LLM源码系列-Baichuan2模型代码解读
2023-12-29 12:46:15
本文是对百川大模型的代码解析,有助于了解其内部模型结构,以及训练和推理的一些细节。
主要是对 modeling_baichuan.py 这个文件进行分析,以下是核心的几个类的关系
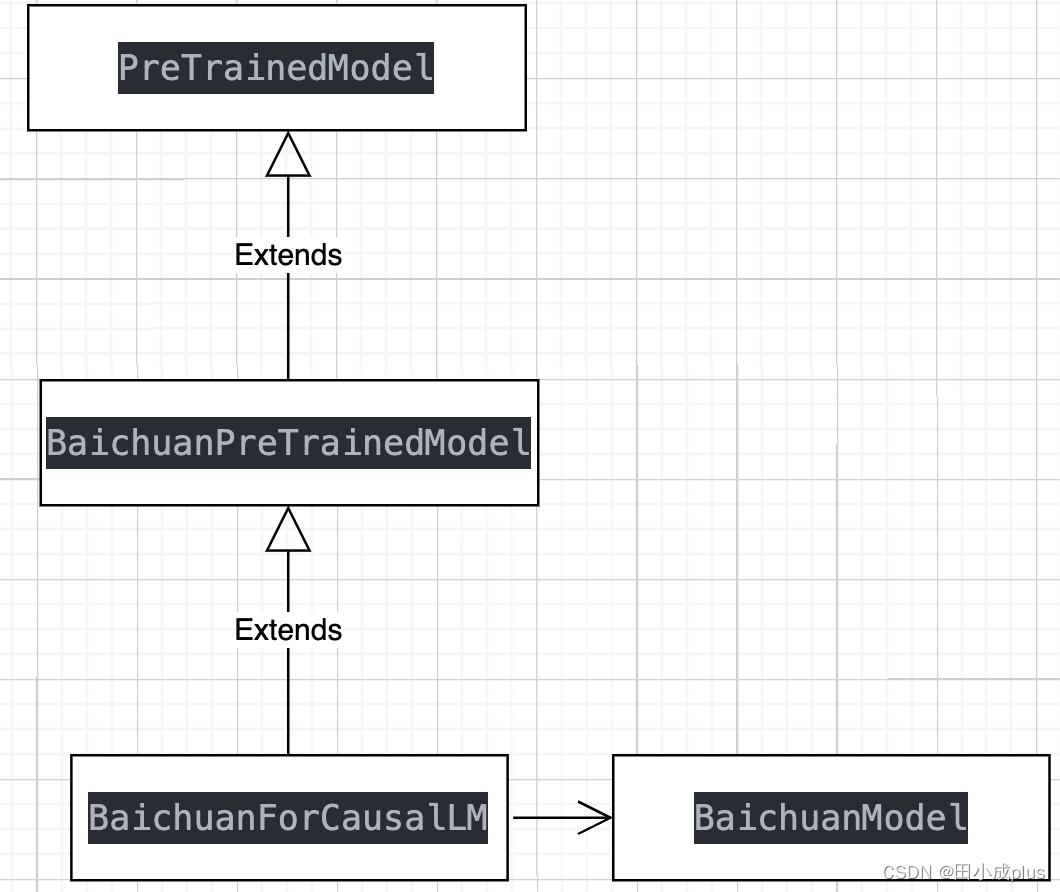
核心的模型结构在 BaichuanModel 中,是多个 MHA多头Attention模块堆叠起来的 Decoder架构,下面是 BaichuanModel的代码解析
class BaichuanModel(BaichuanPreTrainedModel):
def __init__(self, config: BaichuanConfig):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.n_head = config.num_attention_heads
self.embed_tokens = torch.nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
# 40个 block,每个block都是一样的结构,对应的模型类是 BaichuanLayer
self.layers = torch.nn.ModuleList([BaichuanLayer(config) for _ in range(config.num_hidden_layers)])
self.norm = RMSNorm(config.hidden_size, epsilon=config.rms_norm_eps)
self.gradient_checkpointing = config.gradient_checkpointing
self.post_init()
self.max_cache_pos = config.model_max_length
self.first_run = True
self.alibi_mask = None
def get_input_embeddings(self):
return self.embed_tokens
def set_input_embeddings(self, value):
self.embed_tokens = value
def get_alibi_mask(self, tensor, seq_length_with_past):
if self.training:
slopes = torch.Tensor(_get_interleave(self.n_head))
position_point = torch.arange(seq_length_with_past) - seq_length_with_past + 1
position_point = position_point.unsqueeze(0).unsqueeze(0).expand(self.n_head, seq_length_with_past, -1)
diag = torch.diag(position_point[0])
position_point = position_point - diag.unsqueeze(0).unsqueeze(0).transpose(-1, -2)
alibi = slopes.unsqueeze(1).unsqueeze(1) * position_point
mask = _buffered_future_mask(tensor, seq_length_with_past, alibi, self.n_head)
else:
if self.first_run:
self.first_run = False
self.register_buffer(
"future_mask",
_gen_alibi_mask(tensor, self.n_head, self.max_cache_pos).to(tensor),
persistent=False,
)
if seq_length_with_past > self.max_cache_pos:
self.max_cache_pos = seq_length_with_past
self.register_buffer(
"future_mask",
_gen_alibi_mask(tensor, self.n_head, self.max_cache_pos).to(tensor),
persistent=False,
)
mask = self.future_mask[: self.n_head, :seq_length_with_past, :seq_length_with_past]
return mask
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
output_hidden_states: Optional[bool] = False,
return_dict: Optional[bool] = True,
) -> Union[Tuple, BaseModelOutputWithPast]:
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot provide both input_ids and inputs_embeds simultaneously")
elif input_ids is not None:
# input_id 是每个序列的 token_id, shape=[bs, seqlen]
batch_size, seq_length = input_ids.shape
elif inputs_embeds is not None:
