PromptNER: Prompt Locating and Typing for Named Entity Recognition
原文链接:
https://aclanthology.org/2023.acl-long.698.pdf
ACL 2023
介绍
? ? ? ? 问题
????????目前将prompt方法应用在ner中主要有两种方法:对枚举的span类型进行预测,或者通过构建特殊的prompt来对实体进行定位。但作者认为这些方法存在以下问题:1)时间开销和计算成本较高;2)需要精确的设计模板,难以在实际场景中应用。
????????IDEA
? ? ? ? 因此作者提出了一种双插槽的prompt模板来分别进行实体定位和分类,模型可以同时处理多个prompt,通过对每个prompt中的插槽进行预测来提取所有的实体。
? ? ? ? 如下图所示,(a)表示根据实体类别构造prompt的方法;(b)表示根据span构造prompt的方法;(c)表示作者所提出的双插槽方法。
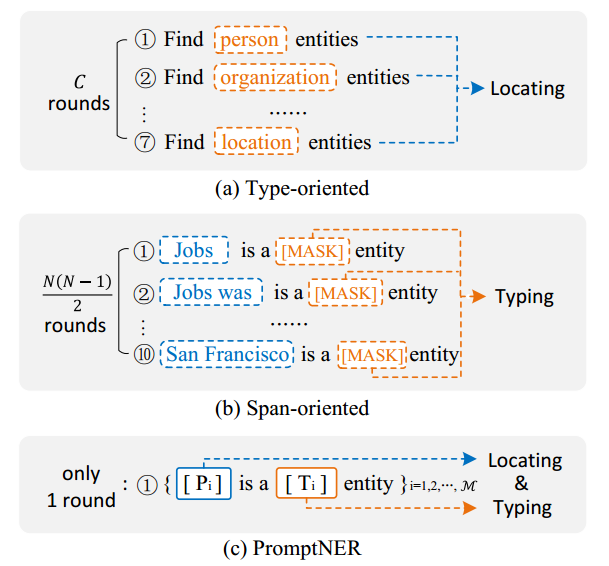
方法
? ? ? ? ?整体的结构如下图所示:

Prompt Construction
? ? ? ? 模型的输入由两部分组成:M个prompt和句子X。具体的,当输入的句子x=“Jobs was born in San Francisco”,则输入序列就表示为T:

????????i表示第i个prompt,pi和Ti分别表示实体的位置和类别,M表示prompt的数量,通过对每个prompt中对应的位置进行解码来提取实体。
Prompt Locating and Typing
Encoder
?????????使用bert对T进行编码后,通过位置索引得到句子X与两个插槽的编码 ![]() :
:
![]()
????????这里作者为了对句子进行独立于prompt的编码(为啥要进行独立编码?好像是为了不让prompt对句子产生影响 实验证明这样的效果会好一点点),通过一个n*k(k表示prompt序列的长度)的左下角掩码矩阵来阻断prompt对句子的注意。
????????为了增强不同prompt之间的交互,作者设计了一个额外的prompt交互层,每层中包括插槽之间的自注意力以及句子和插槽的交叉注意力(q是插槽,key和value是句子),即位置和类别两种插槽的最终表示为:
![]()
Entity Decoding?
?????????通过对prompt中的position slot(位置插槽)和type slot(类别插槽)进行解码得到最终的实体。
? ? ? ? 具体的,对于第i个prompt,将其type slot ![]() 送入一个分类器得到其属于不同类别的可能性:
送入一个分类器得到其属于不同类别的可能性:
![]()
????????对于实体的位置,转化为确定第j个词是第i个prompt所预测实体的起始词还是结束词。首先将position slot ![]() 送入一个线性层,然后与句子中每个单词的表征进行相加得到融合表征
送入一个线性层,然后与句子中每个单词的表征进行相加得到融合表征![]() ,对其进行二分类,得到第j个词是第i个prompt预测实体的左右边界概率:
,对其进行二分类,得到第j个词是第i个prompt预测实体的左右边界概率:

????????最后,m个prompt所预测出的实体可以表示为:
![]()
? ? ? ? 在推理时,同一实体跨度选择分数最高的类别。?
Dynamic Template Filling?
?????????由于prompt和实体之间没有确切的对应关系,也就不能提前为其分配标签。因此,将插槽视为一个线性分配问题,按最小代价原则进行分配。作者提出了一种动态模板匹配机制,在实体和prompt之间进行二部图匹配。
????????gold entity表示为![]() , 其中k表示实体的数量,
, 其中k表示实体的数量,![]() 分别表示第i个实体的左右边界和类别。即与prompt对应的最佳匹配为:
分别表示第i个实体的左右边界和类别。即与prompt对应的最佳匹配为:

? ? ? ? 其中第i个实体与第θ(i)个prompt之间匹配的代价为(这里没看懂这个计算公式,文中也没有进一步说明,预测的实体与真实实体相乘?):
![]()
?????????但传统的二方图匹配算法是一对一的,即一个实体只能分配给一个prompt,这就会导致部分prompt匹配到空集,降低了训练效率。因此作者将其扩展到了一对多的情况,在预定义好的下限值U下重复gold entity来扩充Y,实现一个实体能分配给多个prompt。
????????模型的loss由以下两部分的loss组成:

实验
对比实验
????????在ACE04、ACE05、Conll03这三个数据集上进行实验,结果如下所示:

域内Few-shot
?????????领域内few-shot场景下的实验结果如下图所示:

????????对conll03数据集进行下采样,使得这四个类别的样本数分别为:3763、2496、100、100.
跨域Few-shot
?????????模拟跨领域few-shot的情况进行实验,在conll03数据集上进行预训练,然后迁移到MIT Movie、MIT Restaurant和ATIS这三个数据集的部分样本上(10、20表示每个类别的样本数)进行实验,结果如下图所示:

????????作者认为由于promptNER分别对位置和类别进行预测,适用于语法一致而语义不一致的跨域场景。
消融实验?
?????????作者对模型的主要模块进行了消融实验,结果如下所示:

? ? ? ? 消融设置:
????????1)根据实体出现的顺序来分配给prompt;
????????2)不进行标签的扩充,比如使用传统的一对一二部图匹配;
????????3)使用原始的bert用于对句子和prompt进行编码
? ? ? ? 对不同的prompt模板也进行了实验,结果如下所示:

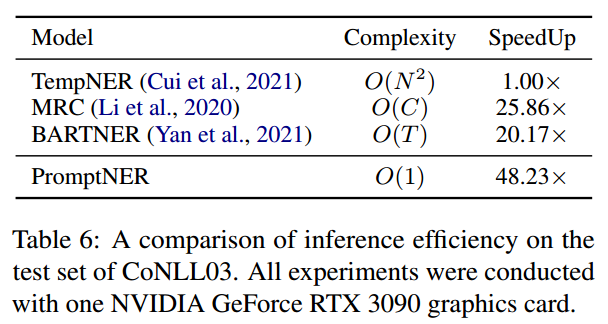
Inference Efficiency
????????对于有N个单词、C个类别的句子,基于实体类型和span的promt方法分别需要运行C和N(N-1)次,以自回归生成实体序列的方法需要运行T步(实体的长度)才能获得所有的实体。
????????而PromptNER只需要运行一次就能得到所有的实体。在conll03数据集上进行推理速度的实验,结果如下所示:
总结
? ? ? ? 之前用在ner上的prompt都是对实体位置和类别分开进行的,这是第一篇(我读到的)?用这种两个slot的方法来对实体及其类别分别进行处理。(但是感觉这样没有语义上的可理解性,也不太符合预训练任务,因为感觉一句话后面也不会直接接上实体)第二个创新点感觉标签动态分配那一块没有讲清楚,很多方法都是使用这种动态分配标签的方法,而去作者扩展为一对多的方式竟然是直接复制,有点过于简单了,真的。但是作者做的相关实验很充分!
????????另外,作者对prompt的模板进行了消融实验,其实这三种prompt相差都不大,感觉都差不多,只是[pi][Ti]这种模板附加信息更少,不会超出bert的最大长度。不过可以借鉴作者做的推理效率那一块的实验。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!