Pytorch:Tensorboard简要学习
目录
一、TensorBoard简介
TensorBoard 是Google开发的一个机器学习可视化工具,其主要用于记录机器学习过程用于数据可视化的工具。它包含在流行的开源机器学习库Tensorflow 中。虽然Tensorboard是TensorFlow的一部分,但是可以独立安装,并且服务于Pytorch等其他的框架。Tensorboard的功能可以描述如下:
- 记录损失变化、准确率变化等
- 记录图片变化、语音变化、文本变化等
- 绘制模型
Tensorboard具体能够支持哪些内容可以参考官方文档
Tensorboard界面:
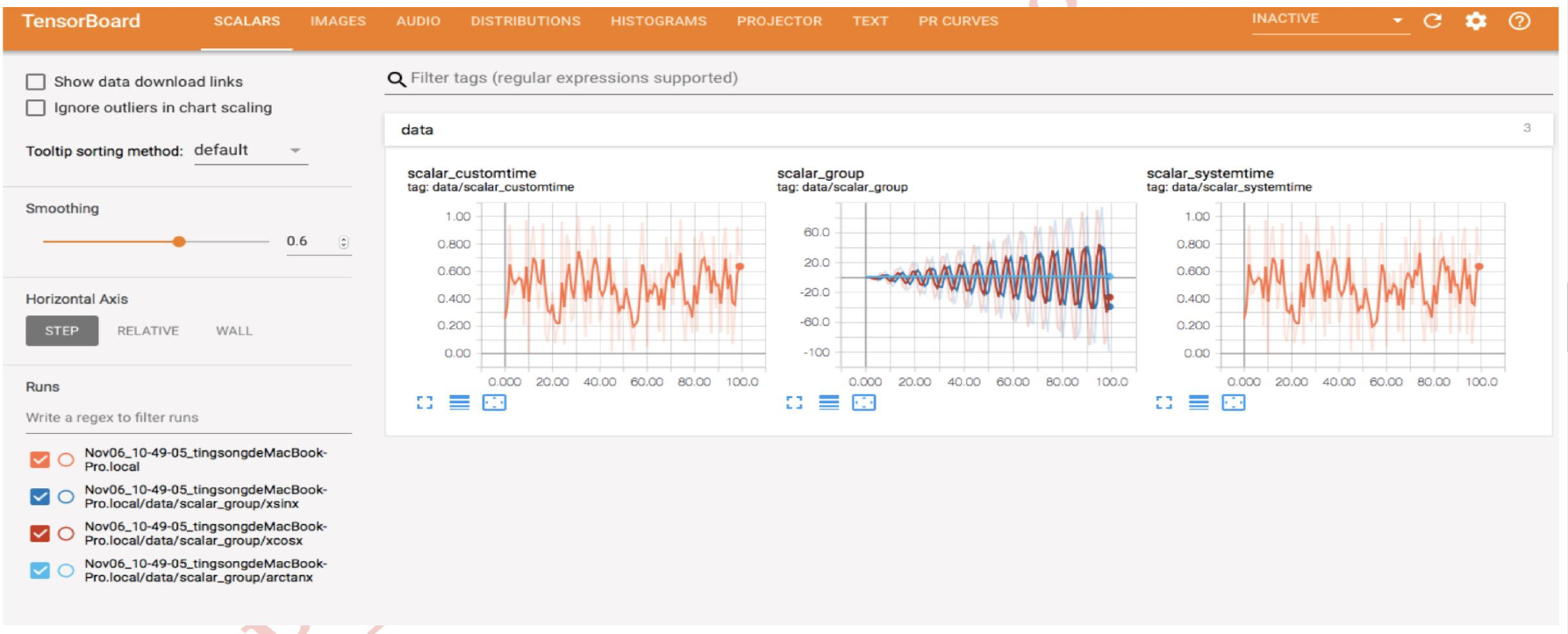
二、TensorBoard的安装与启动
Tensorboard的安装
由于TensorBoard 包含在 TensorFlow 库中,所以可以通过TensorFlow来使用Tensorboard。此外我们也可以单独安装 TensorBoard ,在Terminal使用如下命令(以Pycharm中的venv为例):
pip install Tensorboard
执行命令后,在Terminal使用如下命令以测试是否安装成功:
tensorboard --help
如果正常输出则说明安装成功。
Tensorboard的启动
(1)在 Jupyter Notebooks 中使用 TensorBoard
在Jupyter Notebooks 中使用 TensorBoard,可以使用以下命令:
%load_ext tensorboard
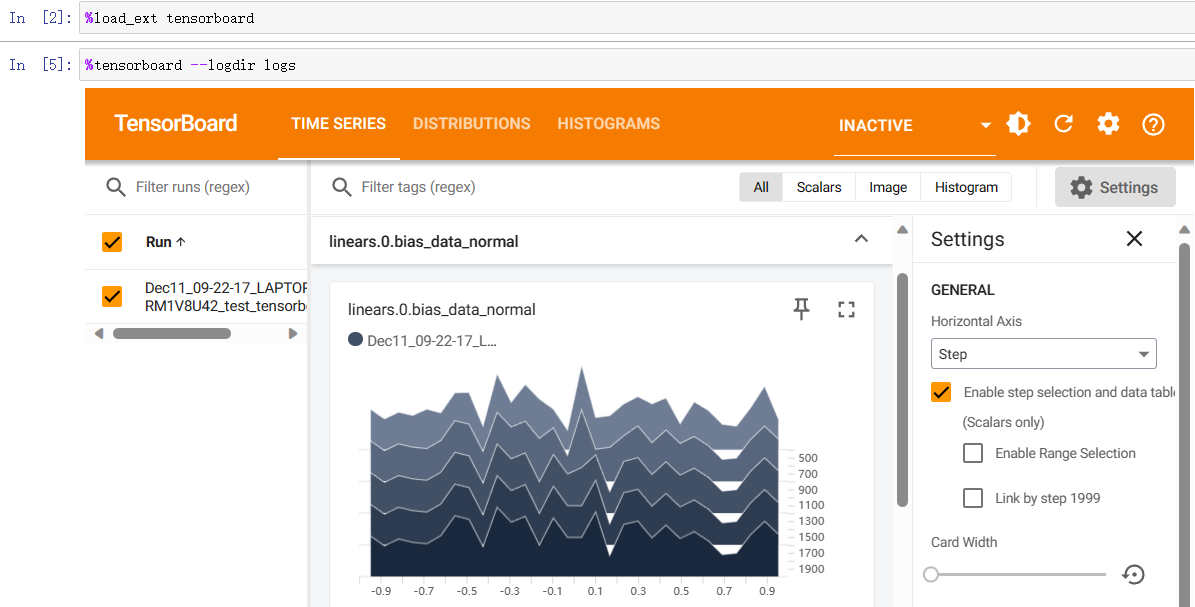
运行这行代码将加载 TensorBoard并允许可视化。加载扩展后,们现在可以启动 TensorBoard:
%tensorboard --logdir logs
运行结果:(如果是首次打开将不再是这个界面,这里是因为我原来就存了都东西在runs里)
(2)本地启动TensorBoard(以Pycharm的venv为例)
要在Pycharm中(这里我用的是venv)启动 TensorBoard,打开Terminal并运行:
tensorboard --logdir=<directory_name>
directory_name是保存数据的目录,默认是“logs”。
运行此命令后,我们将看到以下提示:

这说明 TensorBoard 已经成功上线。可以使用浏览器打开http://localhost:6006/查看或者直接点击链接查看。
三、TensorBoard的简单使用
下面以Pytorch使用Tensorboard为例来看看Tensorboard的简单使用:
使用的流程可以如下图所示:

首先在可以执行的.py文件中记录可视化数据(tensor、text等),然后讲这些可视化数据保存在硬盘之中(文件格式是Tensorboard可以读取的形式),然后通过终端连接上Tensorboard读取可视化数据,最后可以在Web端可视化结果。
这其中,Pytorch使用Tensorboard主要用到了三个API:
SummaryWriter:这个用来创建一个log文件,TensorBoard面板查看时,也是需要选择查看那个log文件。add_something: 向log文件里面增添数据。例如通过add_scalar增添折线图数据,add_image可以增添图片。具体有哪些还得参考官方文档close:当训练结束后,通过close方法结束写入。
下面对主要的调用做一个介绍:
3.1 SummaryWriter()
功能:提供创建event file的高级窗口

| 属性 | 作用 |
|---|---|
| log_dir | 指定输出文件夹 |
| comment | 不指定log_dir时,文件夹后缀 |
| filename_suffix | event file文件名后缀 |
即在不指定log_dir 时,runs文件夹的子文件夹名后缀为comment的参数。
测试代码:
import numpy as np
import matplotlib.pyplot as plt
import torch
import random
from torch.utils.tensorboard import SummaryWriter
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# ----------------------------------- 0 SummaryWriter -----------------------------------
log_dir = "./train_log/test_log_dir" # 路径,"./"表示当前文件夹
# writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
3.2 add_scalar()和add_scalars()
add_scalar():
功能:记录标量
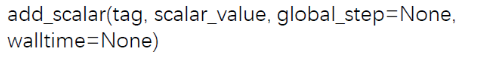
| 属性 | 作用 |
|---|---|
| tag | 图像的标签名,图的唯一标识 |
| scalar_value | 要记录的标量,相当于y轴 |
| global_step | 要记录的标量,相当于x轴 |
add_scalasr():
功能:记录多个标量

