ES查询流程
在ES中查询分为两类:1.基于文档ID查询,2.按照非文档ID查询。
基于文档id查询
1.基于文档ID查询
当执行如下查询时:
GET /megacorp/employee/1
ES在执行上述查询的具体过程如下:
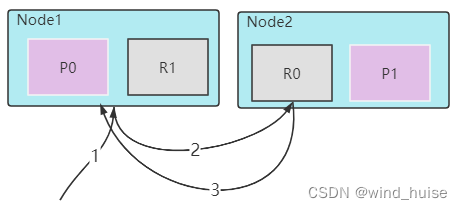
1、客户端向 Node 1 发送获取请求,此时Node1为协调者节点。
2、协调者节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有节点第的三个节点上。 在这种情况下,它将请求转发到 Node 2 。
3、Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
按照非文档ID查询
先看一个同时包含分页,排序,字段值过滤的查询流程。
1.基于其他条件查询
基于其他条件进行文档检索的过程分为:查询和获取。
查询
由于不确定被检索的文档在多个分片中的分布情况,所以会在所有分片上进行文档查询,所以当一个索引的主分片比较多的时候,检索性能反而不高。
具体检索的过程如下:
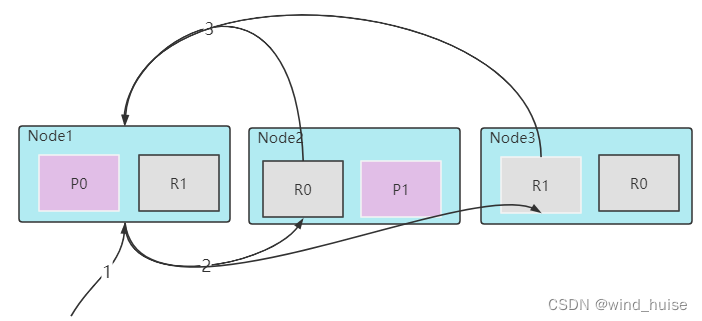
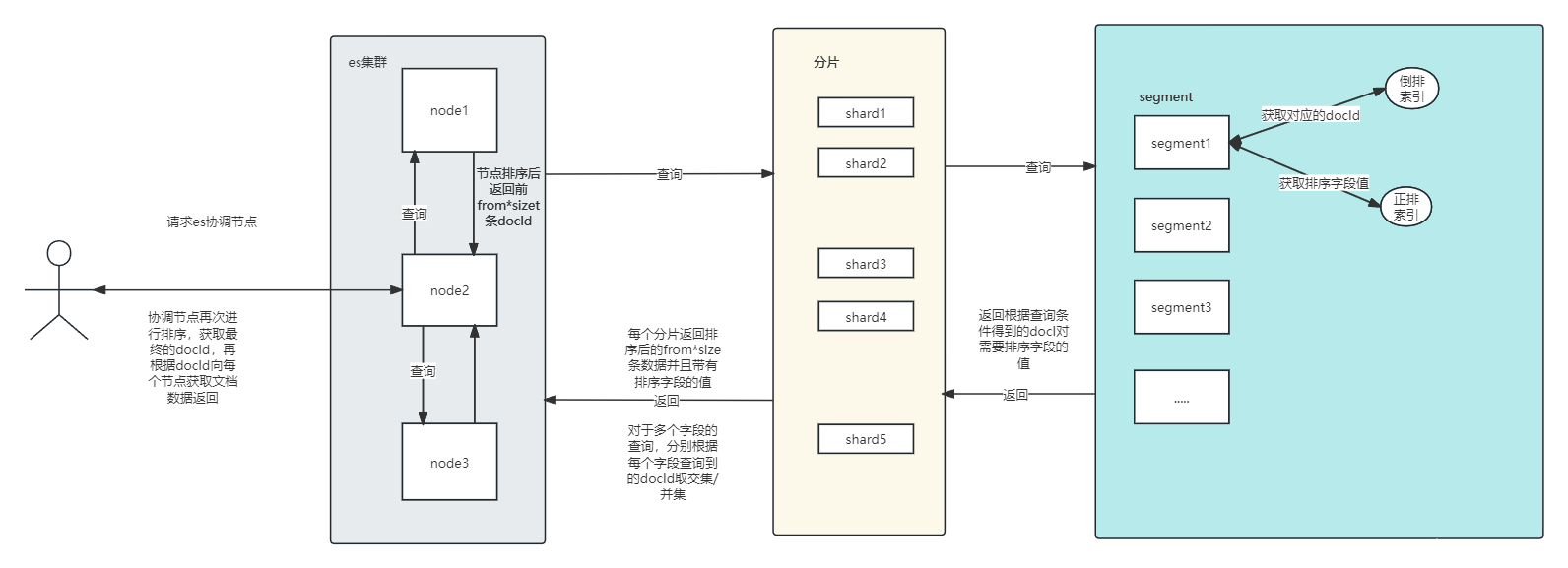
1.客户端发送检索请求,此时ES集群中的某个节点会接受到这个请求,接受请求的节点,被称为协调者节点,如图中Node1。
2.协调者节点将检索请求发送到所有主分片/从分片上,如图上Node2中的R0和Node3中的R1,各个主从分/从分片在所在节点本地执行检索请求。此时检索的结果仅仅是符合条件的文档ID和对应排序字段的值,默认情况下,这个排序字段为相关性评分_score(评分是在查询的时候计算的)。
3.各个分片所在的节点将检索的结果返回给协调节点。
获取
经过查询过程,协调者节点获得了目标文档的ID和文档中对应的排序字段值。基于这些结果数据,接下来会执行数据获取的操作:
1.协调者节点根据排序逻辑和分页逻辑,从结果集数据中筛选最终需要的文档ID。协调者节点根据结果文档ID,计算出文档所在的分片信息,然后向某个或某些个目标分片(如图中Node1的R0和Node2的R1)发送 multi-get request请求,获取文档的全部信息。
2.目标分片将文档数据返回给协调者节点。
3.协调者节点将获取到的结果文档数据,返回给客户端。
上述取回数据的过程和关系型数据库中的普通索引回表过程类似。
2.深度分页查询问题
在分布式系统中,对于分页查询的场景,我们需要了解一下深度分页的性能问题,这是在分布式系统中,比较常见的一个问题。在讨论深度分页问题前,我们先熟悉一下分布式系统中的分页问题。
分页查询通常会伴随着排序问题,如果不按照某个指标进行排序的话,那么分页就没有意义了,如果不进行排序,那么如何区分第一个和第二页的内容呢?
