetBased.train() #别忘了进入训练模式!
epoch = 700
initial_lr =1e-8
opt = torch.optim.Adam(AlexNetBased.parameters(),lr=initial_lr)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt, T_max=50, last_epoch=-1) #使用余弦退火学习率调整方法
if __name__ == '__main__':
for e in tqdm(range(epoch)):
opt.zero_grad()
acc_count = 0 #判断正确计数
total_loss = 0 #每个epoch的总loss
for iter in range(len(datasets_train)):
input= datasets_train[iter][0].unsqueeze(0).cuda() #训练输入图像数据传入cuda
output = AlexNetBased(input).cuda()
label = torch.tensor([datasets_train[iter][1]]).cuda() #训练标签传入cuda
loss = criterion(output, label).cuda() #计算loss
total_loss = loss + total_loss
if torch.argmax(output) == datasets_train[iter][1]: #判断输出是否正确
acc_count = acc_count +1
loss.backward()
opt.step()
scheduler.step()
acc = acc_count/len(datasets_train)
print('epoch%i---loss%f---acc%f'%(e,total_loss,acc))
total_loss = total_loss.detach().cpu()
plt.scatter(e,total_loss,s=2,c='r')
plt.scatter(e,acc,s=2,c='b')
plt.show()
torch.save(AlexNetBased.state_dict(), 'weight/epoch=7--initial_lr=1e-8.pth') #保存训练好的权重
这里需要注意在训练前需要调用 .train()方法进入训练模式!
在PyTorch中,.train()和.eval()方法用于控制模型的训练和评估模式。这些方法主要影响两个关键操作:批量归一化(Batch Normalization)和丢弃层(Dropout)。这两种层在训练和测试阶段的行为是不同的。
