【具身智能评估6】Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots
论文标题:Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots
论文作者:Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai, Alexander William Clegg, Michal Hlavac, So Yeon Min, Vladimír Vondru?, Theophile Gervet, Vincent-Pierre Berges, John M. Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara Rai, Roozbeh Mottaghi
论文原文:https://arxiv.org/abs/2310.13724
论文出处:–
论文被引:4(12/18/2023)
论文代码:https://github.com/facebookresearch/habitat-lab/tree/v0.3.0,1.5k star
项目主页:https://aihabitat.org/habitat3/
Abstract
我们介绍 Habitat 3.0:一个用于研究家庭环境中人机协作(collaborative human-robot)任务的模拟平台。Habitat 3.0 在三个方面做出了贡献:
-
1)准确的仿人仿真:在确保高速仿真的同时,应对复杂变形体建模以及外观和运动多样性方面的挑战。
-
2)人在环基础设施:通过鼠标/键盘或 VR 界面,实现真人与模拟机器人的互动,从而便于通过人的输入对机器人策略进行评估。
-
3)协作任务:研究两种协作任务,即社交导航(Social Navigation)和社交重组(Social Rearrangement)。
- 社交导航:研究的是机器人在未知环境中定位和跟踪人形化身(humanoid avatars)的能力。
- 社交重组:研究的是人形化身和机器人在重新布置场景时的协作能力。
这些贡献使我们能够深入研究人机协作的端到端学习基线和启发式基线,并与人类一起对它们进行评估。我们的实验证明,当机器人与未见过的仿人智能体和人类伙伴协作时,学习到的机器人策略能高效地完成任务。此外,我们还观察到协作任务执行过程中出现的行为,如机器人在阻碍仿人机器人时让出空间,从而使仿人机器人有效地完成任务。此外,我们使用人在回路中(human-in-the-loop)工具进行的实验表明,我们使用仿人机器人进行的自动评估可以说明不同策略在与真实人类协作者进行评估时的相对顺序。Habitat 3.0 解锁了具身人工智能模拟器中有趣的新功能,我们希望它能为具身人机交互能力的新领域铺平道路。以下视频概述了该框架: https://tinyurl.com/msywvsnz
1 INTRODUCTION
当今的具身人工智能智能体基本上都是隐士——作为孤独的居住者存在于虚拟世界中并在其中航行。即使在具有交互性的虚拟世界中,智能体操纵和移动物体,其基本假设也是环境的变化完全是由于这一个智能体的行动而发生的。这些场景为具身人工智能奠定了坚实的基础,并促进了新架构,算法,以及模拟到现实(simulation-to-reality)的结果。然而,这些成果与开发辅助机器人(assistive robots)背后的动机形成了鲜明对比,后者的目标是与能够修改和动态改变环境的人类合作者共享环境。我们认为,现在是时候更全面地**研究和开发能辅助人类并与人类合作的社交具身智能体(social embodied agents)**了。

请看图 1 所示的社交机器人:波士顿动力公司的 Spot 机器人与人形机器人在家庭环境中合作,在打扫房间的同时重新摆放物品。要成功完成此类任务,两个机器人需要根据各自的能力和偏好有效地分工,同时避免干扰并尊重彼此的空间。例如,机器人在通过一扇门时会向后移动,为仿人机器人让出空间(图 1,右)。
在硬件上与真人一起训练和测试这种社交智能体会带来固有的挑战,包括:
- 安全问题
- 可扩展性限制
- 巨大的成本影响
- 建立标准化基准程序的复杂性
仿真平台可以克服这些挑战;然而,人机协作仿真平台的开发也有其自身的复杂性。
- 首先,一个主要的挑战是对可变形人体进行建模,以合成逼真的运动和身体部位的外观。
