计算机网络:网络层上(数据平面)
文章目录
前言
网络层分两部分讲解,本篇文章讲解数据平面的内容:路由器组成、IP协议(IPV4、IPV6)、通用转发和SDN。
一、概述
网络层服务:
- 在发送主机和接收主机对之间传送段(segment)
- 在发送端将段封装到数据报中
- 在接收端,将段上交给传输层实体
- 网络层协议存在于每一个主机和路由器
- 路由器检查每一个经过它的IP数据报的头部
网络层功能:
- 转发(数据平面):将分组从路由器的输入接口转发到合适的输出接口
- 路由(控制平面):使用路由算法来决定分组从发送主机到目标接收主机的路径
- 路由选择算法
- 路由选择协议
- 旅行的类比:
- 转发:通过单个路口的过程
- 路由:从源到目的的路由路径规划过程
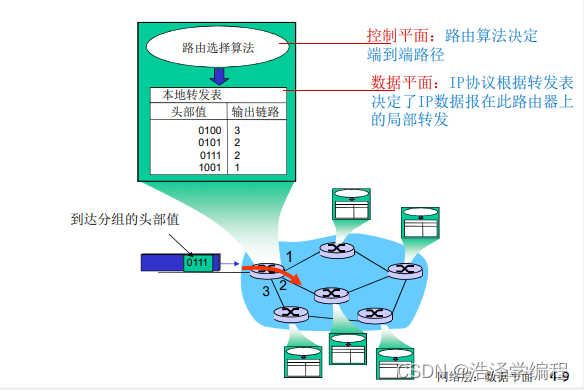
数据平面
- 本地,每个路由器功能
- 决定从路由器输入端口到达的分组如何转发到输出端口
- 转发功能:
- 传统方式:
- 基于目标地址 + 转发表
- SDN方式:
- 基于多个字段 + 交流
控制平面
- 网络范围内的逻辑
- 决定数据报如何在路由器之间路由,决定数据报如何在路由器之间路由,决定数据报从源到目标主机之间的端到端路径
- 2个控制平面方法:
- 传统的路由算法:
- 在路由器中被实现
- 在每一个路由器中的单独路由器算法元件,在控制平面进行交互
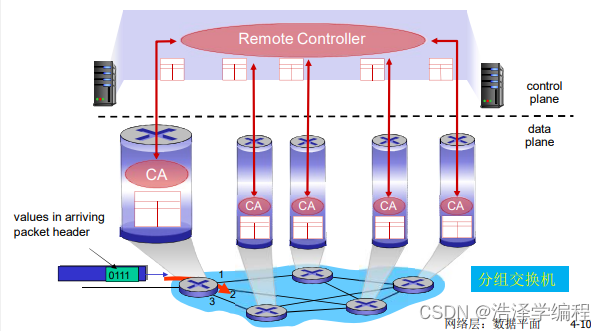
- software-defined networking(SDN):
- 在远程的服务器中实现
- 一个不同的(通常是远程的)控制器与本地控制代理(CAs)交互
1.网络服务模型
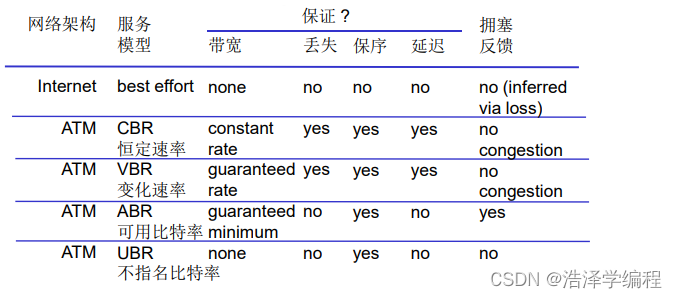
Q:从发送方主机到接收方主机传输数据报的“通道”,网络提供什么样的服务模型?
- 对于单个数据报的服务:
- 可靠传送
- 延迟保证,如:少于40ms的延迟
- 这就是提供的服务模型
- 对于数据报流的服务:
- 保序数据报传送
- 保证流的最小带宽
- 分组之间的延迟差
- 这就是提供的服务模型
2.连接建立
- 在某些网络架构中是第三个重要的功能
- ATM, frame relay,×.25
- 在分组传输之前,在两个主机之间,在通过一些路由器所构成的路径上建立一个网络层连接
- 涉及到路由器
- 网络层和传输层连接服务区别:
- 网络层:在2个主机之间,涉及到路径上的一些路由器
- 传输层:在2个进程之间,很可能只体现在端系统上(TCP连接)
二、路由器组成
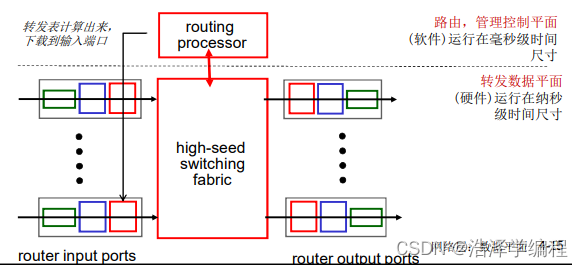
路由器结构概况
高层面(非常简化的)通用路由器体系架构
- 路由:运行路由选择算法/协议(RIP, OSPF, BGP)生成路由表
- 转发:从输入到输出链路交换数据报-根据路由表进行分组的转发
输入端口的功能
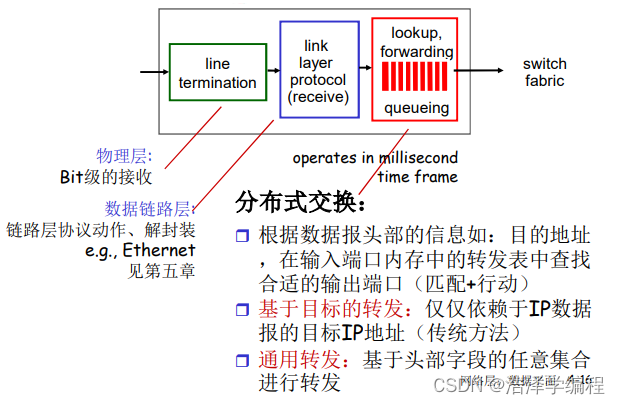
基于目标的转发:
- 最长前缀匹配
- 当给定目标地址查找转发表时,采用最长地址前缀匹配的自标地址表项
- 最长前缀匹配:在路由器中经常采用TCAMs(ternary content addressable memories)硬件来完成
- 内容可寻址:将地址交给TCAM,它可以在一个时钟周期内检索出地址,不管表空间有多大
- Cisco Catalyst系列路由器:在TCAM中可以存储多达约为1百万条路由表项

输入端口的缓存(上面图片的queueing):
- 当交换机构的速率小于输入端口的汇聚速率时→在输入端口可能要排队
- 排队延迟以及由于输入缓存溢出造成丢失!
