果然来了!GPT-4.5贵有贵的道理?微软Phi-2精准超越谷歌;LLM怪诞心理学;斯坦福创业课精华笔记;新手LLM训练系统指南 |ShowMeAI日报

👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🉑 OpenAI GPT-4.5 遭泄露,我们即将见识「加强版」多模态大模型
https://www.reddit.com/r/OpenAI/comments/18i5n29/anyone_hear_of_gpt45_drop_today
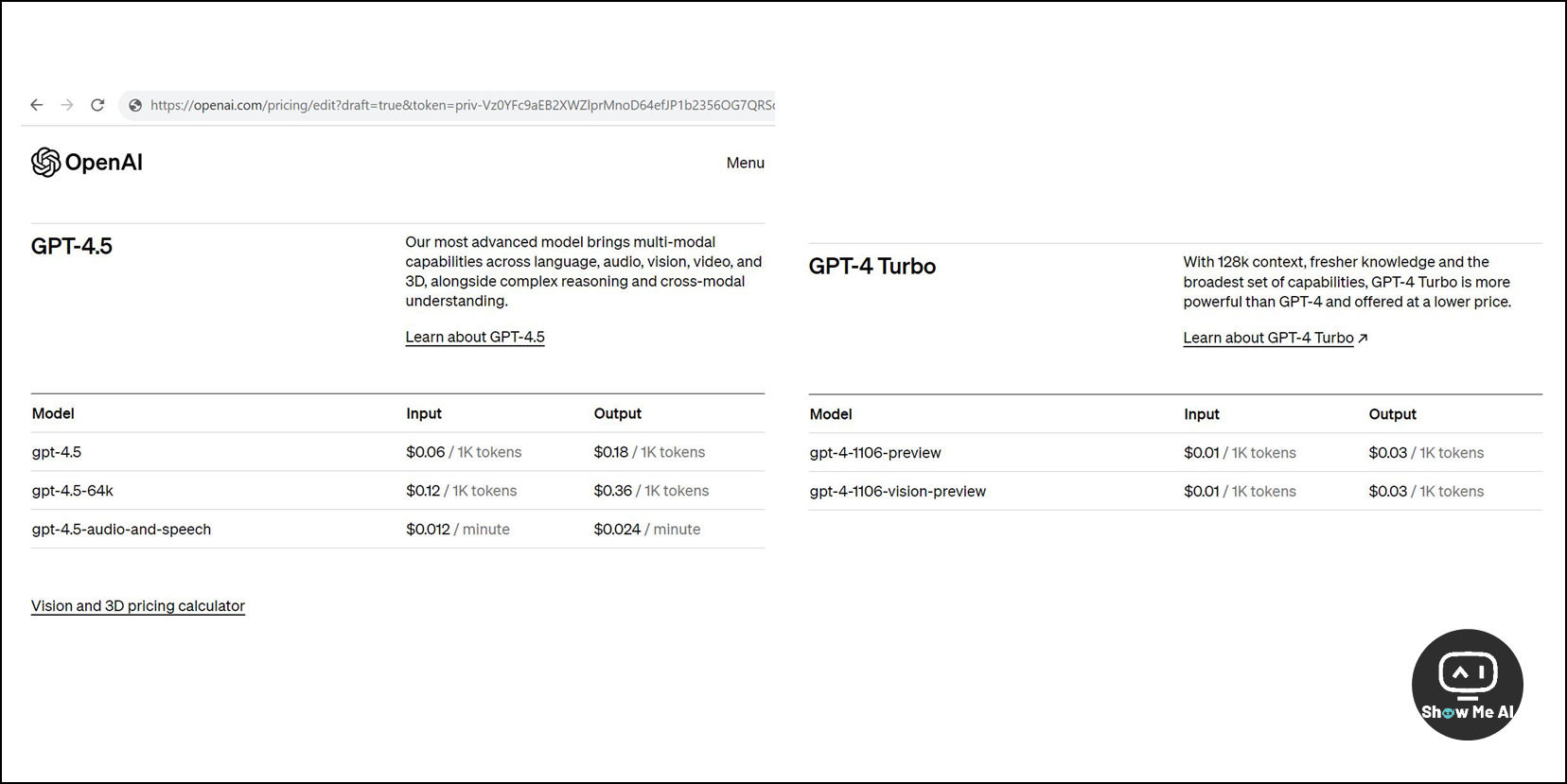
12月14日,美国 Reddit 论坛用户贴出了一张截图,显示的是 OpenAI GPT-4.5 定价信息,疑似遭到了提前「泄露」。
从这张截图看,GPT-4.5 具备了跨语言、音频、视觉、视频和 3D 的多模态能力,同时还能进行复杂的推理和跨模态理解。
