【EAI 007】Mobile ALOHA:一个低成本的收集人类示教数据的双臂移动操作硬件系统
论文标题:Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
论文作者:Zipeng Fu, Tony Z. Zhao, Chelsea Finn
作者单位:Stanford University, UC Berkeley, Meta
论文原文:https://arxiv.org/abs/2401.02117
论文出处:–
论文被引:–(01/05/2024)
项目主页:https://mobile-aloha.github.io/
论文代码:
- 硬件代码:https://github.com/MarkFzp/mobile-aloha
- 软件代码:https://github.com/MarkFzp/act-plus-plus
- 硬件拆解:link
- 先前工作:https://tonyzhaozh.github.io/aloha/
Abstract
在机器人技术领域,从人类演示(human demonstrations)中进行的模仿学习(Imitation Learning,IL)已经取得了令人瞩目的成绩。然而,大多数成果都集中在桌面操作(table-top manipulation)上,缺乏一般有用任务所需的移动性和灵巧性。在这项工作中,我们开发了一套系统,用于模仿需要全身控制(whole-body control)的双臂移动操作任务。我们首先介绍了用于数据收集的低成本全身远程操作系统——Mobile ALOHA。它通过一个移动底座和一个全身远程操作界面增强了 ALOHA 系统[104]。利用Mobile ALOHA 收集的数据,我们进行了有监督的行为克隆,并发现与现有静态 ALOHA 数据集进行联合训练可提高移动操作任务的性能。通过对每个任务进行 50 次演示(demonstrations),联合训练可将成功率提高 90%,从而使 Mobile ALOHA 能够自主完成复杂的移动操作任务,例如炒虾并送到餐桌上,打开双门壁柜以存放沉重的烹饪锅,按电梯按键并进入电梯,以及使用厨房水龙头冲洗用过的平底锅。
1. Introduction
从人类提供的演示中进行模仿学习,是开发通用机器人的一个很有前途的工具,因为它允许人类向机器人传授任意技能。事实上,直接行为克隆可以让机器人学习各种原始的机器人技能,从移动机器人的车道跟随[67],到简单的拾放操作技能[12, 20],再到更精细的操作技能,如涂抹披萨酱或插入电池[18, 104]。然而,在现实的日常环境中,许多任务都需要移动和灵巧操作的全身协调,而不仅仅是单独的移动或操作行为。例如,考虑图 1 中将沉重的锅放入橱柜这一相对基本的任务。
- 机器人首先需要导航到橱柜,这就需要机器人底座的移动性。
- 要打开橱柜,机器人需要后退,同时牢牢抓住两个门把手,这就需要全身控制。
- 随后,双臂需要抓住锅的把手,一起将锅移入橱柜,这就强调了双臂协调的重要性。
与此类似,烹饪,清洁,家务管理,甚至是使用电梯在办公室中穿梭,都需要移动操作,而双臂的灵活性往往会让这些操作变得更加容易。在本文中,我们研究了将模仿学习扩展到需要双臂移动机器人全身控制的任务的可行性。

有两个主要因素阻碍了模仿学习在双臂移动操作中的广泛应用。
- 1)缺乏方便使用,即插即用的全身远程操控硬件。如果购买现成的双臂移动机械手,成本可能会很高。像 PR2 和 TIAGo 这样的机器人价格超过 20 万美元,一般的研究实验室难以承受。要在这些平台上实现远程操作,还需要额外的硬件和校准。例如,PR1 使用两个触觉设备进行双臂远程操作,并使用脚踏板控制底座[93]。之前的工作[5]使用动作捕捉系统将人类动作重定向到 TIAGo 机器人上,而 TIAGo 机器人只能控制单臂,需要仔细校准。游戏控制器和键盘也可用于远程操作 Hello Robot Stretch [2] 和 Fetch Robot[1],但不支持双臂或全身远程操作。
- 2)之前的机器人学习相关工作并未展示复杂任务的高性能双臂移动操作。虽然最近的许多研究表明,扩散模型和Transformer等表现力很强的策略类可以在细粒度,多模态操作任务中表现出色,但目前还不清楚同样的方法是否适用于移动操作:随着自由度的增加,手臂和基座动作之间的交互可能会变得复杂,基座姿势的微小偏差可能会导致手臂末端执行器姿势的大幅偏移。总之,无论是从硬件还是从学习的角度来看,之前的研究都没有为双臂移动操作提供实用且令人信服的解决方案。
在本文中,我们试图解决将模仿学习应用于双臂移动操作的难题。在硬件方面,我们提出了Mobile ALOHA,一种用于收集双体移动操作数据的低成本全身远程操作系统。Mobile ALOHA 通过将其安装在轮式底座上,扩展了原始 ALOHA 的功能,即低成本,灵巧的双臂 puppeteering 操作装置 [104]。然后,用户将身体拴在系统上,反向驱动车轮,使底座移动。这样,当用户双手控制ALOHA 时,底座可以独立移动。我们同时记录底座速度数据和手臂操作数据,形成一个全身远程操作系统。
在模仿学习方面,我们观察到,只需将底座和手臂的动作串联起来,然后通过直接模仿学习进行训练,就能取得很好的效果。具体来说,我们将 ALOHA 的 14-DoF 关节位置与移动底座的线速度和角速度连接起来,形成一个 16 维的动作向量。这种表述方式使Mobile ALOHA 能够直接受益于以前的深度模仿学习算法,在实现过程中几乎不需要任何改变。为了进一步提高模仿学习性能,我们受到了最近在各种机器人数据集上成功进行预训练和协同训练的启发,同时也注意到几乎没有可访问的双臂移动操作数据集。因此,我们转而利用静态双臂操作数据集的数据,这些数据集更为丰富,也更容易收集,特别是来自[81, 104]到RT-X版本[20]的静态ALOHA数据集。该数据集包含 825 个与Mobile ALOHA 任务不相关的任务集,并且双臂的安装位置不同。尽管任务和形态不同,但我们在几乎所有移动操作任务中都观察到了正迁移,其性能和数据效率与仅使用Mobile ALOHA 数据训练的策略相当或更好。这一观察结果在不同类别的先进模仿学习方法中也是一致的,包括 ACT [104] 和 Diffusion Policy [18]。
本文的主要贡献在于建立了一个学习复杂移动双臂操作任务的系统。该系统的核心是:
- 1)低成本全身远程操作系统 Mobile ALOHA。
- 2)一个简单的协同训练方法可以高效地学习复杂的移动操作任务。
我们的远程操作系统能够连续使用多个小时,例如烹饪三道菜,清洁公共浴室和洗衣服。我们的模仿学习结果也适用于各种复杂任务,如打开双门壁柜以存放沉重的烹饪锅,呼叫电梯,推椅子和清理打翻的酒。通过联合训练,我们能够在这些任务中取得 80% 以上的成功率,而每项任务只需 50 次人类示范,与不进行联合训练相比,绝对成功率平均提高了 34%。
2. Related Work
Mobile Manipulation.
