【MySQL·8.0·源码】MySQL 表的扫描方式
前言
在进一步介绍 MySQL 优化器时,先来了解一下 MySQL 单表都有哪些扫描方式。
单表扫描方法是基表的读取基础,也是完成表连接的基础,熟悉了基表的基本扫描方式,
即可以倒推理解 MySQL 优化器层的诸多考量。
基表,即数据库中的原始表,与之对应的是视图、物化临时表或其他形式的派生表(中间生成的)
基表是直接存储实际数据的,在查询语法树中,一般叶子节点所对应的表为基表,
MySQL 语法树大致结构可以参考【MySQL·8.0·源码】MySQL 语法树结构
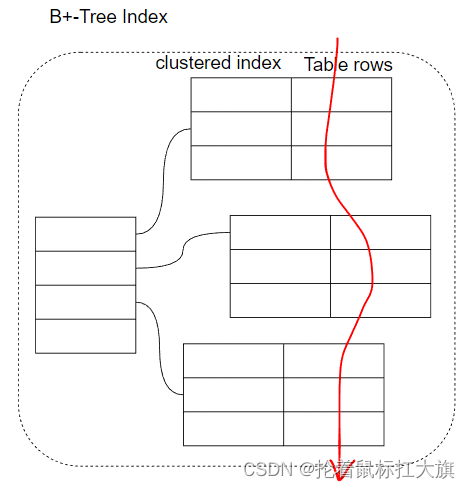
MySQL 支持不同的存储引擎,以 InnoDB 举例,InnoDB 存储引擎采用的是
一种 Index-organized(clustered index)的方式来组织数据。
InnoDB 数据存储的一些关键特点:
- InnoDB 内部数据分割成固定大小的数据页(16KB)
- 每个数据页中存储有序的数据行,且按照主键(即聚簇索引)顺序存储,主键本身也是一颗 B+ 树
- 非主键索引即二级索引叶子节点存储主键值,而非实际数据行,想通过二级索引定位到实际行要通过主键跳转
对物理结构感兴趣的可以去看 innodb_ruby 工程
和 innodb_diagrams
AccessMethods
对基表的读取方式,数据库中有专门的术语,称为 access method
想要读取一张表的记录,无非两种方式:
- 直接从表存储的页上进行扫描,即直接做表扫描
- 通过索引检索记录数据
直接表扫描比较简单,因为记录行已经是按某种顺序存储在数据页上的,直接扫描 data page
索引扫描,根据索引不同(clustered key、second index key),可以衍生出多种扫描方式
TABLE_SCAN
在 TABLE_SCAN 中,所有非空的数据页都会被扫描一次,无论被扫描的数据页是否包含所期望的记录,
但仅只会被扫描一次,然后可以对扫描的记录进行谓词比较,即可返回正确所期望的结果
INDEX_SCAN
不同类型索引的不同处理
-
clustered index
由于 clustered index 的特性:
即 tuple 是按着 clustered index 的顺序插入到 data page 中的,所以 clustered index 的键值顺序和 data page 中的 tuple
