P40 Transformer
2023-12-22 04:27:47
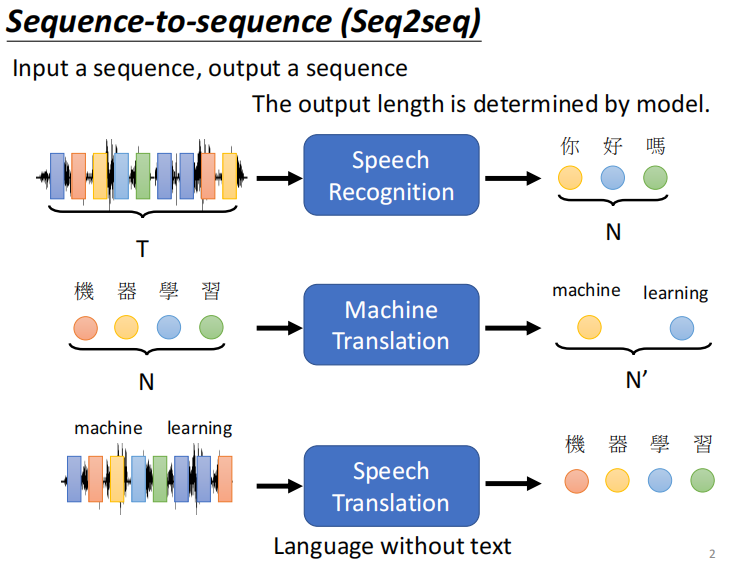
概述
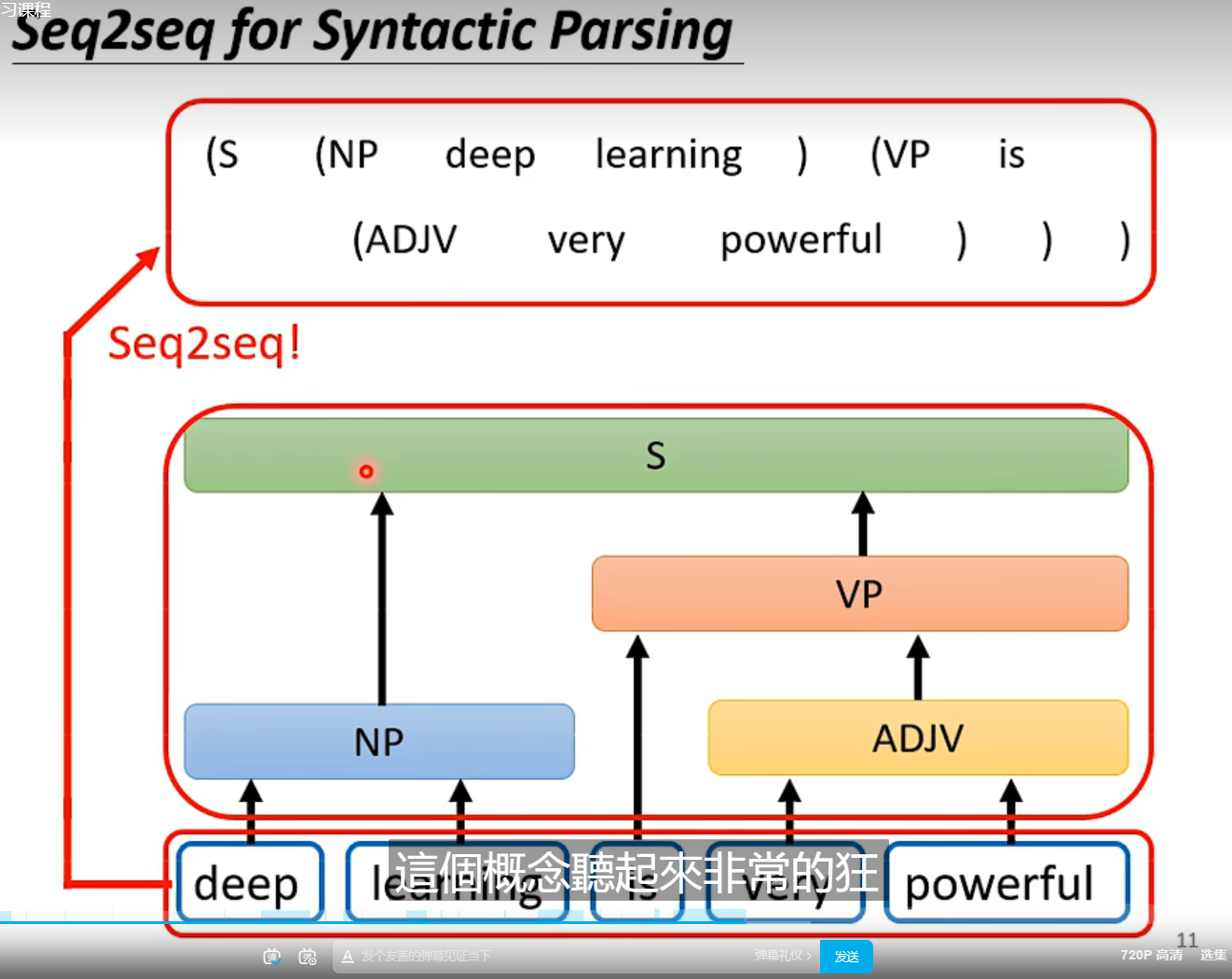
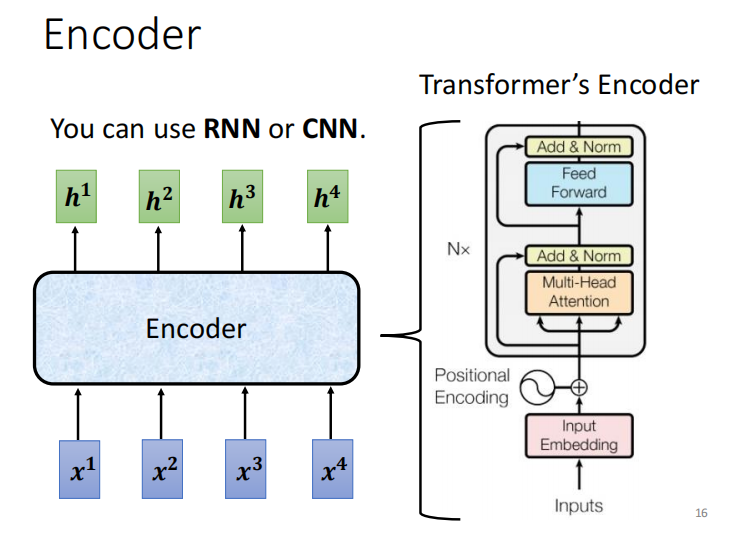
语法剖析
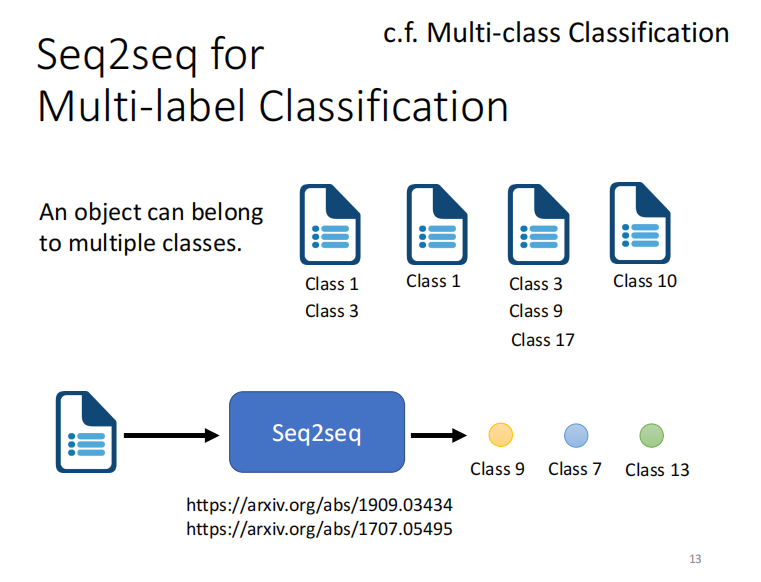