当前的许多移动操作系统都采用了基于模型的控制方法,即将人类的专业知识和洞察力融入到系统的设计和架构中[9, 17, 33, 52, 93]。
- DARPA 机器人挑战赛就是基于模型的移动操控控制的一个显著例子 [56]。尽管如此,这些系统的开发和维护仍极具挑战性,通常需要团队的大量努力,而且即使是感知建模中的微小错误也会导致严重的控制失败[6, 51]。
- 最近,基于学习的方法被应用于移动操控,从而减轻了大部分繁重的工程设计。为了解决移动操作任务中高维状态和动作空间的探索问题,之前的研究使用了预定义技能基元(predefined skill primitives)[86, 91, 92],分解动作空间的强化学习 [38, 48, 58, 94, 101] 或全身控制目标 [36, 42, 99]。
- 与这些使用动作基元,状态估计器,深度图像或物体边界框的前人相关工作不同,模仿学习允许移动机械手通过直接将原始 RGB 观察结果映射到全身动作来进行端到端学习,通过使用室内环境中的真实世界数据进行大规模训练[4, 12, 78],显示出良好的效果[39, 78]。
- 之前的工作使用了通过 VR interface[76],kinesthetic teaching [100],trained RL policies [43],smartphone interface [90],动作捕捉系统[5]或人类[8]收集的专家示范(expert demonstrations)。
- 之前的研究还通过使用人体动作捕捉套件 [19, 22, 23, 26],外骨骼[32, 45, 72, 75],视觉反馈 VR 头戴设备[15, 53, 65, 87]和触觉反馈设备[14, 66]来开发仿人远程操作。Purushottam 等人开发了一种外骨骼服,该外骨骼服与一个力板相连,用于轮式人形物体的全身远程操作。
然而,目前还没有低成本的方法来收集全身专家演示的双手移动操作。我们针对这一问题提出了Mobile ALOHA。它适用于长达一小时的遥控操作,而且不需要 FPV 眼镜就能从机器人的第一视角摄像头或触觉设备上回传视频。
Imitation Learning for Robotics.
模仿学习能让机器人从专家的演示中学习[67]。行为克隆(Behavioral Cloning,BC)是将观察结果映射到行动的简化。行为克隆的改进包括:
- 将历史记录与各种架构相结合[12, 47, 59, 77],新的训练目标[10, 18, 35, 63, 104],正则化[71],运动基元[7, 44, 55, 62, 64, 97]和数据预处理[81]。
- 之前的研究还集中在多任务或小样本模仿学习[25, 27, 30, 34, 46, 50, 88, 102],语言条件模仿学习[12, 47, 82, 83],游戏数据模仿[21, 57, 74, 89],使用人类视频[16, 24, 29, 60, 69, 80, 84, 96]以及使用特定任务结构[49, 83, 103]。
- 对这些算法进行扩展后,系统就能熟练地泛化到新的物体,指令或场景 [12, 13, 28, 47, 54]。
- 最近,对从不同但相似类型的机器人收集的各种真实世界数据集进行的联合训练显示,在单臂操作[11, 20, 31, 61, 98]和导航[79]方面取得了很好的效果。
在这项工作中,我们利用现有的静态双臂操作数据集,为双臂移动操作建立了联合训练管道,并证明我们的联合训练管道提高了移动操作策略在所有任务和几种模仿学习方法中的性能和数据效率。据我们所知,我们是第一个发现利用静态操作数据集进行联合训练可以提高移动操作策略的性能和数据效率的人。
3. Mobile ALOHA Hardware
我们开发的Mobile ALOHA 是一种低成本的移动机械手,可以执行各种家庭任务。Mobile ALOHA 继承了原始 ALOHA 系统 [104] 的优点,即低成本,灵巧,可修复的双臂远程操作设置,同时将其功能扩展到桌面操作之外。具体来说,我们在设计时考虑了四个关键因素:
- 移动性:系统的移动速度与人类行走速度相当,约为 1.42 米/秒。
- 稳定:在操作重型家用物品(如锅和橱柜)时,它是稳定的。
- 全身遥控操作:所有自由度均可同时进行遥控操作,包括双臂和移动底座。
- 不受约束:板载电源和计算。
根据考虑因素 1 和 2,我们选择 AgileX Tracer AGV(Tracer)作为移动底座。Tracer 是一种低矮的差速驱动移动底座,专为仓储物流而设计。它的移动速度可达 1.6 米/秒,类似于人类的平均步行速度。它的最大有效载荷为 100 千克,高度为 163.5 毫米(作者在论文中写成了17毫米),我们可以在离地面较低的位置添加一个平衡砝码,以达到所需的翻倒稳定性。我们发现 Tracer 在无障碍建筑物中具有足够的穿越能力:它可以穿越高 10 毫米的障碍物和陡峭 8 度的斜坡,并带有负载,最小离地间隙为 30 毫米。在实践中,我们发现它能够穿越更具挑战性的地形,例如穿越地板和电梯之间的缝隙。Tracer 在美国的售价为 7,000 美元,比具有类似速度和有效载荷的 Clearpath AGV 便宜 5 倍多。