的物理顺序是一致的,所以扫描 clustered index 也意味着扫描了一次 table data page。 -
second index
普通的二级索引不一样,由于二级索引上的键值顺序是以二级索引列为准,而非 tuple 实际的物理顺序,所以
如果 data 同一个 page 上两个 tuple 在二级索引列上不是紧挨着的顺序,则在扫描二级索引时,该 data page 可能
会被多次扫描到。
同 TABLE_SCAN 要完整的扫描一次所有的非空 data page 不同,INDEX_SCAN 一般无需扫描整个表,可以
通过指定索引的起始键值和终止键值,仅扫描索引值范围内的记录即可。
MySQL 的 Access Method
TABLE_SCAN
MySQL 的 TABLE_SCAN 没有特别的不同,唯一特殊的是对常量表的特别处理
- SYSTEM
当 MySQL 发现基表只有一行行记录时,MySQL 会专门将其访问类型标记为 system,并且会直接记录值
并且物化处理,以显著简化 join 顺序选择

- ALL
MySQL 将完整的 table scan 标记为 ALL,当为 ALL 时,会对所有非空的 data page 进行完整扫描一次
INDEX_SCAN
MySQL 基于索引,从减少扫描代价出发,细化了很多种扫描方式
等值查询
-
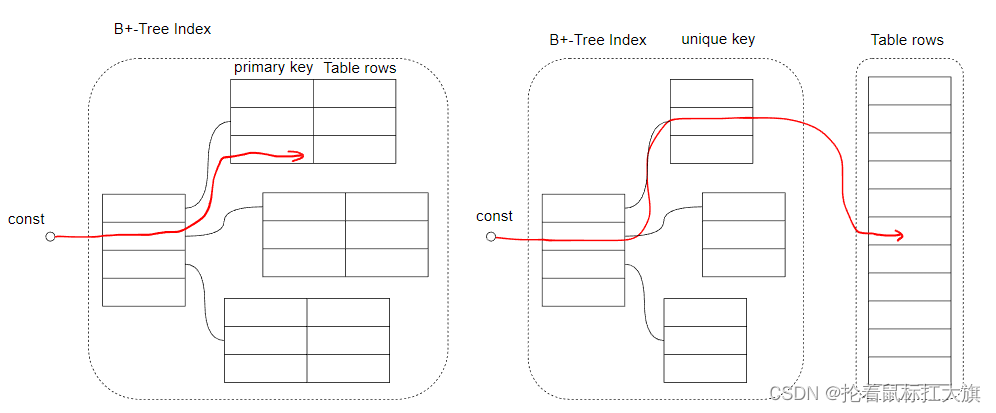
CONST
基表对于给定的查询条件中确定只有一行匹配名中的行,这种访问类型被标记为 const
场景为走主键或唯一索引键精确匹配等值查询
-
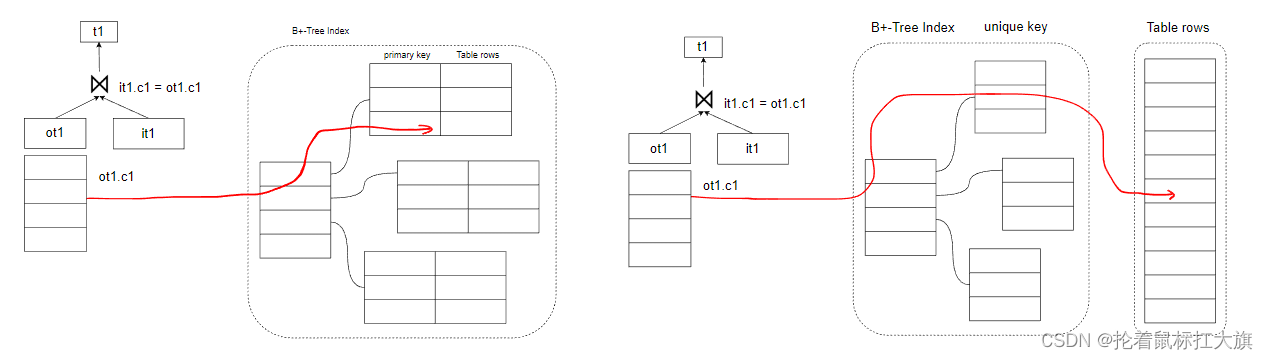
EQ_REF
eq_ref 也是基表的一种访问方式,和 const 一样,也是使用primary key或者unique key not null进行数据检索,
但和 const 不同的是,EQ_REF 是为在 join 查询中的内表连接的一种访问方式
假如说 const 是<table_name>.<key_column> = <const_value>,例如:t1.c1 = 5,t1.c1 上有主键或者不为空的唯一索引
那么 EQ_REF 为<inner_table_name>.<key_column> = <outer_table_name>.<column>,例如:it1.c1 = ot1.c2,it1.c1 上有主键或者不为空的唯一索引
