MySQL数据库——锁-行级锁(行锁、间隙锁和临键锁)
目录
介绍
行级锁,每次操作锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高。
应用在InnoDB存储引擎中。InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。
对于行级锁,主要分为以下三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。

- ?间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。

- ?临键锁(Next-Key Lock):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。在RR隔离级别下支持。

?
行锁
介绍
InnoDB实现了以下两种类型的行锁:
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排它锁。
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。
两种行锁的兼容情况如下:
| 当前锁类型/请求锁类型 | S(共享锁) | X(排他锁) |
|---|---|---|
| S(共享锁) | 兼容 | 冲突 |
| X(排他锁) | 冲突 | 冲突 |
常见的SQL语句,在执行时,所加的行锁如下:
| SQL | 行锁类型 | 说明 |
|---|---|---|
|
INSERT ...
|
排他锁
|
自动加锁
|
|
UPDATE ...
| 排他锁 | 自动加锁 |
|
DELETE ...
| 排他锁 | 自动加锁 |
|
SELECT
(正常)
|
不加任何锁
| |
|
SELECT ... LOCK IN SHARE MODE
|
共享锁
|
需要手动在
SELECT
之后加
LOCK IN SHARE MODE
|
|
SELECT ... FOR UPDATE
|
排他锁
|
需要手动在
SELECT
之后加
FOR UPDATE
|
演示?
默认情况下,InnoDB在 REPEATABLE READ事务隔离级别运行,InnoDB使用 next-key 锁进行搜
索和索引扫描,以防止幻读。
- 针对唯一索引进行检索时,对已存在的记录进行等值匹配时,将会自动优化为行锁。
- InnoDB的行锁是针对于索引加的锁,不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,此时 就会升级为表锁。
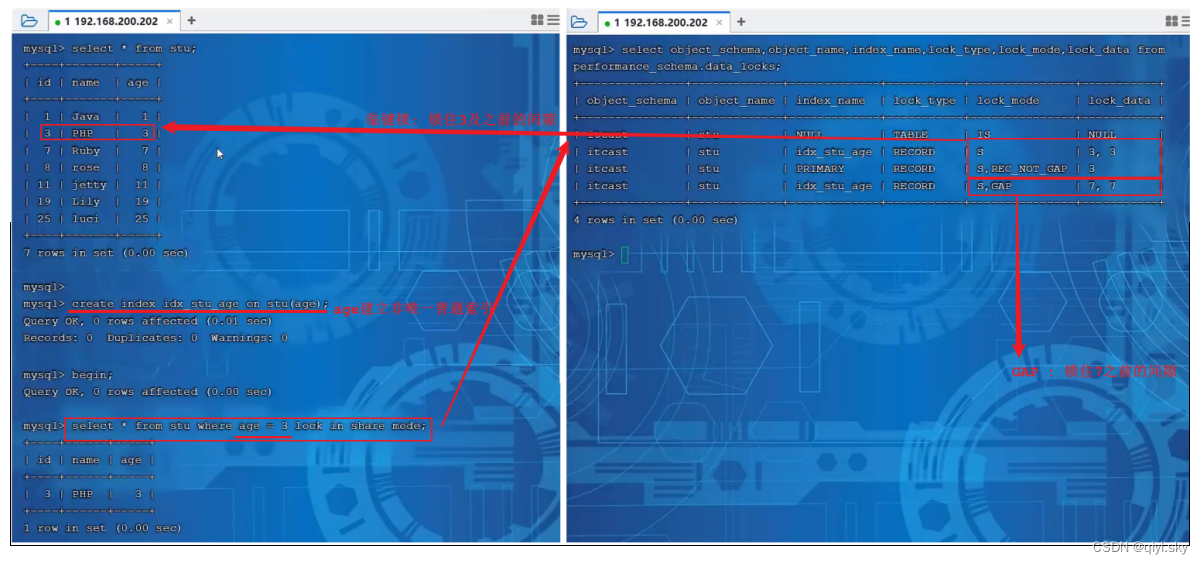
可以通过以下SQL,查看意向锁及行锁的加锁情况:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from
performance_schema.data_locks;示例演示?
数据准备:
CREATE TABLE 'stu' (
'id' int NOT NULL PRIMARY KEY AUTO_INCREMENT,
'name' varchar(255) DEFAULT NULL,
'age' int NOT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4;
INSERT INTO 'stu' VALUES (1, 'tom', 1);
INSERT INTO 'stu' VALUES (3, 'cat', 3);
INSERT INTO 'stu' VALUES (8, 'rose', 8);
INSERT INTO 'stu' VALUES (11, 'jetty', 11);
INSERT INTO 'stu' VALUES (19, 'lily', 19);
INSERT INTO 'stu' VALUES (25, 'luci', 25);演示行锁的时候,就通过上面这张表来演示一下。
A. 普通的select语句,执行时,不会加锁。

