docker 安装elasticsearch、kibana、cerebro、logstash
安装步骤
第一步安装 docker
第二步 拉取elasticsearch、kibana、cerebro、logstash 镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.2
docker pull docker.elastic.co/kibana/kibana:7.10.2
docker pull lmenezes/cerebro:latest
docker pull logstash:7.5.1
第三步、创建 容器
创建elasticsearch 容器
docker run -itd --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.2
该命令会创建一个名为 elasticsearch 的容器,并将主机的 9200 端口与容器内部的 9200 端口关联起来。同时设置 discovery.type 参数为 single-node,表示单节点模式。
可能出现的问题
问题一
Docker容器启动时报错ERROR: for elasticsearch Cannot start service elasticsearch: driver failed programm.
错误原因:
docker服务启动时定义的自定义链docker,由于centos7 firewall 被清掉
firewall的底层是使用iptables进行数据过滤,建立在iptables之上,这可能会与 Docker 产生冲突。 当
firewalld 启动或者重启的时候,将会从 iptables 中移除 docker的规则,从而影响了 Docker 的正常工作。
当你使用的是 systemd 的时候, firewalld 会在 Docker 之前启动,但是如果你在 Docker 启动之后再启动
或者重启 firewalld ,你就需要重启 Docker 进程了。 重启docker服务及可重新生成自定义链docker。
解决方法:
使用systemd关闭firewalld 之后要重启docker 重启docker服务后再启动容器
systemctl restart docker
创建kibana容器
- 首先运行kibana容器
docker run --name kibana -d -p 5601:5601 docker.elastic.co/kibana/kibana:7.10.2
- 然后copy kibana 的配置文件 到宿主机,修改kibana 的零配置文件kibana.yml 修改kibana连接的elasticsearch 连接地址配置