一个样本有多个类别归属
机器自己决定输出几个东西,输出的长度为多少
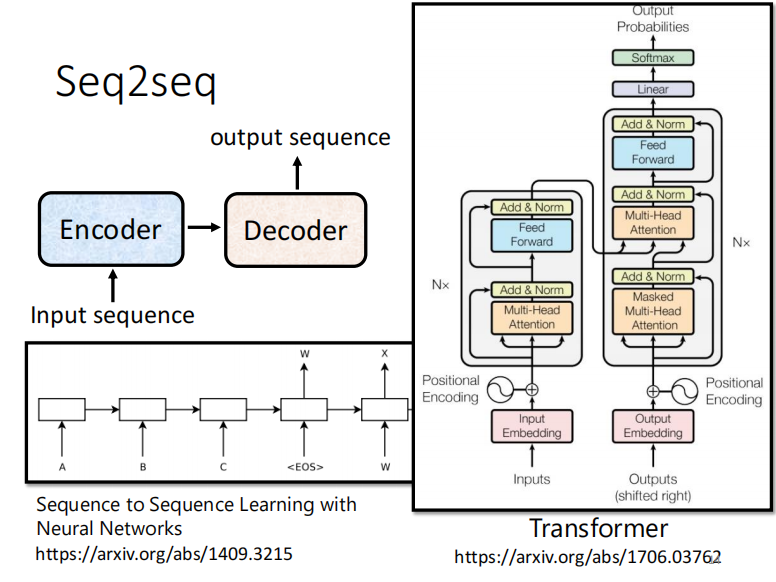
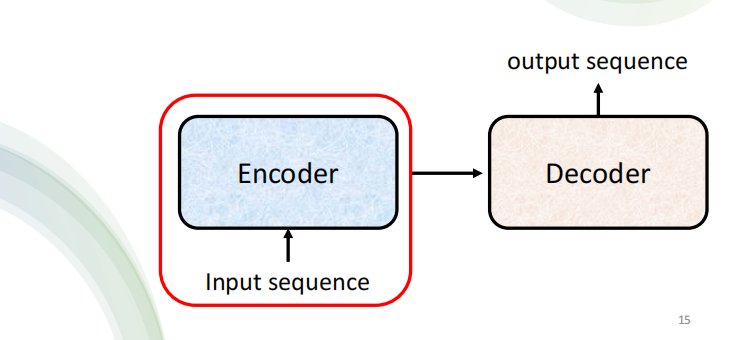
seq2seq实现过程
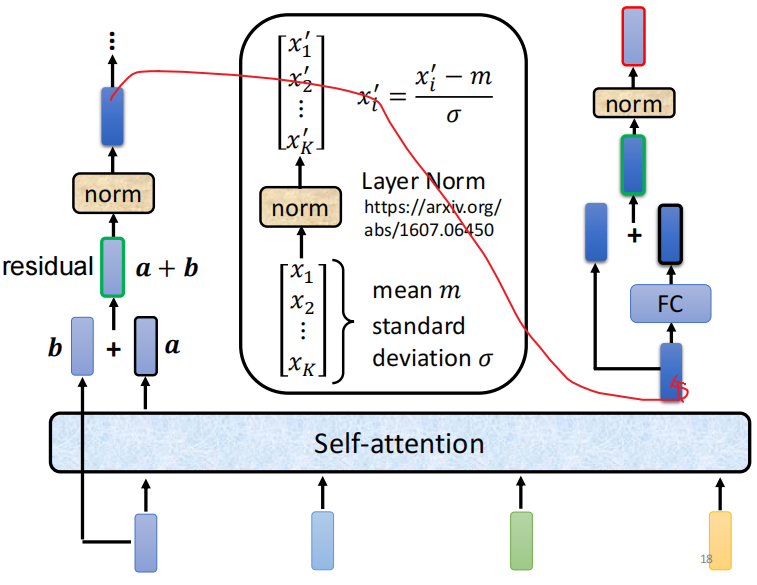
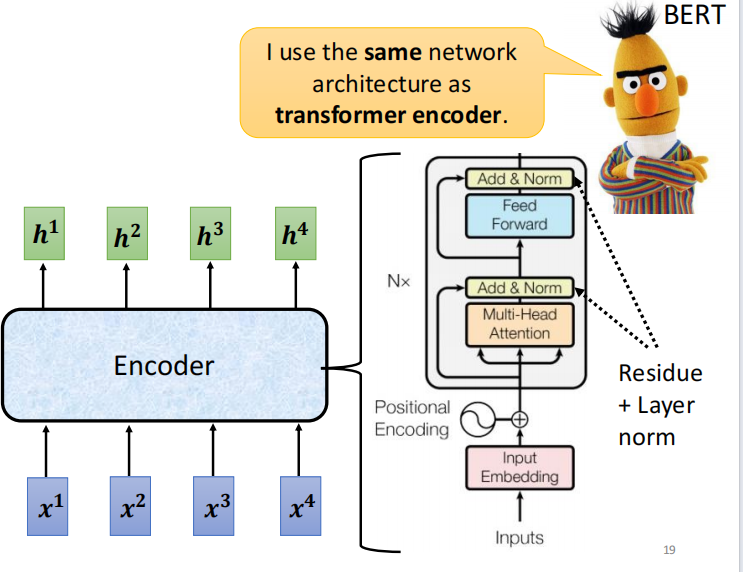
