RTDETR论文快速理解和代码快速实现(训练与预测)
文章目录
前言
最近,我们想比较基于DETR的transformer模型与基于CNN的yolo模型效果,而百度RT-DETR模型声称“在实时目标检测领域打败YOLO”。从数据的角度来看,RT-DETR似乎确实在某些方面超越了YOLO。我选择RT-DETR模型与YOLO模型比较。本篇文章将介绍RT-DETR模型原理–>环境安装–>数据准备–>训练实现–>预测实现。
一、摘要
近期,端到端基于transformer检测器DETRs已有显著性能。然而,DETR的计算成本限制其实际应用,也阻止其无后处理的优势(如:NMS)。在这篇论文,我们首次分析NMS对目标检测的速度与精确率影响,并构建了端到端的speed基准。为了解决这些问题,我们提出RT-DETR模型,据我们所知,这是第一个实时端到端检测模型。特别的,我们设计一个高效混合编码器加工多尺度特征与特征交互和融合,并提出IOU感知查询,通过像解码器提供更高初始目标来提示性能。除此之外,我们提出的检测模型,可使用解码层without retraining灵活调整推理速度,这样可适应多样的实时场景。我们模型RT-DETR-L在coco2017实现了53%的AP和114FPS on T4 gpu,而RT-DETR-X实现54.8%AP和74FPS,超过同规模模型的yolo。此外,我们的 RT-DETR-R50 实现了53.1%的AP和108FPS的速度,准确性优于 DINO-Deformable-DETR-R50 约 2.2% AP,帧率约为其21倍。
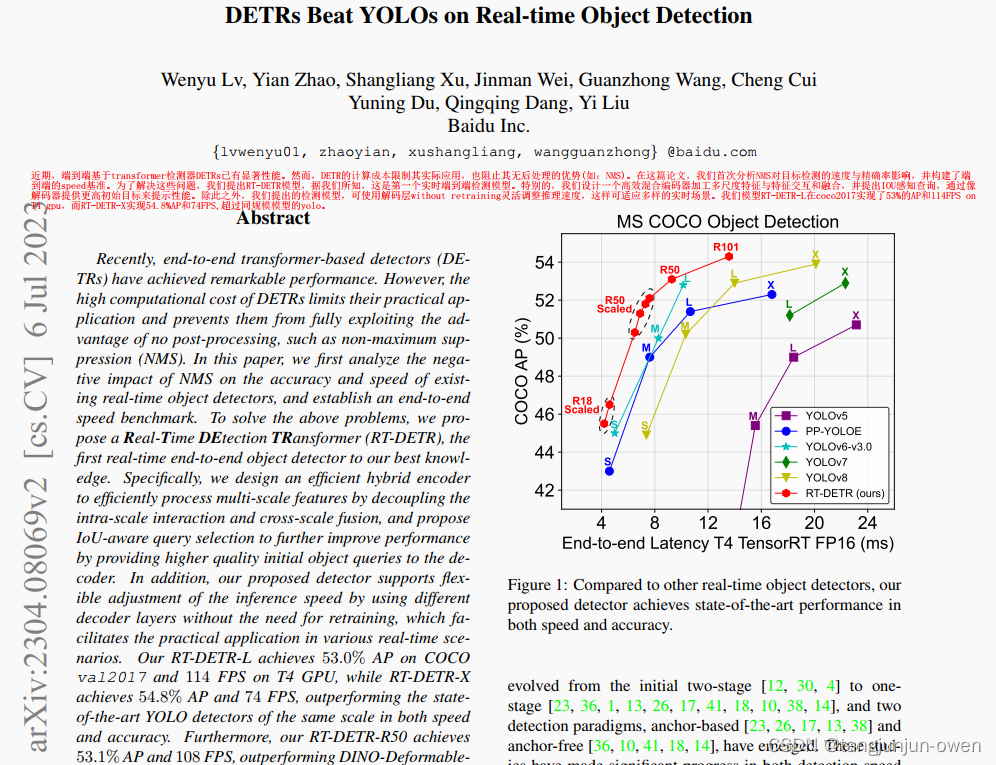
二、论文目的
实时目标检测是一个重要的研究领域,而DETR的高计算成本问题尚未得到有效解决,这限制了DETR的实际应用,并导致无法充分利用其优势(后处理)。换句话说,RTDETR解决问题是
为了实现上述目标,我们重新思考了DETR,并对其关键组件进行了详细分析和实验,以减少不必要的计算冗余。具体而言,我们发现虽然引入多尺度特征有助于加快训练收敛和提高性能[43],但它也导致输入编码器的序列长度显著增加。因此,由于高计算成本,Transformer编码器成为模型的计算瓶颈。为了实现实时目标检测,我们设计了一个高效的混合编码器来替代原始的Transformer编码器。通过解耦多尺度特征的内尺度交互和跨尺度融合,编码器能够高效处理具有不同尺度的特征。此外,先前的研究[35, 20]表明,解码器的对象查询初始化方案对于检测性能至关重要。为了进一步提高性能,我们提出了基于IoU的查询选择方法,通过在训练过程中提供IoU约束,为解码器提供更高质量的初始对象查询。此外,我们提出的检测器支持通过使用不同的解码器层对推理速度进行灵活调节,无需重新训练,这得益于DETR架构中解码器的设计,并有助于实时检测器的实际应用。