docker cp kibana:/usr/share/kibana /home/test

- 重启 kibana 容器
使用数据卷方式重新挂载 kibana 的配置目录文件,重启kibana 容器
docker run --name kibana -itd -p 5601:5601 -v /home/test/kibana/config:/usr/share/kibana/config docker.elastic.co/kibana/kibana:7.10.2
-
可能遇到的问题
kibana解决Kibana server is not ready yet问题- 第一种
将配置文件kibana.yml中的elasticsearch.url改为正确的链接,默认为: http://elasticsearch:9200,改为http://自己的IP地址:9200
- 第一种
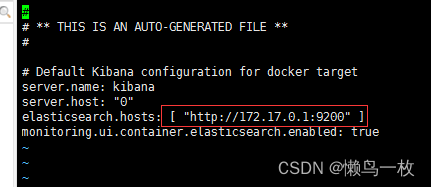
我这里是将原本的elasticsearch改成了docker内部的IP,查看docker内部的IP命令如下
ip address
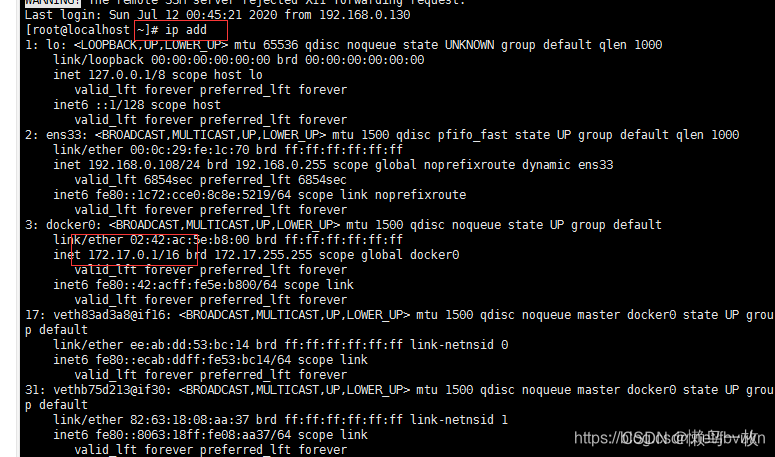
- 第二种
如果上面的配置都没有问题的话,可能是因为防火墙的问题,我们需要把防火墙关掉(我就是这么解决的)
- 查看防火墙状态
