一文彻底掌握浮点数
经典问题
0.1 + 0.2 = ?
我们写个 Go 程序来测试一下:
func main() {
var f1 float64 = 0.1
var f2 float64 = 0.2
fmt.Println(f1+f2 == 0.3)
fmt.Println(f1 + f2)
}
输出:
false
0.30000000000000004
如此违背 “常识” 的结果,其实是因为当下计算机体系中小数的表示方式是浮点数,而计算机中对浮点数的表示并非百分百精确的,在表示和计算过程中都有可能会丢失精度。
这迫使必须深入理解浮点数在计算机中的存储方式及性质,才能正确处理关于数字的计算问题。
结论先行
定点数
要理解浮点数的第一步是考虑含有小数值的二进制数字。在这之前,我们来看看更加熟悉的十进制表示法:
d
m
d
m
?
1
?
?
?
d
1
d
0
.
d
?
1
d
?
2
?
?
?
d
?
n
d_md_{m-1} ··· d_1d_0 . d_{-1}d_{-2}··· d_{-n}
dm?dm?1????d1?d0?.d?1?d?2????d?n?
小数点 . 左边是整数部分,右边是小数部分。其中每个十进制数 di 的取值范围是 0~9。
如十进制的 12.34 即可以表示为:
1
×
1
0
1
+
2
×
1
0
0
+
3
×
1
0
?
1
+
4
×
1
0
?
2
1×10^1+2×10^0+3×10^{-1}+4×10^{-2}
1×101+2×100+3×10?1+4×10?2
那其实二进制也是一样的道理,只不过把其中的 10 换成 2,而 di 的取值范围为 0~1。
如二进制的 101.11 可以表示为:
1
×
2
2
+
0
×
2
1
+
1
×
2
0
+
1
×
2
?
1
+
1
×
2
?
2
1×2^2+0×2^1+1×2^0+1×2^{-1}+1×2^{-2}
1×22+0×21+1×20+1×2?1+1×2?2
如果我们仅考虑有限长度的编码,那么十进制表示法不能准确表达像 1/3 和 5/7 这样的数。类似的,小数的二进制表示法只能表示那些能够被写成以下形式的数:
x
×
2
y
x × 2^y
x×2y
其他的值就只能近似地表示。
定点数的整数部分是小数部分的位数是固定不变的,在位数有限的情况下,定点数的取值范围和精度都比较差。于是就有了 IEEE-754 提出的浮点数表示法。
浮点数
所谓“浮点数”(Floating-point numbers),即小数点可以“浮动”,即小数点的位置不是固定的,而是可以根据数值的大小和精度需求移动的。这种表示法允许在广泛的范围内表示数值,同时保持相对恒定的精度。
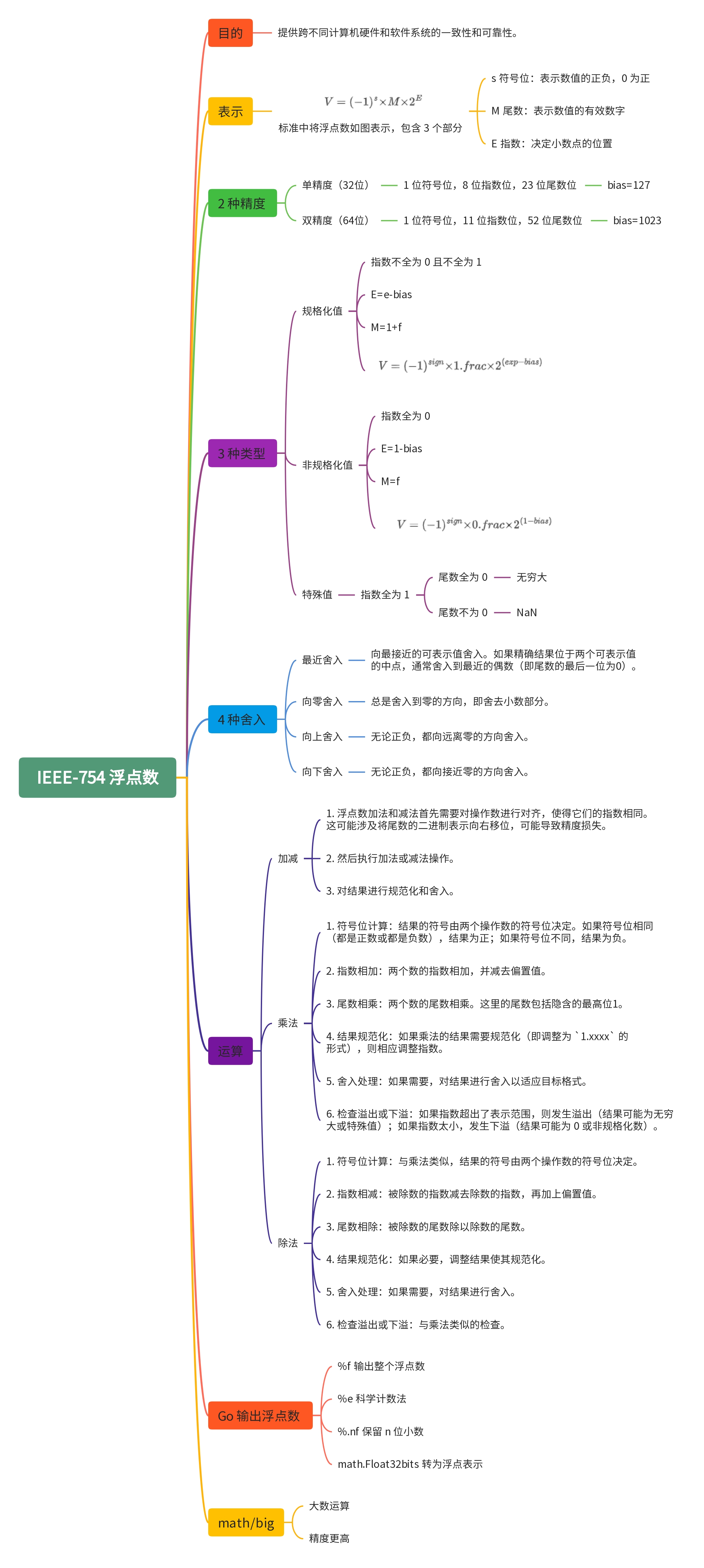
在计算机中,浮点数通常遵循 IEEE-754 标准。这个标准定义了浮点数的存储和运算方式,确保了不同计算机系统之间的一致性。IEEE-754 用以下形式来表示一个数:
V
=
(
?