三、论文贡献
本论文的主要贡献总结如下:
1、我们提出了第一个实时端到端目标检测器,不仅在准确性和速度方面优于当前最先进的实时检测器,而且不需要后处理,因此推理速度不会延迟并保持稳定;
2、我们详细分析了NMS对实时检测器的影响,并从后处理的角度得出了关于基于CNN的实时检测器的结论;
3、我们提出的IoU-aware查询选择在模型中展现出卓越的性能改进,为改进目标查询的初始化方案提供了新的思路;
4、我们的工作为端到端检测器的实时实现提供了可行的解决方案,所提出的检测器可以通过使用不同的解码器层进行灵活调整模型大小和推理速度,无需重新训练。
四、模型结构
1、模型整体结构
RT-DETR模型由主干网络(backbone)、混合编码器(hybrid encoder)和带有辅助预测头的Transformer解码器组成。模型的整体架构概述如下图所示。具体来说,我们利用主干网络最后三个阶段的输出特征{S3,S4,S5}作为编码器的输入。混合编码器通过内部尺度交互和跨尺度融合,将多尺度特征转换为图像特征序列。随后,采用IoU感知的查询选择机制,从编码器的输出序列中选择固定数量的图像特征作为解码器的初始对象查询。最后,带有辅助预测头的解码器迭代优化对象查询,生成边界框和置信度分数。
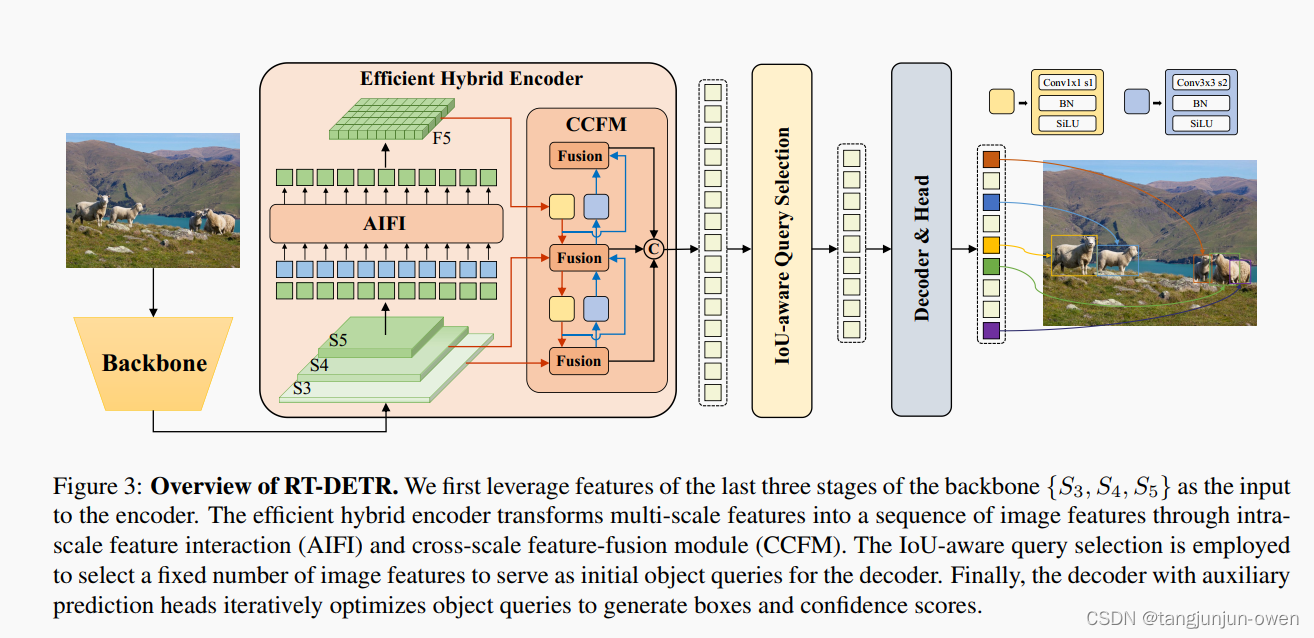
RT-DETR模型架构图显示了主干网络的最后三个阶段{S3,S4,S5}作为编码器的输入。高效的混合编码器通过内部尺度特征交互(AIFI)和跨尺度特征融合模块(CCFM)将多尺度特征转化为图像特征序列。采用IoU感知的查询选择方法,选择固定数量的图像特征作为解码器的初始对象查询。最后,解码器通过辅助预测头迭代优化对象查询,生成边界框和置信度分数
本文最重要是设计AIFI与CCFM结构
2、backbone结构
与YOLO相似,RT-DETR最终会输出三种不同尺寸的特征图,它们相对于输入图像的分辨率下采样倍数分别是 8 倍、16 倍和 32 倍。这与主流的YOLO算法相似。除此之外,在主干结构的其他方面,RT-DETR并没有特别的地方。
3、neck结构
对于颈部网络部分,RT-DETR 采用了一层 Transformer 的 Encoder ,文中这个颈部网络叫做 Efficient Hybrid Encoder,其包括两部分:Attention-based Intra-scale Feature Interaction (AIFI) 和 CNN-based Cross-scale Feature-fusion Module (CCFM),这个AIFI模块有一点值得注意,这个模块只对S5特征图进行处理,