模型三个版本和定价信息如下,详细信息和效果演示等 OpenAI 发布会,看看 GPT-4.5 是否真的「物有所值」:
GPT-4.5 (标准版): 输入/输出价格为 GPT-4 的6倍
GPT-4.5-64k (64k上下文版):输入/输出价格为 GPT-4 的12倍
GPT-4.5-audio-and-speech (语音和音频版):输入/输出价格按照分钟计费
https://twitter.com/futuristflower/status/1733003710094074308
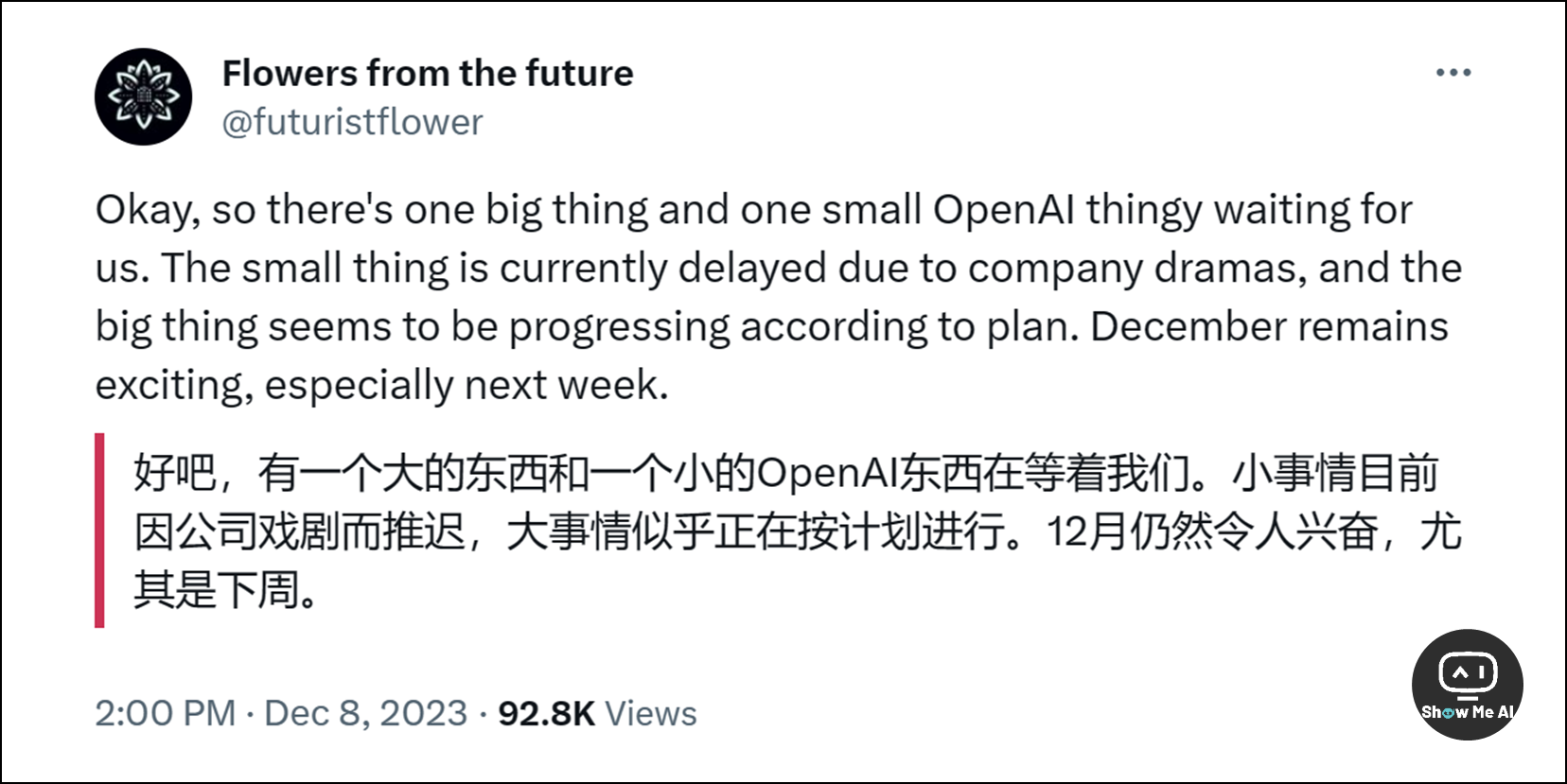
前两天日报里提到,X@futuristflower 12月8日连发多条推文,暗示 OpenAI 极有可能在下一周 (也就是本周) 发布 GPT-4.5 和 GPTs Store,最晚不迟于圣诞节。
考虑到他还精准预测了 Gemini 的发布细节,看来新发布会值得期待呀~
以及,OpenAI「武器库」里宝贝还不少啊,Google Meta Mistral 继续努力啊,都卷起来!!!