- Head-of-the-Line (HOL) blocking:排在队头的数据报阻止了队列中其他数据报向前移动
交换结构
- 将分组从输入缓冲区传输到合适的输出端口
- 交换速率:分组可以按照该速率从输入传输到输出
- 运行速度经常是输入/输出链路速率的若干倍
- N个输入端口:交换机构的交换速度是输入线路速度的N倍比较理想,才不会成为瓶颈
- 3种典型的交换机构
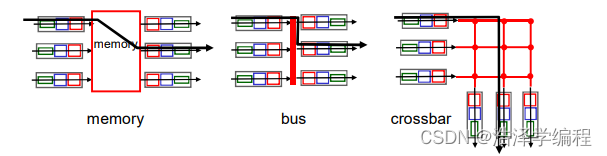
memory交换结构(通过内存交换):
第一代路由器:
- 在CPU直接控制下的交换,采用传统的计算机
- 分组被拷贝到系统内存,CPU从分组的头部提取出目标地址,查找转发表,找到对应的输出端口,拷贝到输出端口
- 转发速率被内存的带宽限制(数据报通过BUS两遍,如下图)
- 一次只能转发一个分组
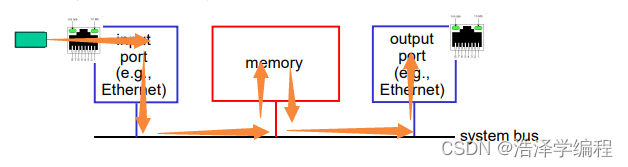
bus交换结构(通过总线交换):
- 数据报通过共享总线,从输入端口转发到输出端口
- 总线竞争:交换速度受限于总线带宽
- 1次处理一个分组
- 1 Gbps bus, Cisco 1900;32Gbps bus, Cisco 5600;对于接入或企业级路由器,速度足够((但不适合区域或骨干网络)
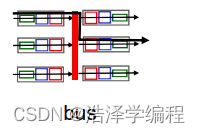
crossbar交换结构(通过互联网络交换):
- 同时并发转发多个分组,克服总线带宽限制
- Banyan(榕树)网络,crossbar(纵横)和其它的互联网络被开发,将多个处理器连接成多处理器
- 当分组从端口A到达,转给端口Y;控制器短接相应的两个总线
- 高级设计:将数据报分片为固定长度的信元,通过交换网络交换
- Cisco12000:以60Gbps的交换速率通过互联网络
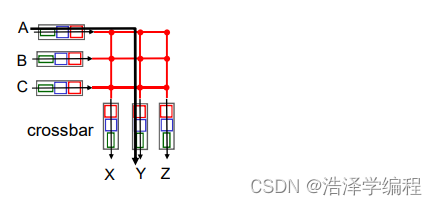
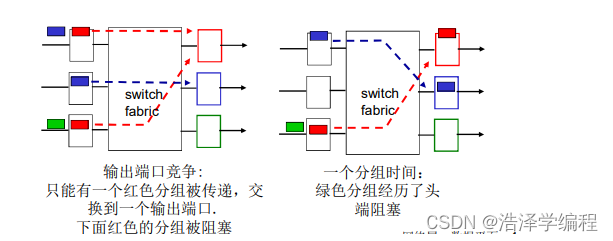
输出端口
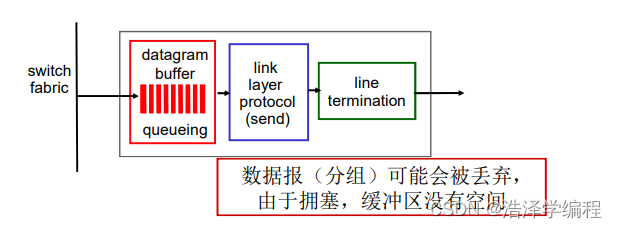
- 当数据报从交换机构的到达速度比传输速率快就需要输出端口缓存
- 由调度规则选择排队的数据报进行传输
输出端口排队
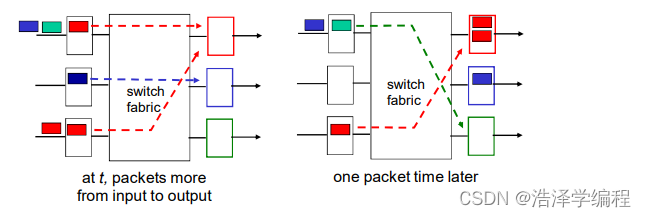
- 假设交换速率Rswitch是Rine的N倍(N:输入端口的数量)
- 当多个输入端口同时向输出端口发送时,缓冲该分组(当通过交换网络到达的速率超过输出速率则缓存)
- 排队带来延迟,由于输出端口缓存溢出则丢弃数据报!
调度机制
- 调度:选择下一个要通过链路传输的分组(先来先服务)
- FIFO (first in first out) schedulin:按照分组到来的次序发送
- 丢弃策略∶如果分组到达一个满的队列,哪个分组将会被抛弃?
- tail drop:丢弃刚到达的分组
- priority:根据优先权丢失/移除分组
- random:随机地丢弃/移除
- 丢弃策略∶如果分组到达一个满的队列,哪个分组将会被抛弃?
调度策略:优先权
优先权调度:发送最高优先权的分组
- 多类,不同类别有不同的优先权
- 类别可能依赖于标记或者其他的头部字段, e.g.IPsource/ dest,portnumbers,ds,etc.
