基于深度学习的唇语识别系统的设计与实现
收藏和点赞,您的关注是我创作的动力
概要
?? 人工智能作为三大工程之一,从上个世纪至今仍然活跃于各个行业的研究与应用之中,应时代的热潮方向,本 课题主要针对深度学习技术应用于唇语识别当中,实现词语唇语的翻译功能。唇语识别在图像处理中一直是一个富 有挑战性的课题,对于唇语识别方法的实现都各有不同,目前来看,使用深度学习的方法提取特征训练效果基本高 于传统实现方法。本文主要使用opencv对视频进行切帧,并采用Yolov5算法对数据中的人脸唇部位置进行检测和切 割,再使用3DResnet结合GRU的复合式网络对唇语图像特征提取,最后用softmax分类器将特征矩阵进行分类。为了 体现系统的完整性,本文使用Flask框架实现唇语识别的功能化,达到了网页操作下的端到端唇语识别效果。
【关键词】:深度学习; Yolo算法; 残差网络; 唇语识别; Flask框架
一、研究背景与意义
??人工智能,作为世纪三大技术之一,从上个世纪至今依然没有被替代,就可以得出结论说明人工智能技术拥有 着无与伦比的技术创新潜力。尤其是这几年深度学习技术发展迅速,AI视觉算法呈现直线式的上升,再加上硬件技 术不断成熟,目标检测、图像处理、自然语言处理和语音识别等多项技术在实际应用当中取得了优异成绩,而唇语 识别则正是图像、语音以及自然语言处理技术的结合体现。
??唇读[1],即唇语识别,也称视觉上的语言识别,它是通过人说话时的动态唇形,来解析出具体说话的内容。在 人工智能的视觉领域中,唇语识别一直是研究者们重要的研究课题,它在许多方面有着广泛的应用价值,例如公共 安防、语音处理和影视行业等。唇语识别在过去难以研究是因为技术上一直存在着许多问题,但是在近十年,随着 神经网络等深度学习技术的不断发展,唇语识别技术研究进展得到了质的飞跃。自1976年McGurk等人提出麦格克效 应[2]后,国内外就出现了大量的研究者展开了对唇语识别技术的研究。在这40多年的研究过程中,各种唇语识别技 术可谓是遍地开花。但是在早期的人工智能技术中,对于唇语识别的研究可以说是寸步难行,尤其是早期的存在数 据集限制条件非常多、数据量低等问题,使得唇语识别技术研究很难找到突破口去进行,导致识别的准确率非常 低。然而这种情况在近几年有了好转,深度学习的热潮同样也冲击了唇语识别研究话题,为唇语识别带来了许多新 的技术,吸引着研究者们不断的向往,随之就出现了许多基于深度学习的唇语识别技术研究。唇语识别也取得了非 常大的进展,逐渐的从限定条件的化境走向非限定甚至是自然环境中研究,让唇语识别技术焕然一新。
??唇语识别具有开阔的应用场景,在当今社会,存在许多听力残疾患者,而唇语识别配合语音识别正是解决此问 题的关键,利用先进的人工智能技术实现人机唇语翻译识别,来帮助他们进行日常生活交流。还有在公共场合下, 想要进行秘密交流,亦可以使用唇语识别技术,实现无声交流,保护个人隐私。不仅如此,在嘈杂的环境下,当说 话声音完全被其他噪声所覆盖,这时候就需要唇语识别来辅助人们进行沟通交流,方便高噪声场合下的人交谈。综 上所述,唇语识别应用广泛,研究唇语识别技术所具有的意义也重大非凡。
二、项目技术理论
2.1 残差网络ResNet
?? 神经网络到目前为止技术发展的相当成熟,随着深度学习的热度飙升,科研人员一直在不断的尝试创造新的算 法来优化神经网络,为智能化时代持续地推进着。而卷积神经网络CNN则是当今最主流的神经网络之一,它依靠卷积 层和池化层对数据进行下采样提取特征,很大程度的使网络学习到了更重要的参数,至今依然适用于图像、语音、 文字处理等领域。
