Hadoop分布式集群搭建
Hadoop分布式集群搭建
一、集群规划
集群以三台电脑搭建,每台电脑创建一个UbuntuKylin虚拟机,集群以三台UbuntuKylin虚拟机为基础搭建,虚拟机主机名分别为hadoop101、hadoop111和hadoop121。IP地址分别为192.168.214.101、192.168.214.111和192.168.214.121。
主机名 IP地址:
hadoop101 192.168.214.101
hadoop111 192.168.214.111
hadoop121 192.168.214.121
二、网络配置
2.1. 修改主机名
通过命令:sudo vim /etc/hostname,将虚拟机主机名改为hadoop101、hadoop111、hadoop121。

2.2. 设置虚拟机IP地址,并配置静态IP
首先通过VMware的虚拟网络编辑器将虚拟机的网络配置为桥接网络(小组在搭建过程中发现net模式下,三台主机的hadoop集群搭建并不能成功)。在虚拟机设置里将网络修改为桥接模式,然后打开虚拟机,通过命令:ifconfig查看虚拟机网卡编号,然后通过命令: sudo vim /etc/network/interfaces配置静态IP,在原有的内容上添加:
auto ens33 #网卡编号
iface ens33 inet static #设置静态IP
address 192.168.214.111 #你想设置的静态IP地址
netmask 255.255.255.0 #VMware的子网掩码
gateway 192.168.214.91 #网关
dns-nameserver 8.8.8.8 114.114.114.114 #dns
然后保存退出,重启虚拟机(reboot),再次通过命令:ifconfig查看虚拟机网络是否配置成功。(一定要设置好IP地址、子网掩码、网关,不然会ping不通外网)

2.3. 主机IP映射
通过命令: sudo vim /etc/hosts来修改主机IP映射。
打开hosts文件,在文件末尾增加三条映射关系:
192.168.214.101 hadoop101
192.168.214.111 hadoop111
192.168.214.121 hadoop121
然后保存退出,重启虚拟机(reboot)。然后就ping另外两台虚拟机的IP地址,看是否可以ping通。

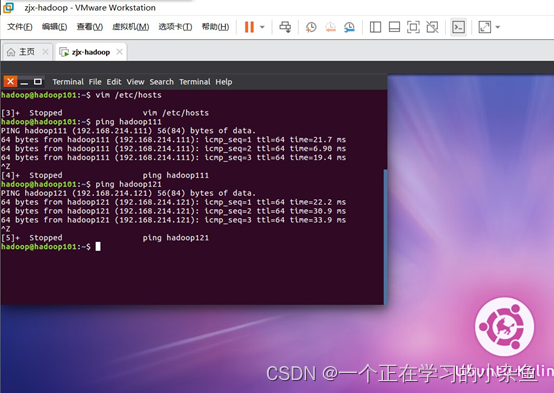
2.5. 关闭防火墙
使用命令: sudo ufw status来查看防火墙状态,inactive状态是防火墙关闭状态 active是开启状态。如果防火墙处于开启状态,那么使用命令: sudo ufw disable将防火墙关闭。
三、安装Java环境
因为hadoop需要Java运行环境,所以我们要安装Java8。首先下载jdk-8u162-linux-x64.tar.gz,保存到本地的“~/Downloads”目录下,然后在终端执行命令解压缩
cd /usr/lib
sudo mkdir jvm # 创建目录来存放JDK文件
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
#将jdk-8u162-linux-x64.tar.gz解压到/usr/lib/jvm中。
3.1.JDK环境配置
JDK文件解压缩之后,可以通过命令:cd /usr/lib/jvm进入JDK安装目录,再通过命令:ls可以查看/usr/lib/jvm内容。
然后执行命令:vim ~/.bashrc设置环境变量。在文件开头位置添加几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

然后保存退出,然后执行命令:source ~/.bashrc使配置文件生效,这时可以使用命令:java -version查看是否安装成功。

四、安装Hadoop
Hadoop安装我们选用的是hadoop-2.7.1,首先我们下载hadoop-2.7.1.tar.gz。保存到“/home/Hadoop/Downloads/”目录下。
然后将hadoop压缩包进行解压缩并移动到/usr/local中,并修改文件权限:
sudo tar -zxf ~/Downloads/Hadoop-2.7.1.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./Hadoop-2.7.1/ ./Hadoop
sudo chown -R hadoop ./Hadoop
hadoop解压完成之后即可使用,使用以下命令检查hadoop是否可用:
cd /usr/local/Hadoop
./bin/Hadoop version

4.1.Hadoop环境配置
Hadoop需要配置相关文件,才能是hadoop在伪分布式模式下顺利运行。Hadoop配置文件位于“/usr/local/Hadoop/etc/hadoop/”中,进行伪分布式模式配置时,需要修改两个配置文件,即core-site.xml和hdfs-site.xml。通过命令:sudo vim core-site.xml和sudo vim hdfs-site.xml进入文件进行编辑:
通过命令:sudo vim core-site.xml进入core-site.xml文件中,在文件中添加:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

通过命令:sudo vim hdfs-site.xml进入hdfs-site.xml文件中,在文件中添加:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>