当向分布式系统提交一个分页查询时,该查询请求会被转发到分布式系统中的各个子节点上,在每个子节点中执行该查询,但是我们需要知道,每个子节点的查询结果只是在该节点上的一个局部结果,并不是全局结果,全局结果是所有子节点查询结果的一个综合结果。只有每个局部结果数据集比较"完整"才能保证全局结果的正确性。
这里的完整怎么理解呢?
假如我们把学生考试成绩存储在一个有3个节点的分布式系统中,此时我们需要获取成绩排名第5到第10的学生信息,那么此时的查询流程如下:
1.每个节点需要查询出当前节点,所拥有数据集中学生成绩排名前10的学生信息。
2.汇总30名学生信息,然后从30名学生中找出考试成绩排名在第5到第10名的6位学生。
这里我们会发现,我们的查询请求只需要6名学生信息,但是查询过程却需要对30名学生信息进行处理。具体可以参考下图:
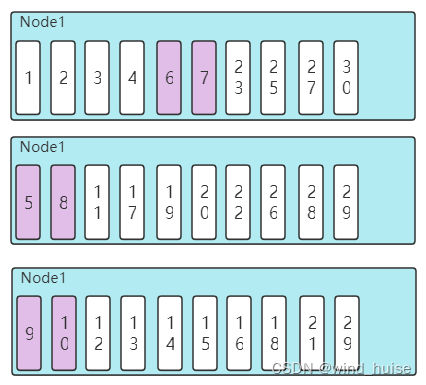
通过上图我们可以发现,考试成绩排名在第5到第10的6名学生信息,在3个节点中的分布并不是在第5到第10的存储位置,有可能分布在第1到第10的任何位置,所以为了保证全局数据的准确性,每个子节点要获取考试成绩是前10名的 10个学生的信息才可以。
上面的查询需求翻译成查询语句就是:按照考试成绩排序后的学生信息集合中 ,查询从考试成绩第5名开始的后5位学生信息。或者是:在分页大小为5的查询中,获取第2页数据。此时各个子节点需要查询的数据量其实是:pagesize*pagenum。
在ES中的查询语句如下:
GET /_search
{
"from": 5,
"size": 5
}
此时我们在回到上面的问题,在分布式系统中执行深度分页查询时(页码比较大),会导致子节点的系统资源被大量占用,查询性能迅速下降。
实际上, “深分页” 不太符合人的行为。当2到3页过去以后,人会停止翻页,或者改变搜索标准,试想一下你在搜索引擎搜索信息时,通常只会看前2页的搜索结果
3、多个字段查询
当在Elasticsearch中进行多个字段作为条件的查询时,查询的流程如下:
针对一个分片进行理解就好了
- 查询语句中包含多个字段的查询条件时,Elasticsearch会使用倒排索引来快速定位匹配的文档。倒排索引是一种以词项为基础的索引结构,它将文档的内容映射到词项上,提供了更高效的文本搜索和检索能力。
- Elasticsearch会根据查询条件中的每个字段,独立地在倒排索引中进行匹配。每个字段的匹配结果将返回与之关联的文档集合。注意,这个阶段还会把排序字段返回。
- 接下来,Elasticsearch会对每个字段的匹配结果进行交集操作。交集操作将返回同时满足所有字段条件的文档集合。如果存在多个字段的匹配结果,Elasticsearch会使用布尔查询(Boolean Query)来组合这些条件。
