在Pytorch中使用Tensorboard可视化训练过程
这篇是我对哔哩哔哩up主 @霹雳吧啦Wz 的视频的文字版学习笔记 感谢他对知识的分享
本节课我们来讲一下如何在pytouch当中去使用我们的tensorboard
对我们的训练过程进行一个可视化
左边有一个visualizing?models?data?and?training?with?tensorboard
主要是这么一个教程
那么这里我想问一下大家
平时你们在使用tensorboard的时候
主要会去使用它的哪些功能
反正在我个人使用当中呢
我主要会使用其中的四个功能
第一个就是去保存一下网络的一个结构图

比如说在我们tensorboard的graphs当中
会有我们模型的一个结构图
然后这个图当中呢其实就能够比较清晰地看到我们整个模型
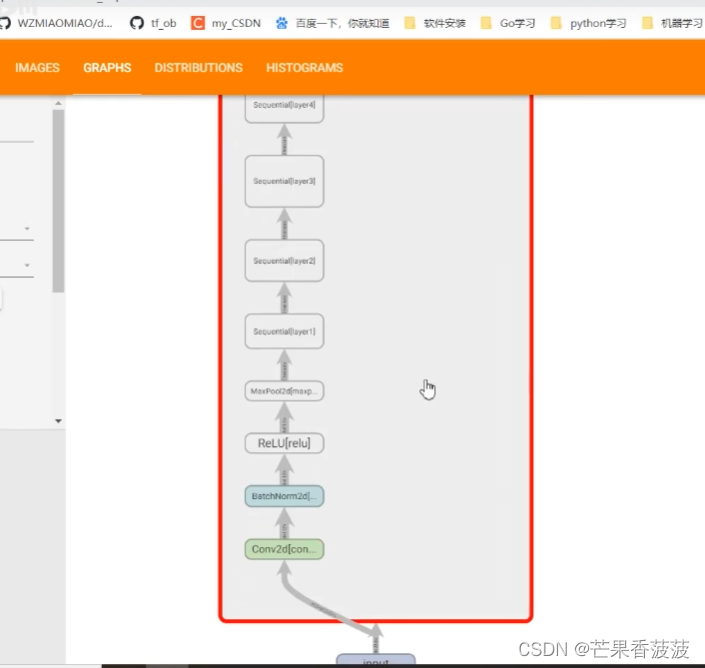
它的搭建的每一个模块
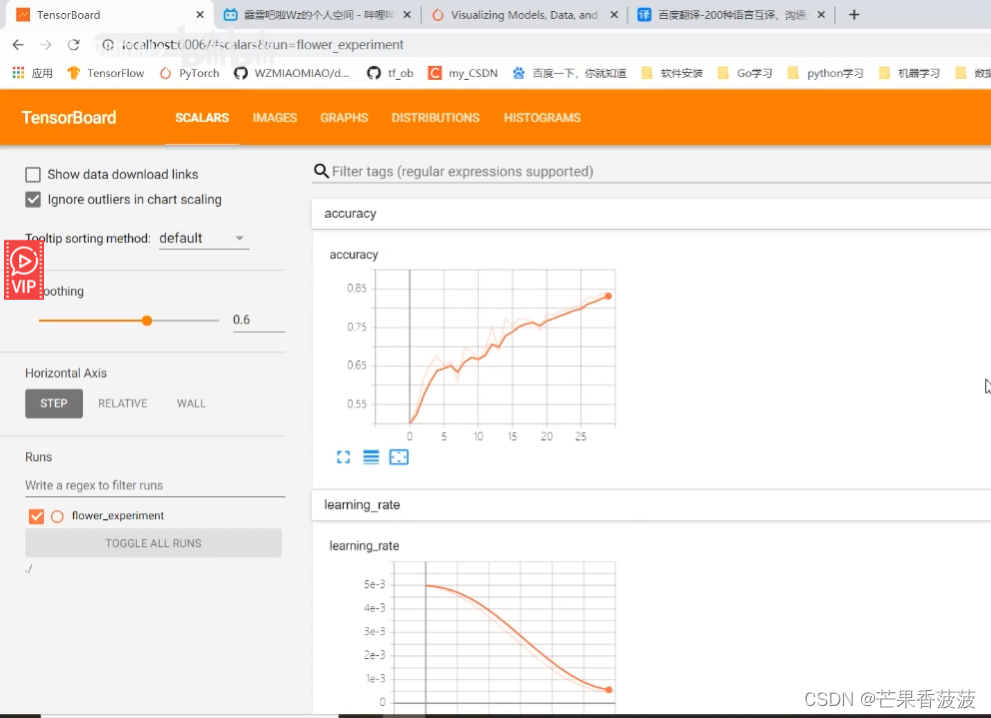
第二个呢就是保存我们在训练过程当中
训练集它的一个损失loss?还有验证集的accuracy?还有我们的学习率变化等等
在我们的scalars当中

