机器学习入门六(贝叶斯网络数据分类)
老师要求做一个因果分析,没有思路。目前作者了解到了辛普森悖论,所以想找一个比较合适的方法做一下因果分析,于是找到了《Python机器学习算法与实战》这本书看了一眼里面的内容,偷学了一手贝叶斯网络书数据分类方法哈哈哈。
前言
? ? ? ? 贝叶斯网络处理一些分类问题,同时尝试用贝叶斯网络做因果分析。本文采用的数据集仍未泰坦尼克号幸存者数据集。
一、贝叶斯网络是什么?
????????贝叶斯网络是一种用于概率推理的图模型,它可以描述多个变量之间的依赖关系。贝叶斯网络反映了变量之间的条件概率分布,以节点表示变量,以有向边表示变量之间的依赖关系。如果两个变量A和B有一条指向B的有向边,则表示A影响了B,即B的条件概率分布依赖于A。贝叶斯网络可以用于很多应用场景,如医学诊断、金融风险评估、机器人导航等。下图就是托马斯 贝叶斯。有点小帅,不得不说这个模型很有东西。

????????贝叶斯网络的推理可以分为两种类型:预测和诊断。预测是指利用已知变量的值来预测其他变量的值,而诊断是指利用已知变量的值来确定某一变量的原因。预测和诊断的核心是贝叶斯规则,即在已知其他变量的条件下,计算某一变量的概率分布。下图就是一个简单的贝叶斯网络了。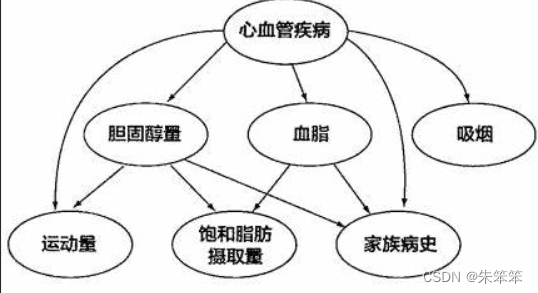
????????贝叶斯网络的构建通常涉及两个步骤:结构学习和参数学习。结构学习是指确定变量之间的依赖关系,而参数学习是指计算每个节点的条件概率分布。结构学习和参数学习可以使用最大似然估计、贝叶斯估计等方法进行。
? ? ? ? 我们呢本篇主要是想做一下分类,并且找到一定的特征之间的因果关系。下面我们直接来进入实战。
二、贝叶斯网络对泰坦尼克号数据进行分类实战
1.引入库和数据
#导入的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
import seaborn as sns
#导入数据
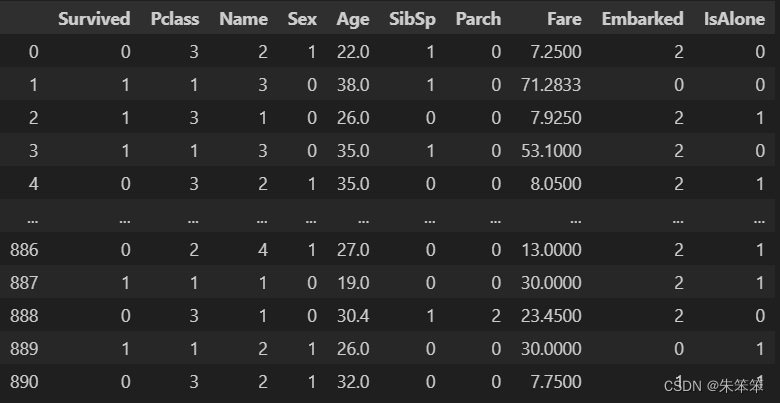
data = pd.read_csv('预处理Titanic.csv',engine='python')#有中文路径,需要设置引擎为python
data????????具体导入的数据在第4篇就已经写过了过段时间我会把数据集发上去的。?
 ?
?
这里引入的库不是很全,下面有sklearn的引入和pgmpy的引入因为作者写着写着发现总丢库哎😔?