1
)
s
×
M
×
2
E
V = (-1)^s×M×2^E
V=(?1)s×M×2E
其中:
- s 符号位(Sign bit):表示数值的正负。
- M 尾数(Mantissa):表示数值的有效数字。
- E 指数(Exponent):决定小数点的位置。
IEEE-754 将浮点数的位表示划分成三个部分,分别对各个部分进行编码,对应上面公式右边的 3 个字母:
- 一个单独的符号位
s直接编码符号s。 -
k
k
k 位的阶码字段
e
x
p
=
e
k
?
1
?
e
1
e
0
exp=e_{k-1}\cdots e_1e_0
exp=ek?1??e1?e0? 编码阶码
E。 -
n
n
n 位小数字段
f
r
a
c
=
f
n
?
1
?
f
1
f
0
frac=f_{n-1}\cdots f_1f_0
frac=fn?1??f1?f0? 编码尾数
M,但是编码出来的值也依赖于阶码字段的值是否等于 0。
在 IEEE-754 标准中,定义了两种精度的浮点数,分别是单精度浮点数(32 位)和双精度浮点数(64 位)。
单精度:
- 1 位符号位 s
- 8 位指数 exp
- 23 位尾数 frac

双精度:
- 1 位符号位 s
- 11 位指数 exp
- 52 位尾数 frac
根据 exp 的值,浮点数又可以分成三类:
- 规格化的
- 非规格化的
- 特殊的
其中第三类“特殊的”又可以根据 frac 分成两类:
- 无穷大
- 不是一个数 NaN(Not a Number)
具体如下表所示:
| exp | frac | |
|---|---|---|
| 规格化的 | ≠0 & ≠ 255 | f |
| 非规格化的 | 0 | f |
| 特殊的 | 1 | f |
| - 无穷大 | 1 | 0 |
| - NaN | 1 | ≠0 |
对于不同类型的浮点数,在计算公式
V
=
(
?
1
)
s
×
M
×
2
E
V=(-1)^s×M×2^E
V=(?1)s×M×2E 中,exp -> E 和 frac -> M 的方式有所不同。
下面我们来对这几种不同类型进行详细讨论,其中不乏有一些很有趣且充满智慧的设计理念。
特殊值 Special Values
- 指数部分:全为 0。
- 尾数部分:全为 0 则表示无穷大,不全为 0 则表示 NaN。
- 作用:特殊值用于表示那些无法用常规数值表示的情况,如无穷大、非数(NaN)等。这些值通常用于操作的错误或特殊情况的结果,如除以0、无效操作等。
规格化的值 Normalize Values
- 指数部分:不全为 0 且不全为 1。
- 尾数部分:可以是任意值。
- 作用:用于表示大多数非零数值
在规格化值中:
- E = e ? b i a s E=e-bias E=e?bias
- M = 1 + f M=1+f M=1+f
其中 e 即为 exp,,bias 是偏置量,它的值为
2
k
?
1
?
1
2^{k-1} -1
2k?1?1,其中 k 为 exp 的位数,故:
- 在单精度中, b i a s = 2 8 ? 1 ? 1 = 2 7 ? 1 = 128 ? 1 = 127 bias=2^{8-1}-1=2^7-1=128-1=127 bias=28?1?1=27?1=128?1=127
- 在双精度中, b i a s = 2 11 ? 1 ? 1 = 2 10 ? 1 = 1024 ? 1 = 1023 bias=2^{11-1}-1=2^{10}-1=1024-1=1023 bias=211?1?1=210?1=1024?1=1023
其中 f 为 frac 表示的数,范围
0
≤
f
<
1
0≤f<1
0≤f<1。
所以一个规格化数,具体可以表示为:
V
=
(
?
1
)
s
i
g
n
×
1.
f
r
a
c
×
2
(
e
x
p
?
b
i
a
s
)
V=(-1)^{sign}×1.frac×2^{(exp-bias)}
V=(?1)sign×1.frac×2(exp?bias)
这里有 4个问题:
- 这个
bias是什么? - 为什么
E要e去减掉一个bias? bias的值是怎么定下的,如单精度为什么是 127,不是 126 或 128?M为什么需要f去加上一个1?
下面我们来对这 4 个问题进行一一解答。
第 1 个问题,这个 bias 是什么?
bias是一个预设的偏移量,用于将指数部分的值偏移到全正数,从而简化处理。
第 2 个问题:为什么 E 要 e 去减去一个 bias?
先说结论:使用 bias(偏置指数,biased exponent)可以允许浮点数以统一的方式表示,同时也使得浮点数的排序和比较变得简单。
首先指数肯定得支持正负形式的出现,那么直接使用无符号整型来表示指数肯定是不行的,因为它无法表示负指数。暂时先抛开 IEEE-754 定下的标准,我们可以尝试用补码来表示指数。
假设我们有两个 32 位的浮点数 A 和 B,并且我们假设它们的指数部分使用 8 位二进制补码表示(这与 IEEE-754 标准不同)。
A的二进制表示:0 0000010 00000000000000000000000B的二进制表示:0 1111110 00000000000000000000000
在这里,第一位是符号位(0 表示正数),接下来的 8 位是以补码形式表示的指数,剩下的 23 位是尾数。
我们想要比较这两个数的大小,需要怎么做呢?