# input_embeds 是每个序列的token对应的 word embedding,shape=[bs, seqlen, emb_dim]
batch_size, seq_length, _ = inputs_embeds.shape
else:
raise ValueError("You need to provide input_ids or inputs_embeds")
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
seq_length_with_past = seq_length
if past_key_values is not None:
"""past_key_values是每个时刻都会缓存当前时刻计算出的 K和 V,再和之前时刻记录的 KV 拼到一起
一个attention的K 的shape是 [bs, num_heads, seqlen, dmodel], 整个模型有多个Attention层,
多个Attention层的K 拼在一起是 [attention_layers, bs, num_heads, decoded_seqlen, dmodel]
past_key_values[0][0]的shape是 [num_heads, decoded_seqlen, dmodel], 所以 shape[2]就是已经解码出的序列的长度(生成了多少个token)
"""
past_key_values_length = past_key_values[0][0].shape[2]
# source句子的长度+已解码的序列的长度,比如source=【中国有多少个民族?】,已生成【汉族】
# 那么seq_length_with_past 就是 【中国有多少个民族?汉族】的token长度
seq_length_with_past = seq_length_with_past + past_key_values_length
if inputs_embeds is None: # input_embeds是空,调用 Embedding层进行生成,[bs, seqlen] -> [bs, seqlen, dmodel]
inputs_embeds = self.embed_tokens(input_ids)
if self.training:
if self.alibi_mask is None or self.alibi_mask.shape[-1] != seq_length_with_past:
self.alibi_mask = self.get_alibi_mask(inputs_embeds, seq_length_with_past)
alibi_mask = self.alibi_mask
else:
alibi_mask = self.get_alibi_mask(inputs_embeds, seq_length_with_past)
if attention_mask is not None:
if len(attention_mask.shape) == 2:
expanded_mask = attention_mask.to(alibi_mask.dtype)
expanded_mask = torch.tril(
torch.gt(expanded_mask[:, :, None] * expanded_mask[:, None, :], 0)
) * torch.eq(expanded_mask[:, :, None] - expanded_mask[:, None, :], 0)
else:
expanded_mask = attention_mask
bsz = inputs_embeds.size(0) # batch_size
src_len, tgt_len = alibi_mask.size()[-2:]
expanded_mask = expanded_mask.unsqueeze(1).expand(bsz, 1, src_len, tgt_len).to(alibi_mask.dtype)
inverted_mask = 1.0 - expanded_mask
inverted_mask = inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(alibi_mask.dtype).min)
attention_mask = inverted_mask + alibi_mask.unsqueeze(0)
else:
attention_mask = alibi_mask
hidden_states = inputs_embeds # input_embeds是整个模型结构的输入
# gradient_checkpointing=False
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
# decoder layers
all_hidden_states = () if output_hidden_states else None # 是否输出隐藏层状态
all_self_attns = () if output_attentions else None # 是否输出Attention层结果,返回是一个list
next_decoder_cache = () if use_cache else None
# self.layers是 多个 decoder block的顺序堆叠,每个block都是一模一样的结构
for idx, decoder_layer in enumerate(self.layers):
if output_hidden_states:
# all_hidden_states= [input_embeds, block1_output, block2_output, ...]
# 每个元素都是 shape=[bs, seqlen, dmodel]的 tensor
all_hidden_states += (hidden_states,)
# 当前是 第 idx个block,每个block有一个Attention层,这里取出当前这个block 在上一时刻的 K,V
# 注意两个维度: 水平的时间维度 t,垂直的模型维度 block_i,对于时刻 t 来说,每个block_i都需要 过去的 [0,t)时刻的 K,V,因为要和过去的source句子+已生成的tokens 计算Attention
# past_key_value.sahpe = [bs, num_heads, decoded_length, dmodel], decoded_length就是时刻t,每个时刻生成一个token
past_key_value = past_key_values[idx] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
return module(*inputs, output_attentions, None)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(decoder_layer),
hidden_states,
attention_mask,
None,
)
else:
# 当前 block进行前向计算, outputs是 tuple (hidden_output, past_key_values)
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
# 输出是 tuple,取出0位置的 output,表示当前block最终的输出,shape=[bs, seqlen, dmodel]
hidden_states = layer_outputs[0]
# 配置中 use_cache=True,cache是指缓存当前层计算出来的 Attention的 K,V
# output_attention 是指返回每层block中 Attention的输出,即 和 V矩阵相乘后的 attention_score
# output_attention=True, 返回 [layer_output, past_key_values, attn_output], false返回 [layer_output, past_key_values]
if use_cache:
# 这里应该有bug,layer_outputs最多2个元素,不可能取到 2的index
# next_decoder_cache就是下个时刻Attention要用到的 past_key_value
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
if output_attentions:
all_self_attns += (layer_outputs[1],)
hidden_states = self.norm(hidden_states) # 最后一个block的输出再进行 norm,这里用的 是 RMSNorm ,和LLama的一样
# add hidden states from the last decoder layer
if output_hidden_states: # 记录每个 block的最后输出
all_hidden_states += (hidden_states,)
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states, # [batch_size, seqlen, dmodel]
past_key_values=next_cache, # tuple of tuple, 外面的tuple的长度是 n_blocks,里面的tuple是每个block中的 (k,v),k和v的shape都是 [batch, n_heads, seqlen, head_dim]
hidden_states=all_hidden_states, # tuple结构, 长度是 n_blocks+1,记录每个block的输出,+1是因为最开始添加的是 input_embeds,shape都是 [b,seqlen, dmodel]
attentions=all_self_attns, # tuple结构,长度是 n_blocks,记录每个block内Attention的结果,shape都是 [batch, n_heads, seqlen, seqlen]
)
BaichuanModel 是由 40个 BaichuanLayer的 Block堆叠起来的,下面是 BaichuanLayer的代码
class BaichuanLayer(torch.nn.Module):
def __init__(self, config: BaichuanConfig):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = BaichuanAttention(config=config)
self.mlp = MLP(
hidden_size=self.hidden_size,
intermediate_size=config.intermediate_size,
hidden_act=config.hidden_act,
)
self.input_layernorm = RMSNorm(config.hidden_size, epsilon=config.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(config.hidden_size, epsilon=config.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = False,
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
residual = hidden_states # 当前block的输入,来自上一个block的输出,对于第一个block就是 input_embeds,这里先记录一下 是为了后面算残差
hidden_states = self.input_layernorm(hidden_states)
# Self Attention,block内的核心 attention模块
# 返回 attn_output, attn_weight, past_key_value,past_kv是合并后的 KV
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
# 残差连接,attention输出+ block输入,shape=[bs, seqlen, dmodel]
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
# layernorm归一化
hidden_states = self.post_attention_layernorm(hidden_states)
# mlp
hidden_states = self.mlp(hidden_states)
# mlp后又来一个残差,上面的残差是连接的 attn_output
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if use_cache: # 推理配置中 use_cache=True,表示缓存当前block中Attention过程的K,V
outputs += (present_key_value,)
return outputs