??ResNet[21](Residual Neural Network)由微软研究院的Kaiming He等人提出,并在ILSVRC2015比赛中取得冠 军。ResNet作为CNN中的经典网络模型,它是通过一个又一个子网络经过堆叠可以构成一个很深的残差网络。实验结 果表明,网络越深它获取的信息越多,学习到的特征也就越多。但是神经网络往往随着层数的加深,优化效果反而 越差,测试数据和训练数据的准确率反而降低了。这很大程度是因为网络的加深会造成梯度爆炸或者梯度消失的问 题,而残差网络就是解决此问题而诞生的。其核心就是利用残差模块,通过子网络跳连的方式构造出一个多层的神 经网络,如图2-1所示。
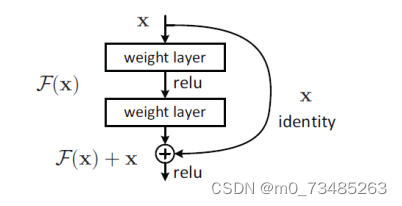
图2-1 残差块结构
?? 通过这中跳连模块,可以将前一层输入与输出进行维度上升后再相加,一般升维操作使用的是全0填充或者1×1 卷积。此操作能够保证下一层网络仍然是目前最优状态,巧妙地解决了网络退化问题。在ResNet网络的构建当中, 大量使用这种残差模块,构建深度达到几十层甚至上百层网络,其规模大到一定程度的时候,网络所具有的表达能 力就越强。一般来说,ResNet深层网络往往比浅层效果更好,但有时候出于计算成本考虑,选用合适的网络层数有 时候对于整个神经网络而言才是最优抉择。
??通过这中跳连模块,可以将前一层输入与输出进行维度上升后再相加,一般升维操作使用的是全0填充或者1×1
卷积。此操作能够保证下一层网络仍然是目前最优状态,巧妙地解决了网络退化问题。在ResNet网络的构建当中,
大量使用这种残差模块,构建深度达到几十层甚至上百层网络,其规模大到一定程度的时候,网络所具有的表达能
力就越强。一般来说,ResNet深层网络往往比浅层效果更好,但有时候出于计算成本考虑,选用合适的网络层数有
时候对于整个神经网络而言才是最优抉择。
2.2 门控循环单元GRU
??GRU[22](Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network,RNN)的一种变体网络,于
2014年由Gulcehre等人提出。GRU有两个门,即一个重置门(reset gate)和一个更新门(update gate)。其中r控
制重置门控,z为控制更新门控,如图2-2所示。
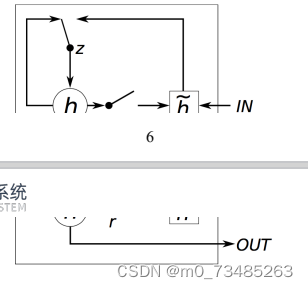
图2-2 GRU单元
??更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带
入越多。重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。用门控机制控制输
入、记忆等信息而在当前时间步做出预测,其数学表达式如下公式2-1、2-2、2-3、2-4所示。
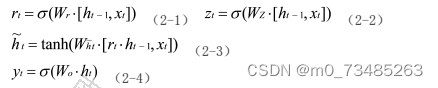
??在上述的四条公式中,GRU首先是通过上一个传输下来的状态ht-1和当前节点的输入xt来获取两个门控状态。通过σ(sigmoid)函数将数据变换的范围缩减到0-1内,以此来作为门控的信号。GRU只要使用一个门控z就可以同时
完成信息的遗忘和记忆,门控信号越接近1,代表“记忆”下来的数据越多;而越接近0则代表“遗忘”的越多。
??GRU的内部思想与LSTM[23]相似,但是GRU内部少了一个门控机制,因此GRU的计算参数比LSTM少。尽管如此,但
是却在性能上却可以跟LSTM不相上下。在使用的领域中,GRU应用范围不仅仅局限于文本处理,在图像上效果也非常
