HiveSql语法优化二 :join算法
????????Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等,下面对每种join算法做简要说明:
Common Join
????????Common Join是Hive中最稳定的join算法,其通过一个MapReduce?Job完成一个join操作。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。Common Join常常用作后备方案。
原理图如下:

????????sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系,一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务。如果sql语句中的两个join操作关联字段各不相同,则该语句的两个join操作需要各自通过一个Common Join任务实现,也就是通过两个Map Reduce任务实现。
????????比如a.key = b.key1,a表和b表用b.key1字段关联,c.key = b.key2,cc表和b表用b.key2字段关联,则a表和b表开启一个Common Join任务,a表和b表join出来的虚拟表再和c表开启一个Common Join任务。
Map Join
????????Map Join算法可以通过两个只有map阶段的Job完成一个join操作。其适用场景为大表join小表。若某join操作满足要求,则第一个Job会读取小表数据,将其制作为hash?table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。第二个Job会先从分布式缓存中读取小表数据,并缓存在Map?Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作。如下图所示:
?
Bucket Map Join
????????Bucket Map Join是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。
????????Bucket?Map?Join的核心思想是:若能保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。其原理如图所示:
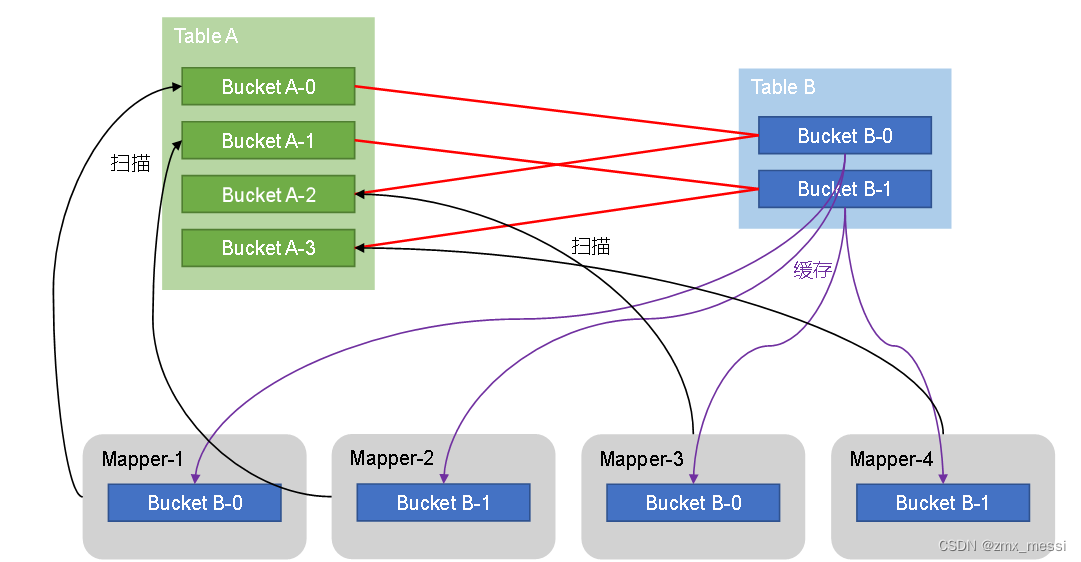
Sort?Merge?Bucket Map Join
????????Sort Merge Bucket Map Join基于Bucket Map Join。SMB?Map?Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
????????SMB?Map?Join同Bucket Map?Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作,不同的是,分桶之间的join操作的实现原理。Bucket?Map?Join,两个分桶之间的join实现原理为Hash?Join算法;而SMB?Map?Join,两个分桶之间的join实现原理为Sort?Merge?Join算法。
????????Hash?Join和Sort?Merge?Join均为关系型数据库中常见的Join实现算法。Hash?Join的原理相对简单,就是对参与join的一张表构建hash?table,然后扫描另外一张表,然后进行逐行匹配。Sort?Merge Join需要在两张按照关联字段排好序的表中进行。
????????Hive中的SMB?Map?Join就是对两个分桶的数据按照上述思路进行Join操作。可以看出,SMB?Map?Join与Bucket?Map?Join相比,在进行Join操作时,Map端是无需对整个Bucket构建hash?table,也无需在Map端缓存整个Bucket数据(优势),每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!