add+norm 代表 residual + noorm
resudial: input+output ???
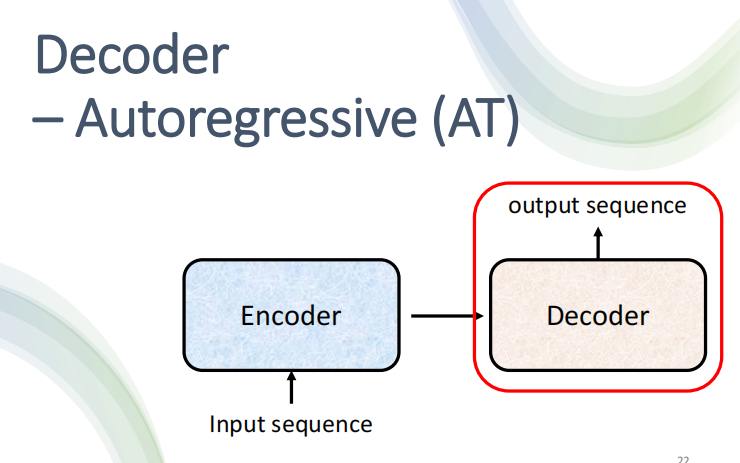
Decoder
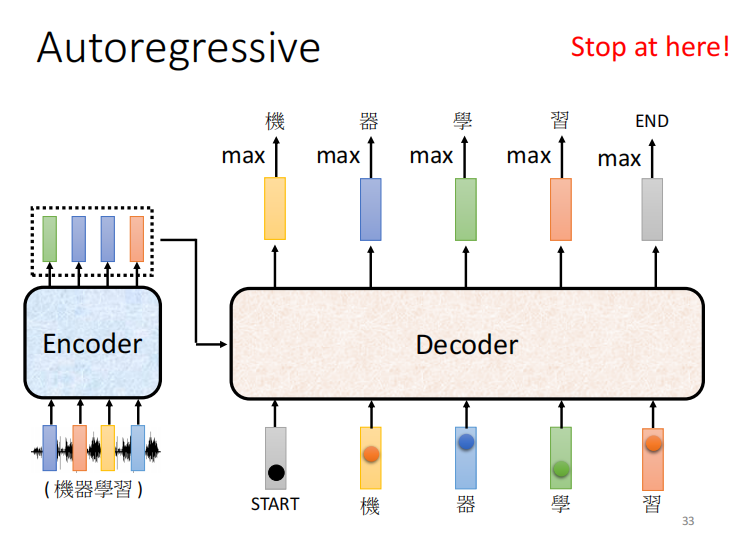
AT
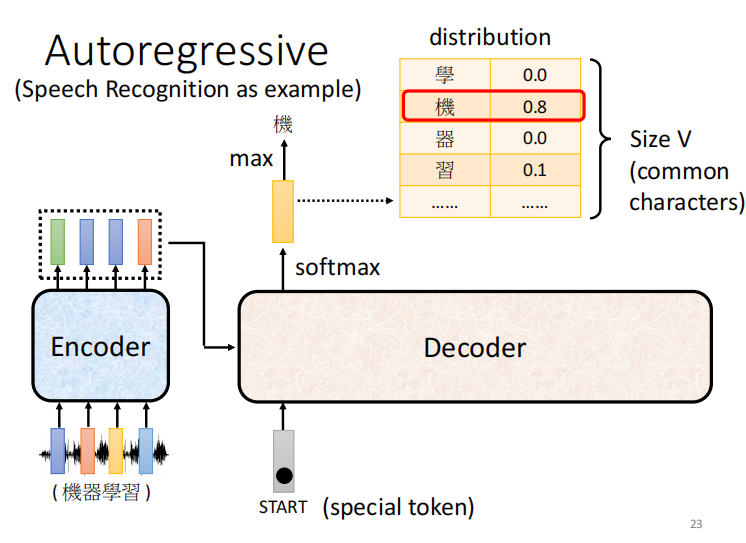
语音或者语句起始的地方,会有一个 special token