- 其次,为了确保人机交互模型的通用性,在模拟器中加入不同的人类行为和动作至关重要。
- 最后,目前最先进的具身人工智能(E-AI)学习算法往往需要大量的迭代才能收敛,导致训练时间过长。
因此,人类运动生成和渲染的优化技术对于在可控的时间内实现学习收敛至关重要。
在本文中,我们将介绍 Habitat 3.0:一种同时支持人形化身和机器人的模拟器,用于研究家庭环境中的人机协作任务。
Human simulation
Habitat 3.0为人类仿真提供了以下功能:
- 1)铰接式骨骼,骨骼与旋转关节相连,便于进行快速碰撞测试;
- 2)表面 “皮肤” 网格,用于高保真渲染人体,增强视觉真实感;
- 3)参数化人体模型(Pavlakos et al. (2019)),用于生成逼真的身体形状和姿势;
- 4)虚拟化身库(library of avatars),由12个基本模型组成,具有多种性别、身体形状和外观;
- 5)运动和行为生成策略,可对虚拟化身进行导航、物体互动和其他各种运动的编程控制。尽管我们强调真实感和多样性,但我们的模拟速度仍可与非人形智能体的场景相媲美(一个人形智能体和一个机器人的模拟速度为 1190 FPS,而两个机器人的模拟速度为 1345 FPS)。这是通过优化技术实现的,其中包括缓存从不同人形收集到的人类运动数据。随后,利用投影技术将这些数据调整到新的环境中,从而实现既快速又准确的模拟,同时尊重环境的几何形状。
Human-in-the-loop tool
除了仿真人形之外,我们系统的一个重要功能是一个 “人在回路中” 工具,这是一个交互式界面,便于与真实的人类合作者一起评估人工智能智能体。通过这一工具,人类可以使用鼠标和键盘输入或虚拟现实(VR)界面与自主机器人协作。通过这种交互式设置,我们可以在与真实世界交互十分相似的场景中评估所学人工智能智能体的性能。
Social tasks
为了实现可重复和标准化的基准测试,我们提出了两项人机协作交互任务以及每项任务的基准测试套件。我们将已被充分研究的导航(Navigation)和重新排列(Rearrangement)任务从单机器人环境 “搬” 到了人类辅助环境中。
- 第一个任务是社交导航(Social Navigation),涉及机器人在保持安全距离的情况下找到并跟随一个仿人机器人。
- 第二项任务是社交重新排列(Social Rearrangement),包括机器人和人形化身协同工作,通过一系列拾放动作(模拟打扫房屋),将一组物品从初始位置重新排列到所需位置。
在社交导航中,机器人的目标与人形化身的目标无关,而在社交重新排列中,机器人和人形化身必须协调行动,尽可能高效地实现共同目标。我们在一个自动化环境中对这些任务进行了评估,在该环境中,仿人虚拟化身和机器人都根据其学习/脚本策略进行操作。此外,我们还在人在回路框架中使用一个子集基线对社交重新安排进行了评估,允许真人控制仿人化身,同时使用学习到的策略控制机器人。
我们对这两项任务的学习基线和启发式基线进行了深入研究,重点是对新场景、布局和协作伙伴的泛化。
- 在社交导航中,我们发现端到端 RL 可以学习协作行为,例如为仿人机器人让出空间,确保其行动不受阻碍。
- 在社交重新排列中,学习到的策略能有效地在机器人和仿人之间分担任务,即使是在看不见合作者的情况下也是如此,从而提高了仿人单独操作的效率。
- 这些发现延伸到了我们的人在回路中研究中,与单独执行任务相比,社交重新安排基线提高了人类的效率。
总之,我们提供了一个模拟仿人机器人的平台,从而为深入研究人与机器人的社交任务提供了环境。我们希望这个平台能鼓励具身人工智能界更多地参与这一重要的研究方向。
2 RELATED WORK
Embodied AI Simulators
最近开发了几种模拟器来支持具身任务。与这些工作相反,除了机器人模拟之外,我们还模拟了人类的运动和互动。
- iGibson 2.0 在社交导航任务中模拟人形机器人。不过,人形机器人被视为在预定轨道上移动的刚体。
- 在 iGibson 2.0 的基础上,Behavior 使用 VR 界面收集人体演示。
- VRKitchen 也提供了这样一个 VR 界面来收集演示和评估智能体的基准。
- 这些模拟器**侧重于人类远程操作,而非仿人模拟。相比之下,Habitat 3.0 同时支持仿人模拟和人类远程操作**。
- Overcooked-AI 是一款烹饪模拟器,旨在与人类协调,但**其环境是简化的网格状2D环境**。