然后,我们试图在 Tracer 移动底座和ALOHA 机械臂的基础上设计一个全身远程操作系统,即一个可以同时控制底座和两个机械臂的远程操作系统(关键因素 3)。这种设计选择在家庭环境中尤为重要,因为它扩大了机器人的可用工作空间。考虑一下打开双门橱柜的任务。即使是人类,在开门时也会自然地后退,以避免碰撞和尴尬的关节配置。我们的远程操作系统不会限制这种协调的人体运动,也不会在收集的数据集中引入不必要的假象。然而,由于 ALOHA 领导臂已经占用了双手,因此设计一个全身远程操作系统具有挑战性。我们发现,将操作员的腰部拴在移动底座上的设计是最简单直接的解决方案,如图 2(左)所示。人类可以反向驱动车轮,而车轮在扭矩关闭时摩擦力非常小。我们测得在乙烯基地板上的滚动阻力约为 13N,大多数人都能接受。将操作员与移动机械手直接连接起来,还能在机器人与物体发生碰撞时获得粗略的触觉反馈。为了改善人体工程学,系留点的高度和领导臂的位置都可以独立调整,最大调整幅度为 30 厘米。在自主执行过程中,还可以通过拧松 4 个螺钉来拆卸系留结构和两个引导臂。如图 2(中)所示,这样可以减少移动机械手的占地面积和重量。为了改善人体工学和扩大工作空间,我们还将 ALOHA 的四个手臂全部朝前安装,这与最初 ALOHA 的手臂朝内安装不同。
为了使我们的移动机械手不受限制(关键因素 4),我们在底部放置了一个 1.26 千瓦时,重 14 千克的电池。它还可作为平衡砝码,避免翻倒。数据收集和推理过程中的所有计算均在一台配备 Nvidia 3070 Ti GPU(8GB VRAM)和英特尔 i7-12800H 的消费级笔记本电脑上进行。
-
它记录了 3 个罗技 C922x RGB 摄像头的stream,分辨率为 480x640,频率为 50Hz。2 个摄像头安装在跟随机器人的手腕上,1 个摄像头朝前。
-
笔记本电脑还通过 USB 串行端口接收来自所有 4 个机械臂的本体传感器数据流,并通过 CAN 总线接收来自 Tracer 移动底盘的数据流。
-
记录移动底盘的线速度和角速度,作为学习策略的动作。
-
还记录了所有 4 个机械臂的关节位置,以用作策略观察和操作。
关于机械臂的更多详情,请参阅 ALOHA 原文 [104]。
考虑到上述设计因素,我们用 3.2 万美元的预算制造了Mobile ALOHA,与 Franka Emika Panda 等单个工业 cobot 相当。如图 2(中图)所示,移动机械手相对于地面的垂直伸展距离为 65 厘米至 200 厘米,可伸出基座 100 厘米,可举起 1.5 千克重的物体,并可在 1.5 米高处施加 100 牛顿的拉力。Mobile ALOHA 可以完成的任务包括:
- Housekeeping:给植物浇水,使用真空吸尘器,装卸洗碗机,从冰箱中取出饮料,开门,使用洗衣机,甩开和铺开被子,塞进枕头,拉上和挂上外套的拉链,折叠裤子,打开/关闭台灯以及自我充电。
- Cooking:打鸡蛋,剁蒜蓉,拆开蔬菜包装,倒入液体,烤和翻转鸡腿,焯蔬菜,炒菜以及将食物盛入盘中。
- Human-robot interactions:与人打招呼并握手,打开啤酒并递给人,帮助人刮胡子和铺床。
Mobile ALOHA 的更多技术规格见图 2(右)。除了现成的机器人外,我们还开源了所有的软件和硬件部件,并提供了详细的教程,包括三维打印,组装和软件安装。教程:项目网站。
4. Co-training with Static ALOHA Data
使用模仿学习来解决现实世界中机器人任务的典型方法,是使用在特定机器人硬件平台上为目标任务收集的数据集。然而,这种简单直接的方法存在数据收集过程冗长的问题,人类操作员需要从头开始收集特定机器人硬件平台上每项任务的演示数据。由于这些数据集的视觉多样性有限,在这些专门数据集上训练出来的策略往往对感知扰动(如干扰因素和光照变化)不具鲁棒性[95]。最近,对从不同但相似类型的机器人收集的各种真实世界数据集进行联合训练,在单臂操作 [11, 20, 31, 61] 和导航 [79] 方面取得了可喜的成果。
在这项工作中,我们使用联合训练管道,利用现有的静态 ALOHA 数据集来提高移动操作(特别是双臂动作)的模仿学习性能。静态ALOHA数据集[81, 104]总共有825个演示任务,包括密封密封袋,拿起叉子,包装糖果,撕纸巾,打开带盖的塑料杯,玩乒乓球,分发胶带,使用咖啡机,铅笔翻转,固定魔术贴电缆,给电池开槽和操作螺丝刀。请注意,静态 ALOHA 数据都是在黑色桌面上收集的,两只手臂固定朝向对方。这种设置与Mobile ALOHA 不同,Mobile ALOHA 的背景会随着移动底座的变化而变化,两臂平行朝前放置。在联合训练中,我们没有对静态 ALOHA 数据中的 RGB 观察结果或双臂动作使用任何特殊的数据处理技术。