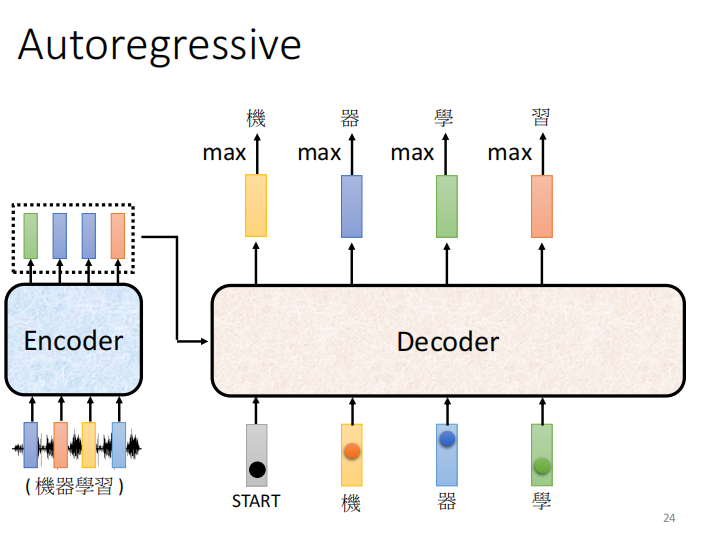
拿机当作输入,输出 器, 输入器 输出 学
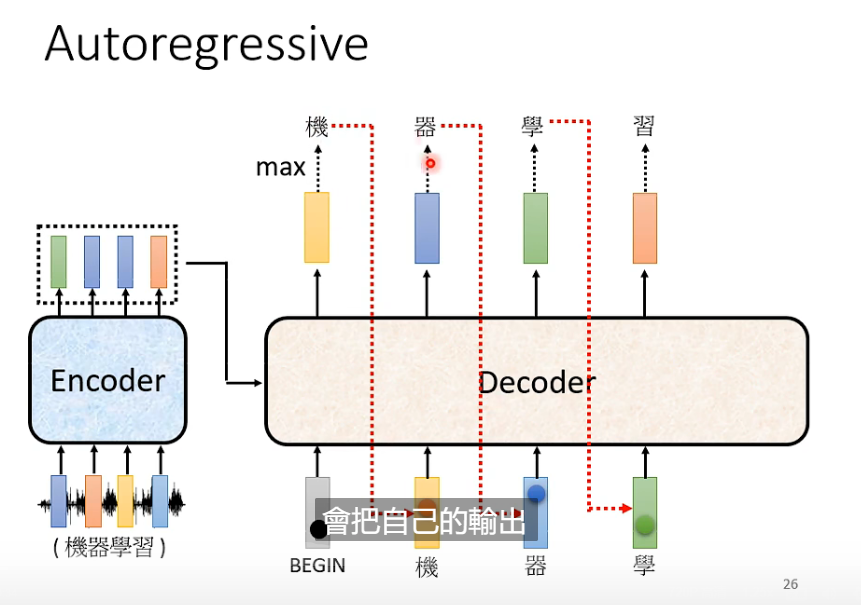
decoder 会把自己的输出当作下一个节点的输入
问题: 会不会造成一步错,步步错
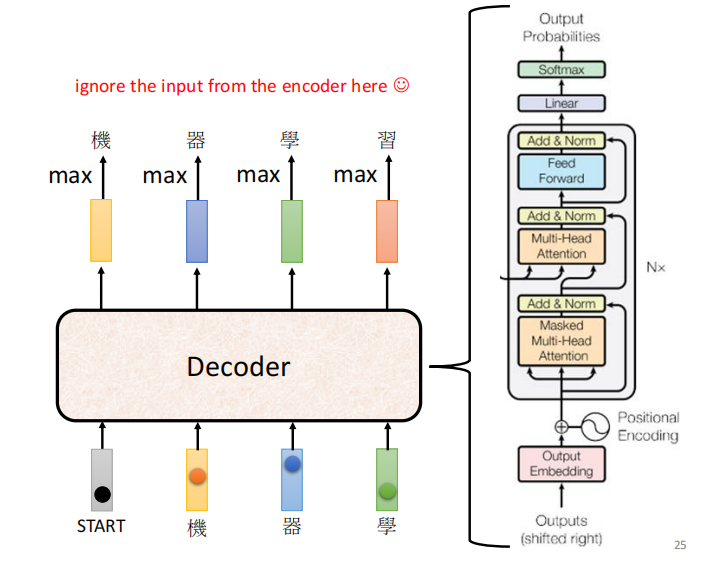
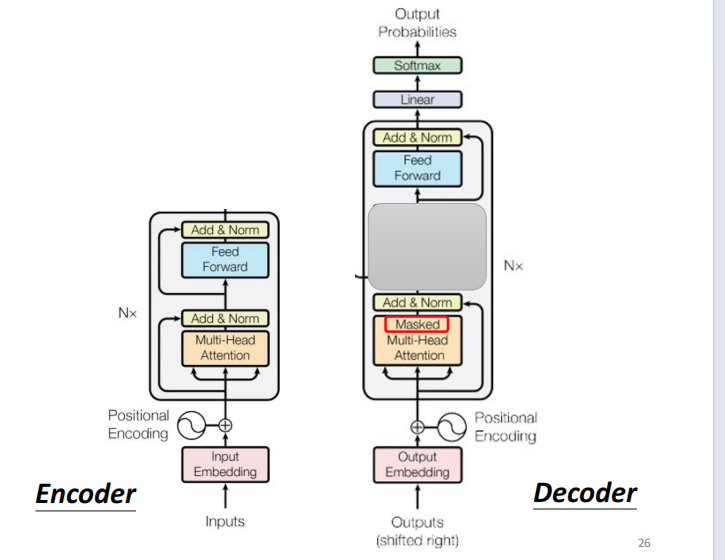