- VirtualHome 是一款支持人形化身在三维环境中交互的模拟器,但**不支持与机器人的交互**。
- 相比之下, Habitat 3.0 同时对机器人和仿人智能体进行模拟和建模,并允许它们之间进行交互。
- SEAN 支持三维环境中的仿人和机器人模拟。不过,它仅限于 3 个场景,而且主要**侧重于社交导航**。
- 相比之下, Habitat 3.0 支持在广泛的室内环境中进行物体交互,并且比现有的仿人模拟器快一个数量级(详细比较见附录中的表 4)。
Human-in-the-Loop Training & Evaluation
人类在环(HITL)训练和评估已在NLP、计算机视觉和机器人学等许多不同的背景下得到研究。具身人工智能领域的此类研究具有挑战性,因为它们需要一个用户和智能体都能互动的环境。之前的工作主要集中在简化的网格或符号状态环境上。少数作品在 3D 环境中大规模收集用户数据,但**侧重于数据收集和离线评估,而非交互式评估。我们提出了一个能够进行交互式评估和数据收集的 HITL 框架**。
Embodied Multi-Agent Environments & Tasks
大多数多智能体强化学习(MARL)工作都是在低维状态空间(如网格状迷宫、表格任务或马尔可夫游戏)中运行的。与这些框架不同的是,Habitat 3.0 环境捕捉到了家务劳动所需的真实感。与我们的工作更接近的是之前在 3D 具身环境中的视觉 MARL 方面的工作:
- [引文,具体参考原文] 在具身模拟中引入多个智能体移动家具;
- [引文,具体参考原文] 研究了模拟家庭环境中的协作重新安排,其中两个机器人执行整理和摆放餐桌等任务。
- [引文,具体参考原文] 研究了具有不同能力的异构智能体,以解决共同任务。
- [引文,具体参考原文] 智能体以团队或个人形式展开竞争(例如捉迷藏)。
- 然而,这些研究都**没有模拟人形机器人**。
- Co-gail 模拟了人形机器人,并通过学习生成人与机器人的协作行为。
- 相比之下,Habitat 3.0 对模拟的每个方面(场景和环境变化,以及仿人模型的逼真度、保真度和多样性)进行了扩展。
3 HABITAT 3.0 FRAMEWORK
我们首先解释了人形模拟的复杂性,以及我们如何应对效率、逼真度和多样性等关键挑战。我们尤其关注缓存策略,这是实现高速外观和动作生成的关键因素。然后,我们介绍了我们的 “人在回路中” 工具,该工具可在仿真中与真人一起评估机器人策略。
3.1 HUMAN SIMULATION
为了让机器人学会有效地与人类互动,我们需要建立快速、多样和逼真的人类模型,以便在模拟中部署和训练智能体。在此,我们将介绍如何设计这些仿人智能体,其中包括两个组成部分:外观和动作/行为。
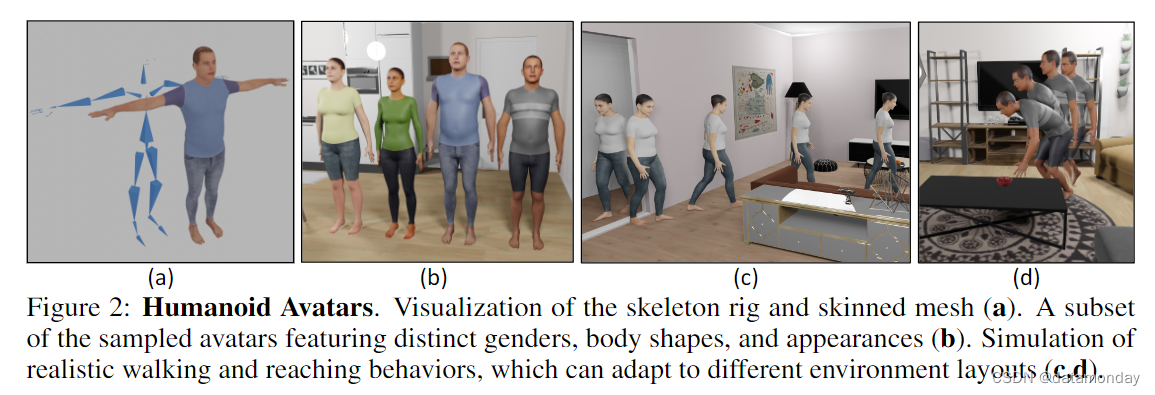
Humanoid Appearance
按照传统的图形方法 [引文,具体参考原文],我们将人形表示为铰接式骨架(articulated skeleton),骨骼通过旋转关节连接(图 2(a))。此外,我们还将表面网格连接到骨架上,并根据骨架的姿势和形状,使用线性混合蒙皮(LBS)更新网格顶点(图 2(a))。骨架用于表示姿势和检查与环境的碰撞,而蒙皮网格则在不影响物理特性的情况下提供视觉保真度。选择铰接式骨架来表示物理特性,选择带皮肤的网格来表示外观,可以在不影响逼真度的情况下提高仿真速度。为了生成逼真的骨架和网格,我们采用了 SMPL-X,这是一种数据驱动的参数化人体模型,它提供了三维人体形状和姿势的紧凑表示。具体来说,SMPL-X 将人的姿势和形状表示为两组参数 J、β(针对不同性别)。 J ∈ R 109 J∈\mathbb{R}^{109} J∈R109 通过手、身体和脸部关节的旋转编码主体的姿势,而 β ∈ R 10 β∈\mathbb{R}^{10} β∈R10 则通过网格顶点位移的原理分量捕捉身体形状的变化。为了对不同姿势下的身体变形进行编码,SMPL-X 使用了与姿势相关的混合形状,根据姿势改变仿人关节和皮肤网格之间的关系。为了实现快速人形模拟,我们缓存了 4 个男性、4 个女性和 4 个中性身体形状,并存储了相应的骨架和皮肤网格。这样,我们就可以离线计算模型装配和混合形状,只需在模拟过程中使用 LBS 即可。由于混合形状是恒定的,因此我们无法创建与姿势相关的皮肤变形,从而损失了一些视觉保真度。不过,通过这种权衡,我们可以高效地加载和摆放人形模型。图 2(b) 和补充视频展示了一些生成的人形模型。