每个BaichuanLayer的核心是 Attention模块和 MLP模块,下面是 BiachuanAttention这个类
class BaichuanAttention(torch.nn.Module):
def __init__(self, config: BaichuanConfig):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size # 5120
self.num_heads = config.num_attention_heads # 40
self.head_dim = self.hidden_size // self.num_heads # 128,每个head的维度是 128
self.max_position_embeddings = config.model_max_length # 4096,最长4096个token
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(f"hidden_size {self.hidden_size} is not divisible by num_heads {self.num_heads}")
# [hs, 3*hs],W_pack是 QKV三个矩阵的初始化,所以是 3*hs
self.W_pack = torch.nn.Linear(self.hidden_size, 3 * self.hidden_size, bias=False)
# output, attention的结果再过一个 线性映射, attention_outptu=最后多个head头的结果拼起来,shape=[batch, seqlen, dmodel], dmodel=hidden_size=head_dim * n_heads
# 输出层映射: [batch ,seqlen, dmodel] -> [batch, seqlen, dmodel]
self.o_proj = torch.nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size() # [batch, seqlen, dmodel]
# [b, selqen, dmodel] -> [b, seqlen, dmodel * 3], 输入特征 -> 经过一个大的 W_pack的线性映射 -> 分离出 三个同样大小的 QKV矩阵
proj = self.W_pack(hidden_states)
# unflatten: 在最后一个轴上展开,展开后的shape [b, seqlen, dmodel * 3] -> [b, seqlen, 3, dmodel]
# unsqueeze: [b, seqlen, 3, dmodel] -> [1, b, seqlen, 3, dmodel],这个操作感觉多余了。。
# transpose: 0和-2的size交换一下,[1, b, seqlen, 3, dmodel] -> [3, b, seqlen, 1, dmodel],意思就是拆分成三个一样大小的矩阵
# squeeze(-2): [3, b, seqlen, 1, dmodel] -> [3, b, seqlen,dmodel]
proj = proj.unflatten(-1, (3, self.hidden_size)).unsqueeze(0).transpose(0, -2).squeeze(-2)
# proj[0] = Q, proj[1] =K, proj[2] = V,之所以用一个大的 Pack矩阵是加快计算速度
# proj[0]=Q: 拆成多个head, [b, seqlen, dmodel] -> [b, seqlen, n_heads, head_dim] -> [b, n_heads, seqlen, head_dim]
# n_heads个 子Q矩阵,每个小Q 的shape都是 [b, seqlen, head_dim],所以要 transpose(1, 2)
query_states = proj[0].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# proj[1]=K: 拆成多个head, [b, seqlen, dmodel] -> [b, seqlen, n_heads, head_dim] -> [b, n_heads, seqlen, head_dim]
key_states = proj[1].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# proj[2]=V: 拆成多个head, [b, seqlen, dmodel] -> [b, seqlen, n_heads, head_dim] -> [b, n_heads, seqlen, head_dim]
value_states = proj[2].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# 这个 kv_seq_len 是指当前输入序列的 length,推理时的初始时候 seqlen=【prompt+query】,后面时刻的输入就是上一个时刻的输出token, seqlen就是1
kv_seq_len = key_states.shape[-2] # seqlen,代表当前
# past_key_value是 tuple of tuple,记录每个block层的 (k, v)
# past_key_value非空 说明不是初始时刻,那么当前的 KV 中的 seqlen=1,计算注意力时要能看到之前每个token的信息才能捕捉全局上下文,进行更好的生成
# 假设当前时刻是 t,t时刻的输入是t-1时刻的输出 token, past_key_value=(past_k, past_v), 每个past的shape都是 [bs, n_heads, past_seqlen, head_dim]
if past_key_value is not None:
# 当前输入的seqlen, 加上过去已知序列的seqlen
kv_seq_len += past_key_value[0].shape[-2]
if past_key_value is not None:
# reuse k, v, self_attention
# 当前时刻的输入,算出来的 K 和上个时刻汇总后的 k 进行合并, dim=2是序列长度的那一维,合并后的k,表示当前时刻的预测能看到的所有token注意力
key_states = torch.cat([past_key_value[0], key_states], dim=2)
# 当前时刻的输入,算出来的 V 和上个时刻汇总后的 v 进行合并, dim=2是序列长度的那一维,合并后的k,表示当前时刻的预测能看到的所有token注意力
value_states = torch.cat([past_key_value[1], value_states], dim=2)
# use_cache=True,则记录当前block内Attention计算的 K矩阵和V矩阵,以tuple形式存储 , (k, v), shape都是[bs, n_heads, seqlen, head_dim]
# 这时的 key_states, value_states 是【prompt+问题+已生成token】的全部注意力
past_key_value = (key_states, value_states) if use_cache else None
if xops is not None and self.training:
attn_weights = None