将汇总的静态 ALOHA 数据记为 asDstatic,将任务 m 的Mobile ALOHA 数据集记为 asDmmobile。双臂动作表述为目标关节位置 aarms∈R14 ,其中包括两个连续的抓手动作,基本动作表述为目标基本线速度和角速度 abase∈R2 。任务 m 的移动操作策略 πm 的训练目标是:
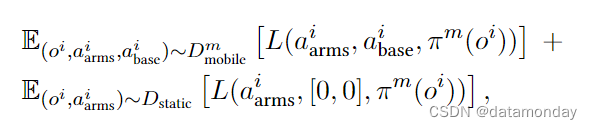
其中,oi 是由两个手腕摄像头 RGB 观测数据,一个安装在双臂之间的第一视角的顶部摄像头 RGB 观测数据和双臂的关节位置组成的观测数据,L 是模仿损失函数。我们以相同的概率从静态 ALOHA 数据 Dstatic 和Mobile ALOHA 数据 Dmmobile 中采样。我们将批量大小设置为 16。由于静态 ALOHA 数据点没有移动基础动作,因此我们将动作标签归零,这样两个数据集中的动作就具有相同的维度。我们还忽略了静态 ALOHA 数据中的前置摄像头(front camera),因此两个数据集都有 3 个摄像头。我们仅根据Mobile ALOHA 数据集 Dmmobile 的统计数据对每个动作进行归一化处理。在实验中,我们将这种联合训练方法与多种基础模仿学习方法相结合,包括 ACT [104],Diffusion Policy [18] 和 VINN [63]。
5. Tasks
我们选择的 7 项任务涵盖了现实应用中可能出现的各种能力,物体和交互。图 3 举例说明了这些任务。在 “擦酒” 任务中,机器人需要清理桌子上打翻的酒。这项任务需要移动能力和双臂灵活性。具体来说,机器人首先要走到水龙头边,拿起毛巾,然后再走回桌子边。在一只手臂举起酒杯的同时,另一只手臂需要用毛巾擦拭桌子和酒杯底部。静态的 ALOHA 无法完成这项任务,而单臂移动机器人则需要更多时间才能完成。

在烹饪虾的过程中,机器人要将一块生虾两面煎熟,然后盛入碗中。这项任务还需要移动能力和双臂灵活性:机器人需要从炉灶移动到厨房岛,并用锅铲翻炒虾,同时另一只手臂倾斜平底锅。由于翻转半熟虾的动态过程非常复杂,因此这项任务比擦拭葡萄酒需要更高的精度。由于虾可能会稍稍粘在平底锅上,因此机器人很难将锅铲伸到虾的下方并精确地将其翻转过来。
在冲洗平底锅任务中,机器人拿起一个脏平底锅,在水龙头下冲洗干净,然后放到架子上。除了前两项任务的挑战之外,打开水龙头也是一项艰巨的感知挑战。旋钮由闪亮的不锈钢制成,体积很小:长约 4 厘米,直径约 0.7 厘米。由于底座运动带来的随机性,手臂需要通过对闪亮旋钮的 “视觉控制” 来主动补偿误差。厘米级的误差可能导致任务失败。
在使用橱柜中,机器人拿起一个沉重的锅,将其放入一个双门橱柜中。看似不需要底座移动的任务,机器人实际上需要来回移动四次才能完成。例如,在打开柜门时,双臂需要抓住把手,同时底座向后移动。这对于避免与柜门发生碰撞并使双臂处于工作范围内是必要的。像这样的动作也强调了全身远程操作和控制的重要性:如果手臂和底座的控制是分开的,机器人将无法快速流畅地打开两扇门。值得注意的是,在我们的实验中,最重的壶重达 1.4 千克,超过了单臂 750 克的有效载荷限制,但仍在双臂的有效载荷范围内。
在呼叫电梯中,机器人需要按下按钮进入电梯。在这项任务中,我们强调长距离导航,大随机化和精确的全身控制。机器人从距离电梯约 15 米处开始,在 10 米宽的大厅内随机移动。要按下电梯按钮,机器人需要绕过一根柱子,然后准确地停在按钮旁边。按钮大小为 2 厘米×2 厘米,按下按钮需要精准,因为按在外围或按得太轻都无法启动电梯。机器人还需要精确地急转弯才能进入电梯门:机器人最宽的部分与电梯门之间只有 30 厘米的间隙。
在推椅子任务中,机器人需要在一张长桌前推入 5 把椅子。这项任务强调的是移动机械手的力量:它需要通过手臂和底座的协调运动来克服 5 千克重的椅子与地面之间的摩擦力。为了增加这项任务的挑战性,我们只收集前 3 把椅子的数据,并对机器人进行压力测试,以推断出第 4 和第 5 把椅子的情况。
击掌任务,我们在附录 A.1 中提供了插图。机器人需要绕着厨房岛走一圈,每当有人类从前方靠近它时,就停止移动并与人类击掌。击掌之后,只有当人类离开机器人的路径时,机器人才能继续前进。我们收集了穿着不同服装的数据,并对训练有素的策略进行了评估。虽然这项任务并不需要很高的精确度,但它凸显了 Mobile ALOHA 在研究人机交互方面的潜力。
我们要强调的是,对于上述所有任务,开环重放(open-loop replaying)演示并将物体恢复到相同配置将导致整个任务的成功率为零。要成功完成任务,就需要学习到的策略做出闭环反应,并纠正这些错误。我们认为,开环重放过程中的错误源于移动底盘的速度控制。举例来说,我们在半径为1米的180度转弯中回放基本动作时,观察到平均误差>10厘米。我们在附录 A.4 中提供了该实验的更多细节。
6. Experiments
我们的实验旨在回答两个核心问题。
- 1)通过联合训练和少量移动操作数据,Mobile ALOHA 能否掌握复杂的移动操作技能?