对于AIFI模块(如下左图),它首先将二维的 S5 特征拉成向量,然后交给AIFI模块处理,其数学过程就是多头自注意力与 FFN,随后,再将输出Reshape回二维,记作 F5,以便去完成后续的所谓的“跨尺度特征融合”。
对于CCFM模块(如下右图),以YOLO的角度看这个结构的话,这个CCFM模块就是一个FPN/PAN结构。关于CCFM模块中的Fusion文中也给了详细的结构图,是由 2 个1×1 卷积和 N 个 RepBlock 构成的,这里之所以写成 N ,我觉得是因为 RT-DETR 可以进行缩放处理,通过调整 CCFM中RepBlock 的数量和 Encoder 的编码维度分别控制 Hybrid Encoder 的深度和宽度,同时对 backbone 进行相应的调整即可实现检测器的缩放。
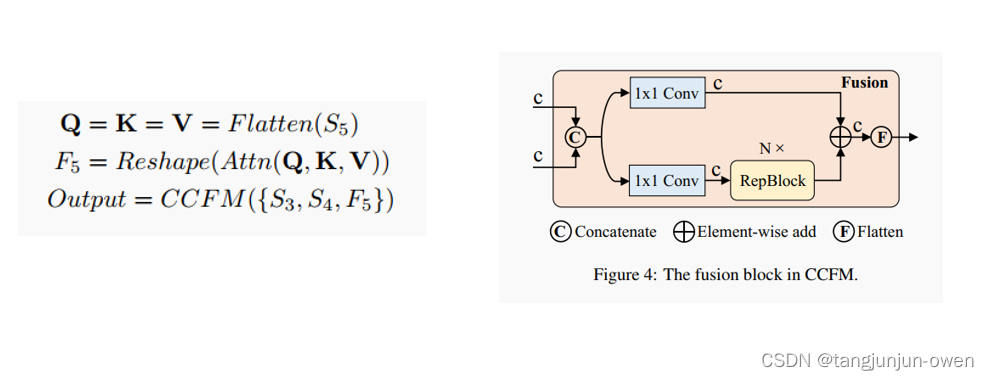
4、混合编码器(neck)
在3已经介绍neck最终结构,而设计neck结构时,作者为了实时性与减少冗余,设计了一些列结构,其原因是注意力机制的改进减少了计算开销,却输入序列的大幅增加仍导致编码器成为计算瓶颈,不太好实时场景中使用。作者分析了多尺度变换器编码器中存在的计算冗余,设计了一系列变种来证明同时进行内部尺度和跨尺度特征交互在计算上效率低下。
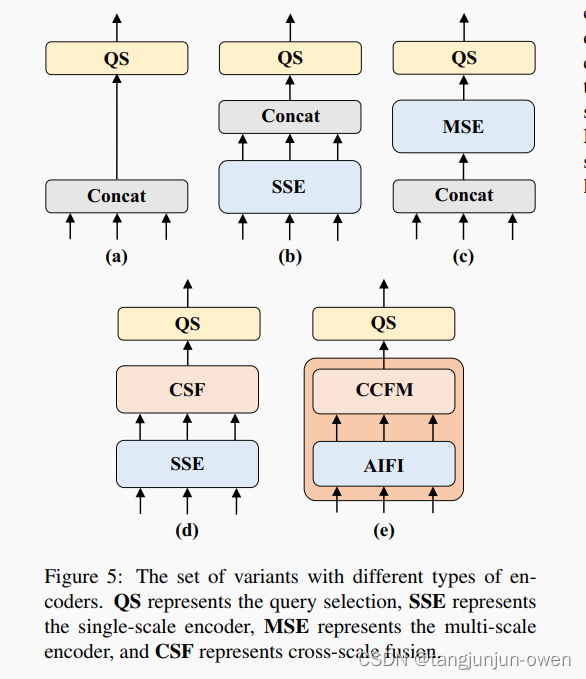
A → B:变体B插入了一个单尺度的Transformer编码器,它使用了一个Transformer块的层。每个尺度的特征共享编码器,进行内部尺度的特征交互,然后将输出的多尺度特征进行连接。
B → C:变体C在B的基础上引入了基于尺度的特征融合,将连接的多尺度特征输入编码器进行特征交互。
C → D:变体D将多尺度特征的内部尺度交互和跨尺度融合解耦。首先,使用单尺度的Transformer编码器进行内部尺度交互,然后利用类似于PANet [21]的结构进行跨尺度融合。
D → E:变体E在D的基础上进一步优化多尺度特征的内部尺度交互和跨尺度融合,采用了我们设计的高效混合编码器。
RT-DETR认为S5特征相对于较浅的S3和S4特征来说,具有更深、更高级和更丰富的语义特征。这些语义特征对于Transformer模型更加重要,因为它们对于区分不同物体的特征非常有用,而浅层特征由于缺乏良好的语义特征并不是很丰富。
五、RTDERT模型训练(data–>train)
我将在此部分介绍环境安装、数据准备格式、训练相关配置与代码、预测相关内容与代码,我也将数据、官网提供权重放在这里,有需要自行下载。
1、环境安装
使用命令安装,如下:
conda create -n yolov8 python=3.8