.train()方法:当调用.train()时,模型进入训练模式。
- 在训练模式下,批量归一化层会使用当前批次数据的均值和方差来标准化输入,从而使网络对输入数据的分布变化更加鲁棒。
- 丢弃层在训练模式下会随机关闭一部分神经元,以减少过拟合的风险。
.eval()方法:当调用.eval()时,模型进入评估模式。
- 在评估模式下,批量归一化层会使用整个训练集数据的均值和方差来标准化输入,这样在整个评估过程中保持了固定的统计量。
- 丢弃层在评估模式下不会关闭任何神经元,所有的权重都会被保留并参与前向传播。
6. 结果解析
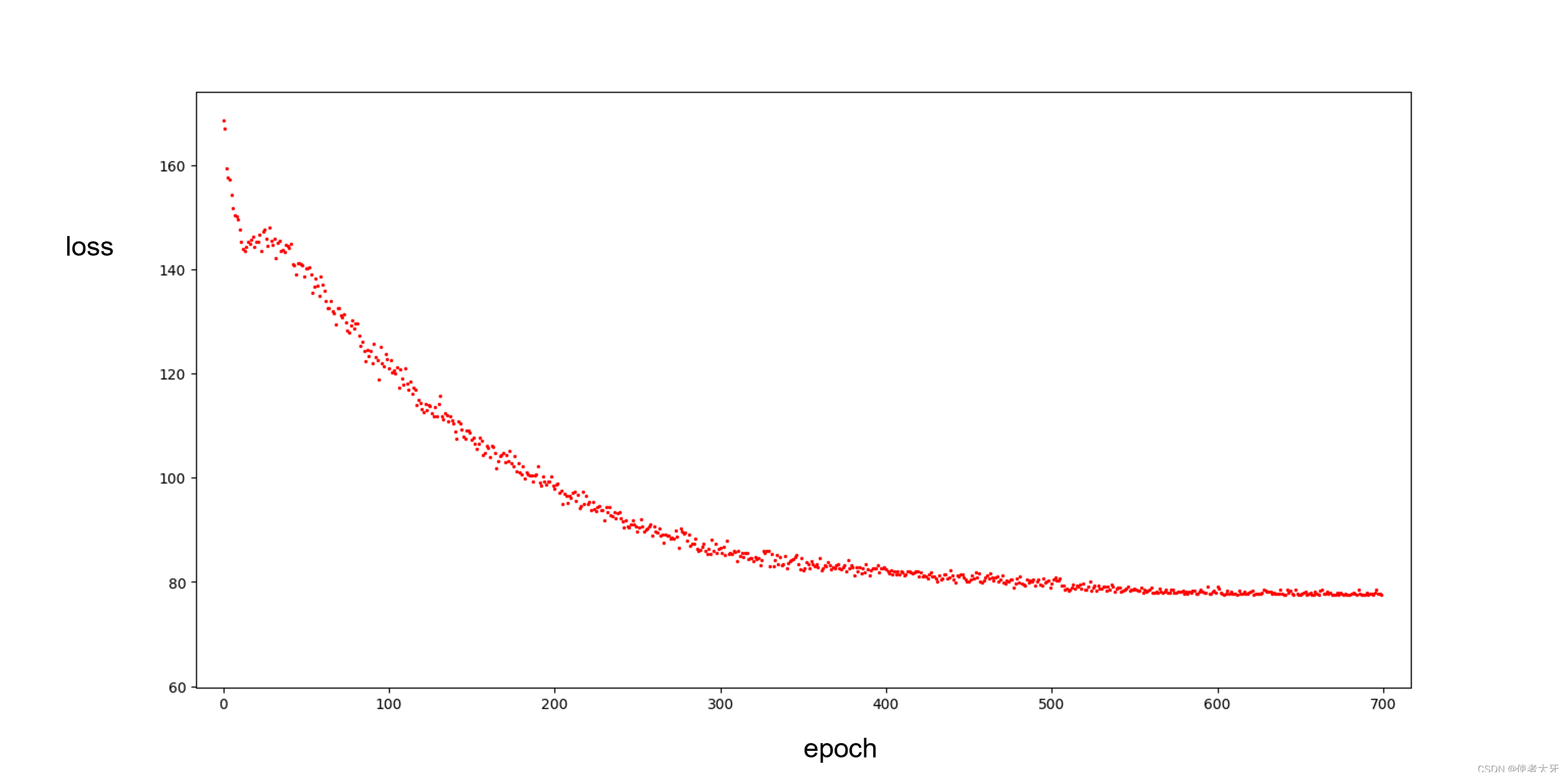
6.1 训练过程
随着迭代次数epoch增加,训练损失loss逐渐收敛:
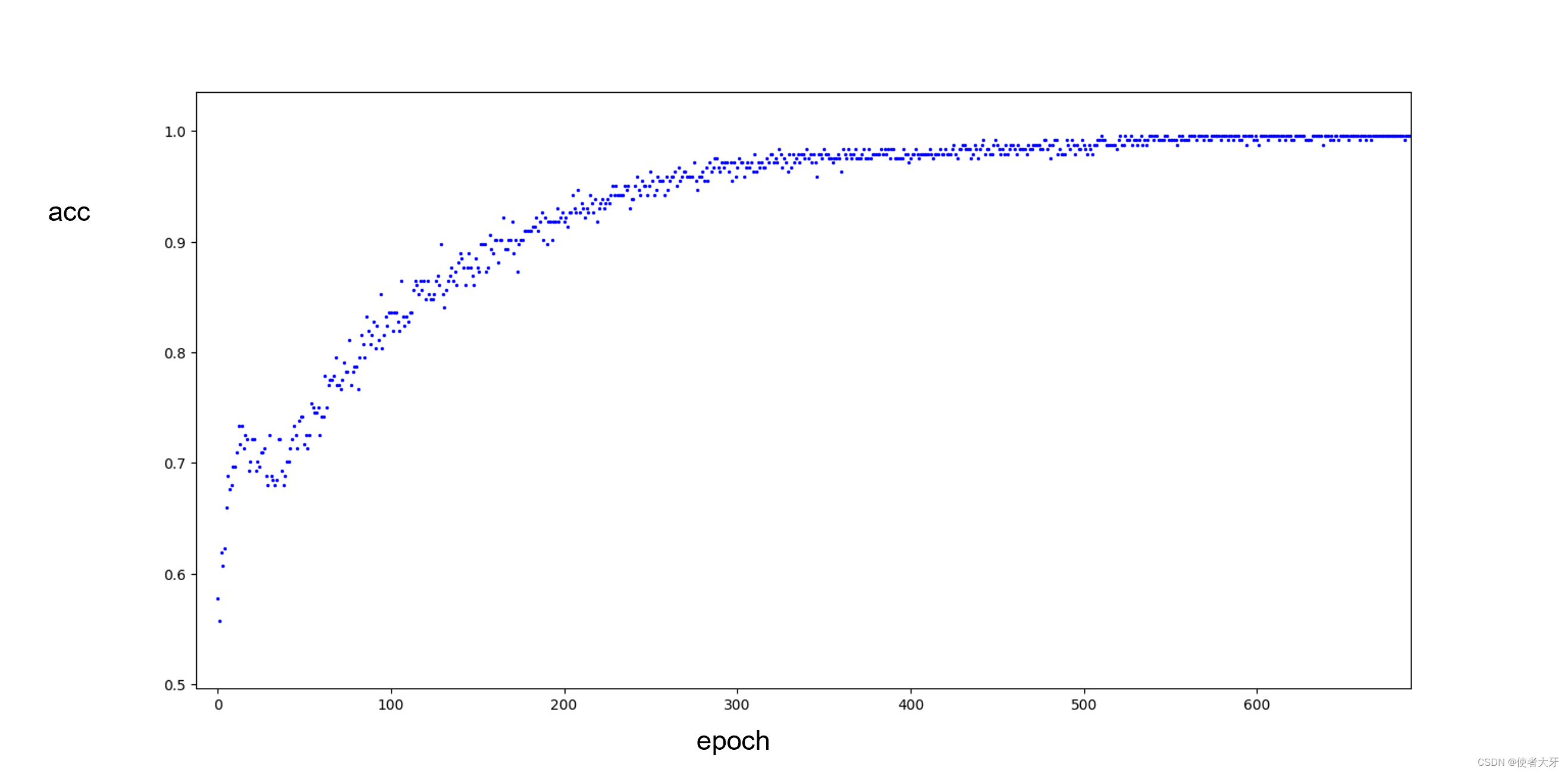
训练精度逐渐提升,接近于1:
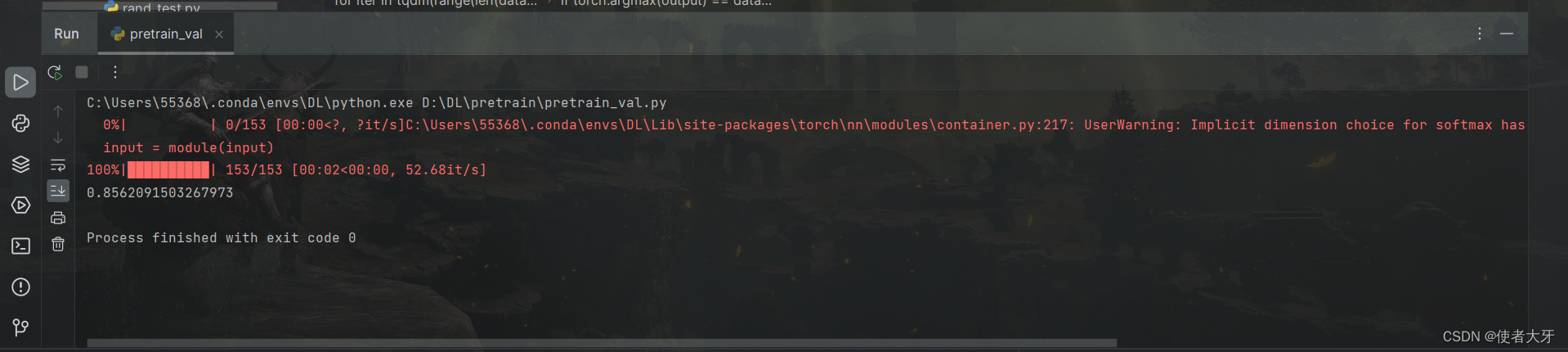
6.2 使用验证组数据验证模型精度
使用训练好的AlexNet网络对hymenoptera数据集验证组数据进行验证得到验证精度为85.6%
总结:通过使用PyTorch提供的预训练AlexNet权重,我们可以大大加快训练速度并提高模型性能。此外,通过适当修改模型的最后一层,我们可以轻松地将预训练模型应用于各种不同的问题。
7. 完整代码
7.2 训练组代码
import torch
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
from tqdm import tqdm
AlexNet = torchvision.models.alexnet()
AlexNet.load_state_dict(torch.load('alexnet-owt-7be5be79.pth'))
class base_alexnet(torch.nn.Module):
def __init__(self):
super(base_alexnet, self).__init__()
self.model = torch.nn.Sequential(
AlexNet,
torch.nn.Linear(in_features=1000, out_features=2),
torch.nn.Softmax()
)
def forward(self,x):
return self.model(x)
img_transforms = transforms.Compose([transforms.Resize(224),transforms.ToTensor()])
img_train = 'hymenoptera/hymenoptera_data/train'