-
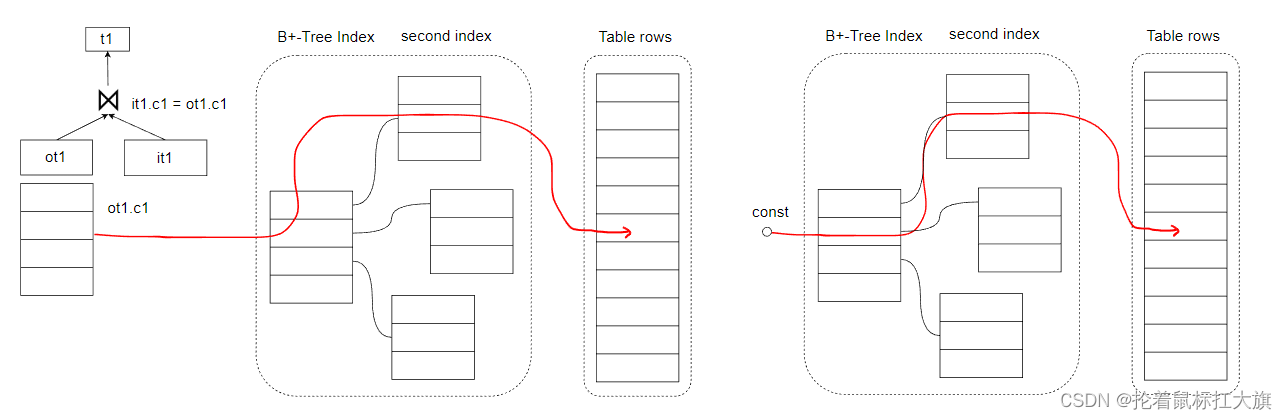
REF
如果仍然是做等值查询,但是选择的索引非primary key或者unique index,也就是说可能匹配到多行的结果,
MySQL 会将其标记为 ref 的访问类型
-
REF_OR_NULL
当给定的查询条件中涉及到 NULL 值查询时,例如:WHERE <key_column> IS NULL; WHERE <key_column> <=> NULL; WHERE <key_column> = const OR <key_column> IS NULL;此种扫描方式和 REF 相同,唯一不同的是额外会扫描 NULL 值
范围查询
- INDEX
如果不用考虑任何性能,那么对于走索引的一个范围查询,最简单的方式就是不管三七二十一,对索引树的叶子结点全部
扫描一次进行然后继续对比,匹配的再进行一次回表取记录即可
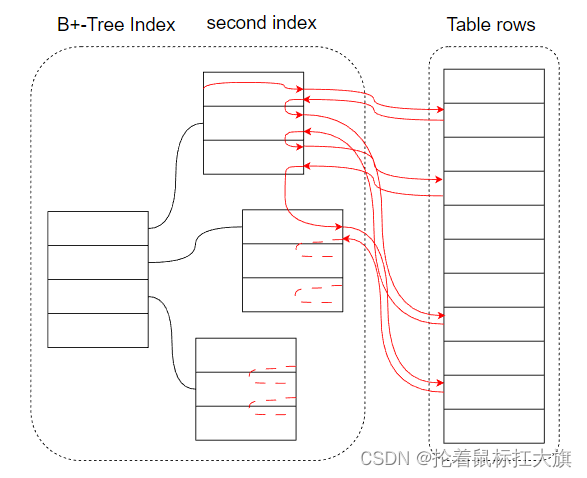
- Using index
对于二级索引扫描,如果select fields即查询列表中,仅仅需要包含在二级索引列上的字段,那么
回表取行记录的动作即可避免,少了回表的 IO 操作

- Using index
- RANGE
虽然一般来说,索引index page比数据data page来的更小,但如果每次都做一次索引 page 全扫描,
代价也很高,而且根本发挥不出索引的最大作用,索引最大的作用在于可以根据给定的索引值快速定位到其
在索引上的位置-
INDEX_RANGE_SCAN
所以,如果给定的条件是一个范围,那么完全可以定位到范围的起始位置,然后扫描索引到结束位置即可
例如:WHERE <key_column> >= 3 and <key_column> <=20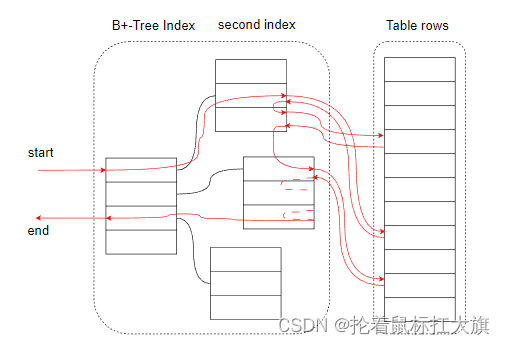
这个范围可以进一步拓展到任何以下的操作符:
=, <>, >, >=, <, <=, IS NULL, <=>, BEWTEEN, LIKE, 或者 IN() -
INDEX_SKIP_SCAN
我们知道,如果要使用索引扫描,那么条件必须满足索引的最左前缀原则:
例如 key(col1, col2, col3),那么 where 条件必须为:WHERE col1 <opcode> const WHERE col1 <comparison> const1 and col2 <comparison> const2 WHERE col1 <comparison> const1 and col2 <comparison> const2 and col3 <comparison> const3这种形式,那假如 WHERE 条件只包含 col2 的话,还要怎么仍然借助这个索引来扫描呢
可以先读取到 key col1 的第一个值,然后与 col2 拼成新的范围:
<col1_first_value>, start到<col2_first_value>, end,
然后跳到col1的下一个不同的值,继续
拼成新的范围:
<col1_second_diff_value>, start到<col1_second_diff_value>, end,
一直扫描完整个索引,此种相对于扫描整个索引而言,不断跳过了col1相同的值部分,如果该
索引col1上的值具有比较稀疏的特性,那么相对于扫描整个索引会减少很多部分的扫描

-
MRR(Multi-Range Read)
当 WHERE 给定的条件中,不止一个 RANGE,即给定了索引上的多个start, end范围段
那么就需要在索引上对多个 RANGE 进行扫描,由于 Table_rows 是以聚簇索引的顺序组织的
而 second index 二级索引上邻近的 key 值,聚餐索引上可能相差很大,那么扫描一个 second index 的 page,
可能需要回表多个 data page,而同一个 data page 也可能会被扫描到多次

为了避免 data page 的随机扫描和同一个 page 的多次扫描,我们仅仅需要在回表前,对回表的 primary key 进行排序处理即可
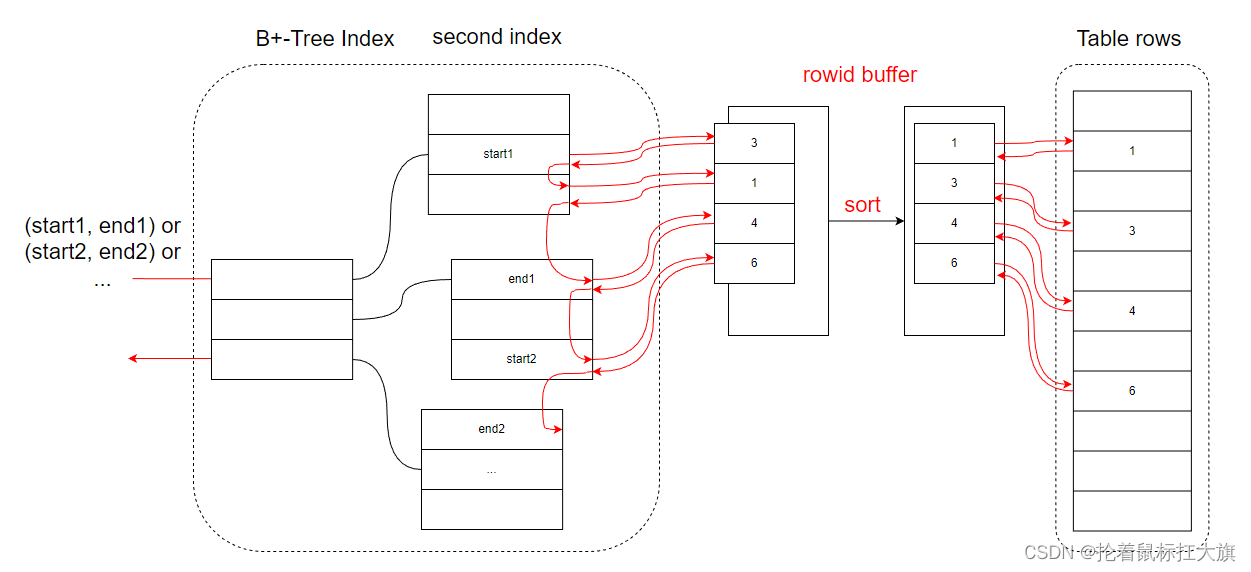
-
GROUP_INDEX_SKIP_SCAN
假如有个查询需求,需要查某个列的 distinct 值,或者 group by 之后的值 MIN()/MAX() 值,
最简单的方式是扫描整个数据页,然后分组排序后,取 DISTINCT/MIN/MAX 值
但由于索引本身就有序并且完成了 group by 工作,如果可以直接借助于这个索引的有序性,