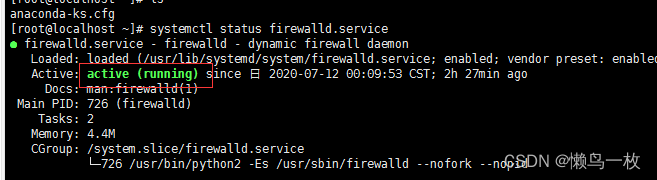
systemctl status firewalld.service
如果结果显示为图中这样,则防火墙是启动了的
接下来需要关闭防火墙,关闭之后再查看防火墙状态
systemctl stop firewalld.service
systemctl status firewalld.service
这样就是显示,就表明防火墙已经关闭

kibana 教程、界面和相关操作
https://www.cnblogs.com/jthr/p/17415787.html
创建cerebro 容器
docker run --name cerebro -itd -p 9000:9000 lmenezes/cerebro
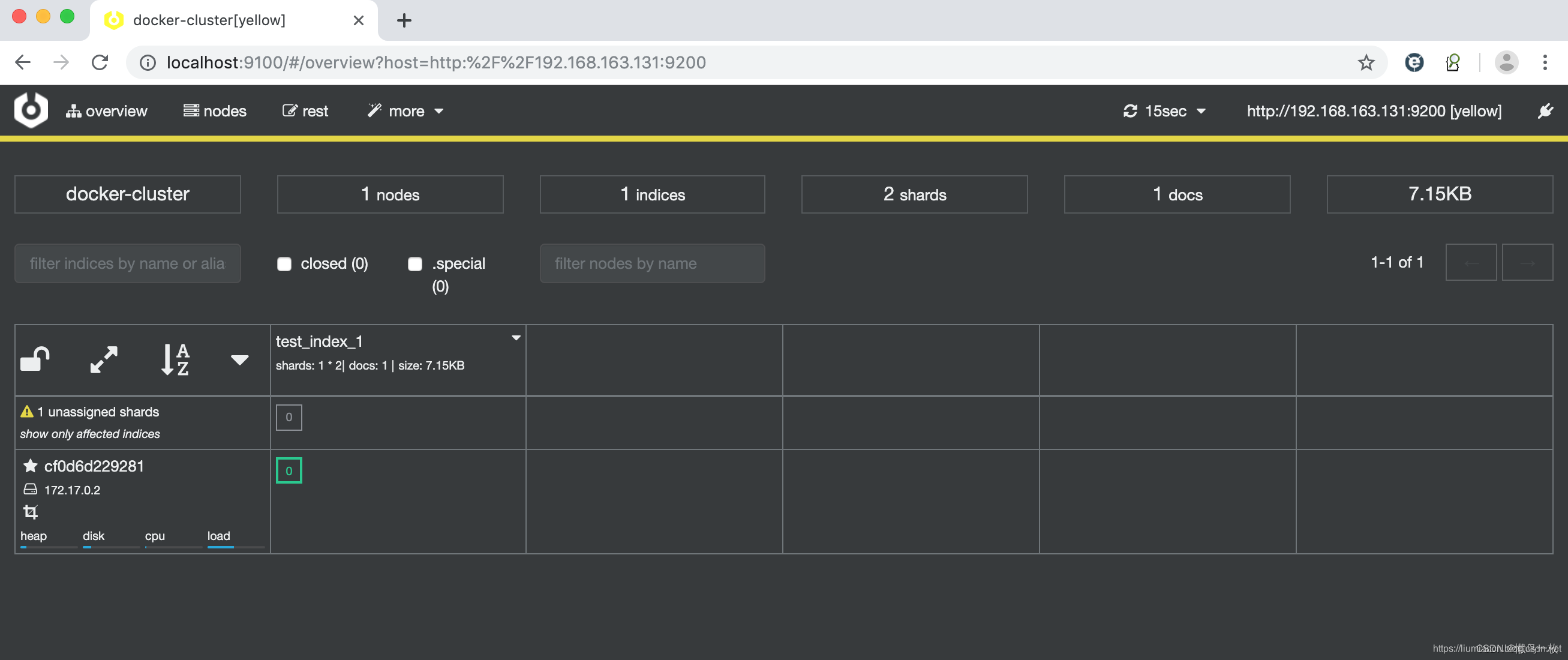
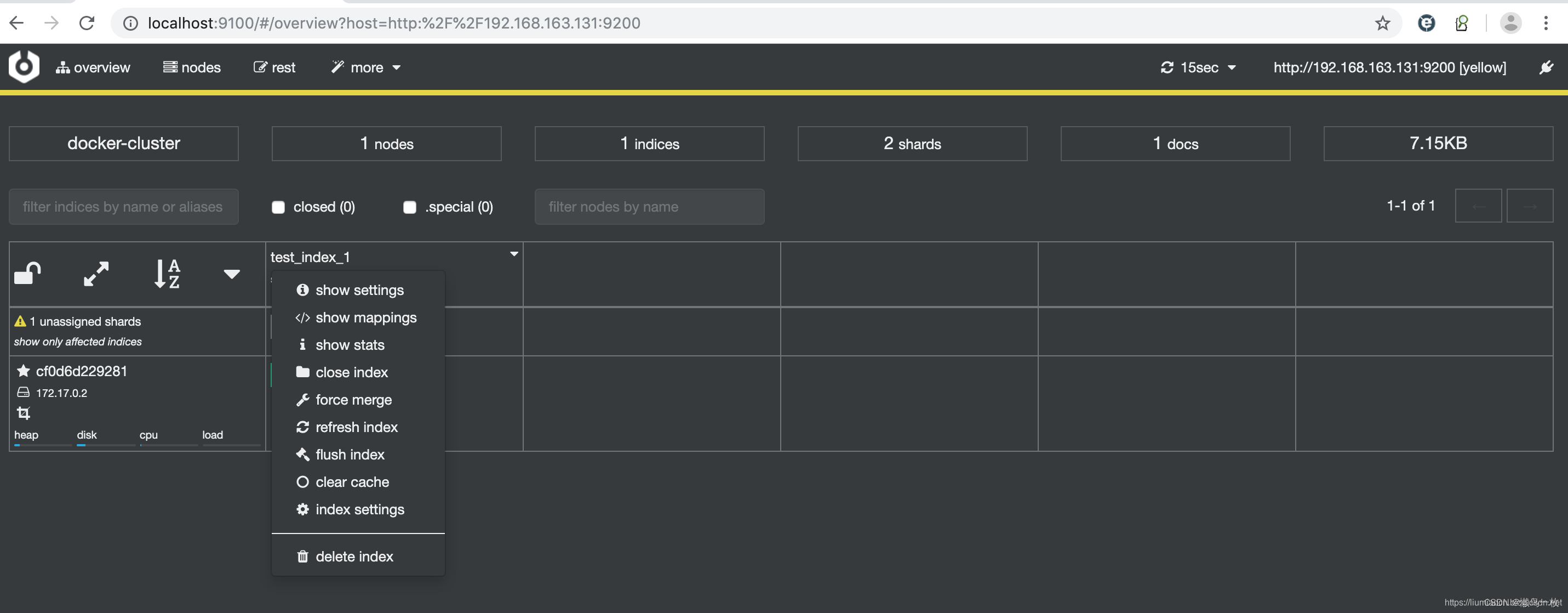
cerebro 的默认端口是9000 ,创建成功后,就可以通过http://localhost:9000/ 进行访问

只需要输入ElasticSearch的URL并点击connect按钮,成功连接即可显示如下图所示信息。需要注意的是由于cerebro运行在容器中,直接输入localhost:9200即使通过浏览器能够访问也可能无法连接,需要保证的是在cerebro的容器中能够访问到的URL,比如这里使用的本机的IP