可观,因此,GRU网络也随之效果而越发让人研究使用。
2.3 目标检测Yolo算法
??目标检测一直是机器视觉的一大主流研究方向之一,在这之中诞生了许多优秀的目标检测算法,比较流行的算
法可以分为两类,一类是基于Region Proposal的R-CNN系tow-stage算法,如Faster R-CNN算法[24];而另一类是
Yolo[19]、SSD[29]这类one-stage算法。第一类方法是准确度高的同时速度慢,第二类算法则反之,计算的速度快
但是准确性低。Yolo作为one-stage算法的代表之一,它所具有的优势吸引着无数研发人员。
??Yolo算法从结构上可以分为输入端、Backbone、Neck、Prediction四个部分,其的核心思想是直接将原始图片
分割成互不重合的小方块,然后通过卷积产生特定大小的特征图,特征图的每个元素是对应原始图片的一个小方
块,然后用每个元素来可以预测那些中心点在该小方块内的目标,以此来达到物体检测的效果。整体来看,Yolo算
法采用一个单独的CNN模型实现端到端的目标检测,整个算法大体操作如图2-3所示:首先将输入图片缩放至
416×416,然后送入多层数的CNN网络,最后处理网络预测结果得到检测的目标。
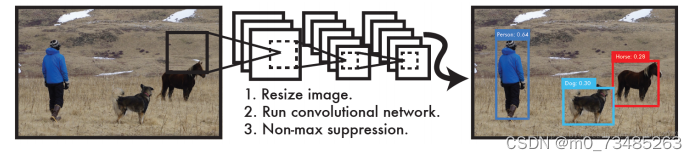
图2-3 YOLO算法示例 确
??切的说,Yolo的CNN网络是将输入的图片分割成S×S网格,然后每个单元格分别检测那些中心点落在该单元格 子内的目标。每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。置信度的 构成由两个方面,一是边界框含有目标的可能性大小,二是这个边界框的准确度,它是两者的乘积结果。而边界框 的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union)即交并比来表示。 对于Yolo中的分类,是对每一个单元格预测出每个类别概率值,其表征的是由该单元格负责预测的边界框中目 标对应各个类别的概率。在Yolov3[25]之前,预测目标类别都是采用softmax进行预测,在Yolov3中作者舍弃了 softmax改用sigmoid函数,解决了类别之间不互斥造成的问题。 在2020年Bochkovskiy等人扛起了Yolo的大旗提出Yolov4[26],算法在预处理中加入了Mosaic数据增强、SAT自
??对抗训练等操作,在主干网络中换成CSPDarknet53以及使用Mish激活函数[27],同时在Neck部分加入了FPN和PAN操 作,并且采用SPP模块,多种措施的采取使其算法进一步增强。在Yolov4才诞生了两个月的时间,Yolov5也随之发 布,尽管v5和v4的区别并不明显,但对于算法的灵活性提升了一个档次。Yolov5在输入端加入了自适应的锚框计 算,同时主干网络上引入了Focus操作,以及在bounding box损失函数中换成了GIOU_Loss等。不仅如此,Yolov5提供了四个预训练模型,由于模型的参数和网络规模都不同,可以根据不同的项目需求,取长补短,发挥不同检测网 络的优势。
2.4 轻量级web框架Flask