| 属性 | 作用 |
|---|---|
| tag | 图像的标签名,图的唯一标识 |
| main_tag | 该图的标签 |
| tag_scalar_dict | key是变量的tag,value是变量的值 |
测试代码:
import numpy as np
import matplotlib.pyplot as plt
import torch
import random
from torch.utils.tensorboard import SummaryWriter
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# ----------------------------------- 1 scalar and scalars -----------------------------------
max_epoch = 100
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x)}, x)
writer.close()
运行结果:
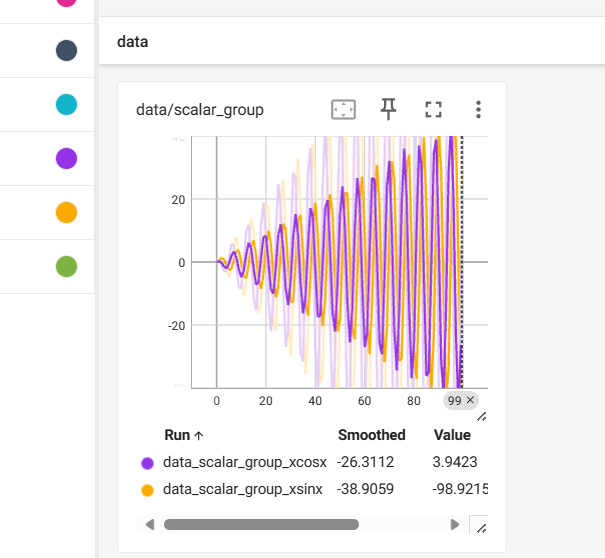
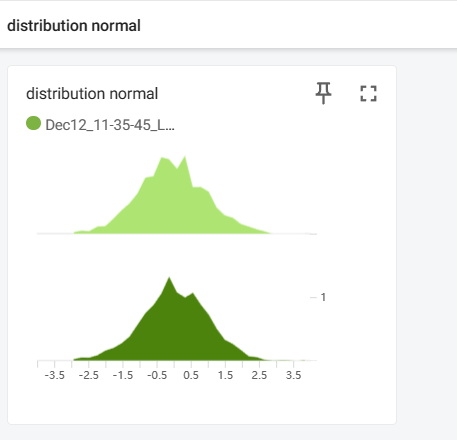
3.3 add_histogram()
功能:
统计直方图与多分位数折线图
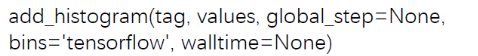
| 属性 | 作用 |
|---|---|
| tag | 图像的标签名,图的唯一标识 |
| values | 要统计的参数 |
| global_step:y轴 | |
| bins | 取直方图的bins |
blog.csdnimg.cn/direct/7b0fc8f1b99e43008c39b0314fbf915c.png)
测试代码:
import numpy as np
import matplotlib.pyplot as plt
import torch
import random
from torch.utils.tensorboard import SummaryWriter
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# ----------------------------------- 2 histogram ----------------------------------
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(2):
np.random.seed(x)
data_union = np.arange(100)
data_normal = np.random.normal(size=1000)
writer.add_histogram('distribution union', data_union, x)
writer.add_histogram('distribution normal', data_normal, x)
plt.subplot(121).hist(data_union, label="union")
plt.subplot(122).hist(data_normal, label="normal")
plt.legend()
plt.show()
writer.close()
运行结果:
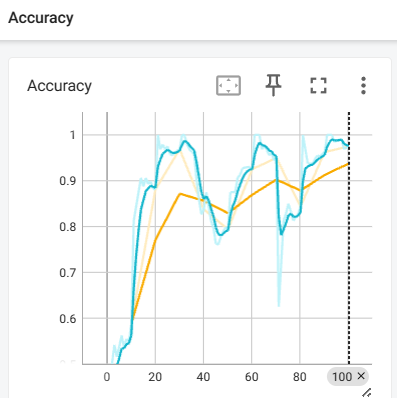
3.4 模型指标监控
此外,Tensorboard还可以实现对神经网络模型的相关参数的监控,仍然以人民币二分类模型为例,Tensorboard可视化结果如下:

四、总结
本文简要介绍了 TensorBoard,介绍了TensorBoard的安装和启动(当然并不能够应付全部情况)以及几个简单函数的使用,借助这些功能,可以能够查看和调试我们训练的模型的内部工作,并最终提高它们的性能。
参考博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!