而且我看的那本书库是写在一页的导致我学起来要不停的导入模块,不过这本书的内容还是比较精致的。
2.数据再处理
因为根据上面的输出我们可以看出有一些数据是连续性的,但我看这个模型基本上都是离散型变量,所以这里我们啊这里用k-means的聚类方法分为3类
#做简单处理 不要出现连续数据
from sklearn.preprocessing import KBinsDiscretizer
X = data[["Age","Fare"]].values
kabins = KBinsDiscretizer(n_bins=[3,3]#分箱数
,encode='ordinal'#编码方式
,strategy='kmeans'#分箱方式
)
X_kb = kabins.fit_transform(X)#分箱后的数据
X = data[["Age","Fare"]]=np.int8(X_kb)#转换为int8类型
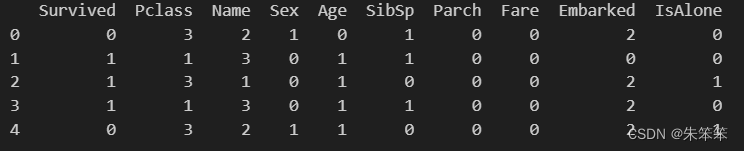
print(data.head())
3.自定义贝叶斯网络并可视化
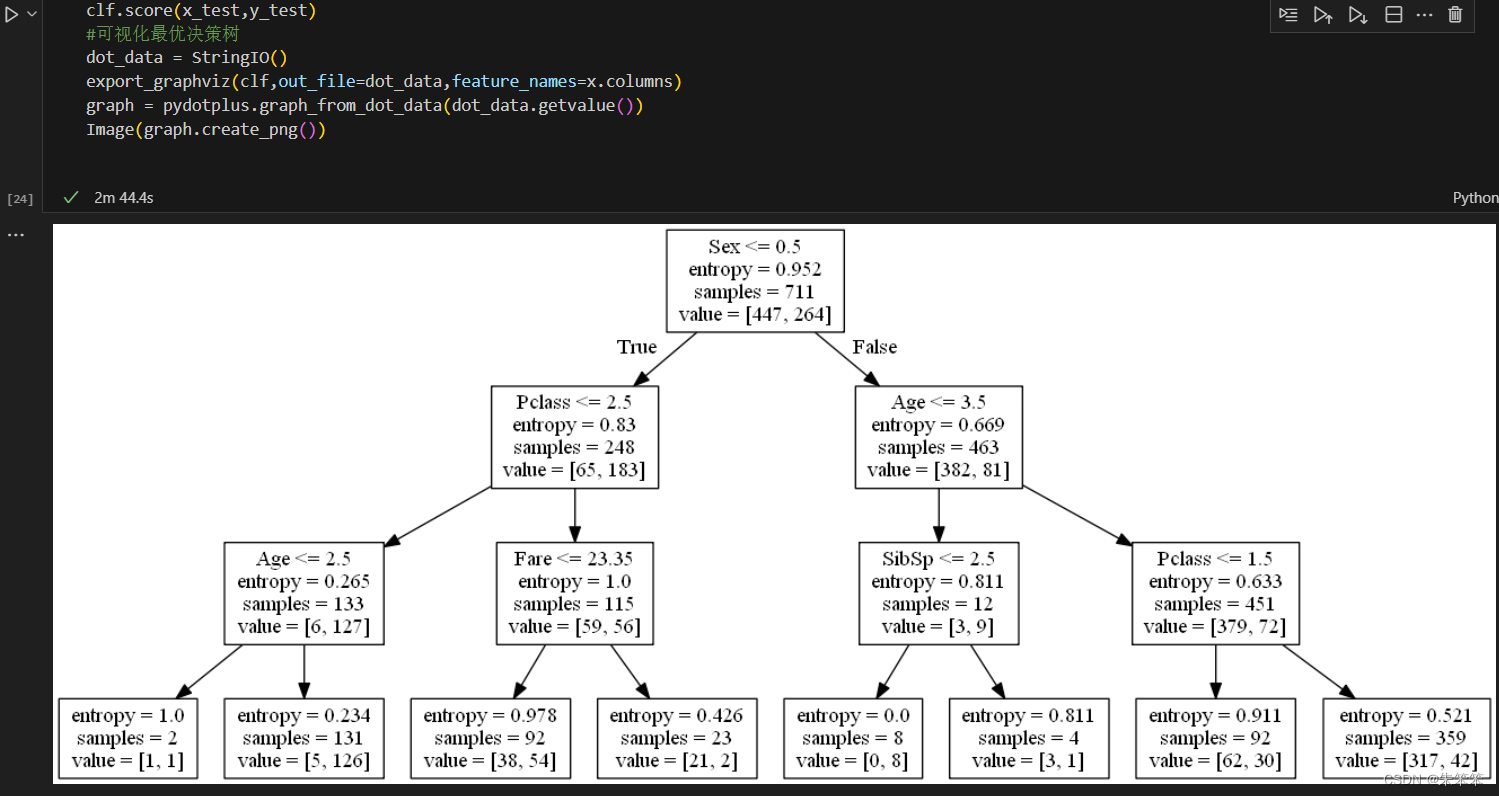
首先我们其实可以根据我们之前做过的决策树去制定一个贝叶斯网络
train = round(data.shape[0]*0.75)#训练集的行数
np.random.seed(0)#设置随机种子
Index=np.random.permutation(data.index)#随机打乱索引
train_data=data.iloc[Index[:train],:]#训练集
test_data=data.iloc[Index[train:],:]#测试集
#贝叶斯算法
#导入贝叶斯模型
import networkx as net
from pgmpy.models import DynamicBayesianNetwork as DBN
from pgmpy.models import BayesianModel
from graphviz import Digraph
## 根据前面的决策树模型,自定义一个简单的贝叶斯网络
model = BayesianModel([("Fare","Survived"), ("Pclass","Survived"),
("SibSp","Survived"),("Pclass","Fare"),
("Name", "Pclass"),("Name","SibSp"),
("Sex", "Pclass"),("Sex","Name")])
## 调用graphviz绘制贝叶斯网络的结构图
node_attr = dict(shape="ellipse",color = "lightblue2", style = "filled")
dot = Digraph(node_attr=node_attr) # 定义一个图#
dot.attr(rankdir="LR") # 指定图的可视化放心为左右