??在众多Python web框架中,Flask[20]是一个相对比较轻量级别的web框架,Flask简单易学,不但可以快速搭建 小型网页,也可作为APP的API,而其采用的MVC架构也非常符合软件设计的原则。Flask对象实现了一个WSGI (Python Web Server Gateway Interface)应用程序,并当作核心对象的模块或包的名称传递应用程序。一旦它被 创建,它将作为一个中心注册表视图函数、URL规则、模板配置等。 Flask作为微型网络开发框架,体现在它只提供Web服务的基本功能,其他的功能是由Flask的扩展实现,用户可 以根据需求应用核心扩展,它的基本功能依赖于符合 WSGI 规范的 Werkzeug 库和模板系统 Jinja2。Flask的应用 程序需要Flask类实例化才能运行,网站的基本配置信息也包含在此类中。 Flask可以通过路由将Web服务的请求转交给Flask程序实例的函数处理,这个函数称为视图函数,路由就是URL 与函数之间的抽象关系。Flask类包含了route装饰器,通过初始化Flask类注册视图函数。在处理GET、POST请求 时,需要添加methods,使得视图函数能够处理http请求,methods中的参数包括了Http协议中定义的5种动作。当服 务器需要响应请求时,主要是处理Flask默认的Http协议的状态码,当处理完毕即可相应服务器的请求,执行相应的 视图函数与参数前后端传递。
三、项目分析与技术路线
3.1 项目分析
??唇语识别作为3D视觉的研究话题,从上个世纪至今不断有研究者向其发出挑战。而本项目的核心问题,就是针 对唇语序列图片或者视频进行有效的识别。在数据方面,项目需要有充足的数据支撑神经网络训练,并且图像数据 不能存在太多的错误数据。而项目使用的数据集是2019年“创青春·交子杯”新网银行高校金融科技挑战赛-AI算法 赛道[28]的唇语数据集,该数据集是只有图片帧的数据集,整份数据集是由9996份带标签训练样本和2504份无标签 预测样本构成,标签文件为txt格式文件,一个样本文件名对应一个中文词语,存储量8GB左右。数据包含的唇语是 两个字或者四个字的中文词语,它们的比例为6816:3180,总共有313个类别,除了其中的“落地生根”和“卓有成 效”两个类是只有22个样本,其他类别均有32个样本。每个数据样本的帧数由2到24不等,平均帧数在8帧左右,分 布比较均匀,图片内容基本都是人脸部的下半部分,如图3-1所示。图像色度和饱和度都没有太大差异,这样一定程 度削减的干扰因素,方便使用者构建网络学习更多的有效特征。

图3-1 唇语图像数据
?? 数据可以分为有用信息和无用信息,在这份数据里,开口状态即为有用信息,闭口则是无用信息。因此在数据
处理过程,神经网络应该着重注意开口状态的特征,但唇语数据中唇形差异并不大,使得低层数的网络提不到更多
有用的特征,所以本文的主干网络选取多层数的Resnet网络。此外,时间序列的特征信息也尤为重要,仅靠3D网络
往往不会有太好的效果,因此本文在网络结构中嵌入门控循环单元GRU,它能将最大限度的保留时序特征,非常符合
网络的需求。
??在图像数据分析中,项目唇部检测的任务难点不是在于目标的精度,而是在于检测的速度,因此本文在唇部检
测模块采取的算法是Yolov5算法,采用的预训练模型为Yolov5s,项目在使用Yolov5之前,曾使用Yolov3算法进行唇
部检测,对比两个网络模型相应的性能如表3-1所示。由表可知在AP精度上,Yolov5s模型比不上Yolov3-spp,但其
优点在于GPU的预测速度远远快于Yolov3-spp模型,并且模型占用的内存仅为Yolov3-spp模型的3.3%,这样极大的缩
小了整个项目的占用空间,降低了整个项目的时间空间复杂度。
表3-1 模型性能对比

??除此之外,本文也非常重视功能需求,特别是系统的完整性,除了唇语识别功能,还要加上一些常见的功能,
如登录注册等,更加符合系统的设计要求。
3.2 项目技术路线