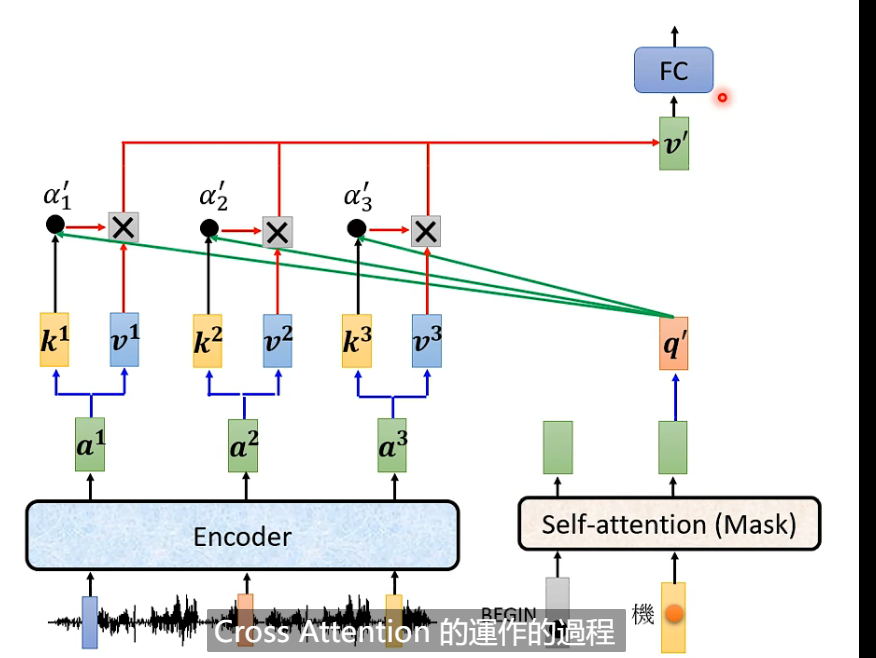
decoder 中间遮起来后,跟encoder 类似 差别:masked softmax
masked:

self -attention : 每个输出 考虑完整的input之后输出
mask - self -attention : 不考虑右边的输入。 如 b2 ,不考虑 a3 a4