conda activate yolov8
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirement.txt
pip install ultralytics
使用上面命令安装可能会报错Could not load library libcudnn_cnn_train.so.8 ,解决方法点击这里,建议先安装较低点的torch版本。
2、训练
我们使用yolov8集成的RTDETR模型,训练与预测文件大致如下图。
1、数据准备
实际为yolo数据格式,可按照yolov5或v8格式准备即可。
2、数据yaml文件
其数据yaml文件与yolo差不多,但少了nc且将names变成字典的映射,coco8.yaml内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco8.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco8 ← downloads here (1 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: C:/Users/Administrator/Desktop/rtdetr/coco128 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/train # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco8.zip
3、训练代码
我们使用命令训练,如下代码:
yolo train model=rtdetr-l.pt data=coco8.yaml epochs=100 imgsz=640 batch=2 amp=False
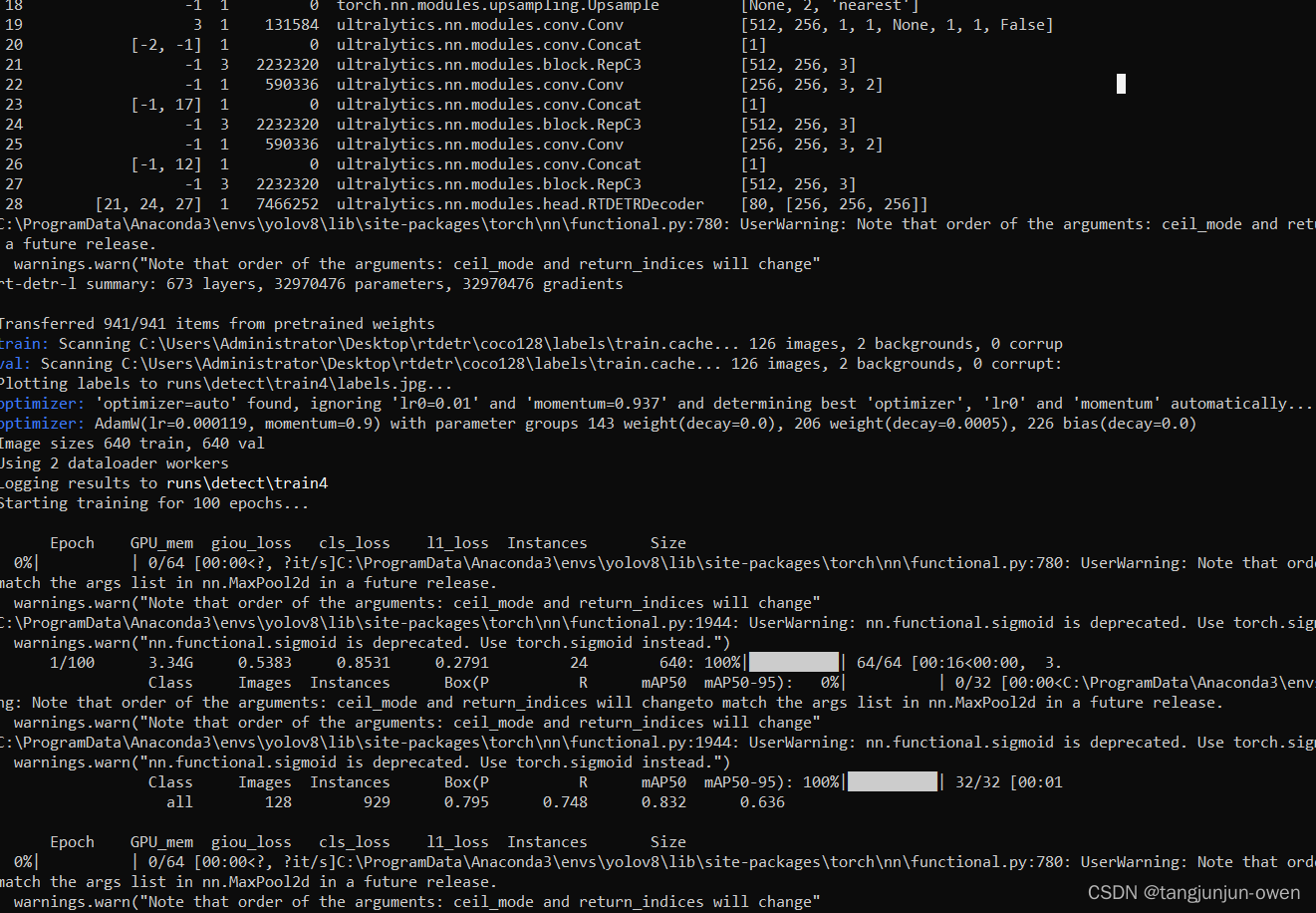
4、训练运行结果
配置好以上内容即可训练,执行过程如下显示
3、推理
1、推理代码
这里不在过多介绍推理代码,朋友们可自行查阅。
import cv2
import torch
import numpy as np
from ultralytics.nn.autobackend import AutoBackend
def preprocess(image):
image = cv2.resize(image, (640, 640))
image = (image[..., ::-1] / 255.0).astype(np.float32) # BGR to RGB, 0 - 255 to 0.0 - 1.0
