Python银行营销响应模型实战
目录
????????在金融信贷领域的获客环节中,银行/金融机构往往通过电销的方式来邀请客户进行存款、购买金融产品、借贷等活动,而营销响应模型可以在营销活动数据基础上,通过学习是否成功营销和特征数据间的关系、能够精准识别未来其他客户的响应概率(如购买理财产品意愿),只针对高响应人员营销、从而极大提升营销人员工作效率。
一、数据介绍及预处理
1、数据介绍
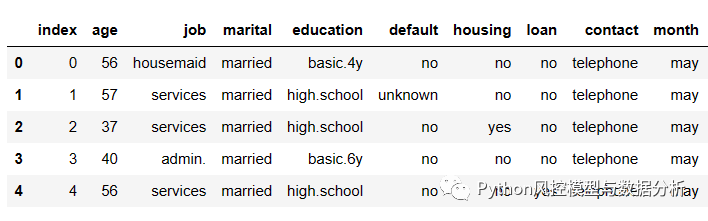
? ? ? ??数据来源某比赛网站(下图仅为部分字段),该数据集包含有关葡萄牙银行机构电话营销活动的信息,为了评估产品(银行定期存款)是否会被认购,通常需要与同一客户进行多次联系,最终电话营销后是否进行定期存款为目标变量,以此来识别哪些是营销响应的客户,通过训练模型可以预测出未来哪些客户响应概率高、从而优化电话营销动作的人力配置。文末获取数据集

????????数据包括年龄、工作、婚姻状况、教育、违约状况、余额、住房状况、贷款状况、联系信息、联系的星期几、联系的月份、最后一次联系的持续时间、营销期间的联系人数、自从上一个活动中最后一次联系客户之后经过的天数等。有了这些数据,就可以创建一个模型来准确预测潜在客户是否会订阅定期存款。
数据说明
-
index:行的索引
-
age:人的年龄
-
job:人的工作
-
marital:婚姻状况
-
education:人的受教育程度
-
default:此人是否有违约信用
-
housing:该人是否有住房贷款
-
loan:此人是否有个人贷款
-
contact:此人的联系人通讯类型
-
day:最后一次联系的星期几
-
month:最后一次联系的月份
-
duration:最后一次联系的持续时间,以秒为单位
-
campaign:在此活动期间并为此客户执行的联系数量
-
pdays:从上一个活动中最后一次联系客户之后经过的天数
-
previous:在此活动之前和为此客户执行的联系次数
-
poutcome:上一次营销活动的结果
-
emp.var.rate:就业变化率-季度指标
-
cons.price.idx:消费者价格指数-月度指标
-
cons.conf.idx:消费者信心指数-月度指标
-
euribor3m:euribor?3个月利率-每日指标
-
y:客户是否订阅了定期存款
2、数据查看及预处理
????????(1)数据清洗:数据集中存在大量的"字符,需要逐列剔除,包括列名、列值的处理;
????????(2)y列编码:y(是否响应)列的值为yes/no,建模之前我们先编码成0/1
????????(3)类别型变量处理:注意到数据集中包括多列类别型变量,所以这里直接使用catboost来建模(仅需指定类别型变量名列表即可)
def data_pred(df):
df.columns=[col.replace('"','') for col in df.columns]
for col in df.select_dtypes(include=['object']).columns:
df[col]=df[col].str.replace('"','')
df.y=df.y.map({'yes':1,'no':0})
return df
df=df.pipe(data_pred)
cate_fea=[col for col in df.select_dtypes(include=['object']).columns if col!='y']
float_fea=[col for col in df.select_dtypes(include=[int,float]).columns if col!='index']二、模型构建及评估
1、模型训练
????????使用catboost构建二分类模型,按照8:2的比例划分训练集、测试集,然后使用ks、auc进行效果评估,结果如下、auc轻松达到0.95