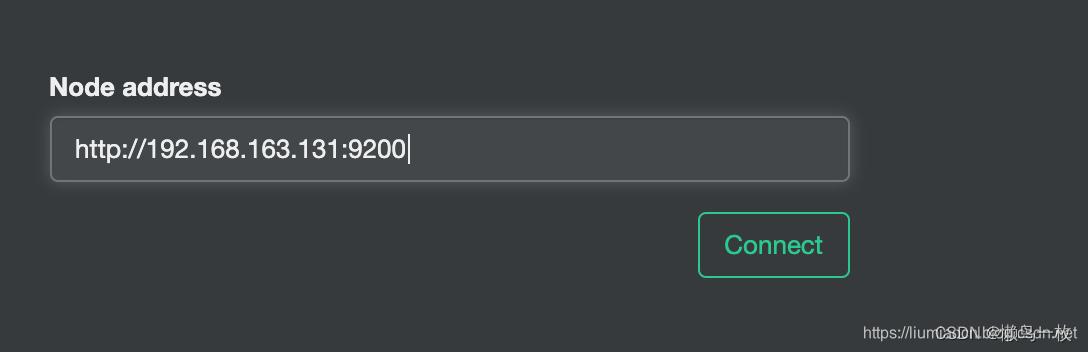
点击Connect按钮即可连接成功
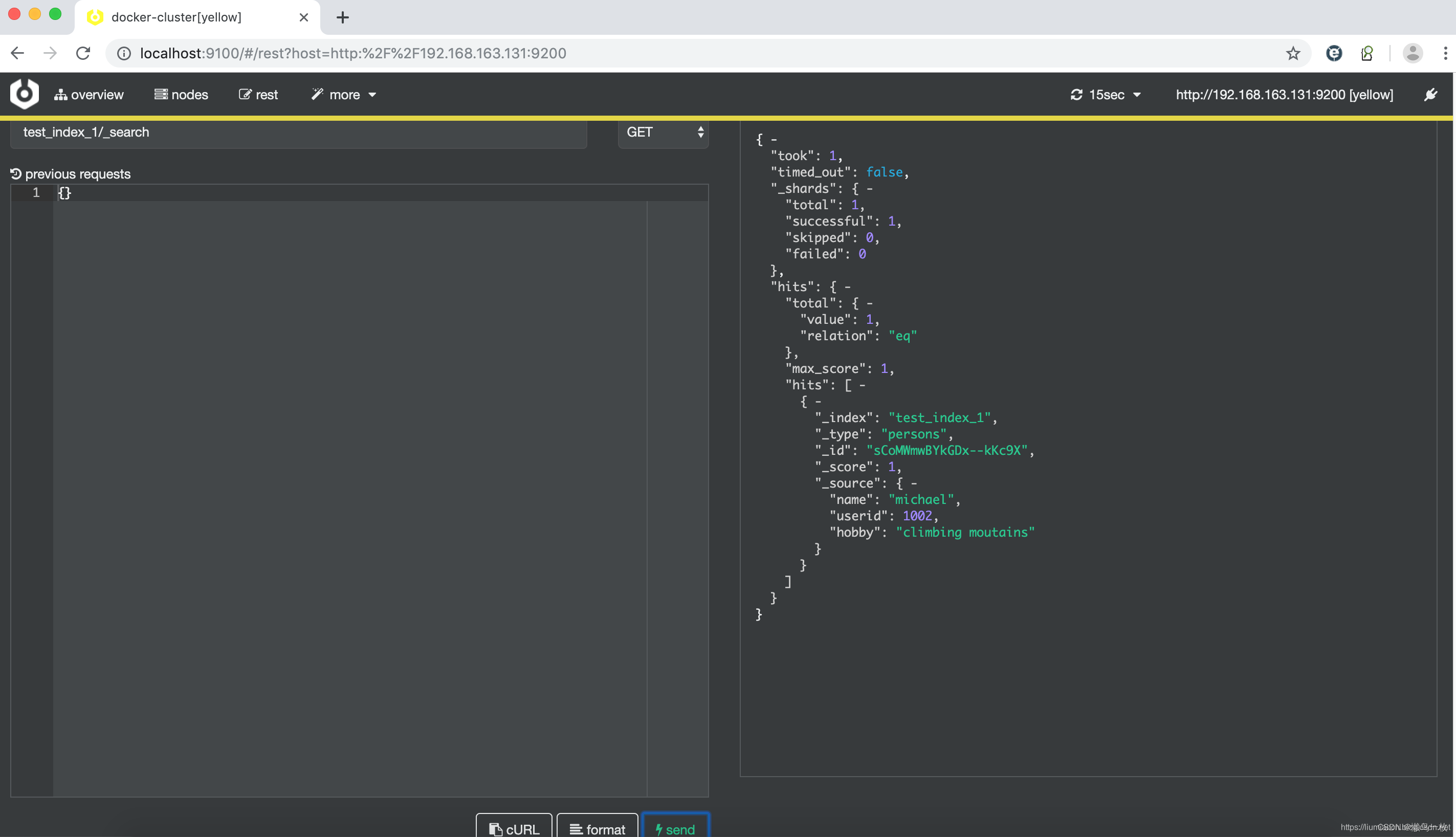
如果需要执行相应的API操作,比如查询,可直接在界面进行操作,比如
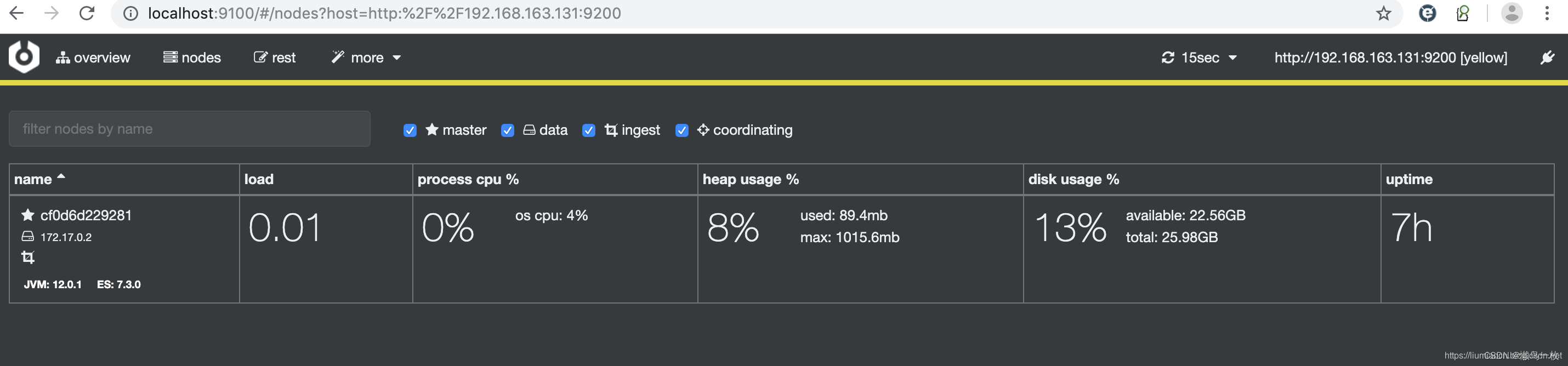
另外还可以确认节点相关的统计信息
很多操作都可以通过页面进行
总结
相较于elasticsearch-head,界面美感较好,功能也在不断更新,建议使用
cerebro 界面、操作教程
https://blog.csdn.net/liumiaocn/article/details/98517815
创建logstash 容器
参考 https://blog.csdn.net/baoshuowl/article/details/114928281
- 启动logstash 容器
docker run -itd --name=logstash logstash:7.5.1
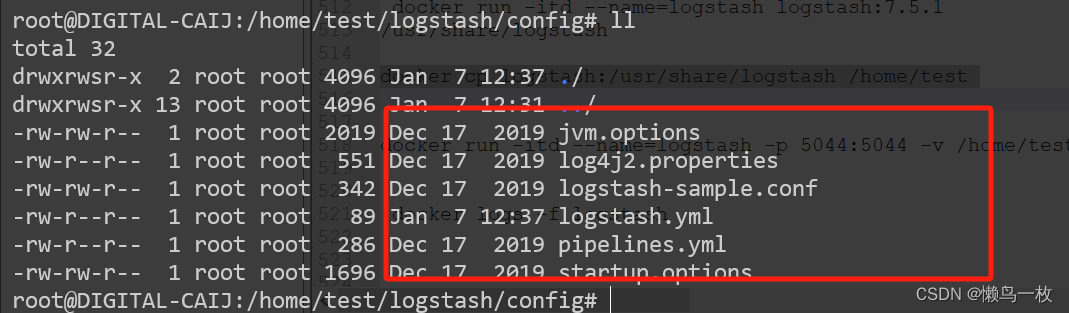
- copy logstash的容器配置文件至 宿主机