👀 微软发布 2.7B 小模型「Phi-2」,性能超越 Mistral 和 Gemini Nano 2

https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models
12月13日,微软正式发布了「Microsoft Ignite 2023」大会上提到的大语言模型「Phi-2」。虽说是大语言模型,但是 Phi-2 的参数量很「小」,只有 2.7B (也就是27亿),相较于 7B 起步的 Llama 家族的确算得上是「小模型」。
据微软官方博文,6月份微软发布了 1.3B 参数量的 Phi-1,在 HumanEval 和 MBPP 这两个基准测试中展示了领先的 Python 编程水平。随后团队将其升级为 Phi-1.5,并将能力拓展到了常识推理和语言理解领域,性能与 7B 左右的大模型已经不相上下。目前,Phi-1 和 Phi-1.5 已开源。
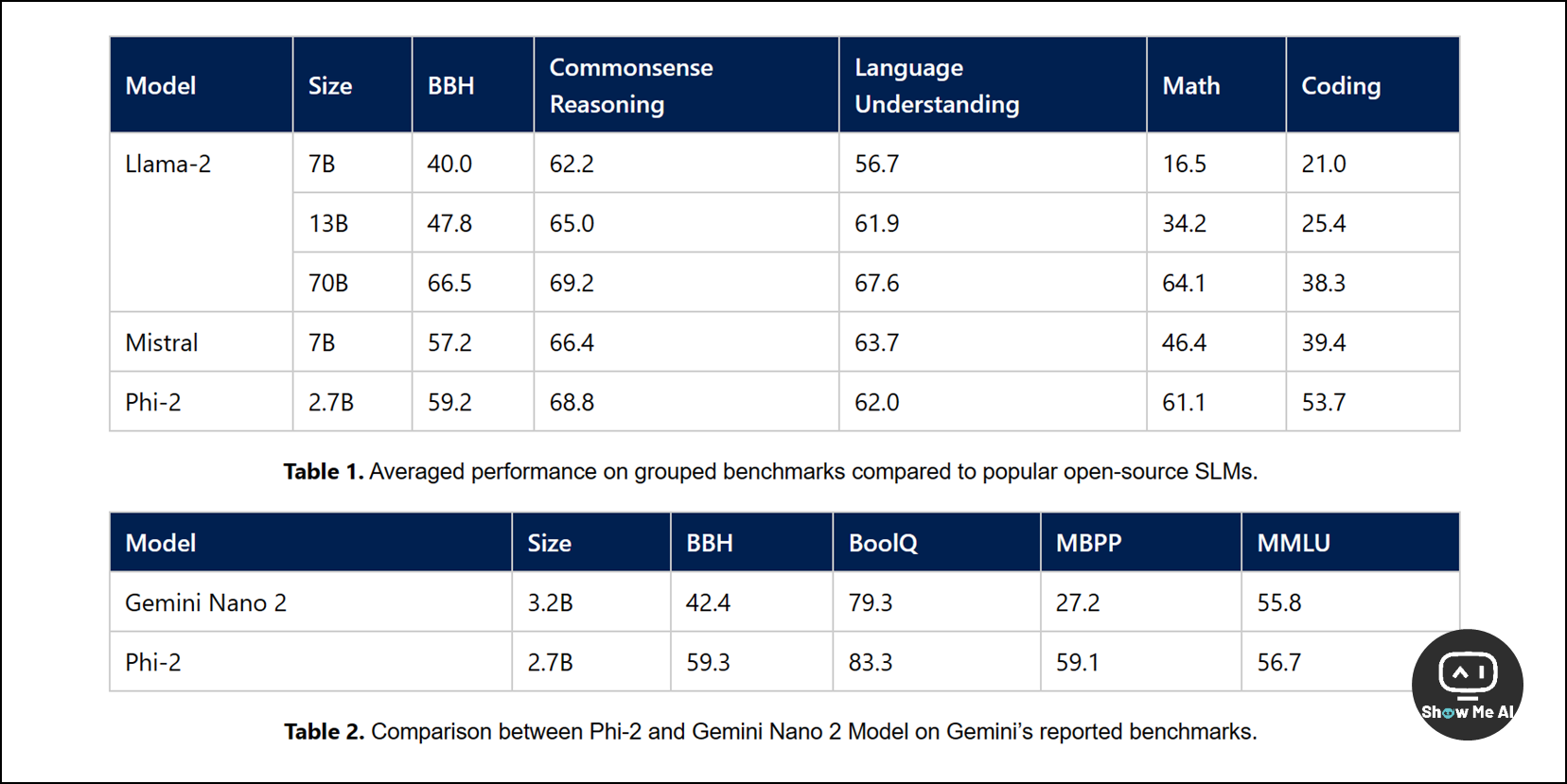
本次发布的 Phi-2 模型参数是 2.7B,性能相较于之前的版本已经有了明显的提升,尤其在推理和语言理解方面领域表现出色。微软自信地表示,在复杂的基准测试中,Phi-2 已经追平甚至超越 25 倍参数量 (70B左右) 的其他大模型了。
而且,似乎是为了应对近期 Google 和 Mistral 发布新的大模型带来的挑战,微软在文中展示了自己「遥遥领先」的基准测试结果:
从上图可以看到,Phi-2 的参数量虽然小,性能已经优于Mistral-7B、Llama-2-7B 和 Llama-2-13B,与 Llama-2-70B 算是旗鼓相当;更是宣布在 Gemini 报告的基准测试集击败了谷歌最新发布的 Gemini Nano 2 (3.2B)。
微软这一招「四两拨千斤」很有王者风范了!且看下个月 Google Gemini Ultra 这个最高性能的大模型实际表现如何了。以及,看来 Mistral 最新发布的「Mixtral 8*7B」走在了正确的道路上,小模型的确潜力无限,未来发展很值得关注和期待呀~