我们先解析这 2 个数:
- 符号位:对于
A和B,符号位都是0,表示这是两个正数。 - 指数部分(使用补码表示)
A的指数为0000010,解读为正数 +2。B的指数为1111110,在补码表示中,这是一个负数。先加 1 后取反转换为正数00000010,它表示 -2。
要比较这 2 个数:
- 当我们比较
A和B时,首先需要考虑它们的指数。 - 指数
A为 +2,而B为 -2。即使它们的尾数部分相同(在这个例子中都是0),A的实际值要大于B,因为正指数表示的数值范围远大于负指数。
可以看出:使用补码表示指数增加了比较过程的复杂性,因为我们需要解读补码并考虑其正负。特别是在涉及到负指数的情况下,我们不能仅仅比较二进制表示的大小,而必须将补码转换为实际的数值,然后再进行比较。
现在回过头来看看 IEEE-754 的设计,假设我们有两个单精度(32位)浮点数 A 和 B:
A的二进制表示为:0 10000010 00000000000000000000000B的二进制表示为:0 01111110 00000000000000000000000
解析这两个数:
A:符号位为 0(正数),指数部分为10000010(二进制,对应十进制的 130),尾数部分为全 0。B:符号位为 0(正数),指数部分为01111110(二进制,对应十进制的 126),尾数部分为全 0。
计算实际指数值:单精度浮点数的偏置值 bias 为 127,故:
A的实际指数E = 130 - 127 = 3。B的实际指数E = 126 - 127 = -1。
比较这两个数:
- 在减去
bias后,我们可以直接比较指数部分的二进制表示来确定数值的大小。 - 由于
10000010(130)大于01111110(126),因此我们可以直接得出A大于B,而无需考虑负指数的复杂表示问题。
这个例子说明了通过减去偏置值,IEEE-754 标准能够简化浮点数的比较和排序操作。偏置后的指数表示方法允许计算机以统一和高效的方式处理浮点数,无论它们的实际数值大小如何。
第 3 个问题:bias 的值是怎么定下的,如单精度为什么是 127,而不是 126 或 128?
bias值的选择,是为了平衡正负指数的表示范围,并且充分利用指数部分的存储空间。
以单精度为例,exp 占了 8 位,8 位二进制可以表示的值的范围是
[
0
,
255
]
[0,255]
[0,255]。如果我们选择 127 作为 bias,则存储的指数范围就是
[
?
127
,
128
]
[-127,128]
[?127,128]。这样可以使得指数部分可以均匀地表示从负大数到正大数的范围(对称)。
在 IEEE-754 标准中,全 0 的指数表示为非规格化数或 0,而全 1 的指数用于表示无穷大或 NaN)。选择 127 作为 bias 可以在保留这些特殊值的同时,提供最大的有效指数范围。
第 4 个问题:M 为什么需要 f 去加上一个 1?
在规格化数中隐含最高位 1 是为了提高尾数部分的表示效率,从而增加精度。
其实这跟科学计数法的很像的,为了确保浮点数表示的唯一性,IEEE-754 规定规格化浮点数最高位一定是非零的。如果不规定最高位非零,同一个数可以有多种不同的浮点表示,例如,在二进制中 0.5 可以表示为
1.0
×
2
?
1
1.0×2^{-1}
1.0×2?1,也可以表示位
0.1
×
2
0
0.1×2^0
0.1×20 或
0.01
×
2
1
0.01×2^1
0.01×21 等等。这种多重表示会使浮点运算变得复杂且低效。
那既然最高位总是 1,那就没必要显示存储了,还可以使尾数部分中多 1 位的存储空间,从而允许存储更多的有效数字,以提高精度。
非规格化的值 Denormalized Values
- 指数部分:全为 0。
- 尾数部分:可以是任意值。
- 作用:
- 提供表示数值 0 的方法。因为规格化中 M ≥ 1 M≥1 M≥1,所以无法表示 0。
- 用于表示非常接近于 0 的数值,这些数值太小,无法用规格化格式表示。它们填补了 0 和最小规格化正数之间的间隙,提供了渐近于 0的连续表示,防止了所谓的“下溢”。
在非规格化值中:
- E = 1 ? b i a s E=1-bias E=1?bias
- M = f M=f M=f
所以一个规格化数,具体可以表示为:
V
=
(
?
1
)
s
i
g
n
×
0.
f
r
a
c
×
2
(
1
?
b
i
a
s
)
V=(-1)^{sign}×0.frac×2^{(1-bias)}
V=(?1)sign×0.frac×2(1?bias)
那这里又有 2 个问题了:
- 为什么指数部分不是 0 ? b i a s 0-bias 0?bias 而是 1 ? b i a s 1-bias 1?bias?
- 为什么 M 不需要隐含的 1 了?
第 1 个问题:为什么指数部分不是 0-bias 而是 1-bias?
这是一个特殊的设计,旨在使非规格化数能够平滑地连接到规格化数的最小正值。
最小的规格化数的指数为 1 - bias。为了在数值上平滑地过渡到非规格化数,非规格化数的实际指数也被设定为 1 - bias。这样,非规格化数就可以代表那些小于最小规格化正数的数值,而不会出现一个数值的“间隙”。
第 2 个问题:为什么 M 不需要隐含的 1 了?