修改完配置文件之后,要执行名称节点的格式化,命令如下:
cd /usr/local/hadoop
./bin/hdfs namenode -format
如果格式化成功之后,会看到“successfully formatted”和“Exiting with status 0”的提示信息,若出现“Exiting with status 1”则表示错误。
然后启动hadoop:
cd /usr/local/hadoop
.sbin/start-dfs.sh
Hadoop启动成功后,可以通过命令:jps来判断是否成功启动。
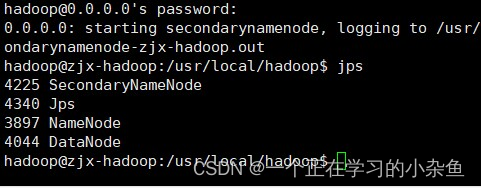
五、搭建集群
5.1. SSH无密码登录节点
要实现hadoop集群的顺利搭建,必须使主节点(hadoop101)ssh无密码登录到其他数据节点(hadoop111、hadoop121),所以必须要设置ssh无密码登录。ssh首先是分为公钥和私钥,如果我们要实现免密登录,只需要将自己的公钥提供给其他主机就行了。这里要注意的是,你有多少台虚拟机,每一台虚拟机都要知道其他的虚拟机的公钥,才可以实现免密登录。
首先,通过命令:cd .ssh/进入到.ssh目录,这个目录在home目录下,有可能你跳转到home目录下是看不到.ssh目录,但是没关系,你只需要直接跳转就行。然后通过命令:ssh-keygen -t rsa生成公钥和私钥,再通过命令:ssh-copy-id hadoop111 ssh-copy-id hadoop121将公钥拷贝到其他主机。其他的两台虚拟机上,也需要用同样的办法,拷贝公钥到另外两台虚拟机。这样就基本实现了ssh免密登录。
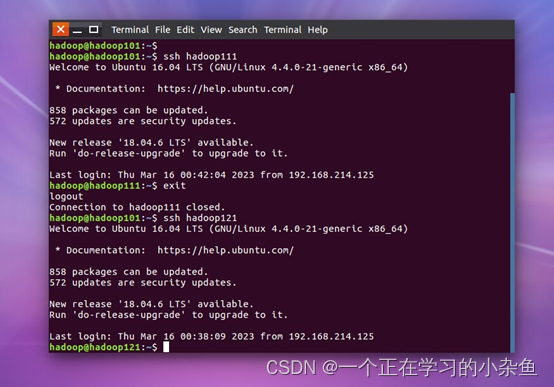
5.2. 配置集群环境
配置集群模式时,需要修改“/usr/local/hadoop/etc/hadoop”目录下的配置文件,包括slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。

5.2.1.修改slaves文件

5.2.2.修改core-site.xml文件

5.2.3.修改hdfs-site.xml文件

5.2.4.修改mapred-site.xml文件

5.2.5.修改yarn-site.xml文件

5.3.Hadoop集群启动
5.3.1.Hadoop初始化
HDFS初始化在主节点上进行,通过以下命令:
cd /usr/local/hadoop
./bin/hdfs namenode -format
5.3.2.Hadoop集群启动
在hadoopMaster节点上执行下面命令启动集群:
cd /usr/local/hadoop
./sbin/start-dfs.sh
./sbin/start-yarn.sh
./sbin/mr-jobhistory-daemon.sh start historyserver
通过命令:jps可以查看各个节点启动的进程。


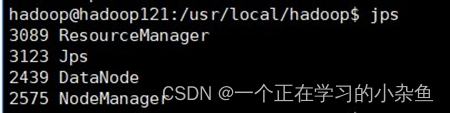
5.3.3.HDFS界面
我们可以在浏览器上查看HDFS界面
HDFS:http://192.168.214.101:50050/

5.3.4.YARN界面
我们可以在浏览器上查看YARN界面
YARN:http://192.168.214.101:8088/

5.3.5.关闭集群
接下来就是关闭集群,输入以下命令:
cd /usr/local/hadoop
./sbin/stop-yarn.sh
./sbin/stop-dfs.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver
六、问题与总结
在这次hadoop集群搭建的过程中,我遇到了很多问题,通过查资料将这些问题一一解决,以下使我们遇到的一些典型问题:
1.在虚拟机搭建初期阶段,三台虚拟机配置网络,我设置网络模式为桥接模式,并将三台IP地址的字段设置在与主机WiFi相同字段下,但在设置固定IP之后,虚拟机网络一直ping不通外网(www.baidu.com)。
解决办法:通过查资料发现,这个问题使在配置桥接网络固定IP的过程中,在/etc/network/interfaces这个文件中的网关设置有问题,原本一直写的是192.168.214.2(VMware虚拟网络编辑器中net模式下设置的网关地址),但桥接模式的网关应该是主机WiFi的网关,也就是192.168.214.91,我们将网关更改为主机WiFi的网关之后,三台虚拟机在同一个WiFi下可以互相ping通,每台虚拟机也可以ping通外网(www.baidu.com)。

2.在虚拟机搭建初期阶段,三台虚拟机配置固定IP,配置完/etc/network/interfaces这个文件,重启虚拟机之后,虚拟机直接没网,通过命令ifconfig查看ip地址发现虚拟机网卡直接没有启动。
解决办法:配置固定IP之后,重启虚拟机使配置生效,网卡直接掉,我怀疑是配置文件出现问题,重新打开/etc/network/interfaces这个配置文件,发现这个文件上的配置代码出现错误,导致虚拟机网卡无法启动。将虚拟机网络配置文件/etc/network/interfaces中的配置代码修改正确之后,重启虚拟机,使配置文件生效,发现虚拟机网络正常,固定IP配置成功。
3.在三台虚拟机上设置ssh无密码登录时,设置一直失败,导致三台虚拟机ssh无法无密码登录。
解决办法:删除原来的ssh,重新下载安装ssh。重新配置ssh无密码登录,即可解决问题。
4.hadoop集群启动之后,通过jps查看的三台虚拟机的hadoop进程出现问题。
解决办法:关闭hadoop集群,再重新启动。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!