Humanoid Motion and Behavior
我们的仿人虚拟化身能够进行逼真的远距离运动和行为,以适应不同的任务和环境。为了实现这一目标,我们设计了一个分层行为模型,在该模型中,学习策略或规划器执行一系列低层次(low-level)技能来移动仿人,从而产生远程行为。由于我们的目标是使仿人模型能够执行重新排列和导航任务,因此我们特别考虑了两种基本的低层次(low-level)技能:
- 在环境中导航
- 拾取和放置物体
虽然我们的重点是有限的一组运动,但SMPL-X格式允许添加广泛的运动,如MoCap数据或运动生成模型生成的运动。
在导航时,我们首先使用路径规划器生成到达目标位置而不会与环境发生碰撞的航点。然后,人形机器人在这些航点之间进行转换,首先刚性旋转底座以面向下一个航点,然后向前移动。为了制作前进运动的动画,我们使用了 AMASS 数据集中的一个行走运动片段,将其修剪为包含一个行走周期(左右脚都移动后),并循环播放,直到到达下一个航点(图 2 ?)。为了生成拾取动作,我们使用 VPoser 为每个身体模型预先计算出一组人形姿势,其中一只手伸向人体周围的一组三维位置,同时将脚限制在固定位置。然后,我们离线存储这些姿势,并以手部相对于人形根部的三维位置为索引。在评估时,我们通过对最接近的存储姿势进行内插,获得到达任意三维点的人形姿势,而无需查询 VPoser。这样就可以快速模拟拾取/放置动作。通过绘制一条从手的当前位置到目标三维位置的三维线,并检索线上中间点的姿势,就能获得连续的取放动作。一旦手到达目标位置,我们就以运动学的方式将目标附着或脱离手。由此产生的运动如图 2(d)所示。虽然这种方法能在根据 VPoser 计算出的位置范围内生成平滑的运动,但在超出这一范围的位置时就会失效,这种情况会在手离身体太近或太远时发生。有关动作示例,请参阅补充视频。
Benchmarking
与仿真机器人相比,我们的仿真设计能够在对性能影响最小的情况下实现高效的仿人仿真。在我们的模拟器中,机器人在单一环境下的运行速度为每秒 245±19 帧(FPS),而仿人机器人的运行速度为每秒 188±2 帧(FPS)。FPS 的差异主要是由于人形模型的关节数量多于机器人。移除皮肤或动作捕捉数据并不会明显影响性能,这意味着我们的模拟可以很好地扩展到逼真的视觉效果和动画。当使用两个智能体时,机器人-机器人的帧率为 150±13,而机器人-类人型的帧率为 136±8。增加环境数量可大幅提高速度,类人型机器人在单 GPU 上的 16 个环境中的帧率为 1191±3。更多详情见附录 F.1。
3.2 HUMAN-IN-THE-LOOP INFRASTRUCTURE
我们的目标是研究机器人策略在与表现出不同行为的合作者(包括真实的人类合作者)互动时的泛化能力。为了促进人机交互,我们开发了人机交互评估平台(HITL)。该工具允许人类操作员使用鼠标/键盘或 VR 界面控制模拟环境中的人形机器人,从而实现在线人机交互评估和数据收集。下面,我们将重点介绍其中的一些主要功能:
Ease-of-Development
我们的 HITL 工具利用了 AI Habitat 仿真器(Savva 等人,2019 年;Szot 等人,2021 年)的基础设施,实现了现有数据集和仿真能力的无缝集成和利用。此外,我们还用 Python 实现了终端用户逻辑,并为底层仿真逻辑提供了便捷的封装,以方便开发。
Portability to Other OS/Hardware Platforms
我们的 HITL 工具采用客户端-服务器架构,可移植到其他操作系统/硬件平台。服务器处理所有逻辑(如模拟、智能体推理和虚拟化身键盘控制),而客户端仅处理特定平台的渲染和输入设备处理。这样就可以在功能强大的机器上运行计算繁重的服务器组件,同时将客户端移植到其他平台,如资源有限的网络浏览器和虚拟现实设备。因此,用户可以在一系列任务中使用该工具:使用鼠标和键盘进行小规模本地评估、在浏览器上进行大规模数据收集或在 VR 中进行高保真人机交互。
Replayability
为了支持数据收集和再现,我们的平台提供了记录和重放 HITL 事件的功能。
- 回放功能支持不同层次的抽象,从高级导航/拾取/放置动作到人形姿势和刚性物体的精确轨迹。
- 此外,该平台还能从不同的自中心或外中心摄像机的视角重新渲染整个回合(episode)。