不包含隐含的 1 使得非规格化数能够在浮点数表示中填补 0 和最小规格化数之间的空隙,提供对极小数值的连续表示。
- 避免下溢:非规格化数通过允许尾数部分不以隐含的 1 开始(而是以显式的 0 开始),使得它们可以表示比最小规格化数还要小的数值。这对于避免数值下溢至 0 非常重要,尤其是在累积了多次运算后的场合。
- 精度牺牲:使用非规格化数的代价是牺牲了一些精度。由于没有隐含的最高位 1,非规格化数的精度较低。但这是为了在非常小的数值范围内提供数值的连续性所做的必要妥协。
总结
规格化值、非规格化值和特殊值三种类型共同构成了 IEEE-754 浮点数标准的完整表示体系,使得浮点数能够在计算机中有效低处理从非常小到非常大的数值范围,同时还能应对特殊的计算情况。
举例
参考《深入理解计算机系统》,我们以 8 位浮点数为例,其中:
- 1 位符号 s
- 4 位指数 exp
- 3 位尾数 frac
可以算出 b i a s = 2 4 ? 1 ? 1 = 2 3 ? 1 = 8 ? 1 = 7 bias=2^{4-1}-1=2^3-1=8-1=7 bias=24?1?1=23?1=8?1=7。
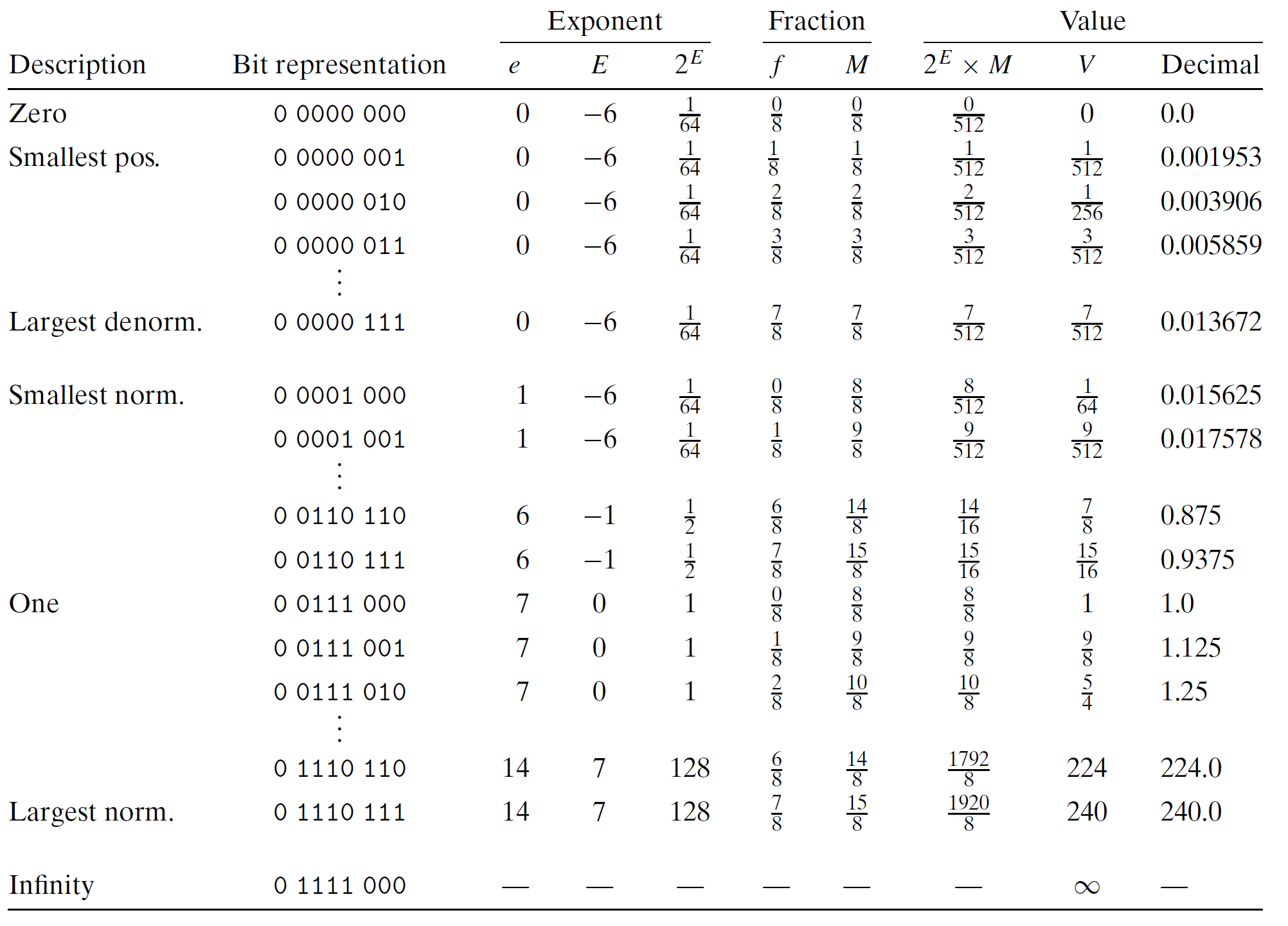
其中靠近 0 的是非规格化值:
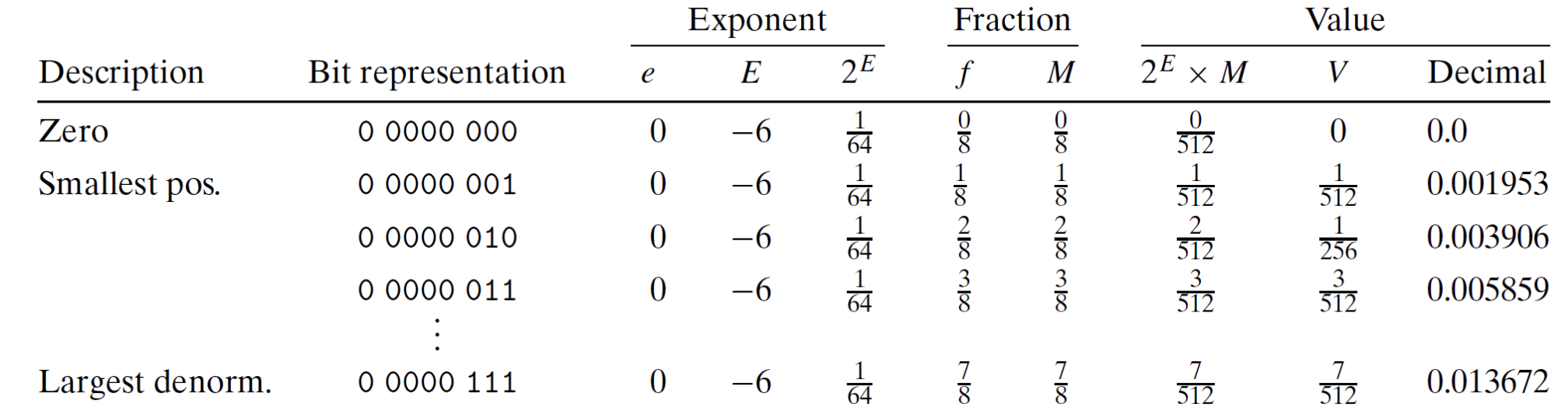
以 0 0000 001 为例:
V
=
(
?