- 先传高优先级的队列中的分组,除非没有(只要有高优先级先传它,传完高优先级的再传低的)
- 高(低)优先权中的分组传输次序:FIFO
调度策略:其他的
Round Robin (RR) scheduling:
- 多类
- 循环扫描不同类型的队列,发送完一类的一个分组,再发送下一个类的一个分组,循环所有类(假设分组有红蓝绿三种颜色,先把其中一个红的传完,再把其中一个蓝的传完,最后传其中一个绿的分组,然后周而复始)
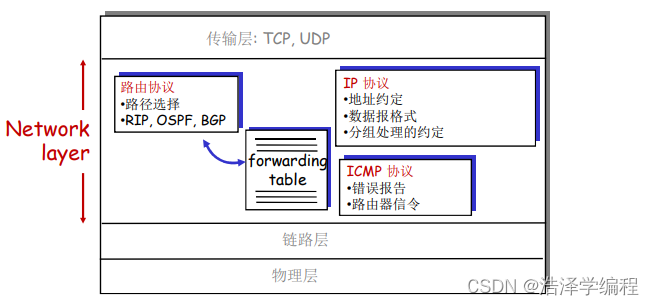
三、IP(Internet Protocol)
主机、路由器中的网络层功能:
IP数据报格式
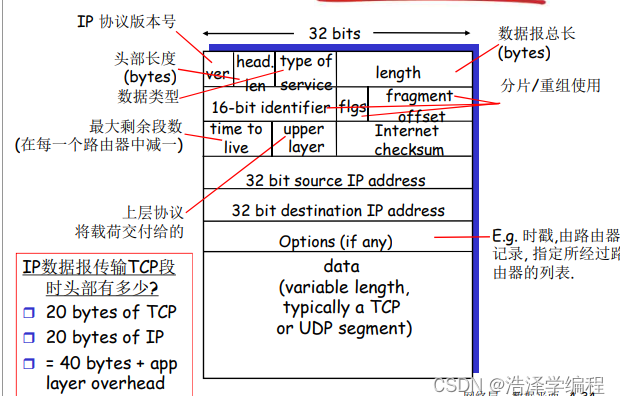

- 首部长度。因为一个IPv4 数据报可包含一些可变数量的选项(这些选项包括在IPv4 数据报首部中),故需要用这4比特来确定IP数据报中数据部分实际从哪里开始。大多数P数据报不包含选项,所以一般的IP数据报具有20字节的首部。
- 服务类型。服务类型(TOS)比特包含在IPv4首部中,以便使不同类型的P数据报(例如,一些特别要求低时延、高吞吐量或可靠性的数据报)能相互区别开来。
- 数据报长度。这是IP数据报的总长度(首部加上数据),以字节计。因为该字段长为16比特,所以P数据报的理论最大长度为65535字节。然而,数据报很少有超过1500字节的。
- 寿命。寿命(Time-To-Live,TTL)字段用来确保数据报不会永远(如由于长时间的路由选择环路)在网络中循环。每当数据报由一台路由器处理时,该字段的值减1。若TTL字段减为0.则该数据报必须丢弃。
- 标识、标志、片偏移。这三个字段与所谓P分片有关,这是一个我们将很快要深入考虑的一个问题。有趣的是,新版本的IP(即IPv6)不允许在路由器上对分组分片。
- 协议。该字段仅在一个IP数据报到达其最终目的地才会有用
- 首部检验和。首部检验和用于帮助路由器检测收到的IP数据报中的比特错误。
- 数据(有效载荷)。我们来看看最后的也是最重要的字段,这是数据报存在的首要理由!在大多数情况下,IP数据报中的数据字段包含要交付给目的地的运输层报文段(TCP或UDP)。然而,该数据字段也可承载其他类型的数据,如ICMP报文
注意:一个IP数据报有总长为20字节的首部(假设无选项)。如果数据报承载一个TCP报文段,则每个(无分片的) 数据报共承载了总长40字节的首部(20字节的P首部加上20字节的TCP首部)以及应用层报文。
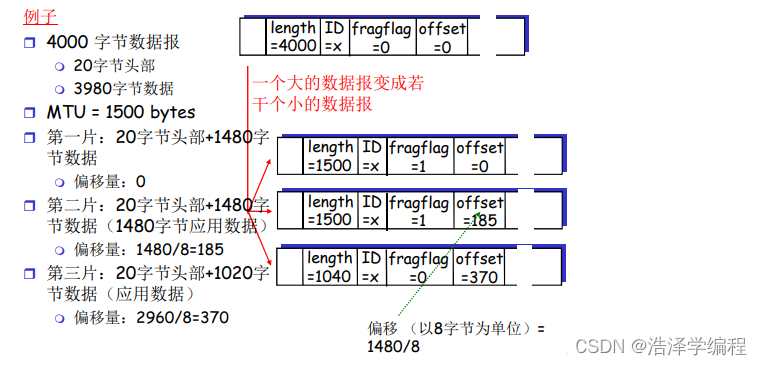
IP分片和重组
- 网络链路有MTU(最大传输单元)-链路层帧所携带的最大数据长度
- 不同的链路类型
- 不同的MTU
- 大的IP数据报在网络上被分片(“fragmented”)
- 一个数据报被分割成若干个小的数据报
- 相同的ID
- 不同的偏移量
- 最后一个分片标记为0
- “重组”只在最终的目标主机进行
- IP头部的信息被用于标识,排序相关分片
- 一个数据报被分割成若干个小的数据报
IPV4
IP编址
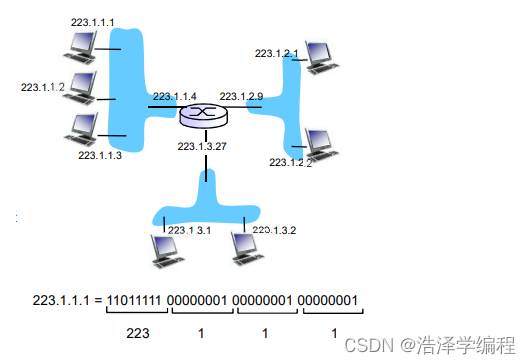
- IP地址:32位标示,对主机或者路由器的接口编址
- 接口:主机/路由器和物理链路的连接处
- 路由器通常拥有多个接口
- 主机也有可能有多个接口
- IP地址和每一个接口关联
- 一个IP地址和一个接口相关联
子网
IP地址:
- 子网部分(高位bits)
- 主机部分(地位bits)
什么是子网(subnet) ?
