【Hadoop_05】NN、2NN以及DataNode的工作机制
1、NameNode和SecondaryNameNode
1.1 NN和2NN工作机制
思考:NameNode中的元数据是存储在哪里的?
- 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
- 这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。==因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。==这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
- 但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
FsImage记录的是结果的值,比如a=100、b=30等。Edits记录的是计算的步骤,比如a*2、b-12等。因此FsImage和Edits需要合并。
- 当服务器一启动的时候,就会将FsImage和Edits加载到内存。
- 当服务器一关机的时候,就会将FsImage和Edits进行合并。【是2NN将这两个文件定期合并】
NameNode工作机制:

1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启
动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
1.2 Fsimage和Edits解析

1)oiv查看Fsimage文件
(1)查看oiv和oev命令
[root@hadoop102 current]$ hdfs
oiv:将离线fsimage查看器应用于fsimage
oev:将离线编辑查看器应用于编辑文件
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[root@hadoop102 current]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
[root@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
[root@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/fsimage.xml
将显示的xml文件内容拷贝到Idea中创建的xml文件中,并格式化。部分显示结果如下。
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>user</name>
<mtime>1512722284477</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16387</id>
<type>DIRECTORY</type>
<name>atguigu</name>
<mtime>1512790549080</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16389</id>
<type>FILE</type>
<name>wc.input</name>
<replication>3</replication>
<mtime>1512722322219</mtime>
<atime>1512722321610</atime>
<perferredBlockSize>134217728</perferredBlockSize>
<permission>atguigu:supergroup:rw-r--r--</permission>
<blocks>
<block>
<id>1073741825</id>
<genstamp>1001</genstamp>
<numBytes>59</numBytes>
</block>
</blocks>
</inode >
可以看出,Fsimage中没有记录块所对应DataNode,为什么?
原因:在集群启动后,要求DataNode主动上报数据块信息,并间隔一段时间后再次上报。
2)oev查看Edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
[root@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
[root@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/edits.xml
将显示的xml文件内容拷贝到Idea中创建的xml文件中,并格式化。显示结果如下。
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>129</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD</OPCODE>
<DATA>
<TXID>130</TXID>
<LENGTH>0</LENGTH>
<INODEID>16407</INODEID>
<PATH>/hello7.txt</PATH>
<REPLICATION>2</REPLICATION>
<MTIME>1512943607866</MTIME>
<ATIME>1512943607866</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-1544295051_1</CLIENT_NAME>
<CLIENT_MACHINE>192.168.10.102</CLIENT_MACHINE>
<OVERWRITE>true</OVERWRITE>
<PERMISSION_STATUS>
<USERNAME>atguigu</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
<RPC_CLIENTID>908eafd4-9aec-4288-96f1-e8011d181561</RPC_CLIENTID>
<RPC_CALLID>0</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<DATA>
<TXID>131</TXID>