- 2)Mobile ALOHA 能否使用不同类型的模仿学习方法,包括 ACT [104],扩散策略 [18] 和基于检索的 VINN [63]?我们在现实世界中进行了大量实验来研究这些问题。
作为初步尝试,我们将研究的所有方法都采用了 “action chunking” [104],即策略预测一系列未来行动,而不是在每个时间步预测一个行动。这已经是 ACT 和扩散策略方法的一部分,对于 VINN 来说也很简单。我们发现,行动分块对操作至关重要,它能提高生成轨迹的一致性,减少每步策略推理的延迟。动作分块还为Mobile ALOHA 提供了一个独特的优势:更灵活地处理硬件不同部分的延迟。我们观察到移动底盘的目标速度和实际速度之间存在延迟,而位置控制臂的延迟要小得多。为了考虑移动底座的 d 步延迟,我们的机器人会执行长度为 k 的动作块(action chunk)中的前 k - d 个手臂动作和最后 k - d 个底座动作。
6.1. Co-training Improves Performance
我们从与 ALOHA 一起推出的 ACT [104] 方法开始,在有和没有联合训练的情况下对所有 7 项任务进行训练。然后,我们在真实世界中对每种策略进行评估,如图 3 所述,对机器人和物体的配置进行随机化。为了计算子任务的成功率,我们用 #Success 除以 #Attempts。例如,在 “举起玻璃杯并擦拭” 子任务中,#尝试次数等于上一个子任务 “抓住毛巾” 的成功次数,因为机器人可能在任何子任务中失败并停止。这也意味着最终成功率等于所有子任务成功率的乘积。我们在表 1 中报告了所有成功率。除 “烹饪虾” 外,每个成功率都是通过 20 次评估试验计算得出的。
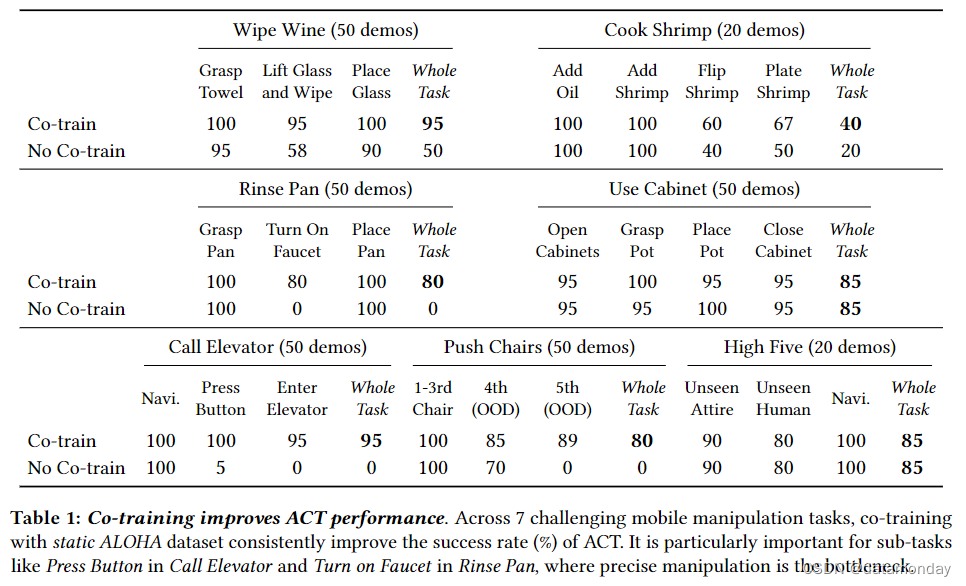
在协同训练的帮助下,机器人在擦拭红酒方面取得了 95% 的成功率,在呼叫电梯方面取得了 95% 的成功率,在使用橱柜方面取得了 85% 的成功率,在击掌方面取得了 85% 的成功率,在冲洗平底锅方面取得了 80% 的成功率,在推椅子方面取得了 80% 的成功率。每项任务只需要 50 次域内演示,击掌任务只需要 20 次。唯一成功率低于 80% 的任务是烹饪虾(40%),这是一项 75 秒的长视距任务,我们只收集了 20 次演示。我们发现,
- 策略在使用刮刀翻转虾和将虾倒入白色碗中时非常吃力,而白色碗与白色桌子的对比度很低。我们假设成功率较低的原因可能是演示数据有限。联合训练提高了 7 个任务中 5 个任务的成功率,分别提高了 45%,20%,80%,95% 和 80%。
- 在其余两个任务中,联合训练和不联合训练的成功率相当。我们发现,联合训练对于精确操作是瓶颈的子任务更有帮助,例如按下按钮,翻转虾和打开水龙头。
- 在所有这些任务中,复合误差似乎是失败的主要原因,这些误差可能来自机器人基础速度控制的随机性,也可能来自丰富的接触,例如在翻转虾的过程中抓取锅铲并与平底锅接触。
- 我们假设,静态 ALOHA 数据集中抓取和接近物体的 “运动先验” 仍然有利于 Mobile ALOHA,特别是考虑到腕部摄像头引入的不变量[41]。
- 在 “推椅子” 和 “擦酒” 的情况下,联合训练策略的泛化效果更好。对于 “推椅子”,联合训练和不联合训练都能在前 3 把椅子上取得完美的成功,这在演示中可以看到。但是,在推断第 4 和第 5 把椅子时,联合训练的效果要好得多,分别提高了 15%和 89%。对于 “擦拭酒杯”,我们观察到联合训练策略在酒杯随机化区域的边界表现更好。
因此,我们假设,考虑到 20-50 次演示的低数据机制和所使用的基于Transformer的表达式策略,联合训练也有助于防止过度拟合。
6.2. Compatibility with ACT, Diffusion Policy, and VINN