# query_states = query_states.transpose(1, 2)
# key_states = key_states.transpose(1, 2)
# value_states = value_states.transpose(1, 2)
# attn_output = xops.memory_efficient_attention(
# query_states, key_states, value_states, attn_bias=attention_mask
# )
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=True, enable_mem_efficient=True):
attn_output = F.scaled_dot_product_attention(
query_states, key_states, value_states, attn_mask=attention_mask
)
attn_output = attn_output.transpose(1, 2)
else:
# shape=[bs, n_heads, seqlen, seqlen]
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attention_mask is not None:
if q_len == 1: # inference with cache,推理的自回归模式,且不是第一个时刻
if len(attention_mask.size()) == 4:
attention_mask = attention_mask[:, :, -1:, :]
else:
attention_mask = attention_mask[:, -1:, :]
# 加上 atten_mask,对应位置元素相加,需要mask的位置变成了 -inf
attn_weights = attn_weights + attention_mask
attn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))
# 最后一维进行 softmax
attn_weights = torch.nn.functional.softmax(attn_weights, dim=-1)
# attn_weight和 V矩阵相乘
attn_output = torch.matmul(attn_weights, value_states)
# [bs, n_heads, seqlen, dmodel] -> [bs, seqlen, n_heads, dmodel]
attn_output = attn_output.transpose(1, 2)
# [bs, n_heads, seqlen, head_dim] -> [bs, seqlen, n_heads * head_dim]
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
# attn_output再过一个线性映射 [bs, seqlen, dmodel] -> [bs, seqlen, dmdel]
attn_output = self.o_proj(attn_output)
if not output_attentions: # 输出 atten_weight,也就是 KV的乘积,注意力权重
attn_weights = None
return attn_output, attn_weights, past_key_value
Attention模块后面会接一个 MLP模块,百川的 MLP这里用了三个映射矩阵,进行先升维后降维
class MLP(torch.nn.Module):
def __init__(
self,
hidden_size: int,
intermediate_size: int,
hidden_act: str,
):
super().__init__()
self.gate_proj = torch.nn.Linear(hidden_size, intermediate_size, bias=False)
self.down_proj = torch.nn.Linear(intermediate_size, hidden_size, bias=False)
self.up_proj = torch.nn.Linear(hidden_size, intermediate_size, bias=False)
self.act_fn = ACT2FN[hidden_act]
def forward(self, x):
# [bs, seqlen, intermediate_size] * [bs, seqlen, intermediate_size] = [bs, seqlen, intermediate_size]
# return: [bs, seqlen, intermediate_size] -> [bs, seqlen, hidden_size]
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
拿到整个 BaichuanModel的输出后,shape是 [bs, seqlen, dmodel],还需要变换到 vocab_size这个空间,所以还需要接一个线性映射层,这部分代码在 BaichuanForCausalLM 中的 forward方法里,这里截取片段进行分析
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
# 返回 (model_output, past_key_values, hidden_state_list, attention_list)
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
# 线性映射 [bs, seqlen, dmodel] -> [bs, seqlen, vocab_size]
logits = self.lm_head(hidden_states)
loss = None
if labels is not None: # label非空是训练模式,需要计算loss
# Shift so that tokens < n predict n
# 这里计算 loss,每个token的 groud truth是右边挨着的 token,每个token计算一个交叉熵损失
shift_logits = logits[..., :-1, :].contiguous() # logit序列截取 [1,... n-1]
shift_labels = labels[..., 1:].contiguous() # label序列取 [2,... n]
# Flatten the tokens
loss_fct = CrossEntropyLoss()
shift_logits = shift_logits.view(-1, self.config.vocab_size)
shift_labels = shift_labels.view(-1)
softmax_normalizer = shift_logits.max(-1).values ** 2
z_loss = self.config.z_loss_weight * softmax_normalizer.mean()
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
loss = loss_fct(shift_logits, shift_labels) + z_loss
全部文件的详细分析,可以参考我的项目 llm-code-analysis
文章来源:https://blog.csdn.net/tiangcs/article/details/135286344
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!