image = image.transpose(2, 0, 1)[None] # BHWC to BCHW (n, 3, h, w)
image = torch.from_numpy(image)
return image
def postprocess(pred, oh, ow, conf_thres=0.25):
# 输入是模型推理的结果,即300个预测框
# 1,300,84 [cx,cy,w,h,class*80]
boxes = []
for item in pred[0]:
cx, cy, w, h = item[:4]
label = item[4:].argmax()
confidence = item[4 + label]
if confidence < conf_thres:
continue
left = cx - w * 0.5
top = cy - h * 0.5
right = cx + w * 0.5
bottom = cy + h * 0.5
boxes.append([left, top, right, bottom, confidence, label])
boxes = np.array(boxes)
lr = boxes[:,[0, 2]]
tb = boxes[:,[1, 3]]
boxes[:,[0,2]] = ow * lr
boxes[:,[1,3]] = oh * tb
return boxes
def hsv2bgr(h, s, v):
h_i = int(h * 6)
f = h * 6 - h_i
p = v * (1 - s)
q = v * (1 - f * s)
t = v * (1 - (1 - f) * s)
r, g, b = 0, 0, 0
if h_i == 0:
r, g, b = v, t, p
elif h_i == 1:
r, g, b = q, v, p
elif h_i == 2:
r, g, b = p, v, t
elif h_i == 3:
r, g, b = p, q, v
elif h_i == 4:
r, g, b = t, p, v
elif h_i == 5:
r, g, b = v, p, q
return int(b * 255), int(g * 255), int(r * 255)
def random_color(id):
h_plane = (((id << 2) ^ 0x937151) % 100) / 100.0
s_plane = (((id << 3) ^ 0x315793) % 100) / 100.0
return hsv2bgr(h_plane, s_plane, 1)
if __name__ == "__main__":