import catboost
from catboost import CatBoostRegressor,CatBoostClassifier
from math import sqrt
def ks_auc_value(y_value,y_pred):
fpr,tpr,thresholds= roc_curve(list(y_value),list(y_pred))
ks=max(tpr-fpr)
auc= roc_auc_score(list(y_value),list(y_pred))
return ks,auc
def init_params_catboost():
params={
'loss_function': 'Logloss', # 损失函数,取值RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE, Poisson。默认Logloss。
'custom_loss': 'AUC', # 训练过程中计算显示的损失函数,取值Logloss、CrossEntropy、Precision、Recall、F、F1、BalancedAccuracy、AUC等等
'eval_metric': 'AUC', # 用于过度拟合检测和最佳模型选择的指标,取值范围同custom_loss
'iterations': 800, # 最大迭代次数,默认500. 别名:num_boost_round, n_estimators, num_trees
'learning_rate': 0.05, # 学习速率,默认0.03 别名:eta
'random_seed': 123, # 训练的随机种子,别名:random_state
'l2_leaf_reg': 0, # l2正则项,别名:reg_lambda
'bootstrap_type': 'Bernoulli', # 确定抽样时的样本权重,取值Bayesian、Bernoulli(伯努利实验)、MVS(仅支持cpu)、Poisson(仅支持gpu)、No(取值为No时,每棵树为简单随机抽样);默认值GPU下为Bayesian、CPU下为MVS
# 'bagging_temperature': 0, # bootstrap_type=Bayesian时使用,取值为1时采样权重服从指数分布;取值为0时所有采样权重均等于1。取值范围[0,inf),值越大、bagging就越激进
'subsample': 0.8, # 样本采样比率(行采样)
'sampling_frequency': 'PerTree', # 采样频率,取值PerTree(在构建每棵新树之前采样)、PerTreeLevel(默认值,在子树的每次分裂之前采样);仅支持CPU
'use_best_model': True, # 让模型使用效果最优的子树棵树/迭代次数,使用验证集的最优效果对应的迭代次数(eval_metric:评估指标,eval_set:验证集数据),布尔类型可取值0,1(取1时要求设置验证集数据)
'best_model_min_trees': 1000, # 最少子树棵树,和use_best_model一起使用
'depth': 4, # 树深,默认值6
'grow_policy': 'SymmetricTree', # 子树生长策略,取值SymmetricTree(默认值,对称树)、Depthwise(整层生长,同xgb)、Lossguide(叶子结点生长,同lgb)
'min_data_in_leaf': 20, # 叶子结点最小样本量
# 'max_leaves': 12, # 最大叶子结点数量
'one_hot_max_size': 100, # 对唯一值数量<one_hot_max_size的类别型特征使用one-hot编码
'rsm': 0.8, # 列采样比率,别名colsample_bylevel 取值(0,1],默认值1
'nan_mode': 'Max', # 缺失值处理方法,取值Forbidden(不支持缺失值,输入包含缺失时会报错)、Min(处理为该列的最小值,比原最小值更小)、Max(同理)
'input_borders': None, # 特征数据边界(最大最小边界)、会影响缺失值的处理(nan_mode取值Min、Max时),默认值None、在训练时特征取值的最大最小值即为特征值边界
'boosting_type': 'Ordered', # 提升类型,取值Ordered(catboost特有的排序提升,在小数据集上效果可能更好,但是运行速度较慢)、Plain(经典提升)
'max_ctr_complexity': 2, # 分类特征交叉的最高阶数,默认值4
'logging_level':'Silent', # 模型训练过程的信息输出等级,取值Silent(不输出信息)、Verbose(默认值,输出评估指标、已训练时间、剩余时间等)、Info(输出额外信息、树的棵树)、Debug(debug信息)
'metric_period': 1, # 计算目标值、评估指标的频率,默认值1、即每次迭代都输出目标值、评估指标
'early_stopping_rounds': 1000,
'border_count': 1000, # 数值型特征的分箱数,别名max_bin,取值范围[1,65535]、默认值254(CPU下), # 设置提前停止训练,在得到最佳的评估结果后、再迭代n(参数值为n)次停止训练,默认值不启用
'feature_border_type': 'GreedyLogSum', # 数值型特征的分箱方法,取值Median、Uniform、UniformAndQuantiles、MaxLogSum、MinEntropy、GreedyLogSum(默认值)
'thread_count':4,
}
return params
def catboost_model(df,y_name,fea_list,params=None,cate_col=[],random_state=123):
if params is None:
params=init_params_catboost()
x_train,x_test, y_train, y_test =train_test_split(df[fea_list],df[y_name],test_size=0.2,random_state=random_state)
model = CatBoostClassifier(**params)
model.fit(x_train, y_train,eval_set=[(x_train, y_train),(x_test,y_test)],cat_features=cate_col)
train_pred=[pred[1] for pred in model.predict_proba(x_train)]
train_ks,train_auc= ks_auc_value(y_train,train_pred)
test_pred=[pred[1] for pred in model.predict_proba(x_test)]
test_ks,test_auc= ks_auc_value(y_test,test_pred)
dic={
'train':y_train.count(),
'train_badrate':y_train.mean(),
'test':y_test.count(),
'test_badrate':y_test.mean(),
'train_ks':train_ks,
'train_auc':train_auc,
'test_ks':test_ks,
'test_auc':test_auc,
}
return dic,model
model_result,model=catboost_model(df,'y',float_fea+cate_fea,params=None,cate_col=cate_fea,random_state=123)
model_result2、特征重要性
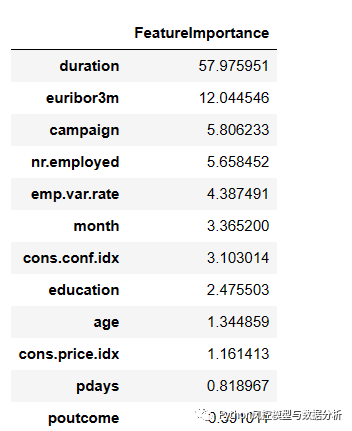
????????特征重要性中,最后一次与客户联系的时长重要性远高于其他特征,因此可以看一下这个特征的分布情况,可用于了解和指导电话营销活动。
def feature_importance_catboost(model):
result=pd.DataFrame(model.get_feature_importance(),index=model.feature_names_,columns=['FeatureImportance'])
return result.sort_values('FeatureImportance',ascending=False)
feature_importance_catboost(model)????????对y分组统计duration的分布情况,明显可以发现对定期存款响应的客户最后一次联系时长明显高于未响应用户,当然很大程度是因为客户有兴趣之后才会聊得更久,不过也可以让电销人员尽量与客户沟通时间久一些、以提高响应率。

三、划重点
少走10年弯路
? ? ? ??关注威信公众号?Python风控模型与数据分析,回复?银行营销响应实战?获取本篇数据及代码
? ? ? ? 还有更多理论、代码分享等你来拿
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!