那么这里呢就比如说我们这里有tracy
还有我们的learning?rate
还有我们的train?loss
那么第三个就是保存权重数值
它的一个分布在tensorboard当中的histogram当中
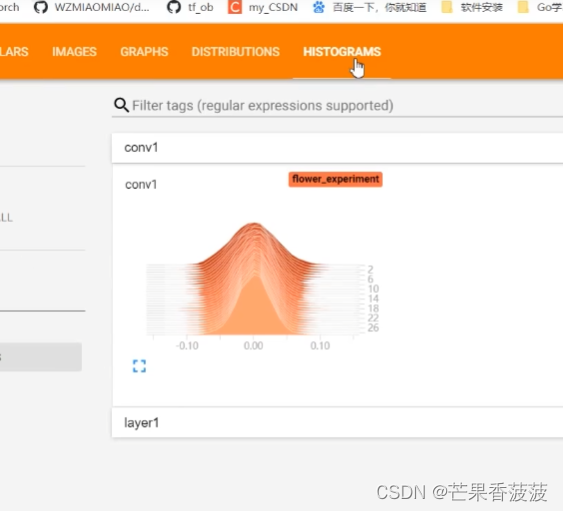
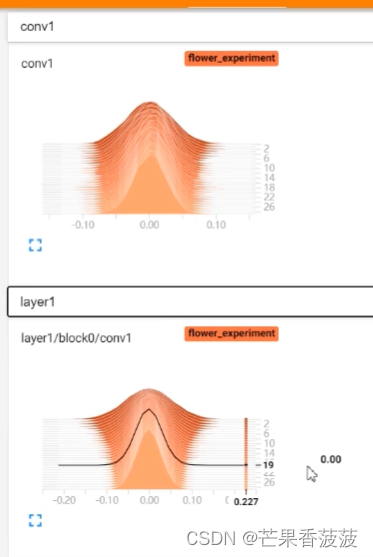
在这个里面呢一般就是保存我们每一个层结构
它的一个权重的数值的一个分布
那么最后一个呢就是保存我们预测图片的一些信息
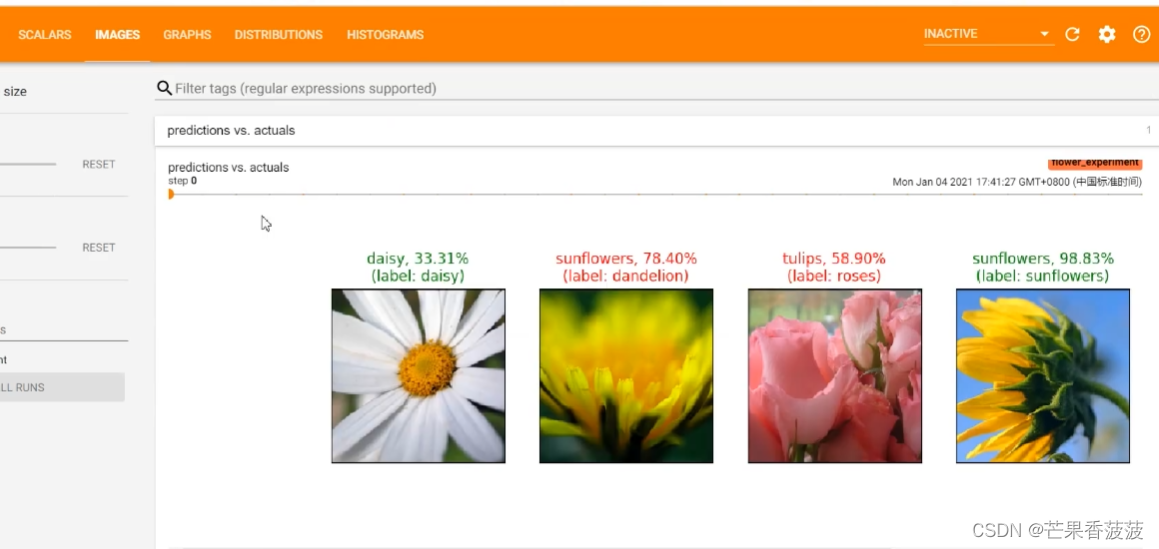
就比如说在我们的image当中保存有我们训练的每一个step对于我们给定的一些图片
它的一个预测的一个结果
首先我们这里需要建一个文件夹
叫做plot?image
那么在这个文件夹当中呢
我们所保存的图片是我们待会儿在训练过程当中
会对我们的这些图片进行预测