img = cv2.imread("1.jpg")
oh, ow = img.shape[:2]
img_pre = preprocess(img)
# postprocess
# ultralytics/models/rtdetr/predict.py
model = AutoBackend(weights="rtdetr-l.pt")
names = model.names
result = model(img_pre)[0] # 1,300,84
boxes = postprocess(result, oh, ow)
for obj in boxes:
left, top, right, bottom = int(obj[0]), int(obj[1]), int(obj[2]), int(obj[3])
confidence = obj[4]
label = int(obj[5])
color = random_color(label)
cv2.rectangle(img, (left, top), (right, bottom), color=color ,thickness=2, lineType=cv2.LINE_AA)
caption = f"{names[label]} {confidence:.2f}"
w, h = cv2.getTextSize(caption, 0, 1, 2)[0]
cv2.rectangle(img, (left - 3, top - 33), (left + w + 10, top), color, -1)
cv2.putText(img, caption, (left, top - 5), 0, 1, (0, 0, 0), 2, 16)
cv2.imwrite("infer.jpg", img)
print("save done")
注:若下载了文件可直接 python detect.py执行,可得结果
2、推理运行结果

总结
文章主要是更换backbone(个人觉得不是文章重点),而使用S5在结合作者多个neck模块实验,该neck结构主打消除计算实现实时。
代码可使用百度官网代码,也可使用yolov8自带代码(高效实现)。
后期,我将仿yolov5一键训练与预测,直接使用xml文件格式训练有预测RTDETR文章。
参考博客链接:
https://blog.csdn.net/qq_40672115/article/details/134356250
https://blog.csdn.net/weixin_43694096/article/details/131353118
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!