除了 ACT 之外,我们还利用Mobile ALOHA 训练了两种最新的模仿学习方法:扩散策略 [18] 和 VINN [63]。扩散策略训练神经网络,逐步完善行动预测。我们使用 DDIM 调度器[85]来提高推理速度,并将数据增强应用于图像观测,以防止过拟合。联合训练数据管道与 ACT 相同,更多训练细节见附录 A.3。VINN 会训练一个视觉呈现模型 BYOL [37],并利用它从演示数据集中检索具有最近邻的动作。我们利用本体感觉特征增强 VINN 的检索能力,并调整相对权重以平衡视觉和本体感觉特征的重要性。我们还检索了动作块,而不是单个动作,结果发现与 Zhao 等人的研究类似,性能有了显著提高。在协同训练方面,我们只需使用移动和静态数据对 BYOL 编码器进行协同训练。
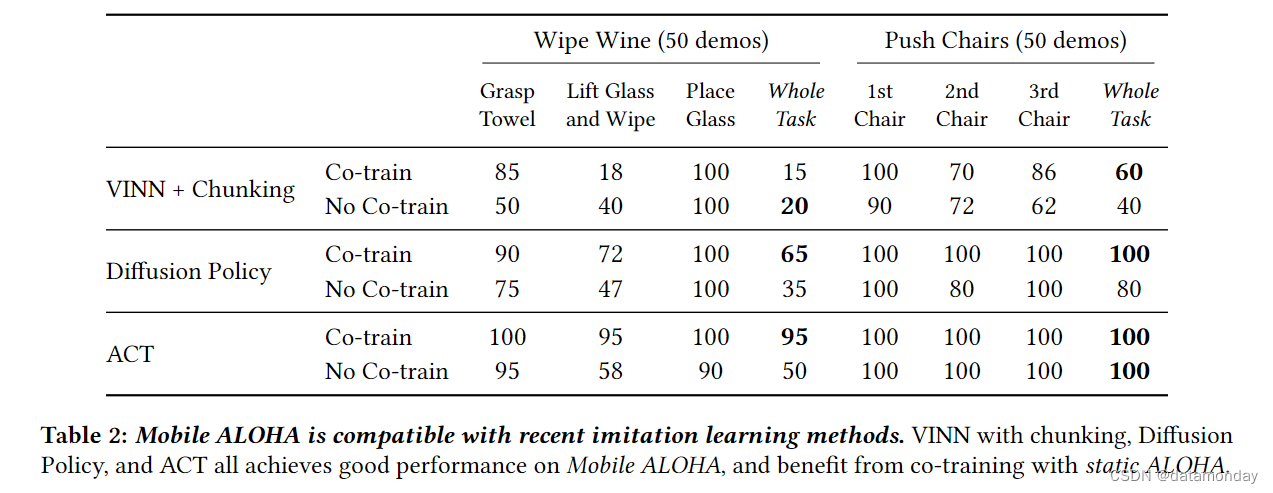
表 2 报告了在 2 个实际任务中联合训练和不联合训练的成功率:擦酒和推椅子。总体而言,扩散策略与 ACT 在 “推椅子” 任务中的表现类似,都是通过联合训练获得 100%的成功率。在 “擦酒” 任务中,我们观察到扩散策略的表现较差,只有 65% 的成功率。在接近厨房岛和抓酒杯时,扩散策略的精确度较低。鉴于扩散策略的表现力,我们推测 50 次演示对于扩散策略来说是不够的:以前使用扩散策略的相关工作往往需要对 250 次以上的演示进行训练。对于 VINN + Chunking,该策略的整体表现不如 ACT 或 Diffusion,但仍然达到了合理的成功率,在 “推椅子” 和 “擦红酒” 上的成功率分别为 60% 和 15%。主要的失败模式是在 “举起玻璃杯” 和 “擦拭” 中的不精确抓取,以及在分块之间切换时的生涩动作。我们发现,
- 在检索时增加本体感觉的比重可以提高平稳性,但代价是减少对视觉输入的关注。
- 联合训练提高了扩散策略的性能,在 “擦酒” 和 “推椅子” 上分别提高了 30% 和 20%。这在意料之中,因为联合训练有助于解决过拟合问题。
- 与 ACT 和 Diffusion Policy 不同,我们观察到 VINN 的结果好坏参半,联合训练使 “擦酒” 的性能降低了 5%,而使 “推椅子” 的性能提高了 20%。只有 VINN 的表征进行了联合训练,而 VINN 的行动预测机制没有办法利用域外静态 ALOHA 数据,这或许是这些混合结果的原因。
7. Ablation Studies
Data Efficiency.
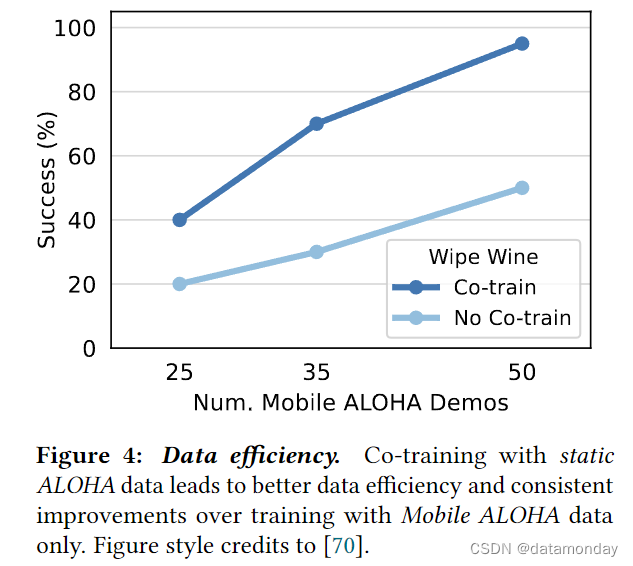
在图 4 中,我们使用 “擦酒” 任务中的 ACT,消融了联合训练和无联合训练的移动操作演示次数。我们考虑了 25,35 和 50 个Mobile ALOHA 演示,并分别进行了 20 次试验评估。我们发现,与仅使用Mobile ALOHA 数据进行训练相比,联合训练能带来更好的数据效率和持续改进。通过联合训练,使用 35 个域内演示训练的策略比不使用联合训练,使用 50 个域内演示训练的策略高出 20%(70% 对 50%)。
Co-training Is Robust To Different Data Mixtures.

在迄今为止的联合训练实验中,我们以相同的概率从静态 ALOHA 数据集和 Mobile ALOHA 任务数据集中抽样,形成训练小批量,因此联合训练数据抽样率约为 50%。在表 3 中,我们研究了不同采样策略对 Wipe Wine 任务性能的影响。除了 50% 的联合训练数据采样率外,我们还使用 30% 和 70% 的联合训练数据采样率对 ACT 进行训练,然后各评估 20 次试验。我们发现,所有测试的表现都差不多,成功率分别为 95%,95% 和 90%。这项实验表明,联合训练的性能对不同的数据混合并不敏感,从而减少了在新任务中采用联合训练所需的手动调整。
Co-training Outperforms Pre-training.