1
)
s
×
M
×
2
E
=
(
?
1
)
s
×
0.
f
r
a
c
×
2
1
?
b
i
a
s
=
(
?
1
)
0
×
(
0
+
(
1
/
8
)
)
×
2
1
?
7
=
1
×
1
/
8
×
2
?
6
=
2
(
?
9
)
=
1
/
512
V = (-1)^s×M×2^E \\ = (-1)^s×0.frac×2^{1-bias} \\ = (-1)^0×(0+(1/8))×2^{1-7} \\ = 1×1/8×2^{-6} \\ =2^{(-9)} \\ = 1/512
V=(?1)s×M×2E=(?1)s×0.frac×21?bias=(?1)0×(0+(1/8))×21?7=1×1/8×2?6=2(?9)=1/512
再往下,就是规格化值:
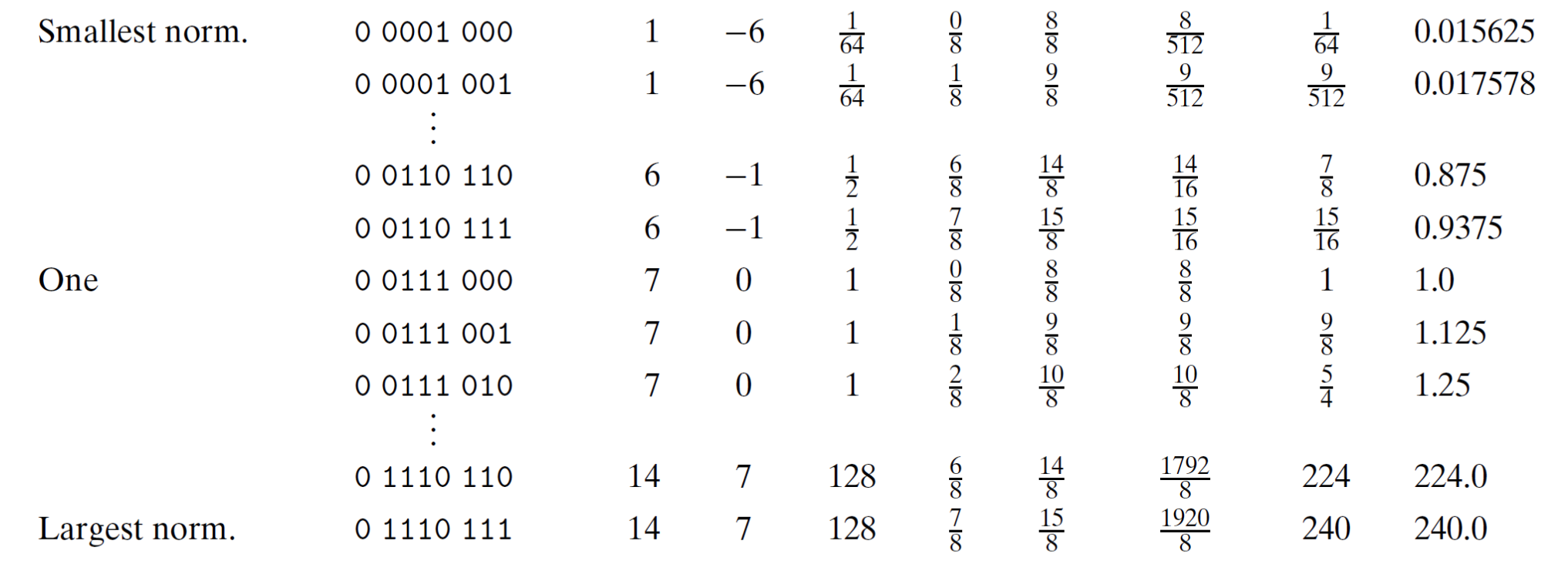
以 0 0110 110 为例:
V
=
(
?
1
)
s
×
M
×
2
E
=
(
?
1
)
s
×
1.
f
r
a
c
×
2
e
?
b
i
a
s
=
(
?
1
)
0
×
(
1
+
6
/
8
)
×
2
6
?
7
=
1
×
14
/
8
×
2
?
1
=
14
/
16
=
7
/
8
V = (-1)^s×M×2^E \\ = (-1)^s×1.frac×2^{e-bias} \\ = (-1)^0×(1+6/8)×2^{6-7} \\ =1×14/8×2^{-1} \\ = 14/16 \\ =7/8
V=(?1)s×M×2E=(?1)s×1.frac×2e?bias=(?1)0×(1+6/8)×26?7=1×14/8×2?1=14/16=7/8
整型转为浮点型
下面以一个例子来直观感受一下一个整型是如何转为浮点型的。
现在我们有一个 int32 的整型 123,我们希望将其转为单精度浮点型 123.0。
1. 将整型用二进制表示出来
1234
5
(
10
)
=
111101
1
(
2
)
12345_{(10)} = 1111011_{(2)}
12345(10)?=1111011(2)?
