【AIGC-图片生成视频系列-3】AI视频随心而动:MotionCtrl的相机运动控制和物体运动控制
最近,「单张图片生成视频」相关工作很多,但运动控制的准确性依旧是个挑战,包括相机运动的控制以及物体运动控制。
然,MotionCtrl?横空出世。
一. 项目简介
MotionCtrl——一个相机运动控制、物体运动控制的视频工具,由国内ARC实验室、腾讯PCG、香港大学、腾讯人工智能实验室、清华大学、 上海人工智能实验室、广东工业大学的团队成员共同研究发布。
代码开源。
项目及演示:MotionCtrl
论文:https://arxiv.org/pdf/2312.03641.pdf
GitHub - TencentARC/MotionCtrlGitHub:GitHub - TencentARC/MotionCtrl
在线演示:https://huggingface.co/spaces/TencentARC/MotionCtrl
二. 主要贡献
- MotionCtrl 提出一个用于视频生成的统一且灵活的运动控制方法,可以实现独立有效地管理生成视频中的相机运动和物体运动。
- MotionCtrl可以部署在LVDM?[1] /?VideoCrafter1?[2](LVDM的改进版本),AnimateDiff?[3]上以及SVD?[4]。
- MotionCtrl 能够指导视频生成模型在给定一系列相机姿势的情况下 创建具有复杂相机运动的视频。
- MotionCtrl 可以指导视频生成模型生成具有特定对象运动的视频,提供对象轨迹。
- 这些结果只需一个统一训练的模型即可生成。




三. 摘要
通常,视频中的运动主要包括由相机运动引起的相机运动和由物体运动引起的物体运动。准确控制相机和物体运动对于视频生成至关重要。
然而,现有的工作要么主要关注一种运动类型,要么没有明确区分两者,限制了它们的控制能力和多样性。
因此,MotionCtrl提出一种用于视频生成的统一且灵活的运动控制方法,旨在有效且独立地控制相机和物体运动。
MotionCtrl的架构和训练策略经过精心设计,考虑到相机运动、物体运动和不完美训练数据的固有属性。
与之前的方法相比,MotionCtrl具有三个主要优点:
1)它可以有效且独立地控制相机运动和物体运动,从而实现更细粒度的运动控制,并促进两种运动的灵活多样的组合。
2)它的运动条件由相机位姿和轨迹决定,它们与外观无关,并且对生成视频中对象的外观或形状的影响最小。
3)它是一个相对通用的模型,经过训练后可以适应各种相机姿势和轨迹。进行了大量的定性和定量实验来证明 MotionCtrl 相对于现有方法的优越性。
四. 实现方法和管线

MotionCtrl 使用相机运动控制模块?(CMCM) 和物体运动控制模块?(OMCM) 扩展了 LVDM 的去噪 U-Net 结构。如图 (b) 所示,CMCM 将相机姿态序列RT与 LVDM 的时序transformer集成在一起。
具体方法是将RT附加到第二个自注意力模块的输入,并应用定制的轻量级全连接层来提取相机姿态特征以进行后续处理。OMCM 利用卷积层和下采样从Trajs中导出多尺度特征,这些特征在空间上合并到 LVDM 的卷积层中以指导对象运动。
进一步,给出一个文本提示,LVDM 从与prompt相对应的噪声中生成视频,并且生成视频的背景和物体运动反映了指定的相机姿势和轨迹。
五. 基于 LVDM [1] / VideoCrafter1 [2]的结果
值得注意的是,所有结果,包括相机运动、物体运动以及这两种运动的组合的结果,都是通过一个统一的训练模型获得的。
(A) 相机运动控制
(a) MotionCtrl 生成具有复杂相机运动的视频。
(b) MotionCtrl 使用8 种基本相机动作生成视频。

(c) MotionCtrl可以细粒度地调整生成视频的摄像机运动。

(B) 物体运动控制
MotionCtrl在给定单个或多个对象轨迹的情况下生成具有特定对象运动的视频。



(C) 相机+物体运动控制
MotionCtrl可以同时控制相机和物体的运动。
MotionCtrl 生成的视频中的摄像机或对象运动与参考视频或给定轨迹完全一致,同时保持自然的外观。

(D) 与VideoComposer的比较[5]


六. 基于 AnimateDiff [3]的结果
值得注意的是,所有的结果,包括相机运动和物体运动的结果,都是通过一个统一的训练模型获得的。
(A) 相机运动控制
(a) 有8 种基本相机运动的结果。

