with torch.no_grad()在Pytorch中的应用
with torch.no_grad()在Pytorch中的应用
参考:
https://blog.csdn.net/qq_24761287/article/details/129773333
https://blog.csdn.net/sazass/article/details/116668755
在学习Pytorch时,老遇到 with torch.no_grad(),搞不清其作用,现在详细了解一下。
1、with torch.no_grad()含义
torch.no_grad() 上下文管理器通常用于那些不需要计算梯度的操作,例如在模型评估或推断时。在这些情况下,关闭自动求导功能可以提高代码执行效率,因为不需要计算梯度的操作通常比需要计算梯度的操作更快。
with torch.no_grad():
# some code that doesn't require gradients
2、with torch.no_grad()运用场景
简单来说,如果不需要在接下来步骤中用到所计算的式子的梯度,就可以使用with torch.no_grad()来提升运算速度。
2.1 只评估模型
在模型的评估模式下,对验证数据集进行前向传播并计算性能指标,而不计算或存储梯度信息。这有助于节省内存和提高代码执行效率。在此处能使用with torch.no_grad()的根本原因是我们不依赖于模型得到的结果去执行梯度下降操作,例如:
model.eval()
with torch.no_grad():
for inputs, targets in validation_loader:
outputs = model(inputs)
# 计算指标,如准确率、损失等
2.2 此模型的计算结果不参与此模型的梯度下降
在SAC算法的更新过程中,需要用到策略policy网络的结果去更新Q网络的参数,在计算策略policy网络的结果时,该计算结果并不会用于更新policy网络,因此我们需要使用with torch.no_grad():对next_log_prob = self.policy_net.evaluate(next_state)进行修饰。
predicted_q_value1 = self.soft_q_net1(state)
predicted_q_value1 = predicted_q_value1.gather(1, action.unsqueeze(-1))
predicted_q_value2 = self.soft_q_net2(state)
predicted_q_value2 = predicted_q_value2.gather(1, action.unsqueeze(-1))
log_prob = self.policy_net.evaluate(state)
# with torch.no_grad()表示不带梯度,因为只是用policy_net得到next_log_prob,对更新Q网络不起作用
with torch.no_grad():
next_log_prob = self.policy_net.evaluate(next_state)
# reward = reward_scale * (reward - reward.mean(dim=0)) / (reward.std(dim=0) + 1e-6) # normalize with batch mean and std; plus a small number to prevent numerical problem
# Training Q Function
self.alpha = self.log_alpha.exp()
target_q_min = (next_log_prob.exp() * (torch.min(self.target_soft_q_net1(next_state), self.target_soft_q_net2(
next_state)) - self.alpha * next_log_prob)).sum(dim=-1).unsqueeze(-1)
target_q_value = reward + (1 - done) * gamma * target_q_min # if done==1, only reward
q_value_loss1 = self.soft_q_criterion1(predicted_q_value1,
target_q_value.detach()) # detach: no gradients for the variable
q_value_loss2 = self.soft_q_criterion2(predicted_q_value2, target_q_value.detach())
self.soft_q_optimizer1.zero_grad()
q_value_loss1.backward()
self.soft_q_optimizer1.step()
self.soft_q_optimizer2.zero_grad()
q_value_loss2.backward()
self.soft_q_optimizer2.step()
2.3 模型更新参数
当你在优化算法中更新模型参数时,不需要在参数更新步骤中计算梯度。在更新参数时使用 torch.no_grad() 可以防止出现错误,并确保计算过程正确。
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
3、with torch.no_grad()本质作用
在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。
即使一个tensor(命名为x)的requires_grad = True,在with torch.no_grad计算,由x得到的新tensor(命名为w-标量)requires_grad也为False,且grad_fn也为None,即不会对w求导。例子如下所示:
x = torch.randn(10, 5, requires_grad = True)
y = torch.randn(10, 5, requires_grad = True)
z = torch.randn(10, 5, requires_grad = True)
with torch.no_grad():
w = x + y + z
print(w.requires_grad)
print(w.grad_fn)
print(w.requires_grad)
输出:
False
None
False
4、为什么要使用with torch.no_grad()
如果在这些情况下没有使用torch.no_grad() 会导致哪些错误?
- 额外的内存消耗:计算和存储梯度需要额外的内存。在不需要梯度的情况下仍然计算梯度会导致不必要的内存消耗。在内存有限的设备上,如GPU,这可能导致内存不足而无法执行计算。
- 降低计算速度:计算梯度会增加计算负担。如果在不需要梯度的情况下仍然计算梯度,会降低计算速度,从而增加模型评估和推理的时间。
- 可能的计算错误:在某些情况下,如在优化算法中更新参数时,如果不使用torch.no_grad(),可能导致错误。例如,如果你在需要梯度的张量上执行原地操作,PyTorch会抛出RuntimeError,因为这样的操作会破坏计算图和梯度计算。
虽然在某些情况下忘记使用 torch.no_grad() 可能不会立即导致错误,但为了确保计算效率和正确性,建议在不需要梯度计算的情况下使用 torch.no_grad()。
下面给出使用with torch.no_grad()修饰不需要求导语句和不使用的对比,可以看到在同样的实际内,使用修饰会带来更好的速度。
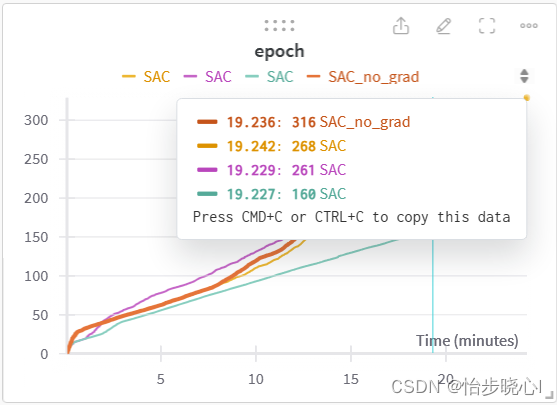
效果也是使用了with torch.no_grad()更好,但是这些都是参考,毕竟每次训练的收敛速度都不太一致:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!