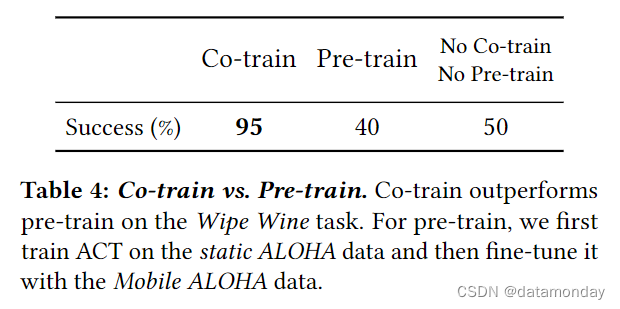
在表 4 中,我们对静态 ALOHA 数据的联合训练和预训练进行了比较。对于预训练,我们首先在静态 ALOHA 数据上对 ACT 进行 10K 步训练,然后继续使用域内任务数据进行训练。我们对 Wipe Wine 任务进行了实验,发现预训练与仅使用 Wipe Wine 数据进行训练相比没有任何改进。我们假设,在微调阶段,网络忘记了在静态 ALOHA 数据上的经验。
8. User Studies
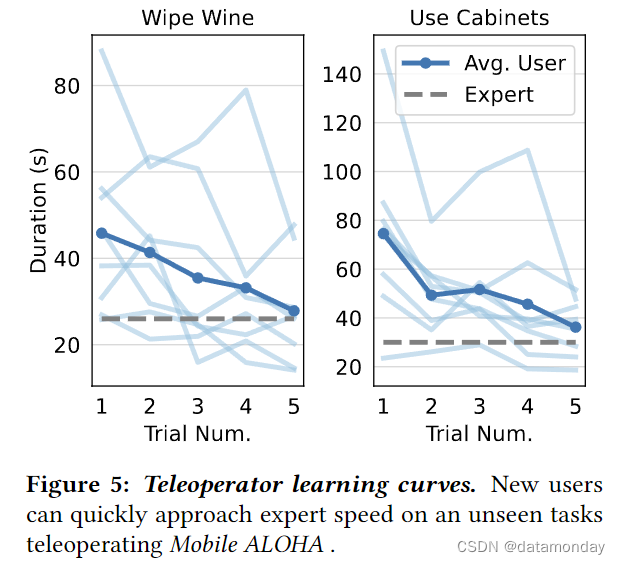
我们进行了一项用户研究,以评估Mobile ALOHA 远程操作的有效性。具体来说,我们测量参与者学习远程操作未见任务的速度。我们在计算机科学研究生中招募了 8 名参与者,其中 5 名女性和 3 名男性,年龄在 21-26 岁之间。其中 4 人没有远程操作经验,其余 4 人的专业水平参差不齐。他们中没有人使用过Mobile ALOHA。我们首先让每位参与者与场景中的物体自由互动 3 分钟。在这一过程中,我们保留了所有将用于未见任务的物体。接下来,我们给每位参与者布置了两项任务:擦酒和使用橱柜。首先由一名专家操作员演示任务,然后由参与者连续进行 5 次试验。我们记录每次试验的完成时间,并将其绘制在图 5 中。我们注意到完成时间急剧下降:平均而言,完成擦酒任务所需的时间从 46 秒降至 28 秒(下降了 39%),完成使用橱柜任务所需的时间从 75 秒降至 36 秒(下降了 52%)。平均 5 次试验后,参与者也能接近专家示范的速度,这表明Mobile ALOHA 远程操作易于使用和学习。
9. Conclusion, Limitations and Future Directions
总之,我们的论文从硬件和软件两方面论述了双臂移动操控。利用移动底座和全身远程操作增强 ALOHA 系统,我们可以收集到高质量的复杂移动操作任务演示。然后,通过与静态 ALOHA 数据共同训练的模仿学习,Mobile ALOHA 只需 20 到 50 次演示就能学会执行这些任务。我们还能保持系统的可访问性,包括板载电源和计算在内的预算不到 3.2 万美元,并且软件和硬件都是开源的。
尽管 Mobile ALOHA 简单易用,性能出色,但仍存在一些局限性,我们希望在今后的工作中加以解决。在硬件方面,
- 我们将努力减少 Mobile ALOHA 的占用面积。目前 90 厘米 x 135 厘米的占地面积对于某些路径来说可能过于狭窄。
- 由于两个随动臂的高度固定,较低的橱柜,烤箱和洗碗机也很难够到。为了解决这个问题,我们正计划增加机械臂升降的自由度。