docker cp logstash:/usr/share/logstash /home/test
- 修改 logstash 关联的elstaicSearch地址
logstash.yml
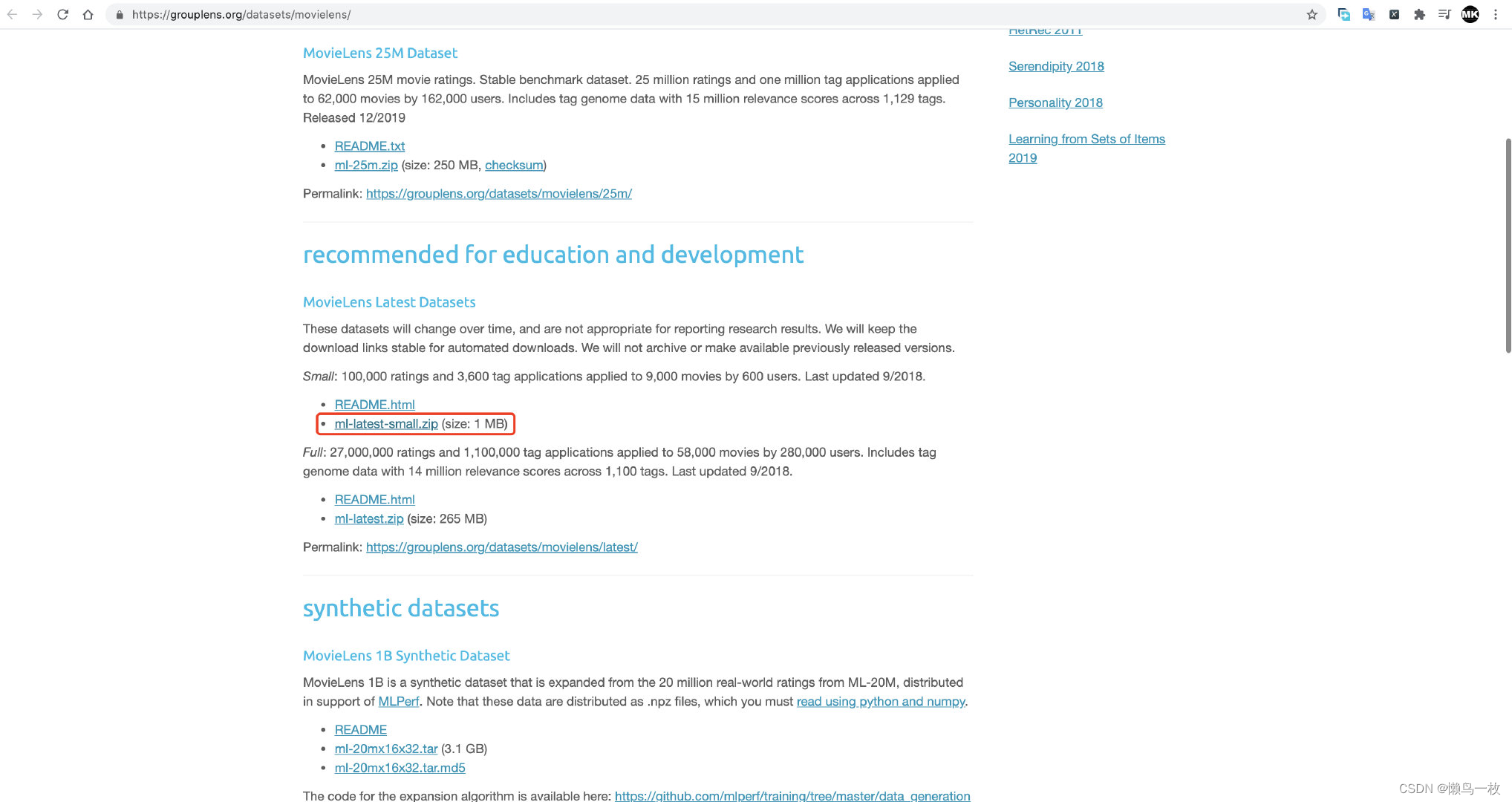
- 下载movielens 测试数据集
下载最MovieLens最小测试数据集:https://grouplens.org/datasets/movielens/
参开博客:https://blog.csdn.net/baoshuowl/article/details/114928281
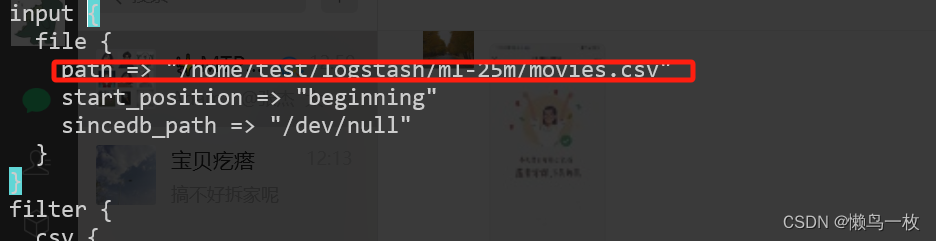
- 准备 logstash.conf配置文件
https://gitee.com/geektime-geekbang/geektime-ELK/tree/master/part-1/2.4-Logstash%E5%AE%89%E8%A3%85%E4%B8%8E%E5%AF%BC%E5%85%A5%E6%95%B0%E6%8D%AE/movielens
logstash.conf
input {
file {
path => "/Users/yiruan/dev/elk7/logstash-7.0.1/bin/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
