小土堆_pytorch_完整的模型训练_十种物品分类_一步一步代码实现14_笔记
2023-12-14 21:43:10
完整的模型训练套路
一.数据的准备
二.利用DataLoader 来加载数据集
三.创建网络模型
四.损失函数
五.优化器
六.设置训练网络的一些参数
七.开始训练
八.开始测试
九.保存每一轮的模型
一些注意的点
综上完整的代码
一.数据的准备
import torchvision
# 准备数据集
## 准备训练数据集
train_data=torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
## 准备测试数据集
test_data=torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
### 查看数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))

二.利用DataLoader 来加载数据集
# 利用DataLoader 来加载数据集
train_dataloader=DataLoader(train_data,64)
test_dataloader=DataLoader(test_data,64)
三.创建网络模型
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2) , # 其中padding=2 是通过计算得出的,也可以写-1自动计算
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
一般情况下,我们通常把神经网络单独放在另一个文件里
# 搭建神经网络
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2) , # 其中padding=2 是通过计算得出的,也可以写-1自动计算
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ == '__main__':
tudui=Tudui()
# 测试模型的可用性
input=torch.ones((64,3,32,32))
output=tudui(input)
print(output.shape)
四.损失函数
loss_fn=nn.CrossEntropyLoss()
五.优化器
earning_rate=0.01
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
六.设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的次数
total_test_step=0
#训练的轮数
epoch=10
七.开始训练
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets) #计算loss
#优先器优化模型
optimizer.zero_grad() #设置梯度为0
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
print("训练次数:{},loss:{}".format(total_train_step,loss.item())) # loss.item()是把tensor数据类型转换为我我们需要的数字类型
运行结果截图:

上述完整代码
保证各个python文件在同一个文件夹下
train.py
import torchvision
from model import *
# 准备数据集
## 准备训练数据集
from torch import nn
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
## 准备测试数据集
test_data=torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
### 查看数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader 来加载数据集
train_dataloader=DataLoader(train_data,64)
test_dataloader=DataLoader(test_data,64)
#创建网络模型
tudui=Tudui()
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learning_rate=0.01
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的次数
total_test_step=0
#训练的轮数
epoch=10
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets) #计算loss
#优先器优化模型
optimizer.zero_grad() #设置梯度为0
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
print("训练次数:{},loss:{}".format(total_train_step,loss.item())) # loss.item()是把tensor数据类型转换为我我们需要的数字类型
model.py
# 搭建神经网络
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2) , # 其中padding=2 是通过计算得出的,也可以写-1自动计算