由于本节课训练是以我们之前的花分类数据集为例
所以呢我们这里需要先提前准备好我们的花分类数据集
我这里有给下载花分类数据集的一个地址

下载完之后呢
我们这里的image?root就指向我们解压之后文件夹它的一个路径
那么准备好我们的数据集之后呢
接下来就是关于预训练权重了
那么这里也是根据你个人的需求来进行选择了
如果你是需要去使用它的预训练权重的话
你就在这个pytorch官方的这个地址上去下载这个权重文件
然后将这里的defaul指向你刚刚下载这个权重路径就可以了
那如果你不去指认的话
那么它默认的就是不去使用任何预训练权重了
那么本教程其实是没有去使用这个预训练权重的
因为如果你使用了预训练权重之后呢
你会发现它的accuracy?loss基本上是没有变化的
因为在你训练的第一个epoch
它的准确率就已经达到97%了
所以基本看不出有什么变化
这里我不去使用预训练权重
就可以看到它的loss变化以及accuracy变化
那么这个参数freeze?layers

就是说是否去冻结我们的除全连接层以外的所有网络结构啊
这里默认是false
就是不去冻结
如果你设置为true的话
它就会去单独训练最后这个全连接层
之前的权重是不会去训练的
那么如果你使用这个预训练权重的话
你可以将这里设置为true
可以加快模型的训练
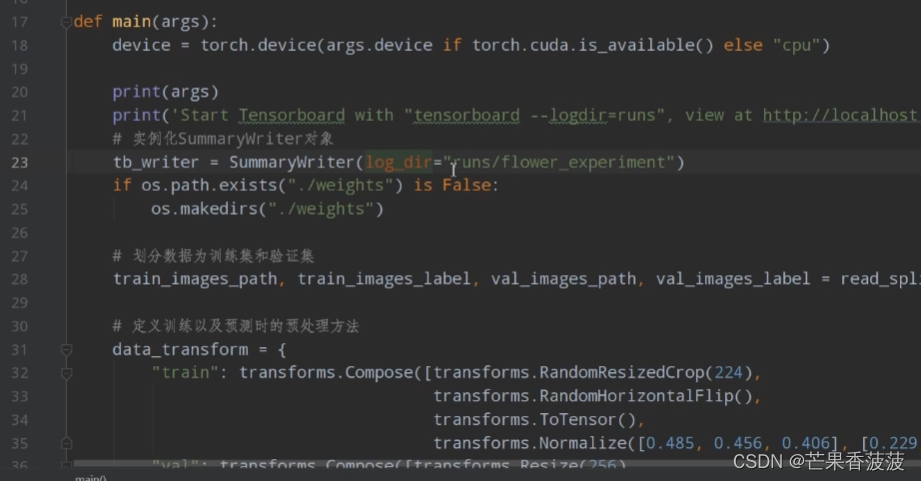
首先我们这里的summary?writer
它是来自于touch?utils的tensorboard的模块当中导入进来的

