(2023,提示分布学习,重参数化,正交损失)DreamDistribution:文本到图像扩散模型的提示分布学习
DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models
公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
Text-to-Image (T2I) 扩散模型的普及使得能够从文本描述生成高质量的图像。然而,使用参考视觉属性生成多样化的定制图像仍然具有挑战性。本工作的重点是在更抽象的概念或类别级别上个性化 T2I 扩散模型,从一组参考图像中保留共同点,同时创建具有足够变化的新实例。我们引入了一种解决方案,允许预训练的 T2I 扩散模型学习一组软提示,通过从学到的分布中采样提示,实现生成新颖图像的能力。这些提示提供了文本引导的编辑功能,并在控制变化和混合多个分布方面提供了额外的灵活性。我们还展示了学到的提示分布对其他任务的适应性,例如文本到 3D。最后,通过包括自动评估和人工评估在内的定量分析,我们展示了我们方法的有效性。
项目网站:https://briannlongzhao.github.io/DreamDistribution
1. 方法
给定一组带有一些共同视觉属性的图像(例如相同的类别,相似的风格),我们的目标是在文本特征空间中捕捉视觉的共性和变化,并通过一个提示分布对其进行建模,该分布与自然语言兼容。参考图像之间的共同点可能很难用自然语言提示来表达。因此,我们可以从分布中采样提示,以引导 T2I 扩散模型生成多样的未见图像,同时遵循共同特征分布。学习到的提示的固有特性与自然语言说明和其他预训练的文本引导生成模型兼容。
1.1 文本到图像扩散
文本到图像扩散模型是一类生成模型,通过逐渐去噪从高斯分布中抽样的噪声来学习图像或图像潜在分布。具体来说,给定自然语言文本提示,一个标记器,然后是一个文本嵌入层,将输入文本映射到嵌入向量序列 p。文本编码器将文本嵌入转换为用于调节生成过程的文本特征 c = E(p)。从 N(0, I) 中抽样初始噪声 ?,并且去噪模型 ?_θ 预测添加到图像潜在 x 的有噪版本的噪声。去噪模型 ?_θ 使用如下目标进行优化:
![]()
其中 x 是从学习的自动编码器获得的地面实况图像或图像潜在图像,x_t 是在时间步骤 t 的 x 的嘈杂版本,而 ? ~ N(0, I)。
1.2 提示调整
我们提出的方法基于提示调整(prompt tuning)的概念,旨在学习目标任务上的软连续提示,广泛用于微调自然语言处理模型[11, 21, 22, 24, 25]。具体来说,对于一个以自然语言提示作为输入的预训练模型,我们可以制定一个具有连续可学习标记嵌入的提示 P = [PREFIX] V [SUFFIX] ∈ R^(L×d),其中 [PREFIX] 和 [SUFFIX] 是自然语言前缀和后缀的词嵌入(如果需要的话),L 表示提示长度或标记总数,d 表示词嵌入的维度。V = [v]_1 . . . [v]_M ∈ R^(M×d) 表示具有与词嵌入相同维度的 M 个可学习标记嵌入向量的序列。
在微调过程中,预训练生成模型的参数保持不变,只有可学习的标记嵌入 V 通过直接优化更新,利用相应的损失函数反向传播到生成器 ?_θ 和文本编码器 E。形式上,提示调整旨在找到优化的嵌入向量 V* = arg max_V P(Y | P,X),其中 X 和 Y 分别是输入数据和输出标签。
先前的研究已经显示了在图像分类任务中采用提示调整技术对视觉语言模型的有效性 [18, 58, 59]。Gal 等人 [7] 采用了类似的提示调整方法,实现了个性化生成。然而,这种方法的局限性在于它只能个性化一个特定的概念,例如一个特定的狗,因为它使用了一个固定的标记嵌入来进行概念编码。
1.3 学习提示分布
我们的目标是建模在参考图像集中呈现的更一般的共性和变化,并生成视觉上对齐的各种新实例的图像,因此我们提出为参考图像建模一个可学习的提示分布。受 Lu 等人 [26] 的启发,该论文提出了估计图像分类任务的提示分布,我们提议利用扩散模型,在一系列 M 个标记嵌入上建模可学习的提示分布,以捕捉 T2I 生成任务中视觉属性的分布。
我们的方法建立在稳定扩散 [37] 的基础上,其中使用预训练的 CLIP [33] 文本编码器获取提示的文本特征。由于 CLIP 的对比训练目标,具有相似语义含义的文本特征在余弦相似性上具有较高的相似性,因此在 CLIP 特征空间中彼此靠近 [33]。Lu 等人 [26] 还表明,对于描述相同类别图像的文本提示,预训练的 CLIP 文本编码器输出的 CLIP 文本特征 c 相邻。因此,对于描述相同类别或具有共享属性的图像,建模描述 c 的高斯分布是自然的。为此,我们不是在训练过程中保留一个可学习的软提示进行优化,而是保持一组 K 个可学习的提示
![]()
对应于一组相似的参考图像。我们的目标是优化一组可学习的标记嵌入
![]()
通过 K 个可学习的提示,我们可以在文本编码器空间估计均值和标准差,
![]()
![]()
其中 d_E 是文本编码器空间的特征维度。
应用于 T2I 扩散模型的训练目标,方程 (1) 变为:
![]()
其中 ?c ~ N( μ_c,σ^2_c) ,而 ? ~ N(0, I) 是添加到图像或图像潜在的采样高斯噪声。然而,从分布中采样 ?c 在优化过程中不可微,因此我们应用类似于 VAE [19] 中使用的重参数化技巧。形式上,由于 ?c ~ N( μ_c,σ^2_c),我们可以将优化目标 Eq. (2) 重写为:?