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ == '__main__':
tudui=Tudui()
# 测试模型的可用性
input=torch.ones((64,3,32,32))
output=tudui(input)
print(output.shape)
八.开始测试
#测试步骤开始
total_test_loss=0 #记录总共loss
with torch.no_grad(): #不更新梯度
for data in test_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
但是我们发现在循环中我们很难查看整体测试集上的loss,为了方便查看,我们在训练步骤中加入if
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets) #计算loss
#优先器优化模型
optimizer.zero_grad() #设置梯度为0
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step %100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss.item())) # loss.item()是把tensor数据类型转换为我我们需要的数字类型
运行结果截图:

加入tensorboard
当前train.py 完整代码,model.py是不发生变化的:
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
## 准备训练数据集
from torch import nn
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
## 准备测试数据集
test_data=torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=False)
### 查看数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader 来加载数据集
train_dataloader=DataLoader(train_data,64)
test_dataloader=DataLoader(test_data,64)
#创建网络模型
tudui=Tudui()
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learning_rate=0.01
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的次数
total_test_step=0
#训练的轮数
epoch=10
# 添加tensorboard
writer=SummaryWriter("../logs_train")
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets) #计算loss
#优先器优化模型
optimizer.zero_grad() #设置梯度为0
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step %100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss.item())) # loss.item()是把tensor数据类型转换为我我们需要的数字类型
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
total_test_loss=0 #记录总共loss
with torch.no_grad(): #不更新梯度
for data in test_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step=total_test_step+1
writer.close()
tensorboard --logdir=绝对路径
tensorboard可视化截图: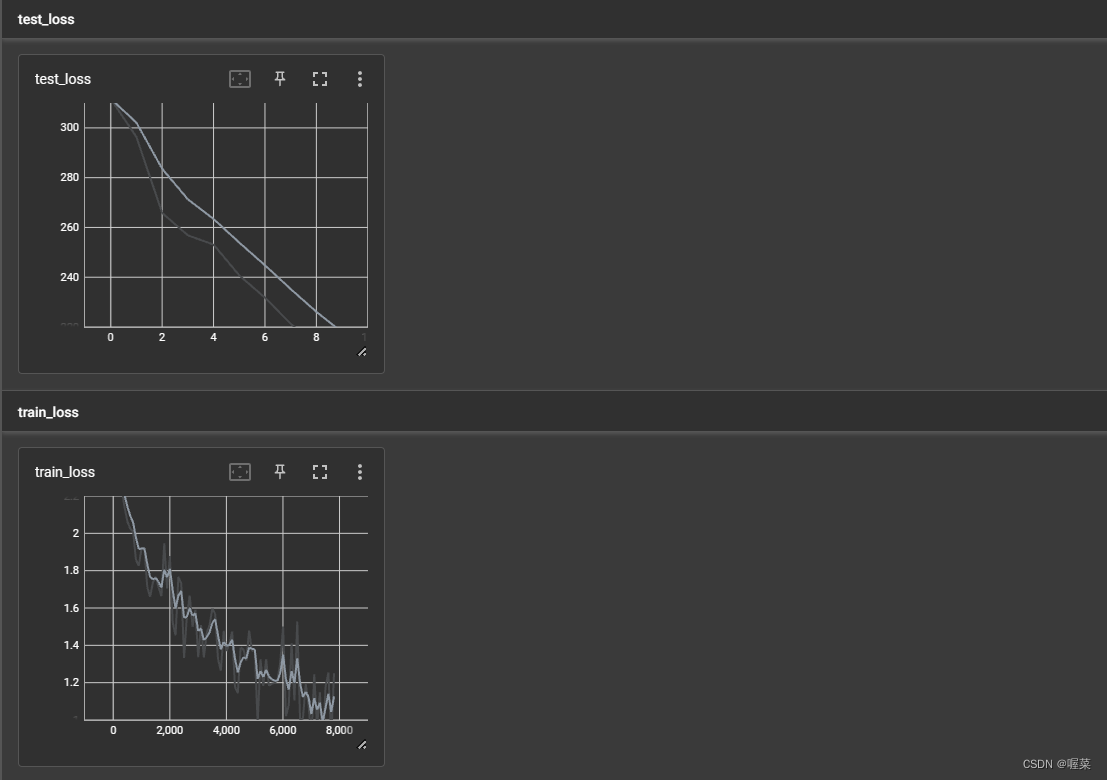
分类问题可以增加argmax()判断正确率,作为可视化的数据
完整的train.py代码
#测试
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
## 准备训练数据集
from torch import nn
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
## 准备测试数据集
test_data=torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
### 查看数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader 来加载数据集
train_dataloader=DataLoader(train_data,64)
test_dataloader=DataLoader(test_data,64)
#创建网络模型
tudui=Tudui()
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learning_rate=0.01
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的次数
total_test_step=0
#训练的轮数
epoch=10
