DFA 算法实现敏感词过滤
2024-01-01 06:46:50
背景
项目中APP端发帖,评论可能包含多个关键词,铭感词。此时需要对该内容进行过滤处理。此前都是在客户端层面操作,这样不仅带来了性能的损耗,而且新增铭感词时,需要客户端重新打包上架,显得十分不合理。所以应该在服务端层面进行算法数据处理。
DFA 算法
DFA 全称为: Deterministic Finite Automaton, 即确定有穷自动机。其特征为:有一个有效状态的集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA 中不会有从同一个状态触发的两条边标志有相同的符号。
- 确定:状态以及引起状态转换的事件都是可确定的,不存在“意外”
- 有穷: 状态以及事件的数量都是可穷举的
DFA 算法模型如下:
state_event_dict = {
"匹": {
"配": {
"算": {
"法": {
"is_end": True
},
"is_end": False
},
"关": {
"键": {
"词": {
"is_end": True
},
"is_end": False
},
"is_end": False
},
"is_end": False
},
"is_end": False
},
"信": {
"息": {
"抽": {
"取": {
"is_end": True
},
"is_end": False
},
"is_end": False
},
"is_end": False
}
}
用通俗易懂的话来解释,就是将数据库中的铭感词进行建立树结构,举个例子,数据库的铭感词汇有三个,分别是:今天,今天很好,今天真烦
建立树结构,并且标记好三个词汇的非叶子节点和叶子节点 (即最后一个字符是非叶子节点),并且制定好匹配规则,只有碰到叶子节点才算一次过滤:
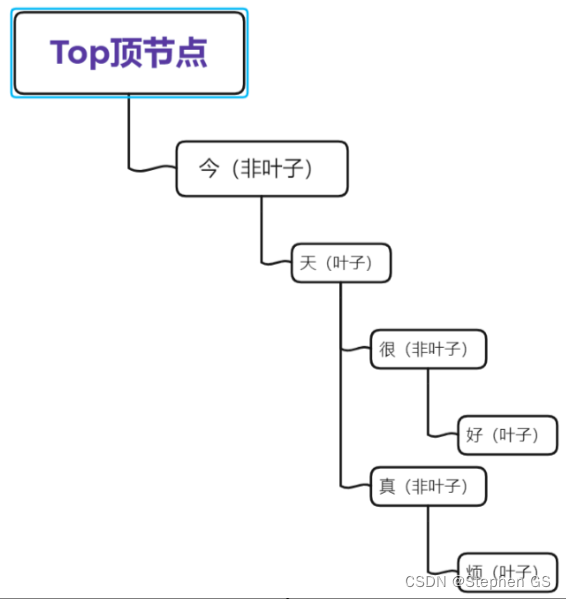
模拟用户输入以下一句话:
我觉得今天还行。
接下来我们将这句话逐个字拆分并将每一个字代入到上面的树状结构图中。
- 前面三个字不在铭感词树种直接可以跳过,直到遇到今这个字,发现匹配上铭感词树,接下来看树状结构发现只有一个字是天才能捕获。
- 再接着走发现在树结构中天这个字的下一个字只有匹配到很或者真才能继续匹配,
- 而用户输入的下一个字是还,第一步判断当前已经走到了叶子节点,故先将今天置为敏感词。
- 然后将还这个字从Top顶节点中重新继续流转,发现无法匹配。
- 过滤结束,且当前的节点是叶子节点,故这句话仅仅被[敏感词过滤]了今天这两个字,最终的过滤结果应该是:
我觉得**还行
要注意的是只有完整的碰到过一次叶子节点才算一次过滤,且一句话可以被多次过滤。以上就是针对DFA算法的简单说明。
简单使用
Hutool 工具类中通过WordTree 实现类DFA 算法,能构方便的做到开箱即用
这是源码中的一个简单介绍

import cn.hutool.dfa.WordTree;
public static void main(String[] args) {
WordTree wordTree = new WordTree();
wordTree.addWords("希望", "这是真的", "哈哈");
// 搜索出内容中名并输出
String text = "我希望你是最好的";
List<String> matchWords = wordTree.matchAll(text, -1, true, true);
System.out.println(matchWords); // [希望]
// 是否匹配上内容的铭感词,匹配上返回true
boolean match = wordTree.isMatch(text);
System.out.println(match); // true
}
文章来源:https://blog.csdn.net/TheWindOfSon/article/details/135294396
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!