![]()
其中 ω ~ N (0, I) 具有与 μ_c 和 σ_c 相同的维度。由于精确计算 L(P_K) 是不可行的,我们使用蒙特卡洛(Monte Carlo)方法对 ω 进行 S 次采样以近似期望值进行优化:?
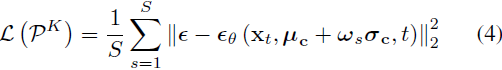
为了避免多个提示特征收敛到相同的向量,导致不具代表性的低方差分布的情况,我们应用了类似的 [26] 中提出的正交损失,对余弦相似性进行惩罚,并鼓励每一对提示之间的正交性:?
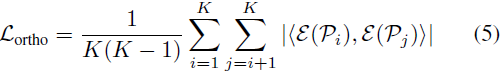
其中 ?·, ·? 是一对向量之间的余弦相似度。因此,总损失为:?
![]()
其中 λ 是一个超参数。
2. 结果

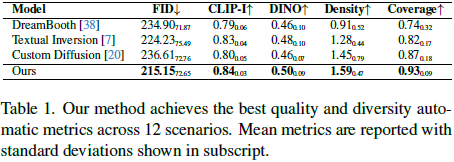

定性、定量以及人工评估显示,DreamDistribution 表现良好。
3. 局限性?
尽管我们的方法能够生成多样的新颖分布内图像,但它确实具有一定的局限性。具体来说,当训练图像的数量有限且非常多样时,我们的方法可能难以捕捉视觉特征。此外,高斯分布的假设可能在训练图像和文本编码器的潜在空间中过于限制。在未来,我们希望能够找到一种更强健的方法,从少量且高度多样的图像中学习分布,采用更准确的假设和弹性的分布形式。
S. 总结
S.1 主要贡献
梦常常以创新的方式重新组合现实的元素,带来新的视角和想法。
基于此,本文提出?DreamDistribution,允许预训练的 T2I 扩散模型学习一组软提示(捕捉文本特征空间中视觉的共性和变化),通过从学到的提示分布中采样,实现在保留参考图像中共同点的同时,创建具有足够变化的新实例。
S.2 方法
提示分布学习:
- 制定一个具有连续可学习标记嵌入的提示 P = [PREFIX] V [SUFFIX],其中 [PREFIX] 和 [SUFFIX] 是自然语言前缀和后缀的词嵌入,V 表示可学习标记嵌入向量的序列。
- 根据 V* = arg max_V P(Y | P, X) 优化一组可学习的标记嵌入,其中 X 和 Y 分别是输入数据和输出标签。
- 在文本编码器空间估计优化的嵌入的提示的均值 μ_c 和标准差 σ_c(建模提示分布)。
- 训练目标如等式 2 所示,其中 ?c ~ N( μ_c,σ^2_c)
![]()
重参数化:采样的提示在优化中不可微?,为解决这个问题,使用类似 VAE 的重参数化技巧,并使用蒙特卡罗法进行近似优化。
正交损失:为避免降低多样性,在文本编码器空间中,使用正交损失对提示嵌入的余弦相似性进行惩罚,鼓励每一对提示之间的正交性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!