- 一个子网内的节点(主机或者路由器)它们的IP地址的高位部分相同,这些节点构成的网络的一部分叫做子网
- 无需路由器介入,子网内各主机可以在物理上相互直接到达
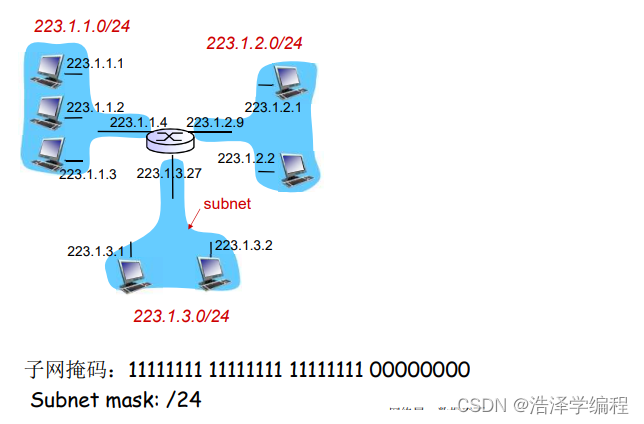
方法:
- 要判断一个子网,将每一个接口从主机或者路由器上分开,构成了一个个网络的孤岛
- 每一个孤岛(网络)都是一个都可以被称之为subnet
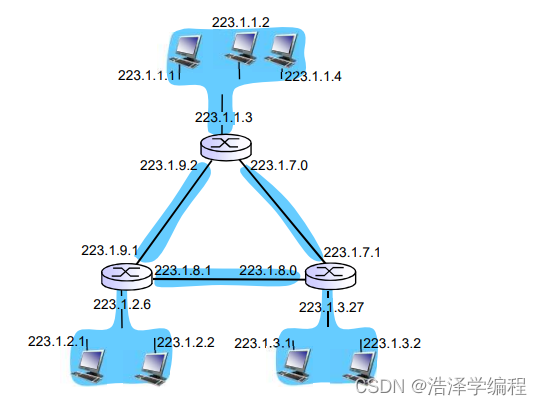
如下:6个子网
IP地址分类
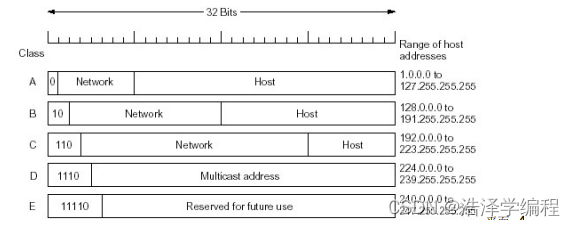
- Class A: 126(2的7次方 - 2) networks , 16 million hosts
- Class B: 16382(2的14次方 - 2)networks ,64 K hosts
- Class C: 2 million(2的21次方) networks ,254 host
- Class D: multicast
- Class E: reserved for future
A类B类C类都是单播地址
特殊IP地址
一些约定:
- 子网部分:全为O—本网络
- 主机部分:全为O—本主机
- 主机部分:全为1–广播地址,这个网络的所有主机
特殊IP地址:
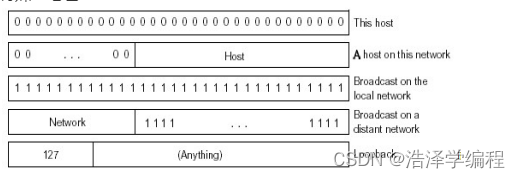
127.x.x.x:回路(/测试)地址
内网(专用)IP地址
- 专用地:地址空间的一部份供专用地址使用
- 永远不会被当做公用地址来分配,不会与公用地址重复
- 只在局部网络中有意义,区分不同的设备
- 路由器不对目标地址是专用地址的分组进行转发
- 专用地址范围
- Class A 10.0.0.0-10.255,255.255 MASK 255.0.0.0
- Class B 172.16.0.0-172.31.255.255 MASK 255.255.0.0
- Class C 192.168.0.0-192.168.255.255 MASK 255.255.255.0
IP编址:CIDR
CIDR: Classless InterDomain Routing(无类域间路由)
- 32比特的IP地址被划分为两部分
- 地址格式: 点分十进制数形式a.b.c.d/x,其中x指示的是第一部分中的比特数(地址中子网号的长度)
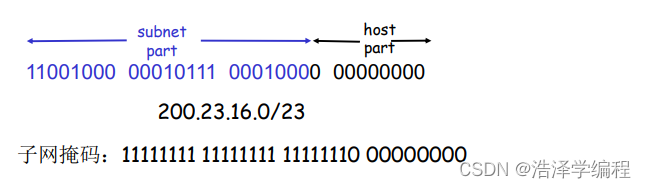
子网掩码(subnet mask)
- 32bits ,0 or 1 in each bit
- 1:bit位置表示子网部分
- 0:bit位置表示主机部分
- 原始的A、B、C类网络的子网掩码分别是
- A:255.0.0.0: 11111111 00000000 00000000 00000000
- B:255.255.0.0:11111111 11111111 00000000 00000000
- C: 255.255.255.0:11111111 11111111 11111111 00000000
- CIDR下的子网掩码例子:
- 11111111 11111111 11111100 00000000
- 另外的一种表示子网掩码的表达方式
- /#
- 例:/22:表示前面22个bit为子网部分
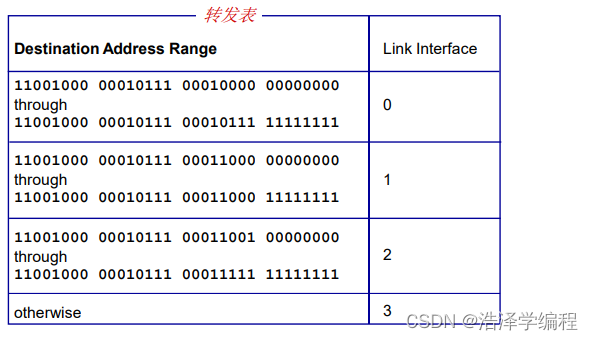
转发表和转发算法

- 获得IP数据报的目标地址
- 对于转发表中的每一个表项
- 如(IP Des addr)&(mask) == destination,则按照表项对应的接口转发该数据报
- 如果都没有找到,则使用默认表项转发数据报
如何获得一个IP地址
Q:主机如何获得一个IP地址?
