基于python的大数据分析与应用环境的搭建
2023-12-13 13:32:22
一、主要目的:
初步熟悉Python数据分析工具,通过查阅相关说明文档掌握Numpy、Scipy和Pandas包的基本使用方法。对于不同形式的源数据文件,能够基于python开发环境正确的完成数据导入。
二、主要内容:
1、Python开发环境安装以及数据分析包的加载
(1)Anaconda安装过程
(2)相关第三方库的加载 如 爬虫scrapy包。
提示:
① Anaconda下载地址:
② Anaconda安装参考:
https://blog.csdn.net/weixin_37766087/article/details/100742198
2、通过简要的实例代码熟悉开发环境以及数据分析包的基本功能
(1)代码实例展示Spyder的基本功能
例如:代码提示、变量浏览、图形查看
- 代码实例展示Pandas 中的数据结构
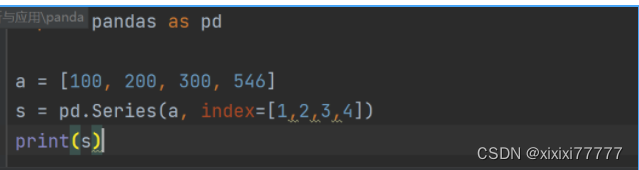
① Series:一维数组系列,也称序列
② DataFrame:二维表格型数据结构。可以将DataFrame理解为Series的容器。
- 数据的导入与导出
- 导入不同形式的文件,例如.txt/.csv/.excel
- 导出到csv/excel
- 导入导出MySql库[附选]
三、实验过程:
1.Anaconda安装过程
已安装


2.Spyder
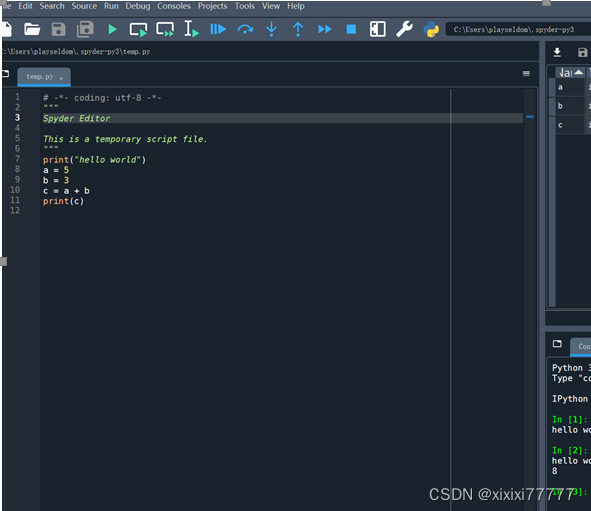
① Series:一维数组系列,也称序列

② DataFrame:二维表格型数据结构。

导入不同形式的文件,例如.txt/.csv/.excel
导入excle
- df?=?pd.read_excel(io='自己的文件路径',index_col='序号')??
- print(df)??
导出到csv/excel
Excel:
- writer?=?pd.ExcelWriter('age-name.xlsx')??
- df.to_excel(writer)??
- writer.save()??
CSV:
- csv_data?=?df.to_csv("自己的文件路径",sep='|')??
导入导出MySql库[附选]
- 从mysql中导出dataframe对象
- conn?=?pymysql.connect(host="localhost",port=3306,user="root",??
- ?password="密码已经被和谐",database="school",charset="utf8")??
- sql?=?"select?*?from?student;"??
- df?=?pd.read_sql(sql,conn)??
- print(df)?
- 导入dataframe数据到mysql
- from?sqlalchemy?import?create_engine??
- engine?=?create_engine("mysql+pymysql://root:密码已被和谐@localhost:3306/school?charset=utf8")??
- data?=?[['小明',14],['东东',18],['奥图码',53]]??
- df?=?pd.DataFrame(data,columns=['姓名','年龄'])??
- df.to_sql("try",?engine,?schema="try")??
文章来源:https://blog.csdn.net/xixixi7777/article/details/134968847
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!