- 最后,根据查询语句中的排序条件(如果有的话),Elasticsearch会对结果进行排序。排序操作会增加查询的复杂性和计算成本,因此在使用排序功能时应该权衡好性能和需求。
需要注意的是,Elasticsearch中的查询流程可以根据查询语句的具体结构和查询需求进行调整和优化。例如,可以通过使用布尔查询(Boolean Query)来组合多个查询条件,或者使用过滤器(Filter)来优化特定条件的过滤等。
总之,Elasticsearch通过使用倒排索引和布尔查询等机制,可以高效地处理多个字段作为条件的查询请求,并返回满足条件的文档集合。
4、范围查询
Elasticsearch中处理数值范围查询,可以通过使用range查询来实现。range查询允许你指定一个字段的范围条件,并返回符合该条件的文档。
以下是一个示例查询,展示如何使用range查询来处理数值范围:
bash复制代码
GET /my_index/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 200
}
}
}
}
上述查询将在名为"my_index"的索引中执行一个范围查询,针对"price"字段的值在100到200之间的文档进行匹配。gte表示大于等于(greater than or equal),lte表示小于等于(less than or equal)。
Elasticsearch会利用倒排索引来快速定位满足条件的文档。对于数值类型的字段,Elasticsearch会将数值映射到倒排索引中,以便进行范围比较。它会查找满足条件的价格词汇,并返回与这些词汇关联的文档集合。
5、排序
般都是首先通过一些条件过滤出一部分的id
再通过文档id查询正排索引,得到排序字段的值,进行排序。或者分组。
特别是分组,甚至不需要读取存储在es中的原,仅通过正排索引就能得到结果
为什么不开启正排索引的字段,无法进行排序
不开启正排索引的字段无法进行排序的原因主要是因为正排索引是用于支持文档内容查找和排序的索引。
正排索引将文档ID与文档内容关联起来,使得可以通过文档ID直接定位到文档内容,从而实现基于文档内容的排序操作。如果未开启正排索引,则无法建立文档ID与文档内容的关联关系,因此无法进行基于文档内容的排序。
如果仅仅通过倒排索引,那么一个索引值首先就会对应多个id,如果要排序,就要全量从磁盘中获取文档的全部数据,那么再进行排序就很困难, 因为数据量很大,很难将数据都放到内存中进行排序。
另外,正排索引的建立和维护相对简单,可以快速响应排序请求,提高查询效率。而如果未开启正排索引,则需要对所有文档进行扫描,效率低下,无法满足实时排序的需求。
总之,为了实现基于文档内容的排序操作,需要开启正排索引。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!