- 系统管理员将地址配置在一个文件中
- Win+el:control-panel->network->configuration->tcp/ip->properties
- UNIX:/etc/rc.config
- DHCP:Dynamic Host Configuration Protocol:从服务器中动态获得一个IP地址
- “plug-and-play”
DHCP(Dynamic Host Confiquration Protocol):
- 目标:允许主机在加入网络的时候,动态地从服务器那里获得IP地址:
- 可以更新对主机在用IP地址的租用期——租期快到了
- 重新启动时,允许重新使用以前用过的IP地址
- 支持移动用户加入到该网络(短期在网)
- DHCP工作概况:
- 主机广播“DHCP discover”报文[ 可选 ]
- DHCP服务器用“DHCP offer”提供报文响应[ 可选 ]
- 主机请求IP地址:发送“DHCP request”报文
- DHCP服务器发送地址:“DHCP ack”报文
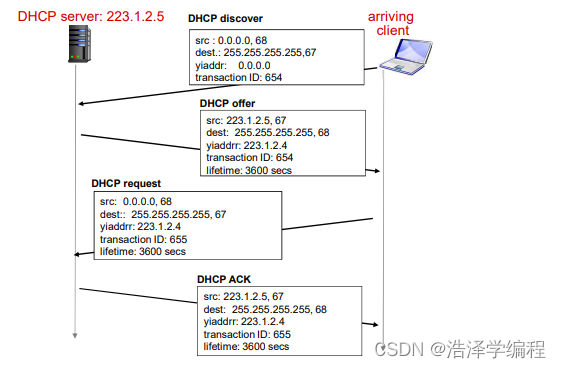
通俗的说:主机上线联网的时候先吼一嗓子——有人吗?(discover)然后在线的服务器(可能不止一个回复的)说我在(offer),主机知道有人在,就选择一个服务器请求获取一个IP地址(request),然后被选择的服务器收到请求就给主机一个IP地址(ACK)
- DHCP返回:
- IP地址
- 第一跳路由器的IP地址(默认网关)
- DNS服务器的域名和IP地址
- 子网掩码(指示地址部分的网络号和主机号)
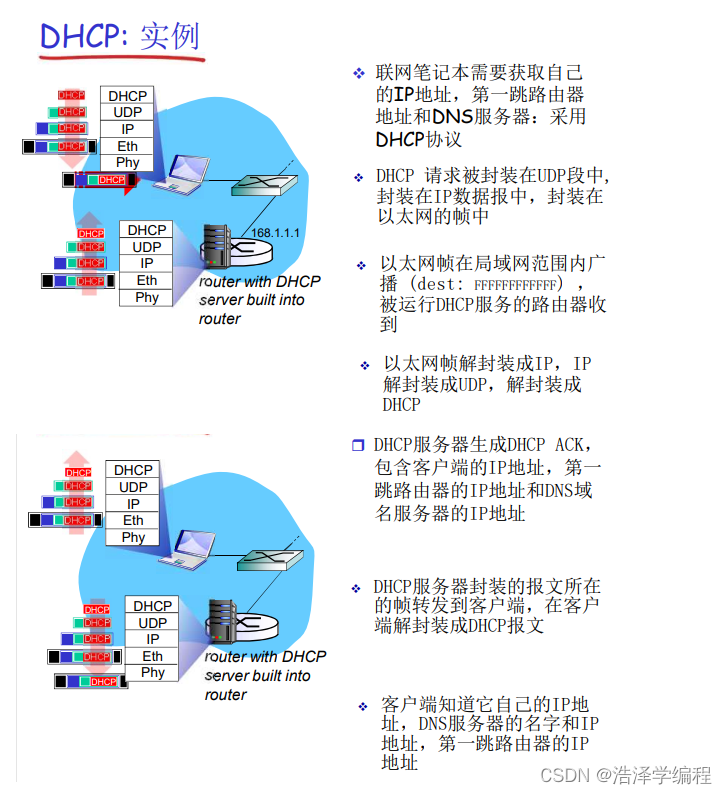
Q:如何获得一个网络的子网部分?
A:从ISP获得地址块中分配一个小地址块
Q:一个ISP如何获得一个地址块?
A:ICANN:Internet Corporation for Assigned Names and Numbers
- 分配地址
- 管理DNS
- 分配域名,解决冲突
形式为a.b.c.d/x的地址的x最高比特构成了P地址的网络部分,并且经常被称为该地址的前缀(prefix)(或网络前缀)。一个组织通常被分配一块连续的地址,即具有相同前缀的一段地址。在这种情况下,该组织内部的设备的IP地址将共享共同的前缀。
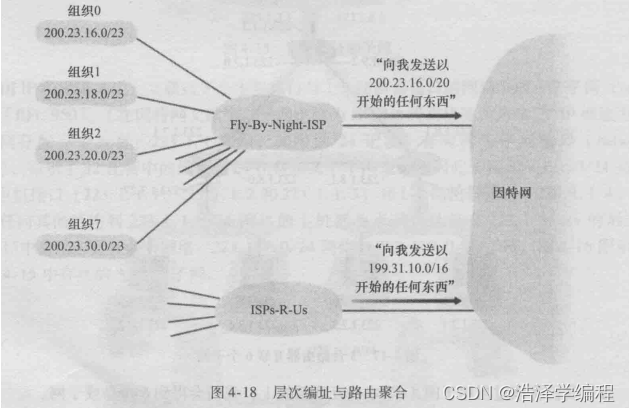
一个ISP将8个组织连接到因特网的例子(这里的地址例子是点分十进制式表示,所以被点分成了四块(200 23 x y),而IP地址总共32位,所以一块是8位,所以下面说的前20位一样,肉眼你可能看不出来,化成二进制再看):
假设该ISP(我们称之为Fly-By-Night-ISP)向外界通告,它应该发送所有地址的前20比特与200.23.16.0/20相符的数据报。外界的其他部分不需要知道在地址块200.23.16.0/20内实际上还存在8个其他组织,每个组织有自己的子网。这种使用单个网络前缀通告多个网络的能力通常称为地址聚合(address aggregation),也称为路由聚合(route aggregation)或路由摘要( routesummarization)。
NAT(Network Address Translation,网络地址转换)
动机:本地网络只有一个有效IP地址
- 不需要从ISP分配一块地址,可用一个IP地址用于所有的(局域网)设备–省钱
- 可以在局域网改变设备的地址情况下而无须通知外界
- 可以改变ISP(地址变化)而不需要改变内部的设备地址
- 局域网内部的设备没有明确的地址,对外是不可见的–安全
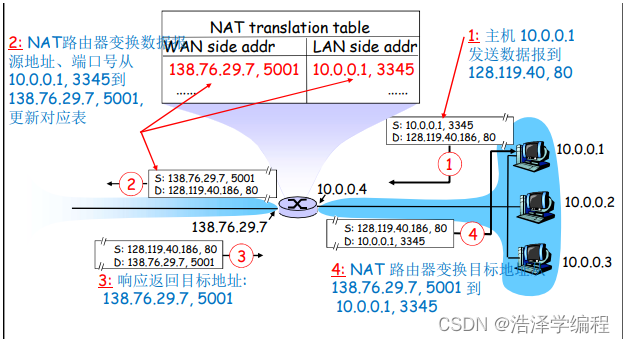
实现:NAT路由器必须:
- 外出数据包:替换源地址和端口号为NAT IP地址和新的端口号,目标IP和端口不变
…远端的C/S将会用NAP IP地址,新端口号作为目标地址 - 记住每个转换替换对(在NAT转换表中)
…源IP,端口 vs NAP IP,新端口 - 进入数据包:替换目标IP地址和端口号,采用存储在NAT表中的mapping表项,用(源IP,端口)
NAT:
- 16-bit端口字段:
- 6万多个同时连接,一个局域网!