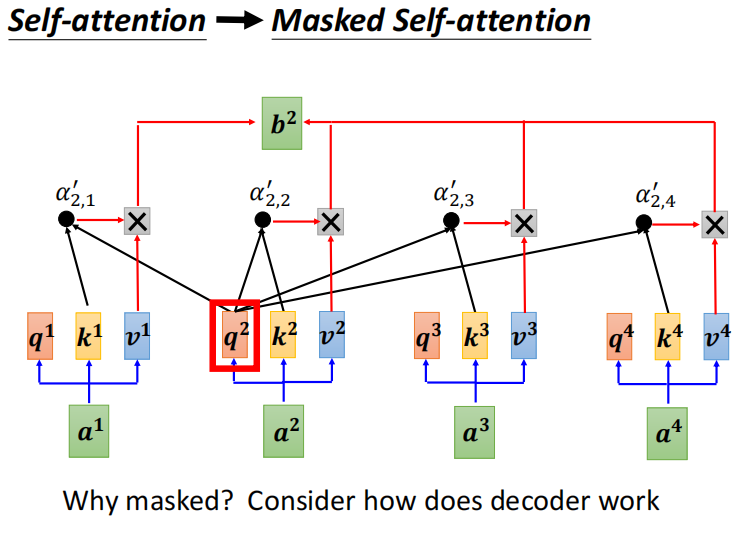
b2 只考虑 a1 a2
- DECODER 是 masked self-attention , 输出是一个一个输出的,所以只能考虑左边的东西
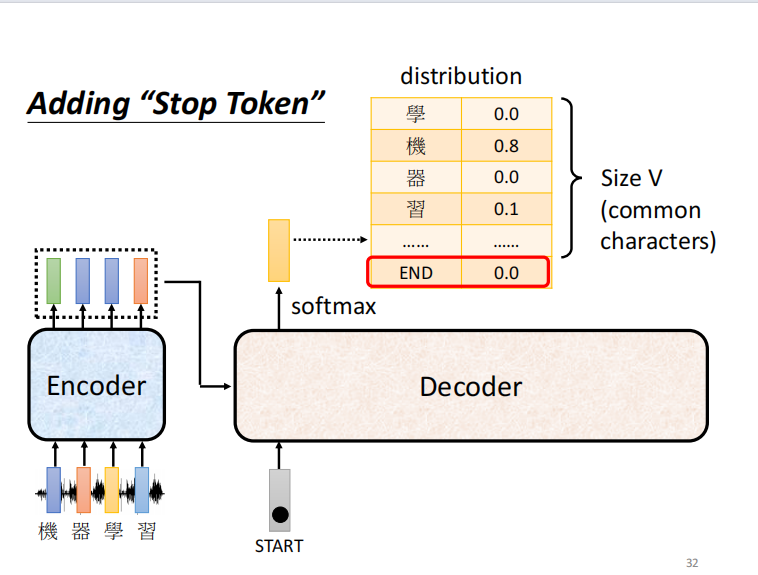
关键的问题: decoder 必须自己决定输出的 sequence 的长度
希望机器可以自己学到输出的长度。