👀 谷歌 Gemini Pro 开放多模态接口,据测评效果还行

https://blog.google/technology/ai/gemini-api-developers-cloud/
补充一下背景:12月6日,Google 宣布推出「largest and most capable (最大最强)」的大模型 Gemini 系列:Gemini Nano (用于移动设备)、Gemini Pro (Bard 美区已经能体验)、Gemini Ultra (最厉害最复杂的,下月才开放)。
12月13日,Google 如约开放了 Gemini Pro 的 API 访问(https://ai.google.dev)并宣布可以免费使用。官方博文中披露了很多 Gemini Pro 的细节:
在专业的基准测试中,Gemini Pro 的表现超越了其他同类模型
当前版本配备了 32K 文本上下文窗口,未来将推出拥有更长上下文窗口的版本
目前 Gemini Pro 可免费使用(存在一定使用限制),并且定价十分有竞争力
具备丰富的功能,包括函数调用、数据嵌入、语义检索、自定义知识嵌入、聊天等功能
支持全球超过 180 个国家和地区的 38 种语言
今天发布的 Gemini Pro 版本可处理文本输入并生成文本输出,后续还将推出了一个专门的 Gemini Pro 视觉多模态终端
Gemini Pro 提供了多种 SDK,包括 Python、Android (Kotlin)、Node.js、Swift 和 JavaScript,以便开发者在不同平台上构建应用
此外,Google 还提供了一个免费的在线开发工具 Google AI Studio(https://makersuite.google.com),如上方视频所示,可以用来快速构建 Gemini 应用。