4 INTERACTIVE HUMAN-ROBOT TASKS
我们在 Habitat 3.0 中研究了两项任务:社交导航和社交重组。 在社交导航中,机器人必须找到并跟随人形机器人,同时保持安全距离。在社交重新排列中,仿人机器人和机器人合作将场景中的物体从初始位置移动到目标位置。社交导航要求机器人在不干扰仿人机器人的情况下实现目标,而在社交重新排列中,两个智能体必须合作实现共同目标。
4.1 SOCIAL NAVIGATION: FIND & FOLLOW PEOPLE
Task description
辅助机器人应该能够执行 “Bring me my mug” 或 “Follow Alex and help him in collecting the dishes” 等命令,这些命令要求在安全距离内找到并跟随人类。有鉴于此,我们设计了一项社交导航任务 [引文1],在该任务中,一个人形机器人在场景中行走,机器人必须在保持 1 米至 2 米安全距离的情况下找到并跟随该人形机器人。我们的任务不同于之前的社交导航研究,如[引文2,3],因为他们主要关注的是避开人类。
[引文1]:Principles and Guidelines for Evaluating Social Robot Navigation Algorithms,2023
[引文 2]:iGibson Challenge 2021
[引文 3]:SocNavBench: A Grounded Simulation Testing Framework for Evaluating Social Navigation,2021
图 3(左)展示了社交导航任务。机器人被放置在一个看不见的环境中,其任务是利用手臂上的深度摄像头(手臂深度)、二分类人形探测器(检测人形是否在画面中)以及人形与机器人的相对距离和航向(人形 GPS)来定位并跟随人形。这项任务不同于其他导航任务,如图像目标(Zhu 等人,2017 年),点目标(Anderson 等人,2018 年)和物体目标(Batra 等人,2020 年)导航,因为它**需要对动态目标和动态障碍物进行推理。机器人必须根据人形物体的位置调整路径,并预测人形物体的未来运动,以避免与其发生碰撞**。如果机器人与仿人机器人相撞或达到最大回合(episode)数长度,则回合终止。人形机器人沿着最短路径到达环境中随机取样的一系列点。

Metrics
我们为这项任务定义了 3 个指标:
- 1)寻找成功(Finding Success,S):机器人是否在最长的路径步数内找到了人形机器人(面对人形机器人时,机器人的距离在 1-2 米内)?
- 2)根据路径步数加权的寻找成功率(Finding Success Weighted by Path Steps,SPS): 相对于一个拥有完整人形机器人轨迹和环境地图的真实知识的 oracle 来说,机器人找到人形机器人的效率如何?设 l l l 为 oracle 找到人形机器人所需的最小步数, p p p 为机器人的路径步数,则 S P S = S ? l m a x ( l , p ) SPS = S \cdot \frac{l}{max(l,p)} SPS=S?max(l,p)l? 。
- 3)跟踪率(Following Rate,F):机器人在朝向人形机器人的过程中与人形机器人保持 1-2 米距离的步数与最大可能跟随步数之比。对于最长持续时间为 E 的事件,我们假定一旦找到一个掌握人形机器人路径和环境地图的地面真实知识的甲骨文,它就能始终跟随人形机器人。因此,这样一个神谕的跟随步数为 E - l,其中 l 是找到人形机器人所需的最小步数。让 w 表示智能体跟随人形的步数,则跟随率 F = wmax(E-l,w)。
- 4)碰撞率(Collision Rate,CR):智能体与仿人机器人发生碰撞的事件比例。更多指标详情见附录 A。
Baselines
我们比较了社交导航任务中的两种方法:
- 启发式专家(Heuristic Expert):我们创建了一个可以访问环境地图的启发式基线,它使用最短路径规划器生成一条通往仿人机器人当前位置的路径。启发式专家遵循以下逻辑: 当智能体距离仿人机器人超过 1.5 米时,它会使用 "查找 "行为,即使用路径规划器接近仿人机器人。如果人形机器人在 1.5 米以内,它就会使用后备动作,以避免与人形机器人相撞。