2. 规范化表示
1111011
=
1.111011
×
2
6
1111011= 1.111011×2^6
1111011=1.111011×26
3. 计算指数
e
x
p
=
6
+
127
=
13
3
(
10
)
=
1000010
1
(
2
)
exp = 6 + 127 = 133_{(10)} = 10000101_{(2)}
exp=6+127=133(10)?=10000101(2)?
4. 确定尾数**
这是个规范化值,所以 1.frac 的 1 省略,又因为单精度浮点数 frac 占 23 位,所以我们需要在 111011 后面再填 17 个 0,即:
f
r
a
c
=
11101100000000000000000
frac = 111011 0000 0000 0000 0000 0
frac=11101100000000000000000
5. 确定符号位
s
=
0
(
2
)
s = 0_{(2)}
s=0(2)?
6. 组合起来
12345.0 = 0 10000101 11101100000000000000000
浮点数舍入
由于浮点数的表示具有固定的精度,在进行运算或表示时,经常会遇到无法精确表示的数值,这就需要采用舍入方法来近似表示这些数值。IEEE-754 标准定义了几种不同的舍入模式,以适应不同的计算需求。
舍入模式
最近舍入(Round to Nearest):
- 这是最常用的舍入模式,也是默认的模式。
- 规则是向最接近的可表示值舍入。如果精确结果位于两个可表示值的中点,通常舍入到最近的偶数(即尾数的最后一位为0)。
- 这种方法减少了累积误差,确保了在多次运算后的总体精度。
向零舍入(Round Toward Zero):
- 这种模式总是舍入到零的方向,即舍去小数部分。
- 对于正数,这相当于取下限,对于负数,相当于取上限。
向上舍入(Round Up):
- 无论正负,都向远离零的方向舍入。
- 对于正数,舍入后的值不小于原值;对于负数,舍入后的值不大于原值。
向下舍入(Round Down):
- 无论正负,都向接近零的方向舍入。
- 对于正数,舍入后的值不大于原值;对于负数,舍入后的值不小于原值。
舍入的影响
- 精度损失:由于固定的尾数位数,舍入可能导致精度的损失。
- 舍入误差:舍入操作本身可能引入误差,这些误差在连续运算中可能会累积。
- 选择合适的舍入模式:不同的舍入模式适合不同的应用场景。例如,金融计算可能更倾向于使用向零舍入,而科学计算通常使用最近舍入以减少累积误差。
实例
| Mode | 1.40 | 1.60 | 1.50 | 2.50 | -1.50 |
|---|---|---|---|---|---|
| 最近舍入 | 1 | 2 | 2 | 2 | -2 |
| 向零舍入 | 1 | 1 | 1 | 2 | -1 |
| 向上舍入 | 2 | 2 | 2 | 3 | -1 |
| 向下舍入 | 1 | 1 | 1 | 2 | -2 |
浮点数运算
因为浮点数本身就存在精度问题,所以浮点数运算在计算机中是一个近似过程,涉及到精确度的权衡、特殊值的处理、错误的传播,以及舍入规则的应用。
浮点数加减
- 浮点数加法和减法首先需要对操作数进行对齐,使得它们的指数相同。这可能涉及将尾数的二进制表示向右移位,可能导致精度损失。
- 然后执行加法或减法操作。
- 对结果进行规范化和舍入。
注意,浮点数的加减法不满足结合律、交换律和分配律,这你简单分析下应该就可以理解了,这里不赘述了。
假设我们要在单精度浮点数格式下计算:
12.375
+
0.1
=
?
12.375 + 0.1 = ?
12.375+0.1=?
第 1 步:转为二进制表示
其中 12.375 我们可以用二进制精确表示:
12.37
5
(
10
)
=
1100.01
1
(
2
)
12.375_{(10)} = 1100.011_{(2)}
12.375(10)?=1100.011(2)?
而 0.1 就比较特殊了,用二进制表示的话它会无限循环。
将十进制小数转换为二进制表示涉及到重复乘以 2 的过程,并提取每次乘法后整数部分作为二进制位。这个过程是一个不断重复的过程,直到小数部分变为 0 或开始循环。
-
取
0.1的小数部分乘以 2(即0.1 × 2 = 0.2),整数部分是0,小数部分是0.2。 -
再次取小数部分乘以 2(即
0.2 × 2 = 0.4),整数部分是0,小数部分是0.4。 -
继续这个过程,我们得到以下序列:
0.4 × 2 = 0.8→ 整数部分00.8 × 2 = 1.6→ 整数部分10.6 × 2 = 1.2→ 整数部分10.2 × 2 = 0.4→ 整数部分0…(循环开始)
所以,0.1 的二进制表示开始为 0.0001100110011…,并且这个模式会无限循环下去。
第 2 步:规格化
回顾一下这张图:
所以 12.375 规格化表示为:
- 先规范化为 1.xxxx 形式: 1100.01 1 ( 2 ) = 1.100011 × 2 3 1100.011_{(2)} = 1.100011 × 2^3 1100.011(2)?=1.100011×23
- 指数为: 3 + 127 = 130 = 1000001 0 ( 2 ) 3 + 127 = 130 = 10000010_{(2)} 3+127=130=10000010(2)?