<BLOCK_ID>1073741839</BLOCK_ID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<DATA>
<TXID>132</TXID>
<GENSTAMPV2>1016</GENSTAMPV2>
1.3 CheckPoint时间设置
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description> 1分钟检查一次操作次数</description>
</property>
2、DataNode
2.1 DataNode工作机制
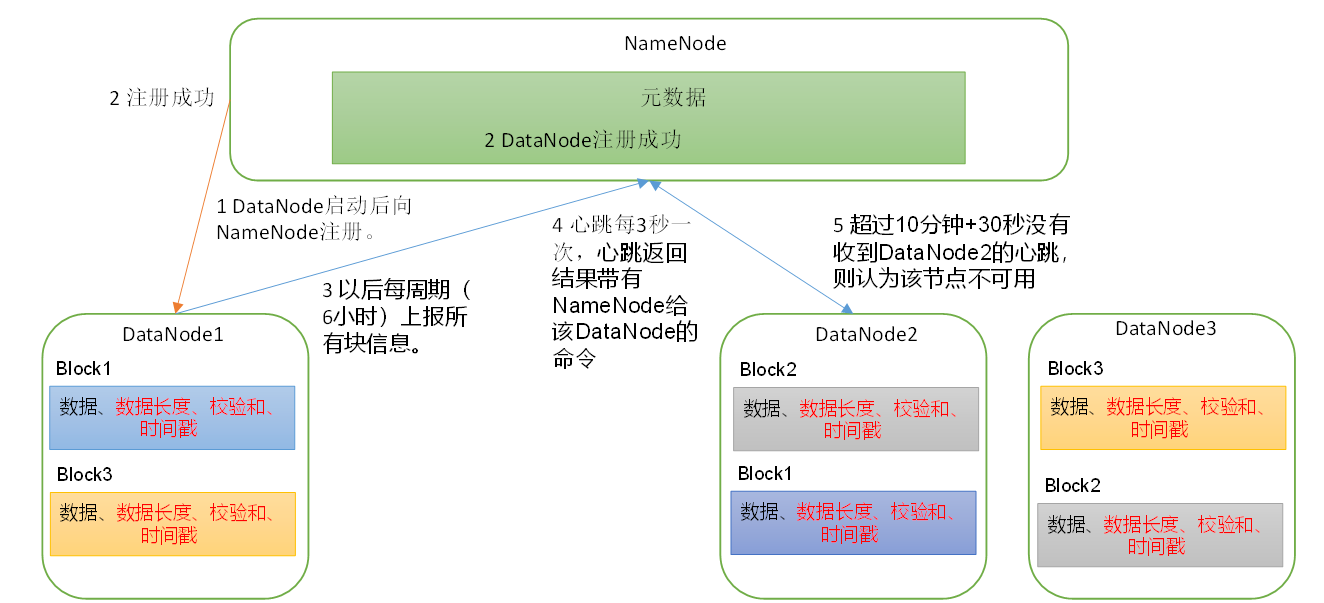
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息。
DN向NN汇报当前解读信息的时间间隔,默认6小时;
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
DN扫描自己节点块信息列表的时间,默认6小时
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>21600s</value>
<description>Interval in seconds for Datanode to scan data
directories and reconcile the difference between blocks in memory and on the disk.
Support multiple time unit suffix(case insensitive), as described
in dfs.heartbeat.interval.
</description>
</property>
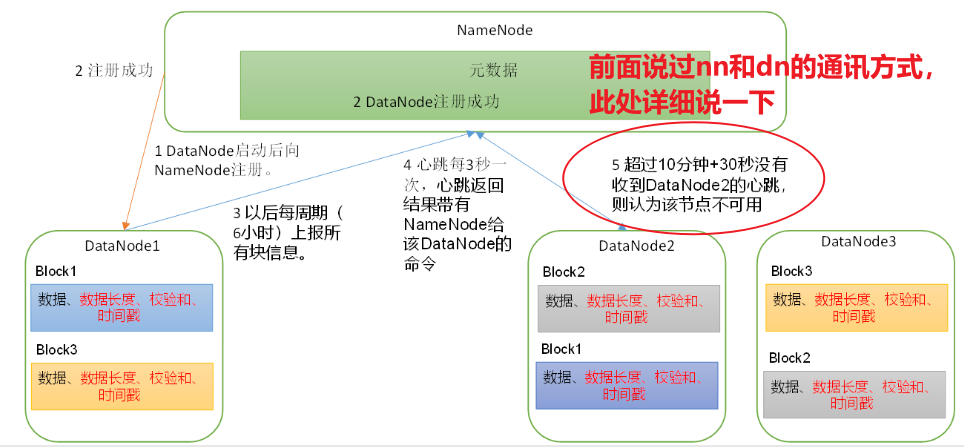
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
2.2 数据完整性
如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理DataNode节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是DataNode节点保证数据完整性的方法。
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)常见的校验算法crc(32),md5(128),sha1(160)
(5)DataNode在其文件创建后周期验证CheckSum。
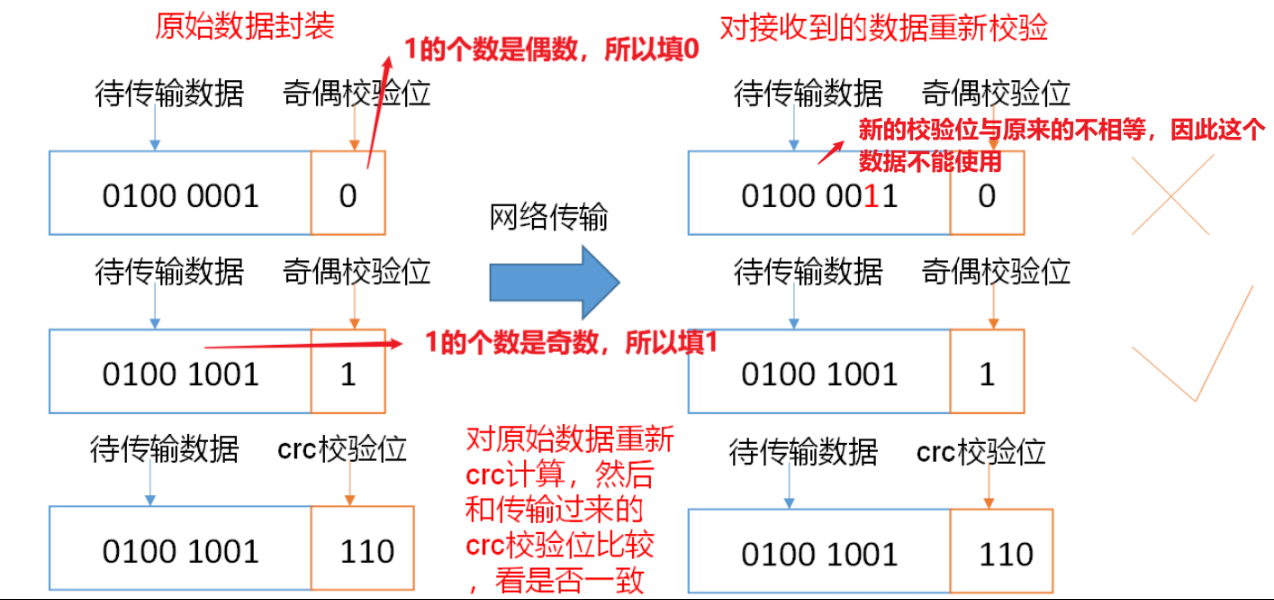
- 实际上使用的不是简单的奇偶校验,而是采用crc校验位。
2.3 掉线时限参数设置
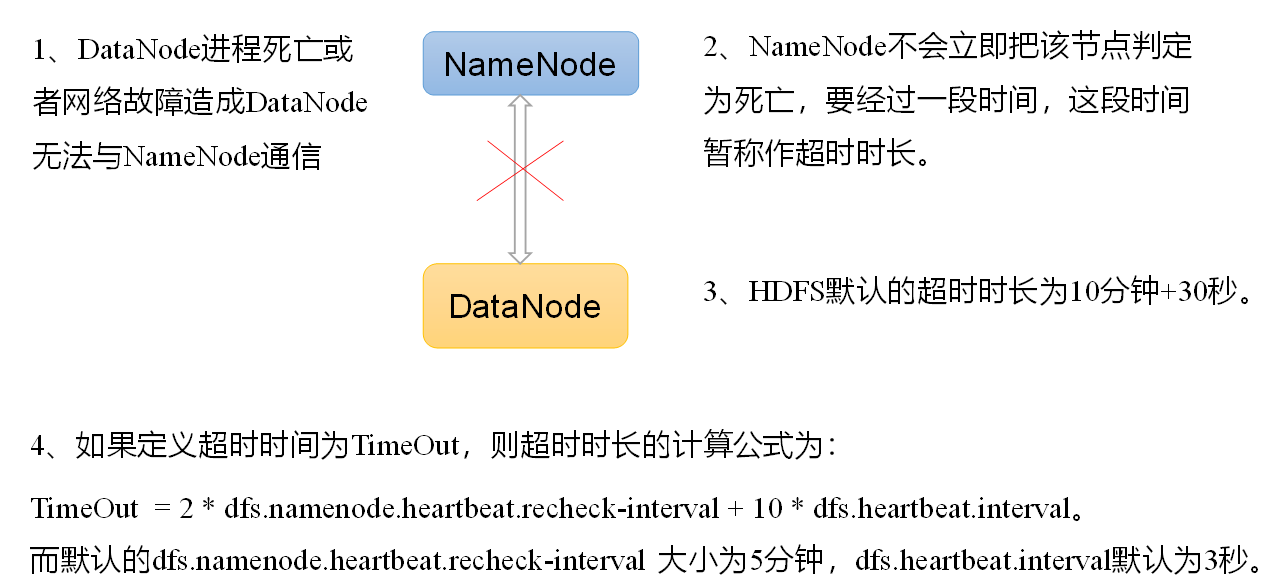

需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
300000毫秒=300秒=5分钟
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!