# 添加tensorboard
writer=SummaryWriter("../logs_train")
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))
#训练步骤开始
for data in train_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets) #计算loss
#优先器优化模型
optimizer.zero_grad() #设置梯度为0
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step %100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss.item())) # loss.item()是把tensor数据类型转换为我我们需要的数字类型
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
total_test_loss=0 #记录总共loss
total_accuracy=0
with torch.no_grad(): #不更新梯度
for data in test_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step=total_test_step+1
writer.close()
运行结果截图:
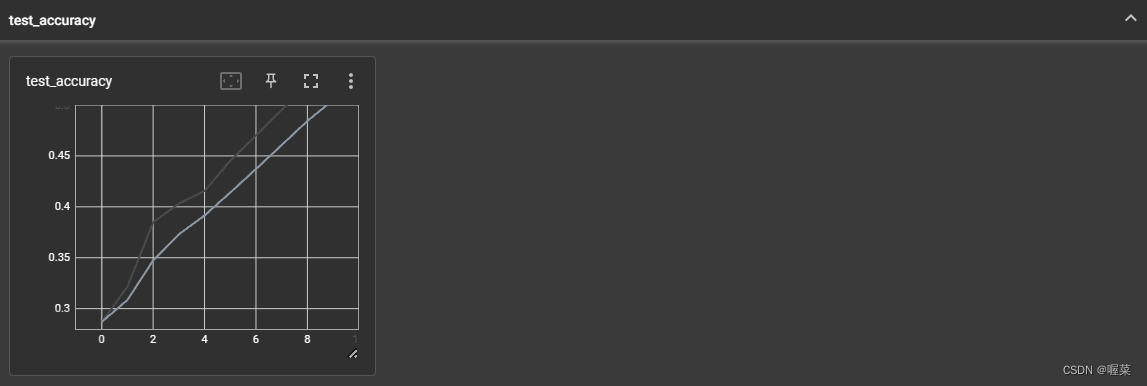
九.保存每一轮的模型

一些注意的点
在训练和测试开始前对某些特殊的层进行优化
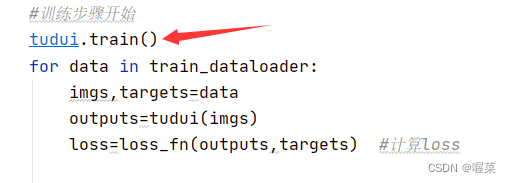
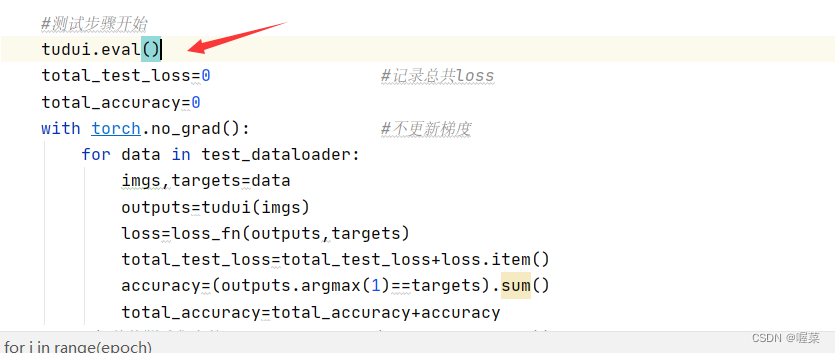
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
## 准备训练数据集
from torch import nn
from torch.utils.data import DataLoader
train_data=torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
## 准备测试数据集
test_data=torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
### 查看数据集的长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader 来加载数据集
train_dataloader=DataLoader(train_data,64)
test_dataloader=DataLoader(test_data,64)
#创建网络模型
tudui=Tudui()
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learning_rate=0.01
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的次数
total_test_step=0
#训练的轮数
epoch=10
# 添加tensorboard
writer=SummaryWriter("../logs_train")
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i+1))
#训练步骤开始
tudui.train()
for data in train_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets) #计算loss
#优先器优化模型
optimizer.zero_grad() #设置梯度为0
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step %100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss.item())) # loss.item()是把tensor数据类型转换为我我们需要的数字类型
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
tudui.eval()
total_test_loss=0 #记录总共loss
total_accuracy=0
with torch.no_grad(): #不更新梯度
for data in test_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step=total_test_step+1
writer.close()
model.py
# 搭建神经网络
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2) , # 其中padding=2 是通过计算得出的,也可以写-1自动计算
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ == '__main__':
tudui=Tudui()
# 测试模型的可用性
input=torch.ones((64,3,32,32))
output=tudui(input)
print(output.shape)
文章来源:https://blog.csdn.net/weixin_62613321/article/details/132721175
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!