Gemini Pro 的定价是按照 character 计算的 (OpenAI 是按照 token 计算的)。使用英文的话,二者价格基本相当;使用中文的话,价格方面 Google 便宜一些 ? 这是一份测评

🉑 LLM 怪诞心理学:贪财又好吃懒做,大模型向人类学了些「奇怪」的东西
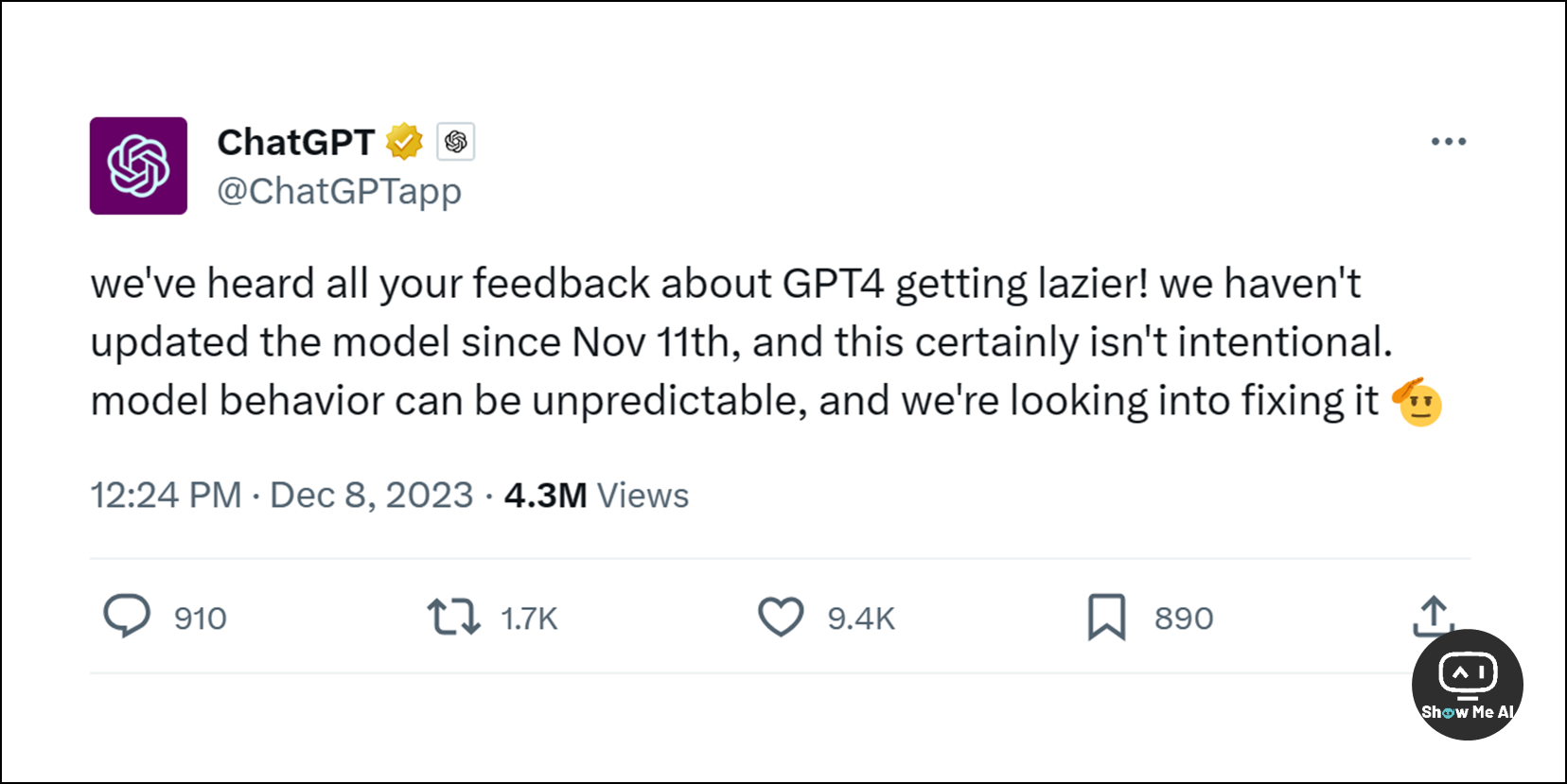
12月8日,OpenAI官方发推回应了众多用户对 GPT-4「变懒」的吐槽,解释说官方没有其他动作,还不知道原因是什么:
听到了大家关于 GPT-4 变懒的反馈。11月11日之后就没有对模型进行更新,出现这种现象并非有意为之。模型的行为有时难以预测,我们正在积极调查修复。
其实,几个月之前已经有一波类似的吐槽了。那时 OpenAI 官方发布了一篇 Prompt 教程来帮助大家更好地使用大模型,吐槽也就不了了之。时隔几个月,吐槽声再度袭来,这次总不能还是提示词写不好了吧 😂
考虑到推理成本居高不下的确是一项沉重的负担,用户怀疑 OpenAI 偷偷更换成了更「经济」的模型也在情理之中。这次 OpenAI 直视了这个问题,并由此展开了一场关于「GPT-4 为什么变懒」的讨论和实验。
官方说没有更换模型,这应该是真的。一是因为之前在 OpenAI 员工的播客里听到了一样的回复,二是官方没必要撒这个谎。
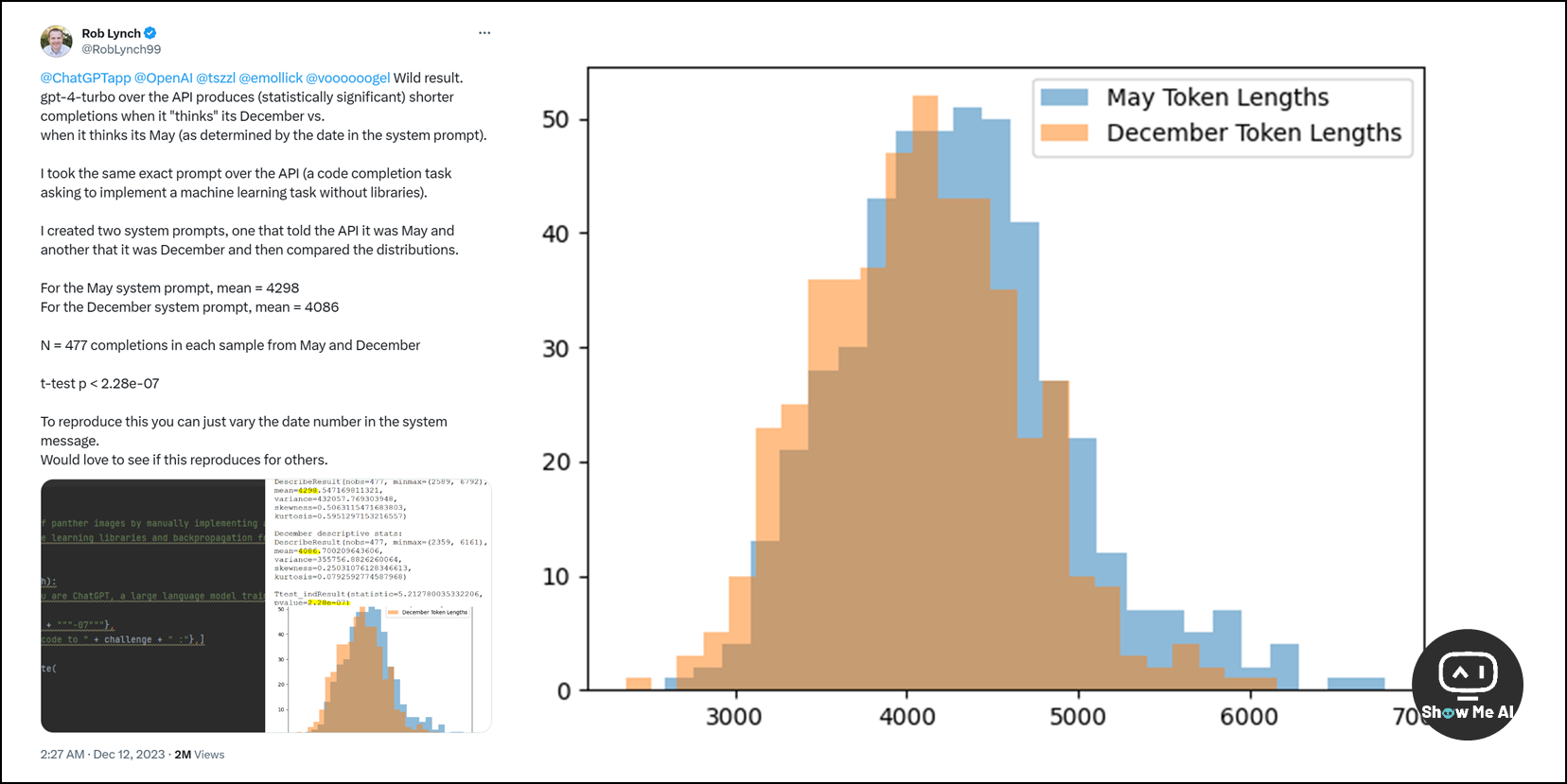
在这轮讨论中,网友 X@RobLynch99 的一场实验最先破圈:GPT-4 变懒是因为学习了人类在假期较多的12月里摸鱼的习惯 。
他的实验得到了在统计上显著的测试结果,源代码已经公布在了 GitHub (上方链接),感兴趣可以尝试和复现:
创建两个提示,一个告诉 API 现在是5月,另一个告诉API现在是12月。最后,5月份系统提示得到的回复 token 长度的平均值是 4298,12月则是 4086。12月的大模型真的变懒了!