??本文研究的主要内容是对中文唇语词语的识别功能,研究的问题涉及到唇部定位、时序信息特征提取、网络对 特征的预测结果以及web端实现前后端数据交互四个方面。由于采用深度学习模型,为了保证模型的鲁棒性和泛化能 力,本文需要大量的数据提供训练。 在系统功能上,用户需要登录成功才能使用唇语识别功能,项目流程如图3-1所示。
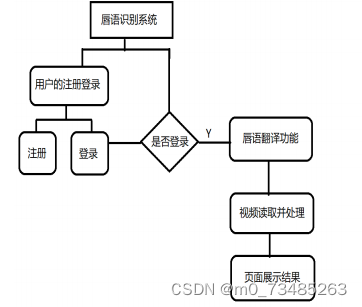
图3-1项目流程
在技术路线上,第一个模块是目标检测,该模块需要准确的找到人的唇部位置,并且通过预测的坐标进行图像
裁剪,保证唇部位于图像的最中间位置,项目实现算法为Yolov5算法。目标检测数据集的制作中,尽量保证数据的
完整性,采用最小的预训练模型进行训练得到一个model。
第二模块采用的是3DResNet与GRU复合式网络,通过Yolov5算法处理过的数据传入该网络中,残差结构提取特
征,GRU保证时序信息的传递与保存,再通过softmax得到预测的结果。在该模块中,训练数据的数量尤为关键,所
以在预处理中,使用数据增强让网络有充足的数据训练。其次,网络的结构也非常重要,残差网络ResNet是由多层
网络堆叠而成,解决网络深度造成的梯度消失问题,让网络更深,提取到的图像信息特征越多越有效。而循环神经
网络RNN的变种体GRU则是通过了门的控制机制,使时序信息得到很好的保留,让神经网络更加关注的是连续序列而
成的唇部动态变化信息。
预测结果最终传入web模块,依靠html和js完成前后端的交互,实现的系统的识别功能。在web模块中,所使用
的框架是flask框架,该框架优点就是轻巧灵活,在登录功能中html直接往后端提交表单,后端只要通过数据库对表
单进行校验,就可以完成登录功能。在识别功能中,通过js配合html读取本地视频,再提交到后台进行处理,处理
过程首先是经过视频切帧,然后Yolov5模型对帧数图像进行唇部坐标预测,再切割图像并保存,最后通过分类网络
得到预测的结果,识别的词语展示到前端页面即可完成整个功能的流程,处理的流程如图3-2所示。
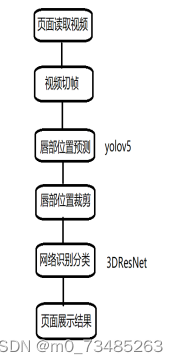
图3-2数据处理流程
项目采用的技术为当今最主流的one-stage目标检测算法Yolo,用做辅助残差网络ResNet对视频进行唇语翻译,
该目标检测算法首次应用于唇语识别中,使系统达到端到端的识别效果。其次数据集是由多帧数图像组成单一样
本,存在缺帧等问题,给项目带来了一定的难度。项目还采用了python轻量级web框架Flask,通过前端html和js的配
合使用来操作深度学习算法,达到视觉上的展示效果,让用户可以使用网页端操作唇语识别系统。
4.2 唇语识别技术实现
4.2.1唇部检测切割
?? 在第三章节中对数据集进行了分析,对于图像处理中数据特征提取很大程度取决于图像内容结构。拿唇语数据
集来说,每一帧的有效信息有时候仅仅只是唇部的位置,所以对于半张脸型的图像来说,里面内容包含的无效因素
是过多的。因此,对数据进行分类之前,有必要对整份数据集的所有图像进行一个唇部位置切割,这就需要用到相
应目标检测算法,通过第三章节的分析本项目采用的是Yolov5算法。
在算法部署之前,需要对目标检测的数据集进行一个标注,使用的标注工具为labelLmg,标注的图像为随机从
源数据集中抽取的500张和个人自拍上半身图片100张图片,500张数据集抽取的图像是为了对整份数据集进行唇部检
测,100张上半身照片是为了预测视频的时候能准确找到预测人的唇部位置而设的。标记完成后得到的是一张图像对
应一个xml文件的标签文件,其内容主要有图像名、图像的宽高、坐标点以及框住物体对应类别。如图4-2所示。