img_val = 'hymenoptera/hymenoptera_data/val'
datasets_train = torchvision.datasets.ImageFolder(root=img_train,transform=img_transforms)
datasets_val = torchvision.datasets.ImageFolder(root=img_val,transform=img_transforms)
#验证ImageFolder
# print(datasets_train[200][1])
# img = datasets_train[200][0].permute(1,2,0)
# plt.imshow(img)
# plt.show()
AlexNetBased = base_alexnet().cuda()
criterion = torch.nn.CrossEntropyLoss()
AlexNetBased.train()
epoch = 700
initial_lr =1e-8
opt = torch.optim.Adam(AlexNetBased.parameters(),lr=initial_lr)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer=opt, T_max=50, last_epoch=-1) #使用余弦退火学习率调整方法
if __name__ == '__main__':
for e in tqdm(range(epoch)):
opt.zero_grad()
acc_count = 0 #判断正确计数
total_loss = 0 #每个epoch的总loss
for iter in range(len(datasets_train)):
input= datasets_train[iter][0].unsqueeze(0).cuda() #训练输入图像数据传入cuda
output = AlexNetBased(input).cuda() #在cuda中计算输出
label = torch.tensor([datasets_train[iter][1]]).cuda() #训练标签传入cuda
loss = criterion(output, label).cuda() #计算loss
total_loss = loss + total_loss
if torch.argmax(output) == datasets_train[iter][1]: #判断输出是否正确
acc_count = acc_count +1 #对判断正确的结果进行累加计数