所以我们这里先实例化我们的tensorboard对象

这里我们需要插入这个参数呢
就是说我们将我们的tensorboard的文件保存在哪里
我这里就是保存在当前项目目录下的runs
然后flower?experiment这个文件夹当中
那么当我们实例化之后呢
它就会在我们当前项目想创建一个runs这个文件
然后会将我们对应的tbd文件保存在flower?experiment当中

实例化我们的tensorboard对象之后呢
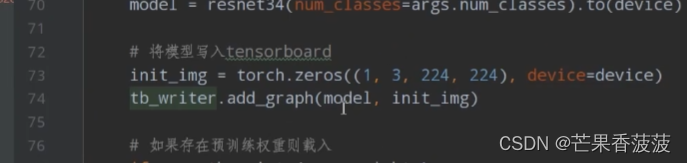
这里有去添加我们网络的一个结构图
在我们实例化我们的模型之后呢
紧接着在这里我创建了一个initial?image
它就是一个零矩阵了
这里为什么要去创建一个initial?image呢
因为在我们添加这个graph的时候
我们是需要将我们这个initial?image传入到我们的模型当中
让它进行一个这样传播
然后会根据我们输入的数据
在模型中正向传播的一个流程来创建我们的网络结构图
所以我们这里传入的数据只要和我们的图片大小相同就可以了

所以呢我这里就有创建一个initial?image
那么我们通过我们实例化的tensorboard
它的add?graph这个函数项目的模型
以及我们初始的一个图片传入进去就ok了
 在我们的这个位置有使用到add?scaler
在我们的这个位置有使用到add?scaler
那么这里呢其实就是在我们训练的每个epoch之后
也就是在我们验证完我们的模型之后
我们会去保存一下我们当前这一轮训练的训练集的平均损失loss
还有我们验证集的accuracy
以及我们的learning?rate

我们传入有这五个变量
第一个那就是我们实例化的模型
第二个image
第二对应的就是我们刚刚这个plot?image它的一个根目录
第三个transform对应着我们验证集所使用的一个图像预处理
第四个参数对应就是我们总共要展示多少张图片
第五参数就是我们说使用的device信息
然后接下来我们再往下走就到了我们这里的add?figure
也就是添加我们预测plot?image文件夹下这几张图片

第一个是我们这张图片它的一个名称
它的一个标题
然后第二个参数对应的就是figure这个对象
第三个global?step朋友们是通过epoch来指定的
首先在我们训练过程当中呢
我们会去生成一个json文件
这个json文件保存的就是我们类别索引
以及它的一个名称的一个对应关系


那么这里呢只要是正常训练的话
就会生成它
那如果它不存在的话
就说明训练过程是有问题的
那么这里就会报出一个错误
就是没有找到这个文件
然后接下来我们就会读取这个文件

我们通过touch?stack方法将我们的images
也就是我们刚刚所保存的一个图片的列表进行一个拼接
拼接成一个batch
那么这里大家需要注意的是
我们的stack方法会对我们的数据增加一个新的维度
那么通过我们刚才预处理之后
其实我们的每一个图片就变成了一个tensor的格式
它的shape就是3x224x224
那么这里呢我们会在它的最前面新增一个维度
那么就变成了拼接之后呢
它就变成了batch?x?3x224x224
我已经将我之前训练好的结果保存在对应的文件夹下面了
那么接下来我们就来打开tenor?board来看一下
那么首先进入我们的项目根目录
然后呢进入我们的runs文件

