matplotlib 虚战1
2024-01-09 21:40:59
?EDA?入门
visualization.py
import matplotlib
matplotlib.use("TkAgg")
import pandas as pd
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv("diabetes.csv")
# look at the first 5 rows of the dataset
print(df.head())
df.hist()
plt.tight_layout()
plt.show()
?数据集下载地址:(需要登陆,没有账号可以注册一个)?
Pima Indians Diabetes Database (kaggle.com)
pd.read_csv()读取数据集,得到的是dataframe类型的数据。
df.head()? ? ? ? ? ? ?读取最开始的5行数据
df.hist()? ? ? ? ? ? ? ?设置为直方图
plt.tight_layout()? 可以解决不同轴域的标签叠在一起的问题。
plt.show()
输出:
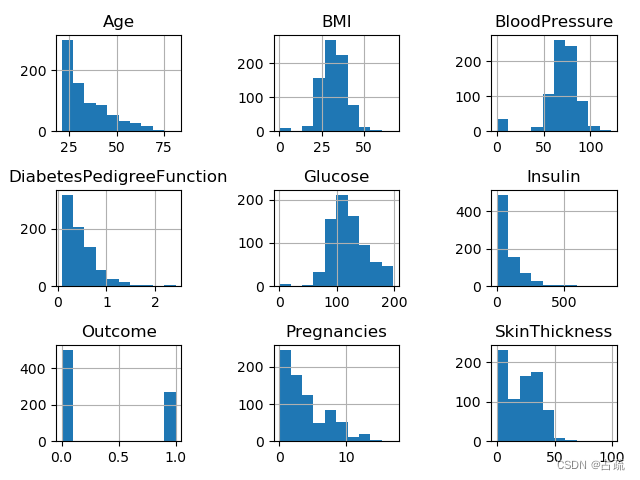
Pregnancies Glucose ... Age Outcome
0 6 148 ... 50 1
1 1 85 ... 31 0
2 8 183 ... 32 1
3 1 89 ... 21 0
4 0 137 ... 33 1
[5 rows x 9 columns]import matplotlib
matplotlib.use("TkAgg")
import pandas as pd
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv("diabetes.csv")
# show density plot
# create a subplot of 3 x 3
plt.subplots(3,3,figsize=(20,20))
# Plot a density plot for each variable
for idx, col in enumerate(df.columns):
ax = plt.subplot(3,3,idx+1) #选中第idx+1个区域返回
ax.yaxis.set_ticklabels([]) #获取当前活跃的的axes然后在上面作图,,隐藏刻度值,但是保留坐标轴标签
sns.distplot(df.loc[df.Outcome == 0][col], hist=False, axlabel= False, kde_kws={'linestyle':'-', 'color':'black', 'label':"No Diabetes",'bw': 1.0})
sns.distplot(df.loc[df.Outcome == 1][col], hist=False, axlabel= False, kde_kws={'linestyle':'--', 'color':'black', 'label':"Diabetes",'bw': 1.0})
ax.set_title(col)
# Hide the 9th subplot (bottom right) since there are only 8 plots
plt.subplot(3,3,9).set_visible(False)
plt.tight_layout()
plt.show()?figsize表示设置图像大小
bw是带宽。你应该调整bw。较大的带宽导致较大的面元大小(例如,平滑的密度函数),而较小的带宽导致较小的面元(更高的分辨率)。
seaborn.distplot(data, bins=None, hist=True, kde=True, rug=False, fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None, vertical=False, norm_hist=False, axlabel=None, label=None, ax=None)
参数说明:
- data: 需要绘制分布图的一维数组或序列,默认为 None。
- bins: 直方图的箱数,一个整数或列表,默认为 None。
- hist: 是否显示直方图,默认为 True
- kde: 是否显示核密度估计图,默认为 True。
- rug: 是否显示rugplot,默认为 False。
- fit: 是否拟合数据分布,默认为 None。
- hist_kws: 直方图的其他参数,如颜色、透明度等,字典类型,默认为 None。
- kde_kws: 密度曲线的其他参数,如颜色、透明度等,字典类型,默认为 None。
- rug_kws: rugplot的其他参数,如颜色、透明度等,字典类型,默认为 None。
- fit_kws: 数据拟合的其他参数,如函数类型、拟合方法等,字典类型,默认为 None。
- color: 整个图的颜色,字符串类型,默认为 None。
- vertical: 是否纵向绘图,布尔类型,默认为 False。
- norm_hist: 直方图是否规范化,默认为 False。
- axlabel: x轴或y轴标签,字符串类型,默认为 None。
- label: 图例的标签,字符串类型,默认为 None。
- ax: 指定绘制的坐标轴,matplotlib坐标轴对象,默认为 None。
输出:
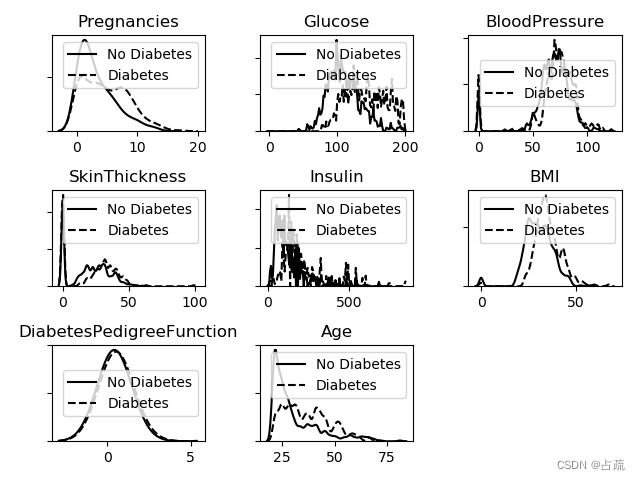
?基于上面的显示,可以做出以下分析:
可以发现哪些因素是强预测因子
哪些曲线符合正态分布(这是我们期望的)
哪个是不可能值,异常的值
参考:?
fig, ax = plt.subplots(2, 2, figsize=(20,20)) # 返回一个 Figure实例fig 和一个 AxesSubplot实例ax fig代表整个图像,ax代表坐标轴和画的图,ax是保存 AxesSubplot实例 的 ndarray数组,通过下标获取需要的子区域。
ax[0][0].plot()? ?# 在第0行的第0个子区域画图
python的matlablib画图库------画布fig和坐标轴ax_python plt dpi ax-CSDN博客
- Pandas库提供了
Series?DataFrame等类型的对象,可以在matplotlib画图中作为数据来源放入参数中,如axes.plot(Series) - 可以对Pandas的对象调用画图方法,如
Series.plot(kind='line'),但说到底还是与matplotlib有关的,是pandas自动帮你生成了axes对象。
【matplotlib绘图】Pandas绘图与matplotlib绘图的关联及异同_pandas和matplotlib区别-CSDN博客
?python神经网络项目实战
文章来源:https://blog.csdn.net/qq_43242266/article/details/135406427
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!