B. select...lock in share mode,加共享锁,共享锁与共享锁之间兼容。

共享锁与排他锁之间互斥。

客户端一获取的是id为1这行的共享锁,客户端二是可以获取id为3这行的排它锁的,因为不是同一行数据。
而如果客户端二想获取id为1这行的排他锁,会处于阻塞状态,因为共享锁与排他锁之间互斥。
C. 排它锁与排他锁之间互斥
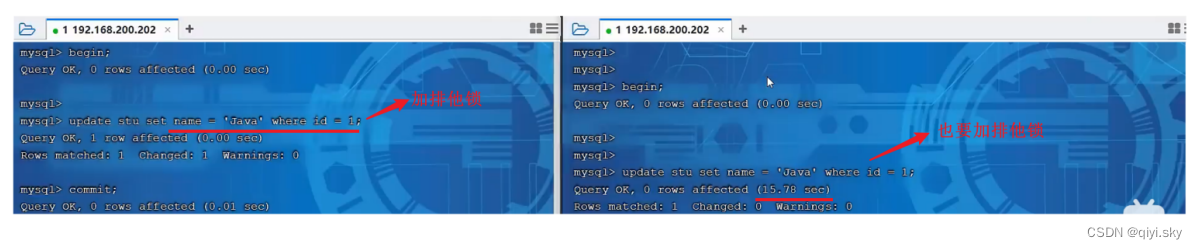
当客户端一执行update语句,会为id为1的记录加排他锁;
客户端二如果也执行update语句,更新id为1的数据,也要为id为1的数据加排他锁,但是客户端二会处于阻塞状态,因为排他锁之间是互斥的。
直到客户端一把事务提交了,才会把这一行的行锁释放,此时客户端二解除阻塞。?
D. 无索引行锁升级为表锁
stu表中数据如下:

我们在两个客户端中执行如下操作:

在客户端一中开启事务,并执行update语句,更新name为Lily的数据,也就是id为19的记录。
然后在客户端二中更新id为3的记录,却不能直接执行,会处于阻塞状态,为什么呢?
原因就是此时客户端一根据name字段进行更新时,name字段是没有索引的,如果没有索引,此时行锁会升级为表锁(因为行锁是对索引项加的锁,而name没有索引)。?
接下来,我们再针对name字段建立索引,索引建立之后,再次做一个测试:

此时我们可以看到,客户端一开启事务,然后依然是根据name进行更新。
而客户端二在更新id为3的数据时,更新成功,并未进入阻塞状态。
这样就说明,我们根据索引字段进行更新操作,就可以避免行锁升级为表锁的情况。
间隙锁&临键锁
介绍
默认情况下,InnoDB在 REPEATABLE READ事务隔离级别运行,InnoDB使用 next-key 锁进行搜
索和索引扫描,以防止幻读。
- 索引上的等值查询(当其索引为唯一索引时),给不存在的记录加锁时, 优化为间隙锁 。
- 索引上的等值查询(当其索引为非唯一普通索引时),向右遍历时,最后一个值不满足查询需求时,next-keylock 退化为间隙锁。
- 索引上的范围查询(唯一索引)--会访问到不满足条件的第一个值为止。
注意:间隙锁唯一目的是防止其他事务插入间隙。间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务在同一间隙上采用间隙锁。
?
示例演示
A. 索引上的等值查询(当其索引为唯一索引时),给不存在的记录加锁时, 优化为间隙锁。

B. 索引上的等值查询(当其索引为非唯一普通索引时),向右遍历时最后一个值不满足查询需求时,next-key lock 退化为间隙锁。?
介绍分析一下:
我们知道InnoDB的B+树索引,叶子节点是有序的双向链表。假如我们要根据这个二级索引查询值为18的数据,并加上共享锁,我们是只锁定18这一行就可以了吗?
并不是,因为是非唯一索引,这个结构中可能有多个18的存在,所以,在加锁时会继续往后找,找到一个不满足条件的值(当前案例中也就是29)。此时会对18加临键锁,并对29之前的间隙加锁。

C. 索引上的范围查询(唯一索引)--会访问到不满足条件的第一个值为止。?

查询的条件为id>=19,并添加共享锁。 此时我们可以根据数据库表中现有的数据,将数据分为三个部分:
- [19]
- (19,25]
- (25,+∞]?
所以数据库数据在加锁时,就是将19加了行锁,25的临键锁(包含25及25之前的间隙),正无穷的临键锁(正无穷及之前的间隙)。
END?
学习自:黑马程序员——MySQL数据库课程?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!