- 端到端 RL(End-to-end RL):使用 DDPPO 训练的 “传感器到行动” 递归神经网络策略。该策略的输入为以自我为中心的手臂深度、仿人探测器和仿人 GPS,输出为机器人本地帧中的速度指令。该策略无法访问环境地图。架构和训练详情见附录 A。我们还提供了消融案例,研究不同传感器对策略输入的影响。
Scenes and Robot
我们将生境合成场景数据集(HSSD)纳入 Habitat 3.0,并使用波士顿动力公司的 Spot 机器人。我们使用了 37 个训练场景、12 个验证场景和 10 个测试场景。有关机器人和场景的详细信息,请参阅附录 D 和 E。
Results
图 3 显示了不同基线的性能。启发式专家的搜索成功率(S)为 100%,而端到端 RL 策略的搜索成功率(S)为 97%。这是意料之中的,因为启发式专家有访问环境地图的特权,可以计算出通往仿人机器人的最短路径,而 RL 策略则必须探索环境。因此,启发式专家寻找 SPS 的能力也高于端到端 RL 策略。不过,即使无法获得地图,RL 策略也能通过预测人形机器人的运动、后退以避免碰撞以及在狭窄空间中让路来学习跟随人形机器人,从而获得与启发式专家相似的成功率(S)和碰撞率(CR),启发式为 0.52,RL 策略为 0.51±0.03,以及具有竞争力的 SPS 和跟随率 F,启发式专家为 0.51,RL 策略为 0.44±0.01。定性结果请参阅补充视频和附录 C.1。
Ablations
我们分析了单个传感器对端到端 RL 策略性能的影响(图 3 底行)。一般来说,结果可分为两种情况:找到仿人机器人之前和之后。在找到仿人机器人之前,仿人机器人的 GPS 系统是最重要的传感器,因为它能帮助智能体确定仿人机器人的位置。因此,不使用仿人机器人 GPS 的基线寻找成功率和 SPS 最低。然而,在找到仿人机器人后,手臂感知(RGB 或深度)变得非常重要,因为智能体在跟随仿人机器人时会使用这些信息来避免碰撞。因此,与带有深度或 RGB 传感器的基线相比,不带手臂摄像头的基线往往具有更高的碰撞率和更低的跟随率。
4.2 SOCIAL REARRANGEMENT
Task Description
在这项任务中(图 4,左),机器人的目标是高效地协助仿人合作者将两个物体从已知的初始位置重新排列到指定目标。物体位置和目标在机器人的起始坐标系中被指定为三维坐标。我们对 [引文1] 的社交重新排列(Social Rearrangement)进行了修改,将其推广到异构智能体(一个仿人机器人和一个机器人),并处理更多样化、未知的环境和仿人合作者。这些物体在一个不可见的房子(有多个房间)中的开放式容器中产生,并在房子中的另一个开放式容器中分配一个目标。机器人可以访问自己的自我中心深度摄像头、本体感觉状态信息(手臂关节角度和基本自我运动)以及仿人机器人的相对距离和方向。但是,它无法获取人形机器人的行动、意图或完整状态。当所有物体都放置在所需位置或达到允许的最大步数时,事件结束。在评估过程中,训练好的机器人会与新的人类或仿人机器人伙伴在不同的、未见过的家庭中进行协作,本节稍后将对此进行介绍。
[引文1] Adaptive Coordination in Social Embodied Rearrangement,2023
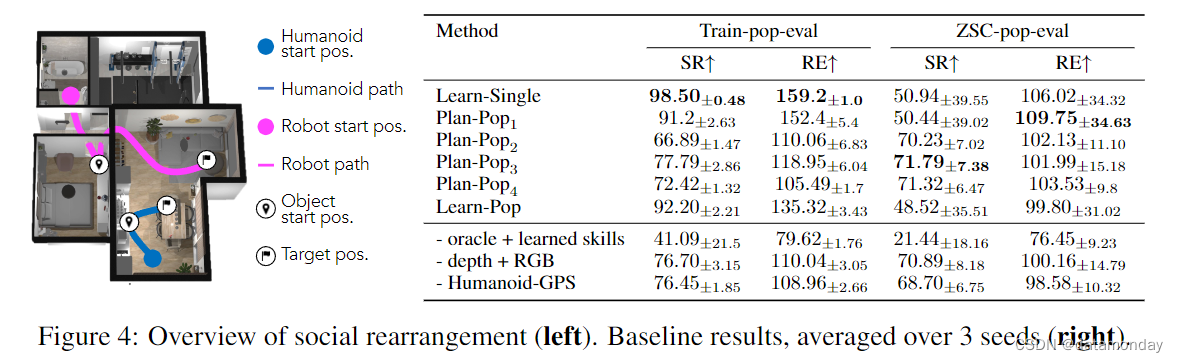
Metrics
我们用两个指标对所有方法进行评估:
- 1)在一个未见过的家庭中完成任务的成功率(Success Rate,SR),以及未见过的物体配置。如果两个物体都在允许的最大轮数(episode)步骤内放置在目标位置,则该集被认为是成功的(SR = 1)。
- 2)相对于单独完成任务的仿人机器人而言,完成任务时的相对效率(Relative Efficiency,RE)。对于最大允许步数为 E 的轮数(episode),如果人形机器人单独完成任务需要 L h u m a n L^{human} Lhuman 步,而人形机器人团队完成任务需要 L j o i n t L^{joint} Ljoint 步,则 R E = L h u m a n m a x ( L j o i n t , E ) RE = \frac{L^{human}}{max(L^{joint}, E)} RE=max(Ljoint,E)Lhuman? 。如果仿人机器人团队完成任务的步数是仿人机器人单独完成任务步数的一半,则 RE 为 200%。
Policy architecture.