那么扫描整个索引就可以避免二次排序的开销SELECT DISTINCT Key_col1 from t1; SELECT MAX(key_col2), key_col1 from t1 WHERE key_col1 = 1 AND key_col2 < 2 GROUP BY key_col1;
这样相比较与索引扫描而言,减少了很多的索引扫描,索引稀疏性越好,性能就会相对更好

- INDEX_MERGE
对于同一个索引的 RANGE 查询,无非是点值查询,范围查询,多范围查询,甚至遍历整个索引
但如果对 WHERE 条件分析后,发现针对不同的范围,可以走不同的索引,那么就可以通过多个索引来进行检索
但如果简单地借助于多个索引进行检索,则不同的索引可能回表到同一行记录,这样就可能造成返回重复记录
为了避免重复记录的返回,需要对多个索引的结果进行去重处理
去重处理的 merge 按行为又可以分为 union(并集)、intersections(交集)和 unions-of-intersections(交集后的并集)-
Index Merge Intersection
示例:SELECT * FROM tbl_name WHERE key1_col1 = 1 AND key1_col2 = 2 AND key2_col = 2;key1: 索引 1,联合索引,字段为 col1 和 col2
key2: 索引 2选择索引
key1或者key2分别进行 range 扫描,然后取交集
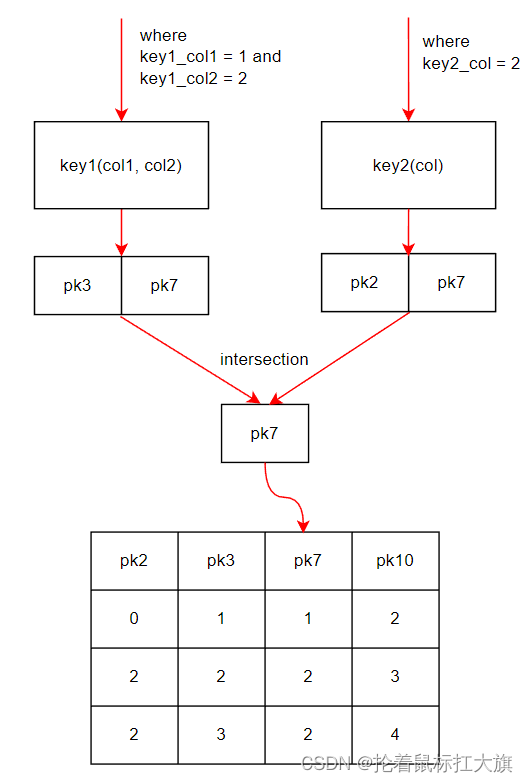
-
Index Merge Union
示例:SELECT * FROM t1 WHERE key1 = 1 OR key2 = 2 OR key3 = 3;选择
key1,key2和key3分别进行索引扫描,然后对结果取并集

-
Index Merge Sort-Union
Sort-union 和 union 访问方式类似,区别在于,sort-union 需要先获取 rowid 之后,在返回行记录之前进行排序处理
示例:SELECT * FROM tbl_name WHERE key_col1 < 10 OR key_col2 < 20; SELECT * FROM tbl_name WHERE (key_col1 > 10 OR key_col2 = 20) AND nonkey_col = 30;
-
-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!