修改导入的测试数据movies.csv 路径和 logstash 输出 elstaicSearch的地址
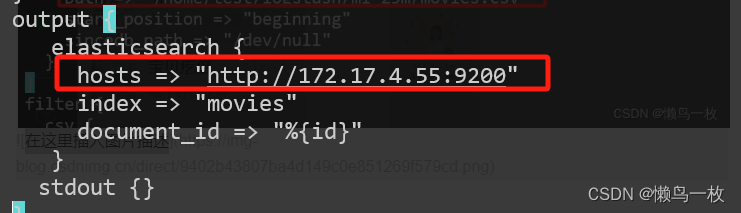
6. 在 logstash/bin 目录下运行一下命令
sudo ./logstash -f logstash.conf
在copy出来的logstash 配置文件下bin 目录下执行,导入测试数据
./logstash -f logstash.conf

以下为输出信息

如果没有出现这个则数据导入有问题
在docker 容器内操作文件没有权限则需要指定 登录容器内部时候的root 用户
docker exec -ited --user=root logstash bash
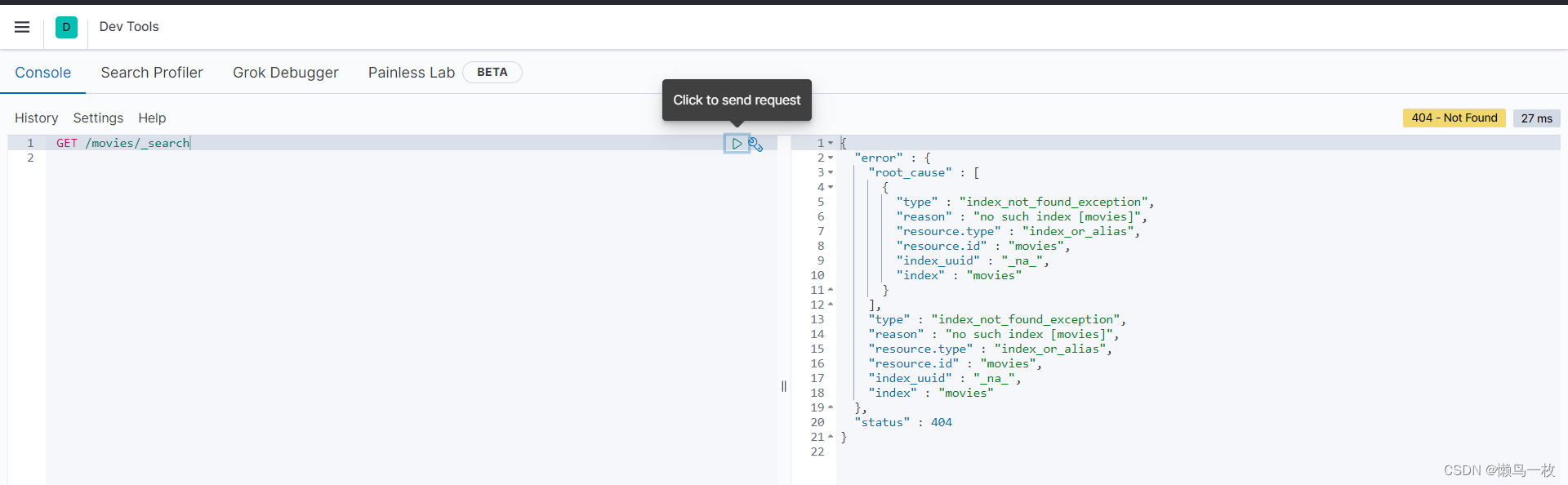
- 在kibana的dev Tool 中查看导入的测试数据
查看已经导入的数据
打开 Kibana 的 Dev Tools 并输入 GET /movies/_search
GET /movies/_search
可以看到下载的测试数据集中的数据已经全部倒入 Elasticsearch 中
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!