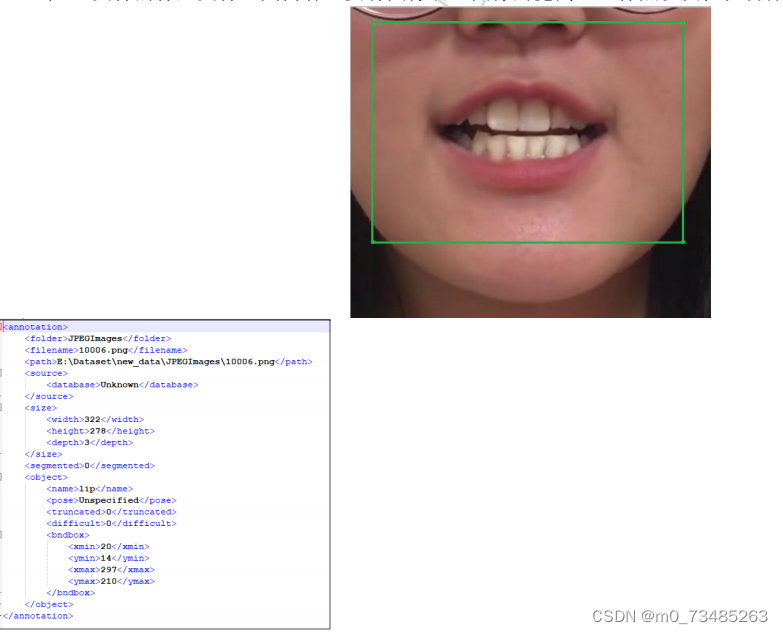
图4-2图像与标签
在图4-2的a图中,标记位置为唇部为中心的小脸型矩形框,b图则是图像对应的xml标签信息文件。标注完的数
据集是VOC格式的标签,而Yolo算法使用的是Yolo格式的标签,因此需要编写python程序对600份标签进行一个格式
转换。最后得到的是txt文件,内容由类别和归一化后的xywh四个值组成。转换完成后还需要将600份样本进行训练
集和测试集划分,划分比例为9比1的比例。做好一切数据集工作,接下来就是Yolo的算法部署。源码和预训练模型
都采用官方pytorch框架实现的源码和模型,模型用的是Yolov5s模型,该模型参数量和网络规模都是最小的,非常
符合项目对速度上的需求。
在Yolov5的算法流程上,图像首先在输入端进行了数据预处理,如缩放、归一化、Mosaic数据增强等,整个算
法处理流程如图4-3所示。
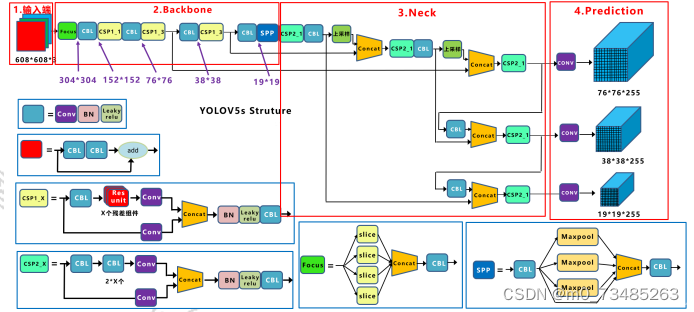
图4-3 Yolov5算法流程
其次是送入Backbone主干网络进行特征提取,Yolo在处理每一张的图像时,首先会通过Focus操作将图像进行切
片,输入图像为608×608×3经过Focus会变成304×304×12的特征图。再利用32(Yolov5s预训练模型的卷积核为
32)个卷积核对特征图进行卷积,最终得到304×304×32的特征图作为网络的输入。特征图输入到主干网络CSP_1中
进行多次卷积、BN(Batch Normalization)和Leaky_ReLU激活的特征提取下采样,以及Concat张量拼接。SPP模块
是多个组件和操作构成,即CBL(conv+BN+Leaky_ReLU)组件、最大池化和Concat操作,该模块为主干网络的输出模
块。
主干网络特征提取后数据会传入Neck部分,Neck中会将特征进行CSP_2网络结构处理,并结合上采样FAN构建特
征金字塔FPN,加大了网络特征融合能力。最后在输出端中,输出端有三层输出结果,分别对应下采样的倍数32、
16、8,以原图尺寸608为例,模型的预测是在19×19、38×38、76×76每个输出层的每个特征点上预测三个框,通
过sigmoid函数对数据进行归一化并计算得到想应的值,最后采用NMS非极大值抑制得到最终的预测框。在损失的计
算中,bounding box的loss函数GIOU_Loss是由预测框与真实框计算得到,公式如4-1所示。其中C表示为预测框和真
实框外切矩形面积,交集为外切矩形面积C减去预测框和真实框的并集。而类别概率和目标得分的Loss,则是由二进
制交叉熵和Logits损失函数计算。
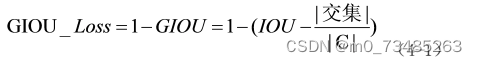
计算出损失就可以不断更新整个网络,调整网络参数完成训练和测试的任务,训练和测试的效果如图4-4所示。
整个网络在epoch达到30次基本就已经收敛了,从图4-3可以看出,唇部位置基本都是位于框的最中间位置,并且预
测框的效果都在0.9左右,可以说训练的模型算是比较完美的。
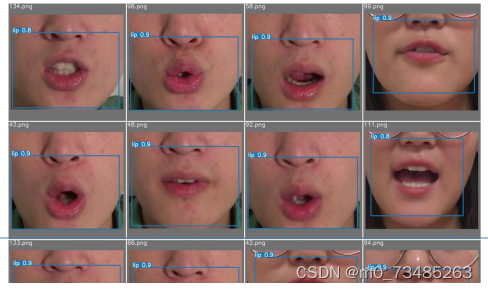
图4-4 训练效果
模型训练并保存完毕即可对整份数据集进行唇部位置切割操作,由于硬件问题,数据集313份中文词语类别我只
挑选了100份类别进行处理。一个类别有32份样本,100个类别就有3200份样本,每个样本中的图像的命名都是从1逐
渐递增而命名的数据文件名,因此在detect中需要对原数据读取进行修改,这里在唇部检测和切割图片分两个步骤