edges = model.edges() # 获取网络的边
for a,b in edges:
dot.edge(a,b)
dot然后出现导出图片
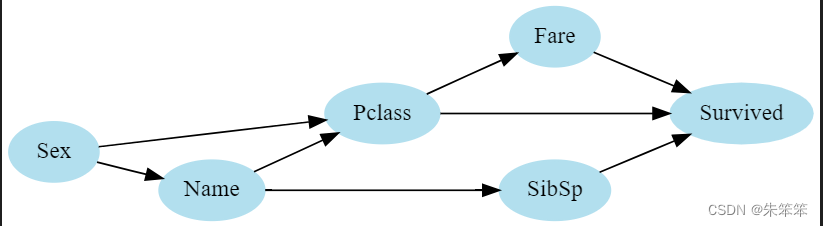
同时我们要看模型的精度,这里划分75%给训练集

?精度只有百分之66左右并不是很理想,所以我们有了4的做法
4. 启发式搜索网络结构
? ? ? ? 因为我们看了一下这里数据的特征较多,所以采用启发式搜索算法,从而获取较优的网络结构,这里我们使用爬山搜索方法 hillclimbseach()。注意:如果特征少可以搜索所有网络找到比较合适的哪个
#启发式搜索网络结构 一般来说适用于数量较多的特征
from pgmpy.estimators import HillClimbSearch
hc = HillClimbSearch(train_data)#定义启发式搜索算法,使用贝叶斯信息准则
best_model = hc.estimate()
#绘制最优网络结构
node_attr = dict(shape="ellipse",color = "lightblue2", style = "filled")
dot = Digraph(node_attr=node_attr) # 定义一个图#
dot.attr(rankdir="LR") # 指定图的可视化放心为左右
edges = best_model.edges() # 获取网络的边
for a,b in edges:
dot.edge(a,b)
dot
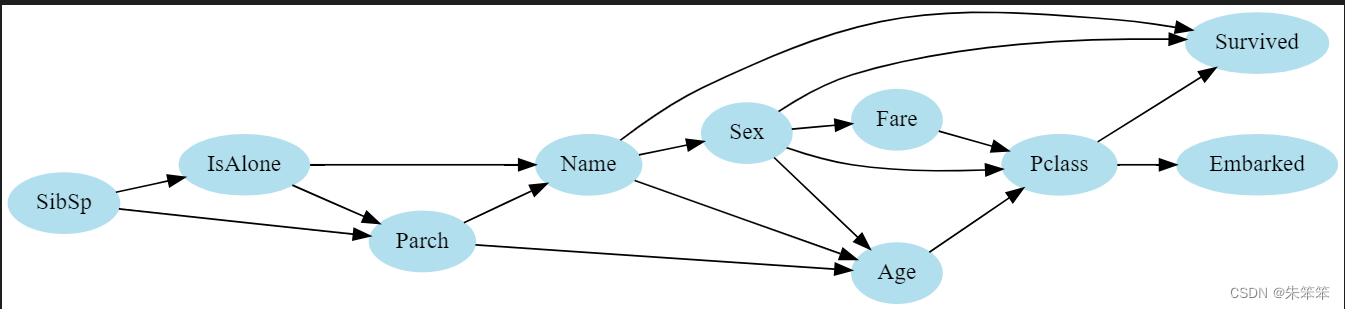 ?
?
同样的我们也要测试精度代码如下
best_model = BayesianModel(best_model.edges())#将最优网络结构转换为贝叶斯模型
best_model.fit(train_data)#训练模型
#计算精度
from sklearn.metrics import accuracy_score
print(test_data)
y_pred = best_model.predict(test_data.drop("Survived",axis=1))#预测结果
y_true = test_data["Survived"].values#真实结果
accuracy_score(y_true,y_pred)#计算精度
这次的精度就提高了一些,虽然没有到预估的,但大致上已经不错了。基于因果分析的学习,我知道了因果性!=相关性,因此贝叶斯网络在处理因果分析问题的时候可能是一个比较好的选择?
三、总结
总的来说,因为作者最近在看关于因果分析的书,然后了解到辛普森悖论。然后作者也在上大学了,平常要搞一些竞赛。因此更新尽量表征一周能更新一篇吧,感谢大家支持,也希望大家能从文章中学到一些方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!