Redis原理及常见问题
高性能之道
- 单线程模型
- 基于内存操作
- epoll多路复用模型
- 高效的数据存储结构
redis的单线程指的是数据处理使用的单线程,实际上它主要包含
- IO线程:处理网络消息收发
- 主线程:处理数据读写操作,包括事务、Lua脚本等
- 持久化线程:执行RDB或AOF时,使用持久化线程处理,避免主线程的阻塞
- 过期键清理线程:用于定期清理过期键
至于redis为什么使用单线程处理数据,是因为redis基于内存操作,并且有高效的数据类型,它的性能瓶颈并不在CPU计算,主要在于网络IO,而网络IO在后来的版本中也被独立出来了IO线程,因此它能快速处理数据,单线程反而避免了多线程所带来的并发和资源争抢的问题
全局数据存储
Redis底层存储基于全局Hash表,存储结构和Java的HashMap类似(数组+链表方式)

rehash
Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新进行打散映射到hash表2中;这个过程采用渐进式hash
即拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries - 释放哈希表 1 的空间。
数据类型
查看存储编码类型:object encoding key
1. string
源码位置:t_string.c
string是最常用的类型,它的底层存储结构是SDS
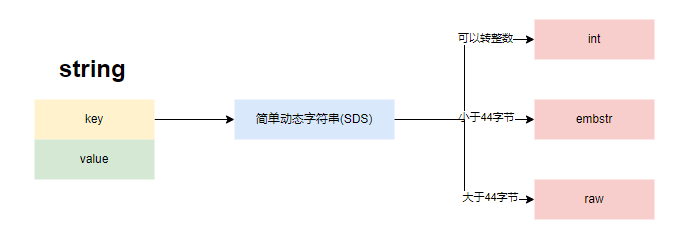
存储结构
redis的string分三种情况对对象编码,目的是为了节省内存空间:
robj *tryObjectEncodingEx(robj *o, int try_trim) |
|
- if: value长度小于20字节且可以转换为整数(long类型),编码为OBJ_ENCODING_INT,其中若数字在0到10000之间,还可以使用内存共享的数字对象
- else if: 若value长度小于OBJ_ENCODING_EMBSTR_SIZE_LIMIT(44字节),编码为OBJ_ENCODING_EMBSTR
- else: 保持编码为OBJ_ENCODING_RAW
常用命令
SET key value |
|
MSET key value [key value ...] |
|
SETNX key value #常用作分布式锁 |
|
GET key |
|
MGET key [key ...] |
|
DEL key [key ...] |
|
EXPIRE key seconds |
|
INCR key |
|
DECR key |
|
INCRBY key increment |
|
DECRBY key increment |
常用场景
- 简单键值对
- 自增计数器
INCR作为主键的问题
- 缺陷:若数据量大的情况下,大量使用INCR来自增主键会让redis的自增操作频繁,影响redis的正常使用
- 优化:每台服务可以使用INCRBY一次性获取一百或者一千或者多少个id段来慢慢分配,这样能大量减少redis的incr命令所带来的消耗
2. list
源码位置:t_list.c
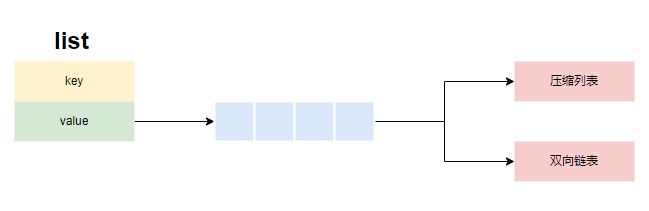
存储结构
redis的list首先会按紧凑列表存储(listPack),当紧凑列表的长度达到list_max_listpack_size之后,会转换为双向链表
// 1.LPUSH/RPUSH/LPUSHX/RPUSHX这些命令的统一入口 |
|
void pushGenericCommand(client *c, int where, int xx) |
|
// 2.追加元素,并尝试转换紧凑列表 |
|
void listTypeTryConversionAppend(robj *o, robj **argv, int start, int end, beforeConvertCB fn, void *data) |
|
// 3.尝试转换紧凑列表 |
|
static void listTypeTryConversionRaw(robj *o, list_conv_type lct, robj **argv, int start, int end, beforeConvertCB fn, void *data) |
|
// 4.尝试转换紧凑列表 |
|
// 若紧凑列表的长度达到list_max_listpack_size之后,则转换 |
|
static void listTypeTryConvertQuicklist(robj *o, int shrinking, beforeConvertCB fn, void *data) |
|
当redis进行list元素移除时
// 1.移除list元素的统一入口 |
|
void listElementsRemoved(client *c, robj *key, int where, robj *o, long count, int signal, int *deleted) |
|
// 2.尝试转换 |
|
void listTypeTryConversion(robj *o, list_conv_type lct, beforeConvertCB fn, void *data) |