- 尾数为: 10001100000000000000000 ( 23 ?? 位,右边补 ?? 0 ) 10001100000000000000000(23\;位,右边补\;0) 10001100000000000000000(23位,右边补0)
- 汇总: 0 ?? 10000010 ?? 10001100000000000000000 0\;10000010\;10001100000000000000000 01000001010001100000000000000000
而 0.1 由于无限循环,我们在单精度下只能保留 23 位,并采用最近舍入,所以 0.1 规格化表示为:
- 先规范为 1.xxxx 形式: 0.00011001100110011001100 ( 循环 ) = 1.10011001100110011001100 × 2 ? 4 0.00011001100110011001100(循环) = 1.10011001100110011001100 × 2^-4 0.00011001100110011001100(循环)=1.10011001100110011001100×2?4
- 指数为: ? 4 + 127 = 123 = 0111101 1 ( 2 ) -4 + 127 = 123 = 01111011_{(2)} ?4+127=123=01111011(2)?
- 尾数为: 10011001100110011001100 10011001100110011001100 10011001100110011001100
- 汇总: 0 ?? 01111011 ?? 10011001100110011001100 0\;01111011\;10011001100110011001100 00111101110011001100110011001100
第 3 步:对齐指数
先把 2 个浮点表示放在一起,好对比:
- 0 ?? 10000010 ?? 10001100000000000000000 0\;10000010\;10001100000000000000000 01000001010001100000000000000000
- 0 ?? 01111011 ?? 10011001100110011001100 0\;01111011\;10011001100110011001100 00111101110011001100110011001100
将两个数的指数对齐,较小的指数增加,同时相应地调整尾数。
这里需要调整将 0.1 的指数从 01111011 调整到 10000010,这里加了 7,所以 0.1 的尾数 1.10011001100110011001100需要右移 7 位,即:0.00000011001100110011001。
第 4 步:相加
现在两个数的指数相同了,我们可以直接把它们的尾数相加:
??????
1.10001100000000000000000
+
??
0.00000011001100110011001
=
??
1.10001111001100110011001
\;\;\;1.10001100000000000000000 \\ +\;0.00000011001100110011001 \\ =\;1.10001111001100110011001
1.10001100000000000000000+0.00000011001100110011001=1.10001111001100110011001
第 5 步:规范化结果
这里无需规范化。
第 6 步:舍入
这里没有进位,不需要舍入。
第 7 步:浮点化表示
0
??
10000010
??
10001111001100110011001
0\;10000010\;10001111001100110011001
01000001010001111001100110011001
第 8 步:转为十进制
V
=
(
?
1
)
s
×
M
×
2
E
=
(
?
1
)
s
×
1.
f
r
a
c
×
2
e
?
b
i
a
s
=
1.10001111001100110011001
×
2
3
=
1100.0111100110011001100
1
(
2
)
=
12.4749994277954101562
5
(
10
)
≈
12.47
5
(
10
)
V =(-1)^s×M×2^E \\ = (-1)^s×1.frac×2^{e-bias} \\ = 1.10001111001100110011001 × 2^3 \\ = 1100.01111001100110011001_{(2)} \\ = 12.47499942779541015625_{(10)} \\ ≈ 12.475_{(10)}
V=(?1)s×M×2E=(?1)s×1.frac×2e?bias=1.10001111001100110011001×23=1100.01111001100110011001(2)?=12.47499942779541015625(10)?≈12.475(10)?
浮点数乘法
- 符号位计算:结果的符号由两个操作数的符号位决定。如果符号位相同(都是正数或都是负数),结果为正;如果符号位不同,结果为负。
- 指数相加:两个数的指数相加,并减去偏置值(单精度浮点数中为127,双精度为1023)。
- 尾数相乘:两个数的尾数相乘。这里的尾数包括隐含的最高位1。
- 结果规范化:如果乘法的结果需要规范化(即调整为
1.xxxx的形式),则相应调整指数。 - 舍入处理:如果需要,对结果进行舍入以适应目标格式。
- 检查溢出或下溢:如果指数超出了表示范围,则发生溢出(结果可能为无穷大或特殊值);如果指数太小,发生下溢(结果可能为 0 或非规格化数)。
假设我们要在单精度浮点数格式下计算:
2.0
×
3.0
=
?
2.0 × 3.0 = ?
2.0×3.0=?
第 1 步:转为二进制表示
2.
0
(
10
)
=
1
(
2
)
3.
0
(
10
)
=
1
1
(
2
)
2.0_{(10)} = 1_{(2)} \\ 3.0_{(10)} = 11_{(2)}
2.0(10)?=1(2)?3.0(10)?=11(2)?
第 2 步:规范化
1
=
1.0
×
2
0
11
=
1.1
×
2
1
1 = 1.0 × 2^0 \\ 11 = 1.1 × 2^1
1=1.0×2011=1.1×21
第 3 步:浮点化
2.0
=
0
??
00000001
??
00000000000000000000000
3.0
=
0
??
00000001
??
10000000000000000000000
2.0 = 0\;00000001\;00000000000000000000000 \\ 3.0 = 0\;00000001\;10000000000000000000000
2.0=000000001000000000000000000000003.0=00000000110000000000000000000000
第 4 步:乘法操作
- 符号位:正正得正: 0 ( 2 ) × 0 ( 2 ) = 0 ( 2 ) 0_{(2)} × 0_{(2)} = 0_{(2)} 0(2)?×0(2)?=0(2)?
- 指数相加并减去偏置值: ( 127 + 1 ) + ( 127 + 1 ) ? 127 = 129 (127+1)+(127+1)-127=129 (127+1)+(127+1)?127=129
- 尾数相乘: 1. 0 ( 2 ) × 1. 1 ( 2 ) = 1. 1 ( 2 ) 1.0_{(2)}×1.1_{(2)} = 1.1_{(2)} 1.0(2)?×1.1(2)?=1.1(2)?
第 5 步:规范化
这里无需规范化。
第 6 步:舍入
这里无需舍入。
第 7 步:浮点化结果
0
??