- 对NAT是有争议的:
- 路由器只应该对第3层做信息处理,而这里对端口号(4层)作了处理
- 违反了end-to-end原则
- 端到端原则:复杂性放到网络边缘
- 无需借助中转和变换,就可以直接传送到目标主机
- NAT可能要被一些应用设计者考虑, 例如:2P applications
- 外网的机器无法主动连接到内网的机器上
- 端到端原则:复杂性放到网络边缘
- 地址短缺问题可以被IPv6解决
- NAT穿越:如果客户端需要连接在NAT后面的服务器,如何操作
NAT穿越问题:
- 客户端需要连接地址为10.0.0.1的服务器
- 服务器地址10.0.0.1 LAN本地地址(客户端不能够使用其作为目标地址)
- 整网只有一个外部可见地址:138.76.29.7
- 方案1:静态配置NAT:转发进来的对服务器特定端口连接请求
- (138.76.29.7, port 2500)总是转发到10.0.0.1 'port 25000
- 方案2: Universal Plug and Play(UPnP)Internet GatewayDevice (IGD)协议.允许NATted主机可以:
- 获知网络的公共IP地址(138.76.29.7)
- 列举存在的端口映射
- 增/删端口映射(在租用时间内),自动化静态NAT端口映射配置
- 方案3:中继(used in Skype)
- NAT后面的服务器建立和中继的连接
- 外部的客户端链接到中继
- 中继在2个连接之间桥接
IPV6
动机
- 初始动机:32-bit地址空间将会被很快用完
- 另外的动机:
- 头部格式改变帮助加速处理和转发
- TTL-1
- 头部checksum分片
- 头部格式改变帮助QoS
- 头部格式改变帮助加速处理和转发
IPv6数据报格式
- 固定的40字节头部
- 数据报传输过程中,不允许分片
IPV6头部(Cont)
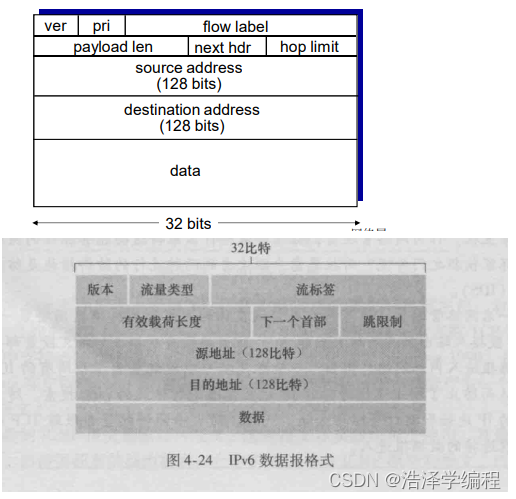
- Priority:标示流中数据报的优先级
- Flow Label:标示数据报在一个"flow."("flow"的概念没有被严格的定义)
- 有效载荷长度。该16比特值作为一个无符号整数,给出了IPv6数据报中跟在定长的40字节数据报首部后面的字节数量。
- 下一个首部。该字段标识数据报中的内容(数据字段)需要交付给哪个协议(如TCP或UDP)。该字段使用与IPv4首部中协议字段相同的值。
- 跳限制。转发数据报的每台路由器将对该字段的内容减1。如果跳限制计数到达0时,则该数据报将被丢弃。
和IPV4的其他变化
- Checksum:被移除掉,降低在每一段中的处理速度
- Options:允许,但是在头部之外,被“NextHeader”字段标示
- ICMPv6: ICMP的新版本
- 附加了报文类型, e.g.“Packet Too Big”
- 多播组管理功能
从IPV4到IPV6的平移
- 不是所有的路由器都能够同时升级的
- 没有一个标记日“flag days”
- 在IPv4和IPv6路由器混合时,网络如何运转?