|
// 3.尝试转换 |
|
static void listTypeTryConversionRaw(robj *o, list_conv_type lct, robj **argv, int start, int end, beforeConvertCB fn, void *data) |
|
// 4.尝试转换双向链表 |
|
// 若双向链表中只剩一个节点,且是压缩节点,则对双向链表转换为紧凑列表 |
|
static void listTypeTryConvertQuicklist(robj *o, int shrinking, beforeConvertCB fn, void *data) |
|
以下参数可在redis.conf配置
list_max_listpack_size:默认-2
常用命令
LPUSH key value [value ...] |
|
RPUSH key value [value ...] |
|
LPOP key |
|
RPOP key |
|
LRANGE key start stop |
|
BLPOP key [key ...] timeout #从key列表头弹出一个元素,若没有元素,则阻塞等待timeout秒,0则一直阻塞等待 |
|
BRPOP key [key ...] timeout #从key列表尾弹出一个元素,若没有元素,则阻塞等待timeout秒,0则一直阻塞等待 |
组合数据结构
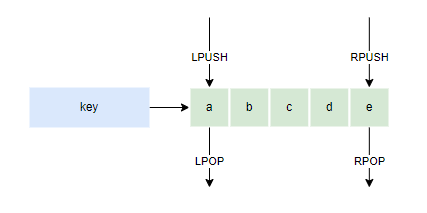
根据list的特性,可以组成实现以下常用的数据结构
- Stack(栈):LPUSH + LPOP
- Queue(队列):LPUSH + RPOP
- Blocking MQ(阻塞队列):LPUSH + BRPOP
redis实现数据结构的意义在于分布式环境的实现
常用场景
- 缓存有序列表结构
- 构建分布式数据结构(栈、队列等)
3. hash
源码位置:t_hash.c
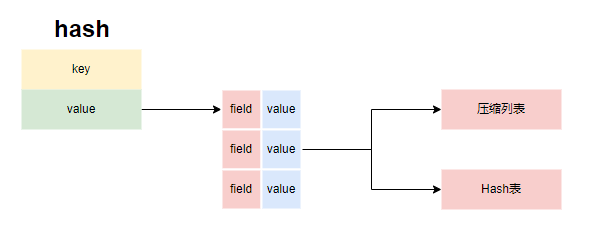
存储结构
redis的hash首先会按紧凑列表存储(listPack),当紧凑列表的长度达到hash_max_listpack_entries或添加的元素大小超过hash_max_listpack_value之后,会转换为Hash表
// 1.添加hash元素 |
|
void hsetCommand(client *c) |
|
void hsetnxCommand(client *c) |
|
// 2.尝试转换Hash表 |
|
// 若紧凑列表的长度达到hash_max_listpack_entries |
|
// 或添加的元素大小超过hash_max_listpack_value |
|
// 则进行转换 |
|
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) |
|
// 3.尝试转换Hash表 |
|
void hashTypeConvert(robj *o, int enc) |
|
// 4.转换Hash表 |
|
void hashTypeConvertListpack(robj *o, int enc) |
|
以下参数可在redis.conf配置
hash_max_listpack_value:默认64
hash_max_listpack_entries:默认512
常用命令
HSET key field value |
|
HSETNX key field value |
|
HMSET key field value [field value ...] |
|
HGET key field |
|
HMGET key field [field ...] |
|
HDEL key field [field ...] |
|
HLEN key |
|
HGETALL key |
|
HINCRBY key field increment |
常用场景
- 对象缓存
4. set
源码位置:t_set.c
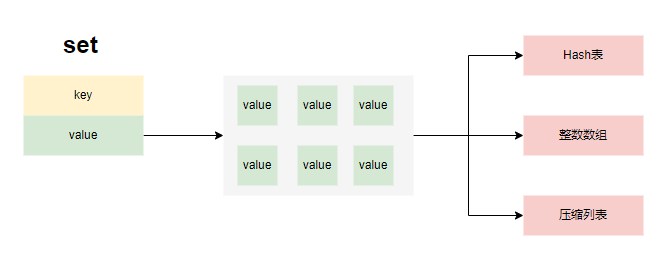
存储结构
- redis的set添加元素时,若存储对象是整形数字且集合小于set_max_intset_entries,则存储为OBJ_ENCODING_INTSET,若集合长度小于set_max_listpack_entries时,存储为紧凑列表。否则,存储为Hash表
// 1.添加set元素 |
|
void saddCommand(client *c) |
|
// 2.1.创建set表 |
|
// 若存储对象是整形数字且集合小于set_max_listpack_entries,则存储为OBJ_ENCODING_INTSET |
|
// 若集合长度小于set_max_listpack_entries时,存储为紧凑列表 |
|
// 否则存储为Hash表 |
|
robj *setTypeCreate(sds value, size_t size_hint) |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!