怎么让 decoder 停止输出呢? --> 增加一个 end 符号
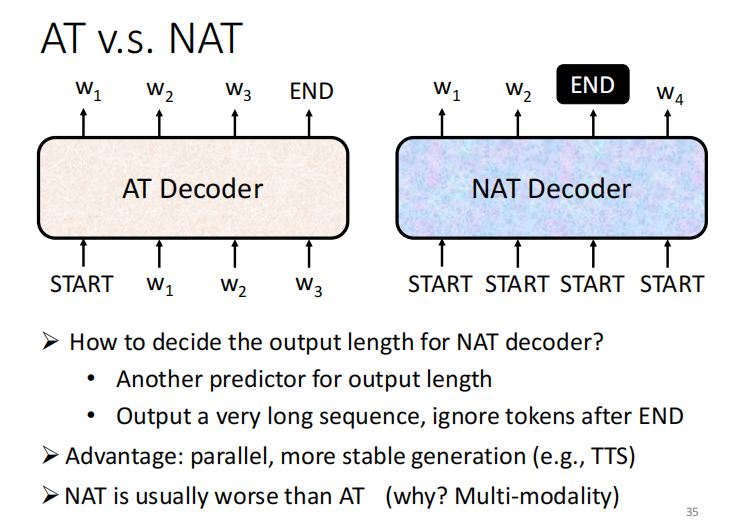
NAT
-
AT: 输入 begin , 输出end , 一次输出一个输出
-
NAT: 一次产生一排token, 一个步骤生成一个句子的生成。 问题: 如何确认输出的长度的?
* 增加两一个 prediction 预测长度
* 输出一个长序列, end 之后的忽略
优势:平行化 能控制输出的长度???