在软件方面,
- 我们的策略学习结果仅限于单一任务的模仿学习。
- 机器人还不能自主改进或探索获取新知识。
- 此外,Mobile ALOHA 演示是由两名专家操作员收集的。对于如何从高度次优的异构数据集中进行模仿学习,我们将留待未来的工作来解决。
A. Appendix
A.1. High Five
图 6 是击掌任务的示意图。机器人需要绕着厨房岛走一圈,每当有人类从前方靠近它时,就停止移动并与人类击掌。击掌后,只有当人类离开机器人的路径时,机器人才能继续前进。我们收集了穿着不同服装的数据,并对训练好的策略进行了评估。虽然这项任务并不需要很高的精确度,但它凸显了 Mobile ALOHA 在研究人机交互方面的潜力。

A.2. Example Image Observations
图 7 展示了在数据收集过程中捕捉到的 Wipe Wine 图像示例。这些图像从上到下按时间顺序排列,从左到右依次为三个不同角度的摄像头:顶部自中心摄像头,左腕摄像头和右腕摄像头。顶部摄像头相对于机器人框架是静止的。相反,腕部摄像头连接在手臂上,可提供抓手动作的特写视图。所有摄像头都设置了固定焦距,并具有自动曝光功能,以适应不同的光线条件。这些摄像头的流媒体分辨率为 480 × 640,帧频为每秒 30 帧。

A.3. Experiment Details and Hyperparameters of ACT, Diffusion Policy and VINN
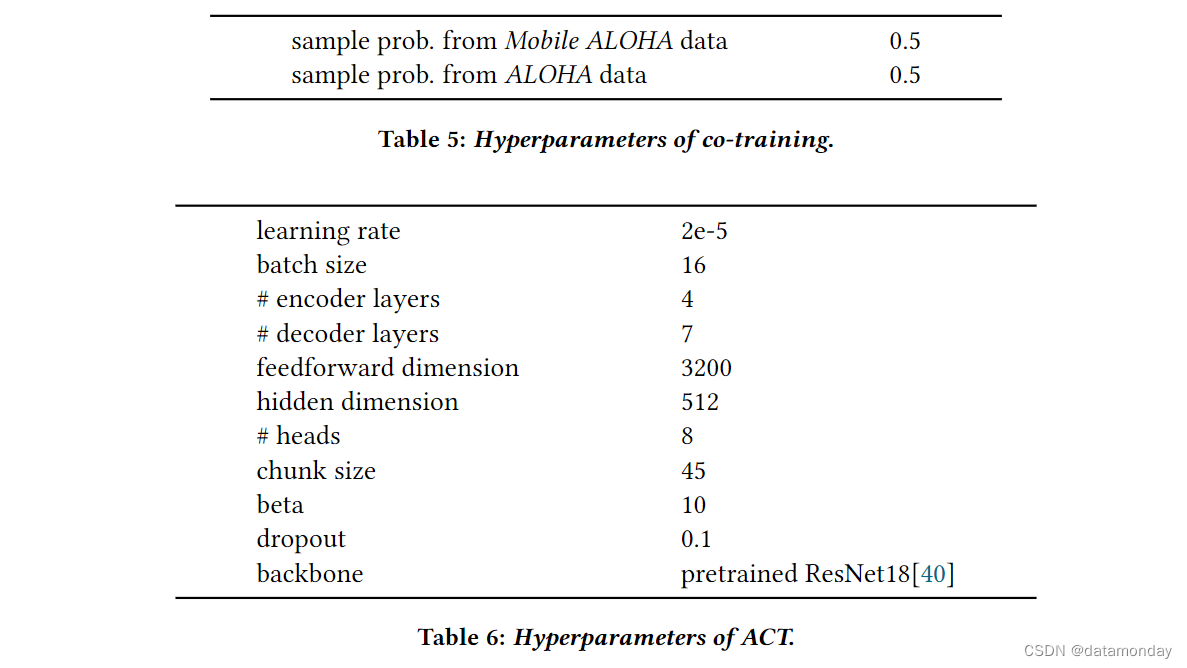
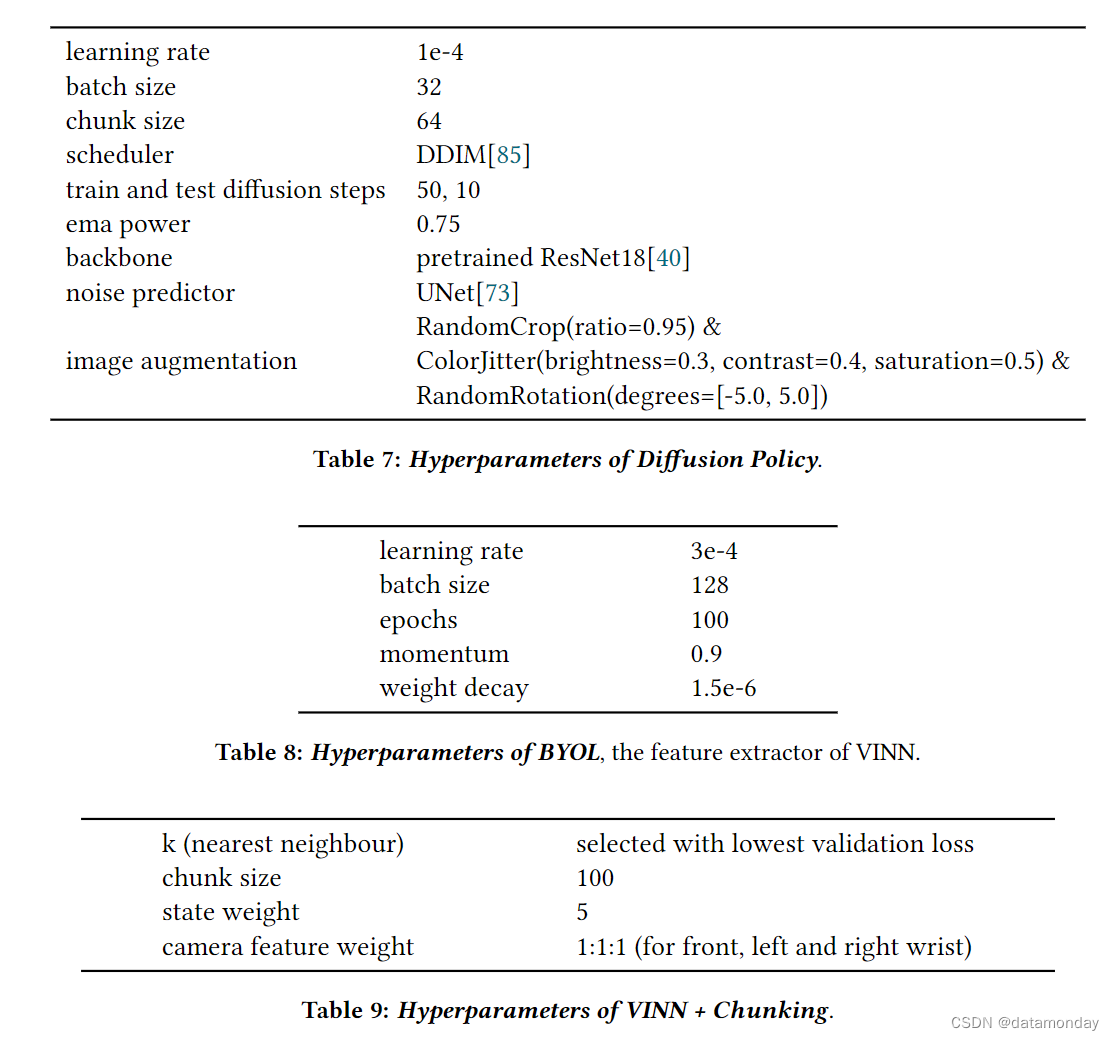
我们仔细调整了基线,并在 Table 5, 6, 7, 8, 9 中列出了基线和联合训练的超参数。
A.4. Open-Loop Replaying Errors

图 8 显示了重放 300 步(6 秒)演示结束时末端执行器误差的分布情况。该演示包含一个半径约为 1 米的 180 度转弯。在轨迹结束时,右臂会伸向桌上的一张纸,并轻轻敲击。然后在纸上标出敲击位置。红叉表示最初的敲击位置,红点表示同一轨迹的 20 次重放。我们观察到在重放基本速度曲线时存在明显误差,这是由于地面接触和低水平控制器的随机性造成的。具体来说,所有重放点都偏向左侧约 10 厘米,并沿着一条约 20 厘米的线分布。我们发现,我们的策略能够在没有明确定位(如 SLAM)的情况下纠正这种误差。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!