- 隧道:在IPv4路由器之间传输的IPv4数据报中携带IPv6数据报(解封装后得到IPV6)
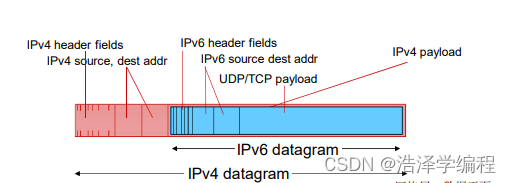
隧道(Tunneling)
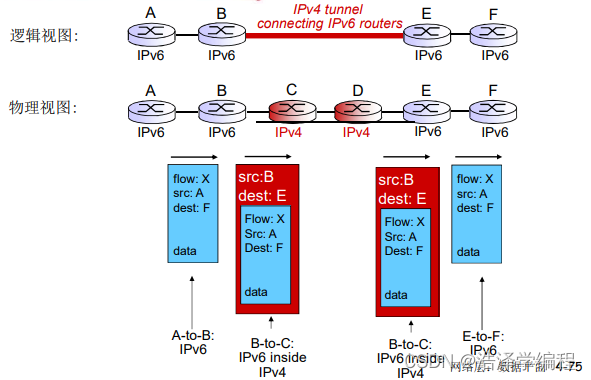
假设两个岛上的人都用的IPV6,其他地方都用IPV4,把这些用IPV4的地方比作海洋,一片海洋上只有两个岛屿。这时岛屿内部之间的交流是没问题的(都用的IPV6),但是两个岛屿之间和岛屿怎么交流,中间是海洋(用的是IPV4),这时就可以用隧道来解决,IPV4就充当隧道连接岛屿,从一个岛屿的数据报封装在IPV4的数据报中,通过隧道后,来到另一个岛屿,岛屿将其解封装,拿出IPV6数据报。
IPV6应用
- Google:8%的客户通过IPv6访问谷歌服务NIST:全美国1/3的政府域支持IPv6估计还需要很长时间进行部署
- 20年以上!
- 看看过去20年来应用层面的变化: www, Facebook,streaming media,Skype,…
四、通用转发和SDN
数量众多、功能各异的中间盒
- 路由器的网络层功能:
- IP转发:对于到来的分组按照路由表决定如何转发,数据平面
- 路由:决定路径,计算路由表;处在控制平面
- 还有其他种类繁多网络设备(中间盒):
- 交换机;防火墙;NAT;IDS;负载均衡设备
- 未来:不断增加的需求和相应的网络设备
- 需要不同的设备去实现不同的网络功能
- 每台设备集成了控制平面和数据平面的功能
- 控制平面分布式地实现了各种控制平面功能
- 升级和部署网络设备非常困难
网络设备控制平面的实现方式特点
- 互联网网络设备:传统方式都是通过分布式,每台设备的方法来实现数据平面和控制平面功能
- 垂直集成:每台路由器或其他网络设备,包括:
- 1)硬件、在私有的操作系统;
- 2)互联网标准协议(IP, RIP, IS-IS, OSPF, BGP)的私有实现从上到下都由一个厂商提供(代价大、被设备上“绑架”“)
- 每个设备都实现了数据平面和控制平面的事情
- 控制平面的功能是分布式实现的
- 设备基本上只能(分布式升级困难)按照固定方式工作,控制逻辑固化。不同的网络功能需要不同的“middleboxes”:防火墙、负载均衡设备、NAT’ boxes, …
- (数据+控制平面)集成>>(控制逻辑)分布->固化
- 代价大;升级困难;管理困难等
传统方式存在的问题:
- 垂直集成>>昂贵、不便于创新的生态
- 分布式、固化设备功能==网络设备种类繁多
- 无法改变路由等工作逻辑,无法实现流量工程等高级特性
- 配置错误影响全网运行;升级和维护会涉及到全网设备︰管理困难
- 要增加新的网络功能,需要设计、实现以及部署新的特定设备,设备种类繁多
- ~2005:开始重新思考网络控制平面的处理方式
- 集中:远程的控制器集中实现控制逻辑
- 远程:数据平面和控制平面的分离
解决:SDN(逻辑上集中的控制平面)
一个不同的(通常是远程)控制器和CA交互,控制器决定分组转发的逻辑(可编程),CA所在设备执行逻辑。
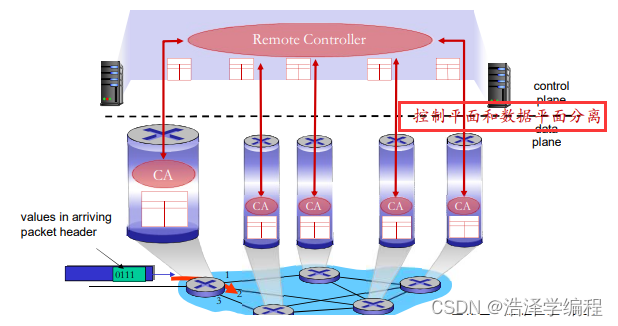
SDN主要思路
- 网络设备数据平面和控制平面分离
- 数据平面——分组交换机