但是,效果没有AT好
encoder - decoder 如何连接起来的

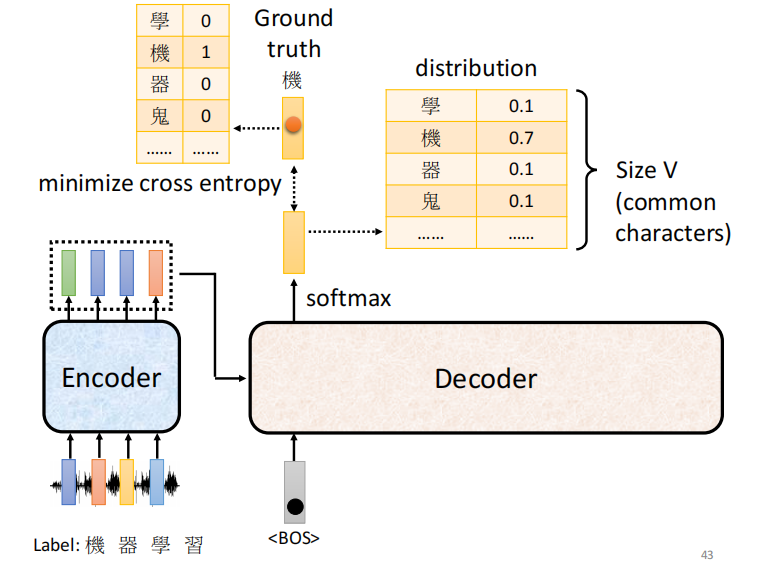
training
文章来源:https://blog.csdn.net/weixin_39107270/article/details/135068990
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!