loss.backward()
opt.step()
acc = acc_count/len(datasets_train)
print('epoch%i---loss%f---acc%f'%(e,total_loss,acc))
total_loss = total_loss.detach().cpu()
plt.scatter(e,total_loss,s=2,c='r')
plt.scatter(e,acc,s=2,c='b')
plt.show()
torch.save(AlexNetBased.state_dict(), 'weight/epoch=7--initial_lr=1e-8.pth') #保存训练好的权重
7.1 验证组代码
from pretrain_main import base_alexnet
import torch
from torchvision import transforms
import torchvision
from tqdm import tqdm
AlexNetBased = base_alexnet().cuda()
AlexNetBased.load_state_dict(torch.load('weight/epoch=700--initial_lr=1e-8.pth'))
img_transforms = transforms.Compose([transforms.Resize(224),transforms.ToTensor()])
img_val = 'hymenoptera/hymenoptera_data/val'
datasets_val = torchvision.datasets.ImageFolder(root=img_val,transform=img_transforms)
AlexNetBased.eval() #别忘了进入评估模式!!
acc_count = 0
for iter in tqdm(range(len(datasets_val))):
input = datasets_val[iter][0].unsqueeze(0).cuda()
output = AlexNetBased(input).cuda()
label = torch.tensor([datasets_val[iter][1]])
if torch.argmax(output) == datasets_val[iter][1]:
acc_count = acc_count + 1
acc = acc_count/len(datasets_val)
print(acc)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!