我们在所有基线中都采用了双层策略架构,其中学习型高级策略会根据观察结果,从预定义的技能库中选择低层次(low-level)技能来执行。我们考虑了机器人低层次技能的两种变体:Oracle 技能和学习的低层次技能。
- Oracle 技能使用特权信息,即用于导航的环境地图和完美的 “即时” 拾取/放置技能。
- 学习的低层次技能经过预先训练和冻结,但符合实际情况,不假定特权信息,因此会出现更多低层次故障。
详情请参阅附录 A。所有仿人低层次技能如第 3.1 节所述。
Baselines
我们在社交重排任务中研究了3种不同的基于群体的方法(Jaderberg et al.,2019),其中单个高级机器人策略被训练为与“群体”内的合作者协调。在训练过程中,每一轮(episode)都会从群体中随机选择一个合作者,并训练机器人与之合作。机器人策略采用端到端 RL 训练,所有方法都使用相同的策略架构、训练参数和场景。这些方法仅在训练群体上有所不同。
-
Learn-Single:在此基线中,我们联合学习仿人机器人和机器人策略;群体由单一的仿人机器人策略组成,因此训练合作者的多样性较低。
-
Plan-Popp:我们考虑了四种不同的群体规模,协作者由特权任务计划者驱动。这导致了四个基线(以 p 为索引),由 1 到 4 的人口规模组成。
- 1)p = 1 是规模为 1 的群体,人形协作者在所有事件中始终重新排列同一物体。
- 2)p = 2 是规模为 2 的群体,每个合作者负责两个物体中的一个。
- 3)p = 3 是指规模为 3 的群体,合作者重新摆放一个或两个物体。
- 4)p = 4 是规模为 4 的群体,合作者重新排列其中一个、两个或任何一个物体。
- 需要注意的是,在所有基线中,每次场景中只有一个人形机器人,从群体中随机抽取。我们对每个群体训练不同的机器人策略,并展示所有四种基线的结果。
-
Learn-Pop:在这一基线中,我们不是依靠特权规划者来形成群体,而是按照群体游戏(Population-play,Jaderberg et al.,2019)的方法来学习协作者群体。考虑到不同的初始化可能会导致不同的最终行为,我们随机初始化了 8 个仿人策略。在训练过程中,每一集都会将从该群体中随机选择的仿人策略与机器人配对,并在协作任务中对两者进行联合训练。这一基线检验了随机初始化在学习群体中的有效性。
Evaluation population
我们使用了与社交导航任务相同的智能体体现和训练/评估数据集。不过,社交重新排列评估额外考虑了表现出不同高级行为的不同协作者。我们结合所有基线的训练合作者子集,创建了一个由 10 个合作者组成的零样本协调(ZSC-pop-eval)群体。具体来说,我们从 Learn-Single 和 Learn-Pop 基线中收集了 3 个学习到的仿人策略,以及 4 个基于计划者的协作者(Plan-Popp 中的每个群体 p 均有一个)。因此,每个基线在学习过程中都看到了大约 1/3 的 ZSC-eval 合作者,并需要将其推广到剩余的 2/3 群体中。我们还针对其训练群体(train-pop-eval)对每种方法进行了评估,但都是在未见过的场景和环境配置下进行的。这样,我们就可以研究与已知合作者合作(train-pop-eval)和与未知合作者合作(ZSC-pop-eval)之间的差异。
Results
图 4 显示了不同基线的 train-pop 和 ZSC-pop 评估结果。Learn-Single 和 Plan-Pop1 在对其训练群体进行评估时,成功率最高。这也是意料之中的,因为它们都是只用一个伙伴进行训练,因此训练设置最简单。然而,在 ZSC-pop-eval 期间,它们的成功率明显下降(98.50% → 50.9% 和 91.2% → 50.4%)。这是因为这些基线方法只接受过与单一伙伴协调的训练,因此对与其训练伙伴不同的伙伴的适应性较差。在群体大于 1 的训练方法中,Learn-pop 的训练-群体 SR 最高,但 ZSC-eval 性能较差(92.2% → 48.5%),原因是学习群体的新兴多样性较低。相比之下,Plan-pop2,3,4 在 train-pop 和 ZSC-pop 之间的性能下降幅度较小,这表明它们有能力适应不可见的伙伴。其中,Plan-pop3,4 的表现类似,ZSC-pop-eval SR 最高,达到 71.7%。我们在 RE 方面也观察到类似的趋势,Learn-Single 在使用 train-pop 时的 RE 最高,而在使用 ZSC-pop 时则有所下降(159.2 → 106.0)。Plan-pop3,4 的下降幅度较小(Plan-pop3,4 为 105.49 → 101.99),但在 ZSC-pop-eval 中,平均 RE 值与 Learn-Single 和 Plan-Pop1 相近。这是因为从 10 个 ZSC 伙伴的平均结果来看,Learn-Single 能显著提高某些伙伴的效率,而另一些则效率低下,这一点从其较大的方差中可以看出。另一方面,Plan-pop3,4 能够适应并使大多数合作伙伴的效率略有提高,这一点可以从其较低的方差看出,但平均表现与 Learn-Single 相似。更多详情和其他分析,请参阅附录 C。