进行,首先是通过预测代码对所有图片进行预测并保存每张图片对应的四个坐标值(左下和右上顶点x和y坐标值)
至txt文件中。其次是遍历每张图片通过其对应坐标进行切割,切割图片使用了opencv库读取、切割和保存,实现的
核心代码如下:
with open(data_root1, ‘r’, encoding=‘utf-8’) as f: #打开txt文件
lines = f.readlines() #获取txt中的每一行内容并返回到列表中
labels = [line.strip().split(’ ') for line in lines][0] #获取第一行内容并进行空格分割
image = cv2.imread(source1) #opencv读取图片
cropped=image[int(labels[2]):int(labels[4]),
int(labels[1]):int(labels[3])] #根据左下和右上顶点的坐标分割图像
cv2.imwrite(source1, cropped) #将图像写到原图路径并覆盖原图
data_root1为预测坐标所在的txt文件,lines为整个文件内容按行存放的列表,labels为获取得到的四个坐标
值存放的列表,最后通过opencv读取、切割、保存即可完成图片的切割任务,切割的效果如图4-5所示。
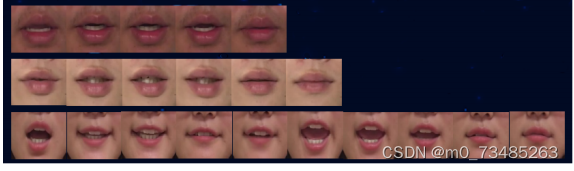
图4-5 切割完成图
从中可以看出,Yolo算法对唇部位置检测的效果非常可观,每一帧图像的唇部基本位于图像的最中间位置,这
样后续分类网络处理图片就减去了许多无效因素,网络更容易拟合。
四、 总结与展望
6.1总结
针对web端操作下的唇语识别,本文主要是使用了两大主流深度学习算法部署到Flask框架的集成思想,对如下
内容进行了研究应用:
(1)Yolov5算法对人脸进行唇部定位,采用预测的坐标对数据集进行处理,整理得到图像内容仅包含有效信息
的数据集;
(2)设计3DResnet和GRU复合网络,利用2D的残差模块组成深度网进行提取特征,最后利用GRU将每个帧数映射
到特征维度中,形成批次和时序的高维度信息,再进行全连接层和softmax层;
(3)整合两个算法到Flask框架中,这是唇语识别首次应用到web框架中,通过设计路由和URL,配合视图函数
对预测算法进行方法调用,让系统可视化更加合理;
(4)对视频流进行预测,充分利用3D模型的优点对唇语视频进行翻译,从视频读取到切帧,最后传入网络中对
图像包含的唇语信息进行相关的解码,达到端到端的识别效果。
五、 文章目录
目录
1 绪论1
1.1研究背景与意义1
1.2国内外研究现状2
1.3论文结构与安排4 2 项目技术理论6
2.1残差网络ResNet6
2.2门控循环单元GRU7
2.3目标检测Yolo算法8
2.4轻量级web框架Flask9
2.5本章小结9 3 项目分析与技术路线10
3.1项目分析10
3.2项目技术路线11
3.3本章小结13 4 项目设计与实现14
4.1用户登录与注册14
4.2唇语识别技术实现15
4.2.1 唇部检测切割15
4.2.2 数据预处理18
4.2.3 网络模型数据处理19
4.2.4 数据训练与测试21
4.3算法与系统框架整合23
4.4本章小结24 5 结果展示与分析25
5.1系统功能展示25
5.2唇语测试分析26
5.3本章小结26 6 总结与展望27
6.1总结27
6.2展望27 参考文献29 致谢31
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!