00000010
??
10000000000000000000000
0\;00000010\;10000000000000000000000
00000001010000000000000000000000
第 8 步:转为十进制
V
=
(
?
1
)
s
×
1.
f
r
a
c
×
2
(
e
?
127
)
=
0
×
1.1
×
2
2
=
11
0
(
2
)
=
6.
0
(
10
)
V = (-1)^s×1.frac×2^{(e-127)} \\ = 0 × 1.1 × 2^2 \\ = 110_{(2)} \\ = 6.0_{(10)}
V=(?1)s×1.frac×2(e?127)=0×1.1×22=110(2)?=6.0(10)?
浮点数除法
浮点数除法类似于乘法,但有一些不同:
- 符号位计算:与乘法类似,结果的符号由两个操作数的符号位决定。
- 指数相减:被除数的指数减去除数的指数,再加上偏置值。
- 尾数相除:被除数的尾数除以除数的尾数。
- 结果规范化:如果必要,调整结果使其规范化。
- 舍入处理:如果需要,对结果进行舍入。
- 检查溢出或下溢:与乘法类似的检查。
假设我们要在单精度浮点数格式下计算:
6.0
÷
3.0
=
?
6.0 ÷ 3.0 =?
6.0÷3.0=?
第 1 步:转为二进制表示
6.
0
(
10
)
=
11
0
(
2
)
3.
0
(
10
)
=
1
1
(
2
)
6.0_{(10)} = 110_{(2)} \\ 3.0_{(10)} = 11_{(2)}
6.0(10)?=110(2)?3.0(10)?=11(2)?
第 2 步:规范化
6.0
=
110
=
1.10
×
2
2
3.0
=
11
=
1.1
×
2
1
6.0 = 110 = 1.10 × 2^2 \\ 3.0 = 11 = 1.1 × 2^1
6.0=110=1.10×223.0=11=1.1×21
第 3 步:浮点化
6.0
=
0
??
00000020
??
10000000000000000000000
3.0
=
0
??
00000001
??
10000000000000000000000
6.0 = 0\;00000020\;10000000000000000000000 \\ 3.0 = 0\;00000001\;10000000000000000000000
6.0=000000020100000000000000000000003.0=00000000110000000000000000000000
第 4 步:除法操作
- 符号位:正正得正: 0 ( 2 ) × 0 ( 2 ) = 0 ( 2 ) 0_{(2)} × 0_{(2)} = 0_{(2)} 0(2)?×0(2)?=0(2)?
- 指数减并加上偏置值: ( 127 + 2 ) ? ( 127 + 1 ) + 127 = 128 (127+2)-(127+1)+127=128 (127+2)?(127+1)+127=128
- 尾数相除: 1. 1 ( 2 ) × 1. 1 ( 2 ) = 1. 0 ( 2 ) 1.1_{(2)}×1.1_{(2)} = 1.0_{(2)} 1.1(2)?×1.1(2)?=1.0(2)?
第 5 步:规范化
这里无需规范化。
第 6 步:舍入
这里无需舍入。
第 7 步:浮点化结果
0
??
00000001
??
00000000000000000000000
0\;00000001\;00000000000000000000000
00000000100000000000000000000000
第 8 步:转为十进制
V
=
(
?
1
)
s
×
1.
f
r
a
c
×
2
(
e
?
127
)
=
0
×
1.0
×
2
1
=
1
0
(
2
)
=
2.
0
(
10
)
V = (-1)^s×1.frac×2^{(e-127)} \\ = 0 × 1.0 × 2^1 \\ = 10_{(2)} \\ = 2.0_{(10)}
V=(?1)s×1.frac×2(e?127)=0×1.0×21=10(2)?=2.0(10)?
Go 语言输出浮点数
func main() {
var number float32 = 12.375
fmt.Printf("浮点数:%f\n", number)
fmt.Printf("科学计数法:%e\n", number)
fmt.Printf("保留 2 位小数:%.2f\n", number)
bits := math.Float32bits(number)
bitsStr := fmt.Sprintf("%.32b", bits)
fmt.Printf("输出32位浮点表示:%s %s %s\n", bitsStr[:1], bitsStr[1:9], bitsStr[9:])
}
math/big
Go 语言的 math/big 包提供了对大数的精确计算支持,这些大数的大小超出了标准整数类型(如 int64)或浮点类型(如 float64)的范围。这个包主要用于需要高精度计算的领域,如加密、科学计算等。
主要功能:
- 算术运算:支持基本的加、减、乘、除等算术运算。
- 比较操作:可以比较两个大数的大小。
- 位操作:对大整数进行位操作,如位移、与、或、异或等。
- 解析和格式化:可以从字符串解析大数,也可以将大数格式化为字符串。
示例:
func main() {
a := big.NewFloat(math.MaxFloat64)
b := big.NewFloat(math.MaxFloat64)
sum := big.NewFloat(0)
sum.Add(a, b)
fmt.Println("a:", a)
fmt.Println("sum:", sum)
sum2 := big.NewFloat(0).
SetPrec(15). // 设置精度,prec 越大,精度越高,计算越复杂
SetMode(big.ToZero) // 设置舍入策略
sum2.Add(a, b)
fmt.Println("sum2:", sum2)
}
// a: 1.7976931348623157e+308
// sum: 3.5953862697246314e+308
// sum2: 3.5953e+308
注意事项:
- 性能考虑:由于
math/big提供的是任意精度计算,其性能通常低于原生的固定大小数值类型。 - 内存使用:大数运算可能会消耗更多的内存。
- 方法链式调用:
math/big的许多方法返回接收者本身,支持链式调用。
参考资料
- IEEE-754
- 深入理解计算机系统
- Go 语言底层原理剖析
- https://www.bilibili.com/video/BV1zK4y1j7Cn
- ChatGPT-4
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!