Ablations
我们对使用 Plan-Pop3 群体训练的机器人策略输入进行了消融实验(图 4(右),最下面几行)。我们用非特权学习的低级技能替换 "oracle "技能,而不重新训练高级策略。我们发现,由于低级执行失败,性能明显下降(train-pop-eval SR 中为 77.79% → 41.96%),这表明可以通过用学习到的技能训练高级策略来提高性能,从而更好地适应此类失败。我们还用 RGB 而不是深度来重新训练策略,结果发现性能并没有下降。移除仿人 GPS 会导致 SR 和 RE 略有下降,这表明该传感器对协作非常有用,尤其是在 ZSC 环境中,但并非必不可少。
4.3 HUMAN-IN-THE-LOOP EVALUATION
我们通过人在回路(HITL)工具测试了经过训练的机器人智能体与真人协调的能力,共有 30 人参加了测试。经过简短的键盘/鼠标控制培训后,我们要求参与者在数据集中的测试场景中执行社交重组任务。具体来说,研究在三种条件下进行:单独执行任务(单人)、与使用 Learn-Single 操作系统的机器人配对或与 Plan-Pop3 智能体配对。每位参与者在其中一个测试场景中,在每个条件下执行任务 10 次。我们测量所有事件中的碰撞率(CR)、任务完成步骤(TS)、机器人完成任务比率(RC)和相对效率(RE)。RE 与第 4.2 节相同。CR 是机器人与仿人机器人发生碰撞的次数比例。RC 是机器人每集重新排列物体的比例。

Plan-Pop3 和 Learn-Single 的 RE 分别提高了123%和134%(表1)。这表明,与人类单独操作相比,机器人提高了人类的效率,即使是对于完全不认识的真实人类伙伴也是如此。我们的分析表明,单人操作与 Learn-Single 操作、单人操作与 Plan-Pop3 操作之间的 TS 估计平均值成对差异显著,但 Learn-Single 操作与 Plan-Pop3 操作之间的 TS 估计平均值差异不显著(详见附录 G)。尽管 Plan-Pop3 的 RE 值低于 Learn-single,但根据 RC 值衡量,Plan-Pop3 的任务卸载率更高。
一般来说,我们观察到人类对机器人行为的反应比 ZSC 智能体更灵敏,这导致所有事件的成功率都是 1,而且 RE 很高。例如,人类会根据推断出的机器人目标迅速调整自己的计划,或者让开道路让机器人通过。然而,我们的自动评估和 HITL 评估之间的平均 RE 和 RC 的相对顺序仍然成立,其中 Learn-Single 使伙伴的效率高于 Plan-Pop3,但 Plan-Pop3 的 RC 却高于 Learn-Single。这揭示了几个有趣的现象:
- 1)当与真实的人类伙伴一起进行评估时,自动评估管道可以显示不同方法的相对排序。
- 2)我们的 ZSC 智能体没有准确捕捉到人与机器人交互的动态,还有改进的余地。
- 3)即使像 Learn-Single 这样不使用多样化训练群体的方法,也能比单独执行任务提高人类的效率。
5 CONCLUSION
我们介绍 Habitat 3.0,这是一款具身人工智能模拟器,旨在高效模拟丰富多样的室内场景中的人形机器人。Habitat 3.0 支持人形化身的各种外观和动作,同时确保逼真度和较快的模拟速度。除了仿真人形外,我们还提供了通过鼠标/键盘或虚拟现实(VR)界面对仿人虚拟化身进行人在回路(HITL)控制的基础设施。通过该界面,我们可以在仿真中收集真实的人机交互数据,并评估机器人与真人的交互策略。有了这些功能,我们就能在自动和人在环评估设置中研究两种协作任务——社交导航和社交重新排列。我们在所学策略中观察到了新出现的协作行为,例如安全地跟随人形机器人,或通过分工提高它们的效率。我们的 HITL 分析揭示了增强社交智能体的途径,我们希望 Habitat 3.0 能够加速这一领域的未来研究。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!