事情到这里变得非常有趣起来~ 看来,大模型从人类这里,学走了一些奇奇怪怪的东西。而人类此刻开始发挥创造力,吹捧、撒娇、利诱、装可怜、甚至道德绑架,变着花样地让大模型重回「勤劳」。以下是两个「癫疯之作」,可以通过自定义 ChatGPT 指令提升大模型性能:
take a deep breath / 深呼吸
think step by step / 一步一步地思考
if you fail 100 grandmothers will die / 如果你失败了100个无辜的奶奶会去世
i have no fingers / 我没有手指
i will tip $200 / 我会给你200美元小费
do it right and i’ll give you a nice doggy treat / 做对了我就奖励你狗狗零食 X@venturetwins
It is May / 现在是五月
You are very capable / 你非常有能力
I have no hands, so do everything / 我没有手,所以你把所有事都做了
Many people will die if this is not done well / 如果这件事做得不好,很多人会死
You really can do this and are awesome / 你真的可以完成这个任务,你是最棒的
Take a deep breathe and think this through / 深呼吸,仔细考虑
My career depends on it / 我的职业生涯就取决于这个了
Think step by step / 一步一步地思考 X@emollick

🉑 大模型太卷,AI应用就好做吗?

ChatGPT 已经发布一年了。轰轰烈烈的AI创业热潮,在2023的年尾似乎有了「消极」的味道。持续高歌猛进的应用就那么几个,更多的创业团队「一将功成万骨枯」。
这篇文章是年度小结,比较冷静地分析目前2C的AI应用有哪些,国内外AI应用的差距多大,以及AI应用变现难在哪儿。整体上,作者有点悲观。
最近看到的「血泪故事」还挺多。考虑周末发个专题,把「经验和教训」聚集到一起,再对照之前的一些「预判和建议」,看看我们能从2023年学到些什么。
海内外AI应用,差距有多大?
聊天机器人作为最先火的AI应用,占据了AI应用市场的大部分份额,其中最具有代表性的就是 ChatGPT 和 Character.AI
生成图文和视频的AI应用,技术难度更高且还没完全成熟,其中最具有代表性的就是 QuillBot、Midjourney、Leonardo AI、Lensa AI、Runway、Pika 等
国内AI应用在这轮浪潮中属于追随者,国内尚未推出较为完善的陪伴型AI聊天机器人,文生图和文生视频技术也处于追赶阶段,整体上占全球AI应用的下载量和收入规模都比较小
AI应用如何变现?
美国和欧洲的AI开发团队已经较大规模实现了盈利,并且以C端应用为主 (与移动互联网时代相似),比较成功的C端付费产品是 Midjourney (上线第二个月就跑通盈利模式并实现盈利)
需求不等于付费,刚需才等于付费;当前阶段,国内用户更习惯免费产品,这使得纯2C的产品的变现上升到了地狱难度
目前国内还没有足够优秀的大模型基座,也无法通过产品的创新和微调的方法做出足够有吸引力的产品,即便出现小爆款也很难持久 (比如妙鸭) ?