- 将路由器、交换机和目前大多数网络设备的功能进一步抽象成:按照流表(由控制平面设置的控制逻辑)进行PDU(帧、分组)的动作(包括转发、丢弃、拷贝、泛洪、阻塞)
- 统一化设备功能:SDN交换机(分组交换机),执行控制逻辑
- 控制平面:控制器+网络应用
- 分离、集中
- 计算和下发控制逻辑:流表
SDN控制平面和数据平面分离的优势
- 水平集成控制平面的开放实现(而非私有实现),创造出好的产业生态,促进发展)
- 分组交换机、控制器和各种控制逻辑网络应用app可由不同厂商生产,专业化,引入竞争形成良好生态
- 集中式实现控制逻辑,网络管理容易:
- 集中式控制器了解网络状况,编程简单,传统方式困难
- 避免路由器的误配置
- 基于流表的匹配+行动的工作方式允许“可编程的”分组交换机
- 实现流量工程等高级特性
- 在此框架下实现各种新型(未来)的网络设备
SDN特点
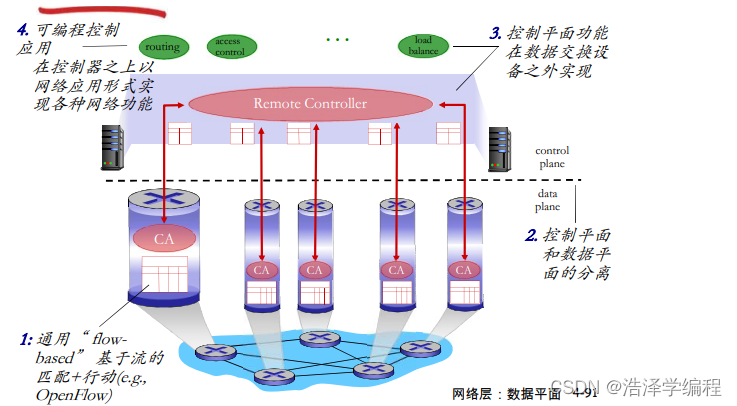
SDN架构:数据平面交换机
数据平面交换机
- 快速,简单,商业化交换设备采用硬件实现通用转发功能
- 流表被控制器计算和安装
- 基于南向API(例如OpenFlow) ,SDN控制器访问基于流的交换机
- 定义了哪些可以被控制哪些不能
- 也定义了和控制器的协议(例如:OpenFlow)
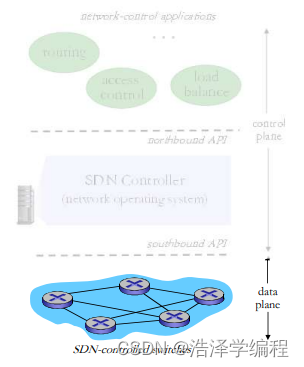
SDN架构:SDN控制器
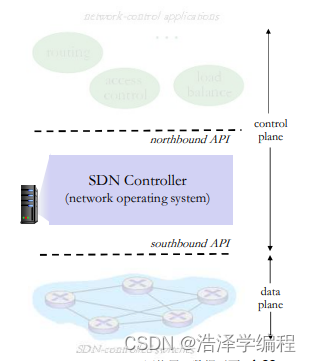
SDN控制器(网络OS)
- 维护网络状态信息
- 通过上面的北向API和网络控制应用交互
- 通过下面的南向API和网络交换机交互
- 逻辑上集中,但是在实现上通常由于性能、可扩展性、容错性以及鲁棒性采用分布式方法
SDN架构:控制应用
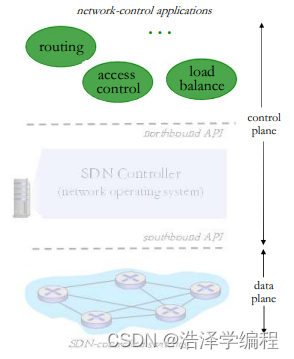
网络控制应用
- 控制的大脑:采用下层提供的服务(SDN控制器提供的API),实现网络功能
- 路由器交换机
- 接入控制防火墙负载均衡
- 其他功能
- 非绑定:可以被第三方提供,与控制器厂商以通常上不同,与分组交换机厂商也可以不同
通用转发和SDN
每个路由器包含一个流表(被逻辑上集中的控制器计算和分发)
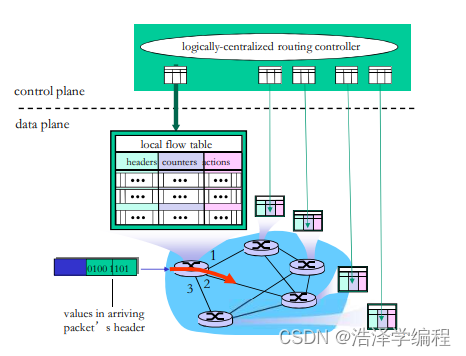
OpenFlow数据平面抽象
- 流:由分组(帧)头部字段所定义
- 通用转发:简单的分组处理规则
- 模式Pattern:将分组头部字段和流表进行匹配
- 行动Action:对于匹配上的分组,可以是丢弃、转发、修改、将匹配的分组发送给控制器
- 优先权Priority:几个模式匹配了,优先采用哪个,消除歧义
- 计数器Counters:#bytes 以及 #packets

OpenFlow:流表的表项结构
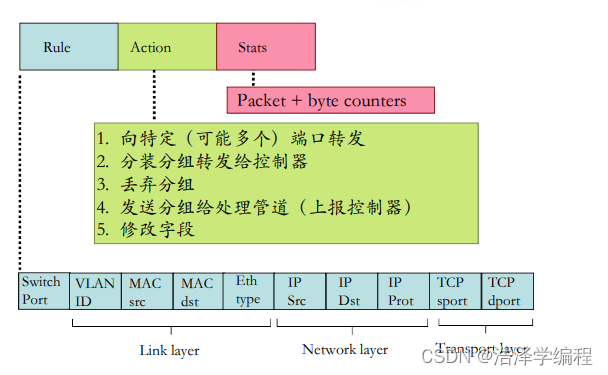
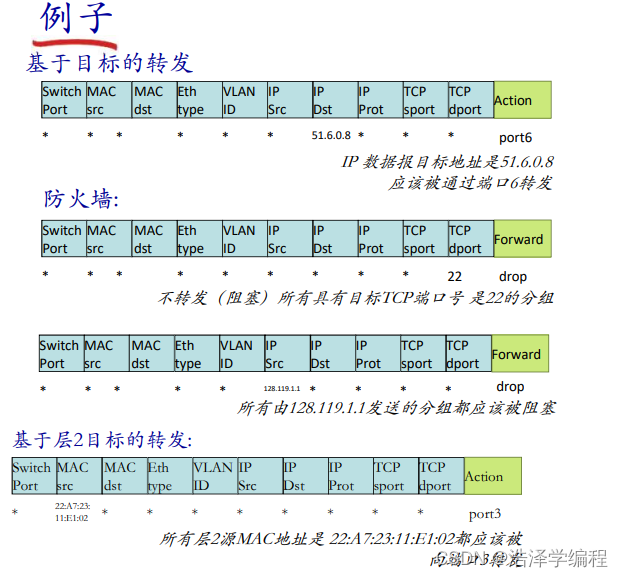
OpenFlow抽象

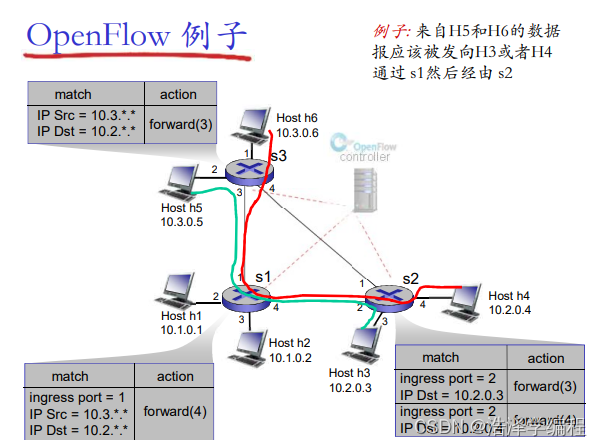
总结
以上就是计算机网络网络层数据平面内容讲解,控制平面内容请看后续文章,即将发布。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!