然后打开终端
打开终端之后呢
然后就输入tensorboard
然后logdir
然后就输入当前路径就可以了

然后接下来大家需要注意的是
我们还需要再加上一个参数啊
就是这个samples?per?plugin
然后在这个参数当中
我们需要指定一下我们所展示图片的一个数目
如果我们不指定这个参数的话
它默认会去采样十张图片
因为在我这个训练过程当中呢
如果按照默认参数来的话
只能看到十张
所以我这里会加上这么一个参数
指定为50之后呢
它就会展示所有的图片了
那么回车之后呢
终端就提示我们在local?host?端口可以看到
那么我们就进入浏览器
输入local?host?6006回车
然后就可以看到我们训练过程当中保存了一系列的数据了
那么在这个blog当中
我们可以看到我们那个数据的流向
就是根据这个箭头可以判断出数据的流向
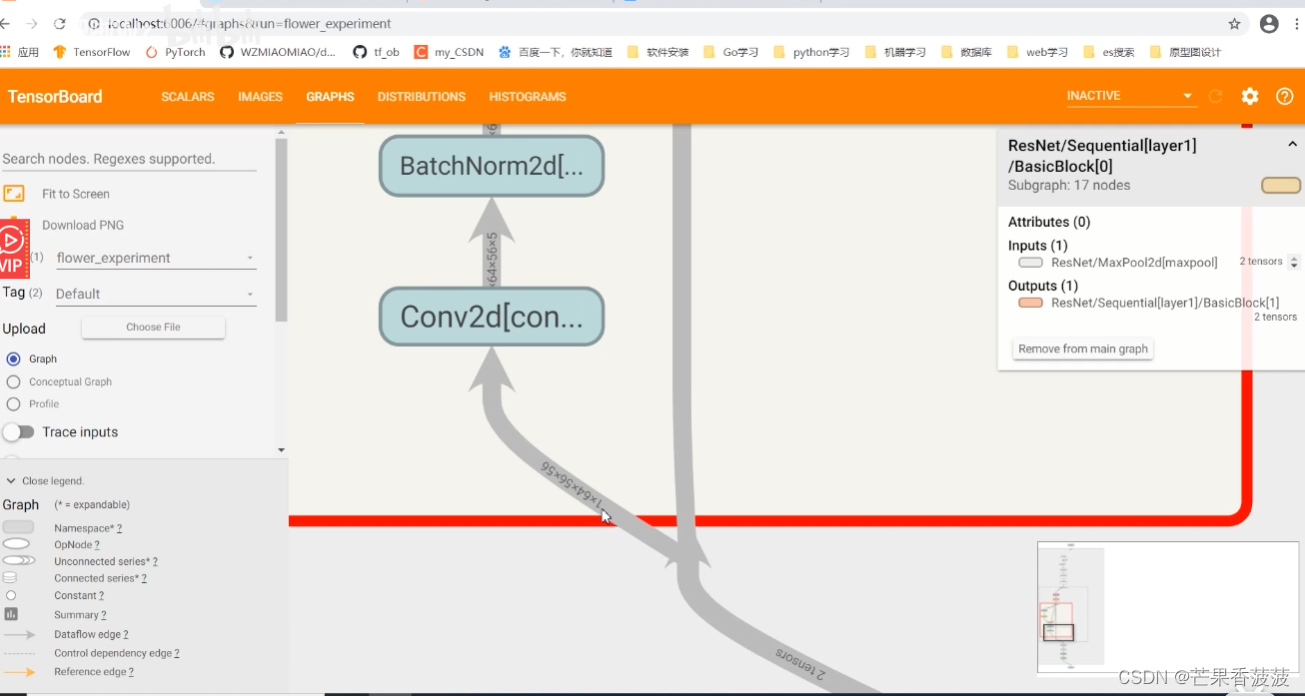
我们的初始化方法中只定义了一个relu
也就是说我们在我们主干分支当中所使用的这个relu结构
与我们主干分支与捷径分支相加之后所经过的机函的relu是同一个
所以这里会有一个往回流的一个箭头
然后经过relu之后呢
它就会输入到下一个模块当中
如果你想为了这个图看起来更好看的话
其实你可以在定义block的时候
定义两个relu
主分支上使用主分支这个relu
然后相加之后再使用另外一个relu
这样的话就不会出现像我们这个箭头往回指的这个情况
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!