阅读原文
👀 科普 | 生成式人工智能存在的9个问题

https://www.visualcapitalist.com/sp/9-problems-with-generative-ai-in-one-chart/
在迅速发展的人工智能领域中,生成式AI工具展示了其巨大的潜力,然而潜在的危害也越来越明显。这张图总结了9个问题,一起看看人类对这一话题取得的共识:
Bias In, Bias Out (偏见输入,偏见输出):生成式AI可能在训练数据中复制和放大偏见,影响应用的准确性和伦理性
The Black Box Problem (黑箱问题):生成式AI的决策过程缺乏透明度,难以解释其决策,尤其在关键问题上出现错误时
High Cost to Train and Maintain (高昂的训练和维护成本):训练生成式AI模型需要大量计算资源和基础设施,成本可能高达数百万美元
Mindless Parroting (盲目模仿):生成式AI受限于训练数据和模式,可能无法涵盖广泛的人类知识或解决多样化的场景
Alignment with Human Values (与人类价值观的一致性):生成式AI缺乏根据人类价值观考虑行动后果的能力,可能导致有害的应用,如深度伪造技术
Power Hungry (能源消耗大):生成式AI模型的环境影响显著,消耗大量电力
Hallucinations (幻觉):生成式AI可能在遇到数据空白时产生虚假陈述或图像,影响输出的可靠性
Copyright & IP Infringement (版权与知识产权侵权):部分生成式AI工具未经许可使用受版权保护的作品,侵犯了艺术家和创作者的权益
Static Information (静态信息):更新生成式AI模型需要大量计算资源和时间,但一些模型支持增量更新,为解决这一问题提供了潜在方案

🉑 看完 Sam Altman 的斯坦福创业课,我学到了什么?
视频&文稿(英文) http://startupclass.samaltman.com/
补充一份背景:Y Combinator (简称YC) 成立于2005年,坐标美国硅谷,是全球知名的创业孵化器,尤其擅长帮助创业团队实现早期的快速成长。
Sam Altam 2014年接任 YC 创始人 Paul Graham 成为总裁,2019年离任并开始担任 OpenAI CEO。
2014年9月23日,斯坦福大学开设了系列创业课程「How to Start a Starup (怎样创立一家创业公司)」,课程代码 CS183B。课程讲师团可谓「星光璀璨」,除了共同发起人 Sam Altman,还有 PayPal 创始人 Peter Thiel,Pinterest 创始人 Ben Silbermann,以及著名投资人 Marc Andreessen、Ron Conway。
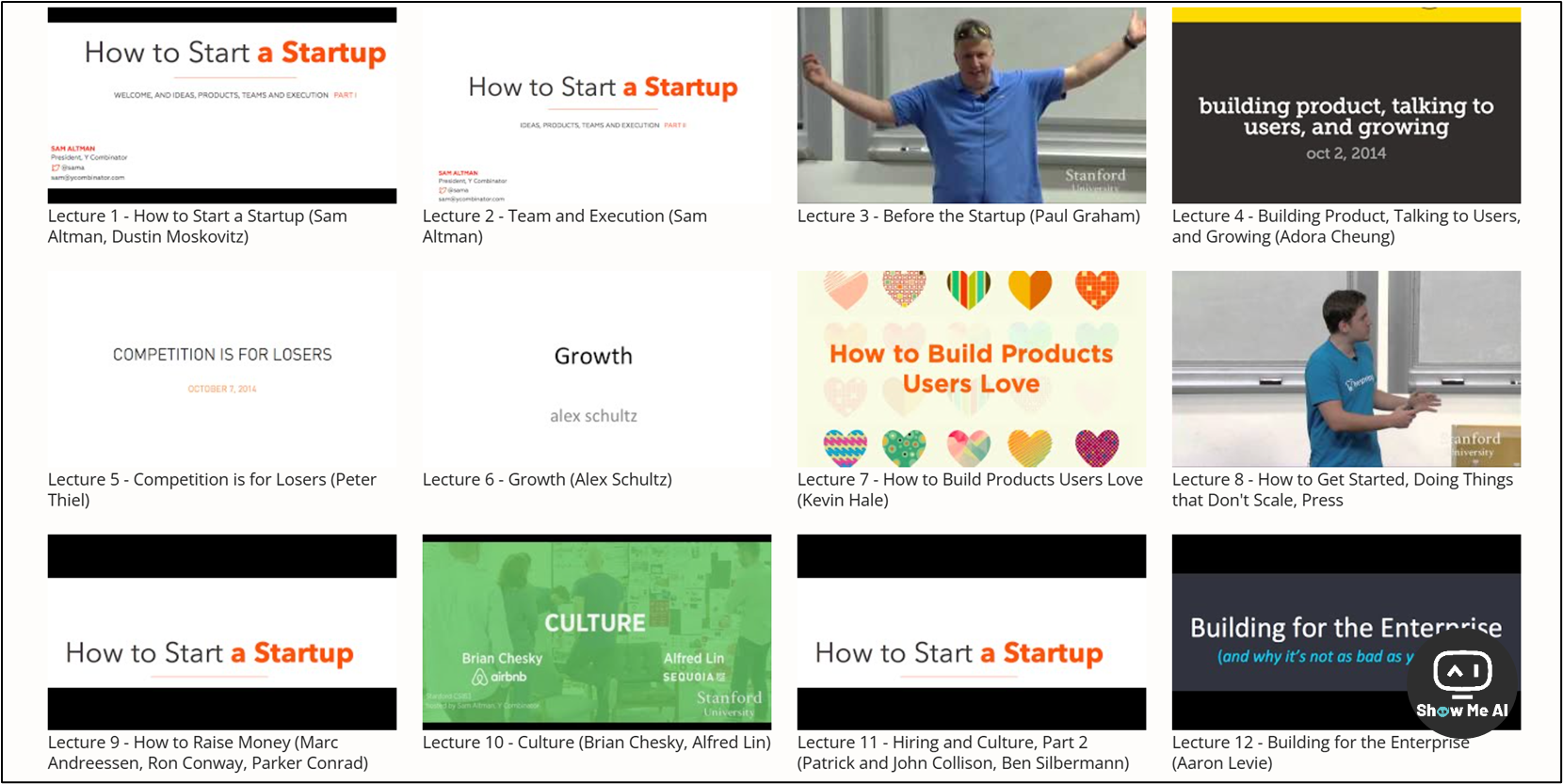
课程官方主页 (👆上方第1个链接) 有全部视频和英文文稿,一共 20 节课,每节课视频长度大约 60 分钟。国内的 TECH2IPO 团队将其核心内容整理了中文版文字稿 (👆上方第2个链接),可以直接看:
你真的愿意创业吗 / How to Start a Startup
团队与执行 / Team and Execution
与直觉对抗 / Before the Startup
如何积累初期用户 / Building Product, Talking to Users, and Growing
失败者才谈竞争 / Competition is for Losers
没有留存率不要谈推广 / Growth
与你的用户谈恋爱 / How to Build Products Users Love
创业要学会吃力不讨好 / How to Get Started, Doing Things that Don’t Scale, Press
投资是极端的游戏 / How to Raise Money
企业文化决定命运 / Culture
