【python】多任务编程
python多任务编程
有哪些编程提速的方法
单线程串行:不加改造的程序
多线程并发:利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
多CPU并行/多进程:利用多核CPU的能力,真正的并行执行任务
多机器并行:hadoop/hive/spark
异步IO:asyncio:在单线程利用cpu和IO同时执行的原理,实现函数异步执行
使用Lock对资源加锁,防止冲突访问
使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果
使用subprocess启动外部程序的进程,并进行输入输出交互
python并发编程
- 多线程
- 多进程
- 多协程
CPU密集型计算/IO密集型计算
- **cpu密集型计算:**也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率非常高
例如:压缩解压缩、加密解密、正则表达式搜索 - IO密集型:系统运作大部分的状况是CPU在等I/O的读/写操作,CPU占用率仍然较低
例如:文件处理程序、网络爬虫程序、读写数据库程序
多线程、多进程、多协程对比
一个进程中可以启动N个线程
多进程 Process:
优点:可以利用多核CPU进行运算
缺点:占用资源多、可启动数目比线程少
适用于:CPU密集型计算多线程 Thread:
优点:相比进程,更轻量级、占用资源小
缺点:相比进程:多线程只能并发执行,不能利用多CPU(GIL)
相比协程:启动数据有限制,占用内存资源,有线程切换开销
适用于:IO密集型计算、同时运行的任务数目要求不多一个线程中可以启动N个协程
多协程 Coroutine:
优点:内存开销最少,启动协程数量最多
缺点:支持的库有限制,代码实现复杂
适用于:IO密集型计算、需要超多任务运行、但有现有库支持的场景
python速度慢的两大原因:
相比于C/C++/JAVA,python确实慢,在一些特殊场景下,python比C++慢100~200倍
1、动态类型语言 边解释边执行
2、GIL 无法利用多核CPU并发执行
GIL是什么?
全局解释器锁:是计算机程序设计语言解释器用于同步线程的一种机制,他使得任何时刻仅有一个线程在执行
即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程
为什么有GIL这个东西?
为了解决多线程之间数据完整性和状态同步问题
怎样规避GIL带来的限制?
1、多线程机制仍然是有用的,用于I/O密集型计算
因为在I/O期间,线程会释放GIL,实现CPU和IO的并行。因此多线程用于IO密集型计算仍可以大幅度提升速度
但是多线程用于CPU密集型计算时,只会更加拖慢速度
2、使用multiprocessing的多进程制实现并行计算、利用多核CPU优势
对了应对GIL,python提供提供了multiprocessing
线程安全概念介绍
线程安全是指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能能正确完成
由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全
Lock用于解决线程安全问题
用法一:try-finally模式:
import threading
lock = threading.Lock()
lock.acquire()
try:
# do something
finally:
lock.release()
用法二:with模式
import threading l
lock = threading.Lock()
with lock:
# do something
python好用的线程池ThreadPoolExecutor
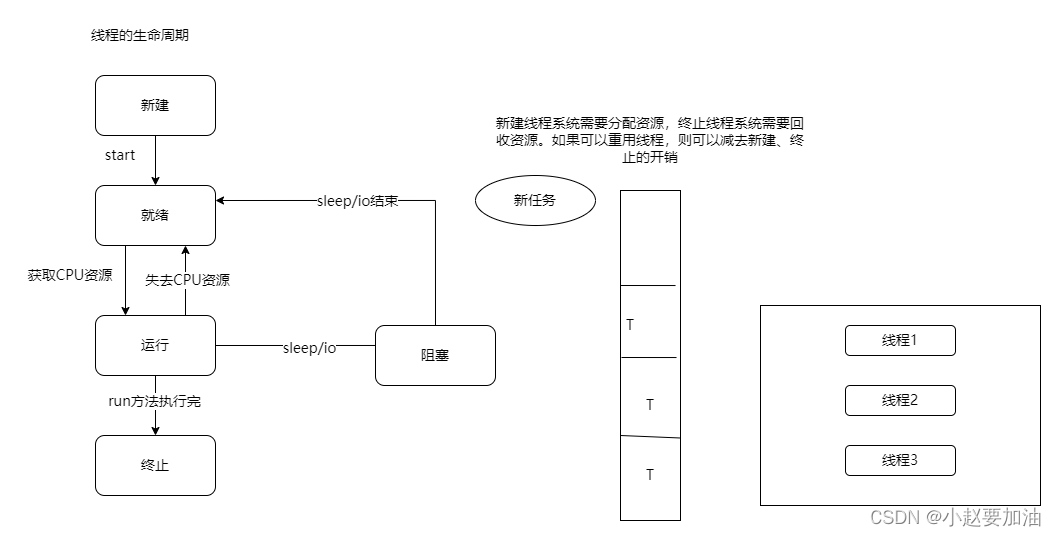
使用线程池的好处
1、提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源
2、使用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短
3、防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题
4、代码优势:使用线程池的语法比自己新建线程执行线程更加整洁
ThreadPoolExecutor的使用语法
from concurrent.futures import ThreadPoolExecutor,as_completed
# 用法一:map函数很简单,注意map的结果和入参是顺序对应的
with ThreadPoolExecutor() as pool:
results = pool.map(craw,urls)
for result in results:
print(result)
# 用法二:future模式,更强大 注意如果用as_completed顺序是不定的
with ThreadPoolExecutor as pool:
futures = [pool.submit(craw,url) for url in urls]
for future in futures:
print(future.result())
for future in as_completed(futures):
print(future.result())
python使用线程在web服务中实现加速
1、web服务的架构以及特点
Web后台服务的特点:
1、web服务对相应时间要求非常高,不如要求200MS返回
2、web服务有大量的依赖IO操作的调用,比如磁盘文件、数据库、远程API
2、使用线程池ThreadPoolExecutor加速
使用线程池ThreadPoolExcutor的好处:
1、方便的将磁盘文件、数据库、远程API的IO调用并发执行
2、线程池的线程数目不会无线创建(导致系统挂掉),具有防御功能
import flask
import json
import time
from concurrent.futures import ThreadPoolExecutor
app = flask.Flask(__name__)
pool = ThreadPoolExecutor()
def read_file():
time.sleep(0.1)
return "file_result"
def read_db():
time.sleep(0.2)
return "read db"
def read_api():
time.sleep(0.3)
return "read api"
@app_route("/")
def index():
result_file = pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
"result_file":result_file.result(),
"result_db": result_db.result(),
"result_api": result_api.result()
})
if __name__ == '__main__':
app.run()
python进程(适用于CPU密集型)

python协程:在单线程内实现并发
核心原理:用一个超级循环(其实就是while true)循环;配合IO多路复用原理(IO时可以去干其他事情)
python异步IO库:asyncio
import asyncio
# 获取时间循环
loop = asyncio.get_event_loop()
# 定义协程
async def myfunc(url):
await get_url(url)
# 创建task列表
tasks = [loop.create_task(my_func(url)) for url in urls]
# 执行爬虫时间列表
loop.run_until_complete(asyncio.wait(tasks))
注意:
需要在异步IO变成中
以来的库必须支持异步IO特征
爬虫引用中:requests 不支持异步 需要用aiohttp
在异步IO中使用信号量控制爬虫并发度
import asyncio
import aiohttp
urls = [
"https://www.cnblogs.com/#p{page}".format(page=page)
for page in range(1,50+1)
]
# 进行初始化一个并发量
semaphore = asyncio.Semaphore(10)
async def async_craw(url):
# 设置并发量
async with semaphore:
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"craw url:{url}".format(url=url),{len(result)})
loop = asyncio.get_event_loop()
# 创建task列表
tasks = [loop.create_task(async_craw(url)) for url in urls]
import time
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time second:" ,end - start)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!