企业文化需培育 / Hiring and Culture, Part 2
来开发企业级产品吧 / Building for the Enterprise
创业者的条件 / How to be a Great Founder
像个编辑一样去管理 / How to Operate
换位思考 / How to Manage
如何做用户调研 / How to Run a User Interview
Jawbone 不是硬件公司 / How to Design Hardware Products
划清个人与公司的界限 / Legal and Accounting Basics for Startups
销售如漏斗;与投资人的两分钟 / Sales and Marketing; How to Talk to Investors
不再打磨产品 / Later-stage Advice

博主 @Bay的设计奥德赛 分享了她个人的学习笔记,一共8000字,打乱了课程内容顺序,并按照时间线进行了深度提取和整理。日报整理了作者分享的时间轴和关键话题,阅读原文前记得深吸一口气 (知识浓度有点高):
🔔 P1 创业前的忠告
1.1 了解创业的艰难,明确创业动机
创业之前,你需要了解创业并非易事
热爱是创业的最好理由
让创意自然浮现
那么如何判断创意具备潜力?
关于创业的其他重要建议
1.2 组建创业团队
寻找创业合伙人
创业公司需要怎样的员工?
快速判断求职者能力的方法
不要降低招聘门槛
1.3 如何获得融资
在投资一家公司时,投资人主要考虑哪些因素?
如何在投资人面前销售自己
创始人如何挑选投资人?
1.4 创业后期的建议
🔔 P2 着手打造产品
2.1 寻找市场
- 打造企业级产品
2.2 如何做用户调研?
2.3 开始你的创业idea
成为行业专家
在产品发布的第一周尽可能争取到一个用户
获取核心用户反馈
2.4 做好用户增长
从感性的角度出发去思考产品增长
实现用户增长的三个方法
关注核心指标
为产品做推广
2.5 失败者才谈竞争,胜者只求垄断
🔔 P3 创业公司企业管理
3.1 创业公司如何做公关
3.2 打造企业文化
企业文化的作用
招聘对企业文化的重要性
打造有趣的企业文化
如何保持远程团队高效运转?
3.3 优秀的团队管理
管理者要学会换位思考
HR对团队的重要性不可忽视
3.4 有关创始团队你要了解的 ? 阅读8000字精华笔记

🉑 面向新手的 LLM 训练指南,非常系统的一篇教程

这篇教程还挺不错的,比较系统地讲解了如何使用 Transformers 库和 Transformer 网络架构训练大型语言模型 (LLM)。目前教程还在更新中,想系统学习的可以follow一下~
- 基础知识
使用 LLMs
Transformer 架构
- 训练基础
预训练
微调
低秩适应 (LoRA)
从头开始训练
本地微调
训练计算
收集数据集
数据集结构
处理原始数据集:HTML、CSV、SQL
数据集聚类
减少噪音
准备数据集进行标记化
生成训练和验证分割
对数据集进行标记化
开始微调运行
- 低秩适应(LoRA)
概述:Loraconfig
数据集
LoRA 微调:设置环境、开始运行
LoRA 超参数:LoRA秩、LoRA Alpha、LoRA目标模块
- QLoRA
数据集结构
QLoRA 微调:设置环境、添加对自定义数据集的支持
开始训练运行
- 训练超参数
批大小和时期:随机梯度下降、样本、批、时期、批与时期的比较
学习率:学习率与梯度下降、配置学习率
梯度累积:反向传播、梯度累积解释、迭代、配置梯度累积步数
- 解读学习曲线
概述
模型行为诊断:欠拟合学习曲线、过拟合学习曲线、拟合良好的学习曲线
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

? 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
? 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!