(b) 存在以不同速度放大和缩小的结果。

(b) 存在复杂相机运动的结果。
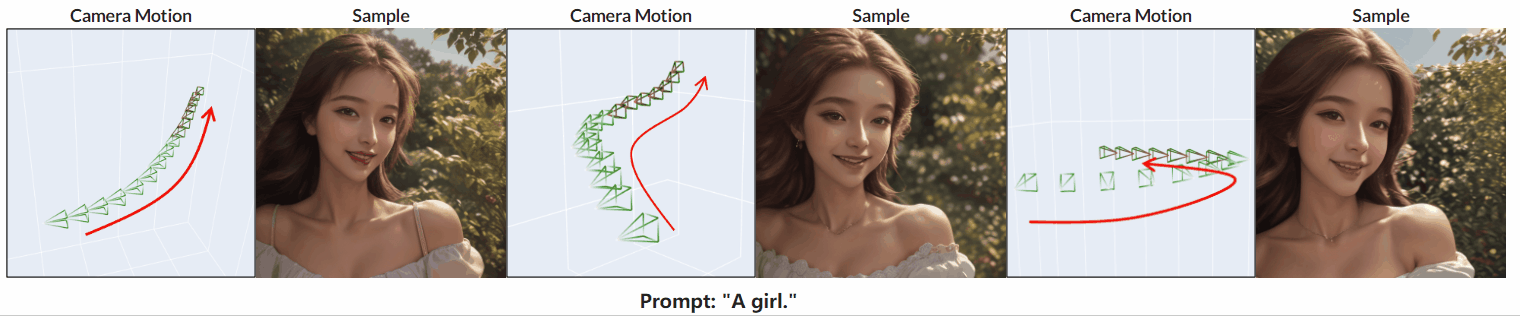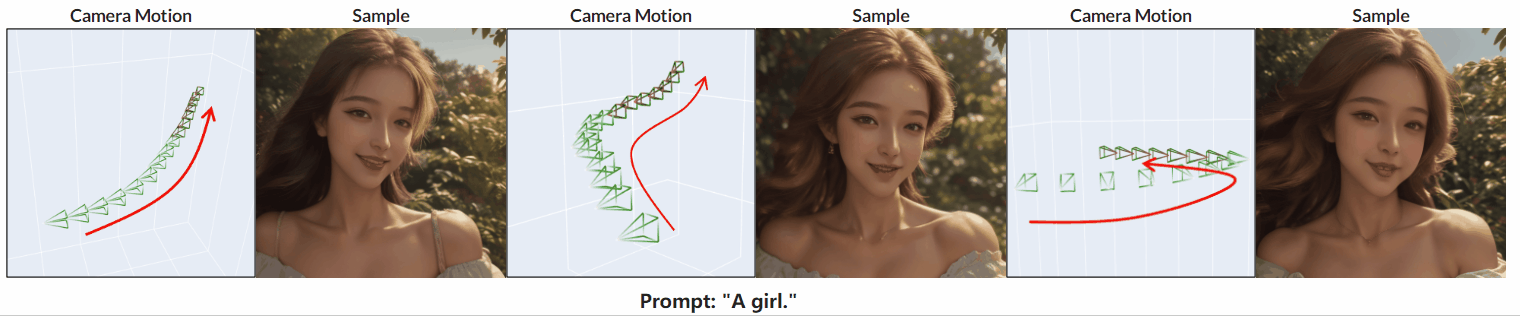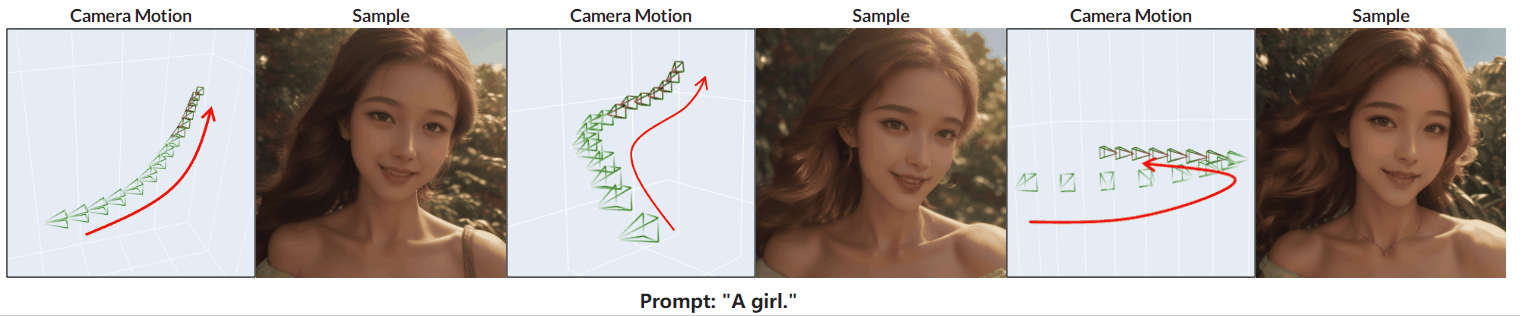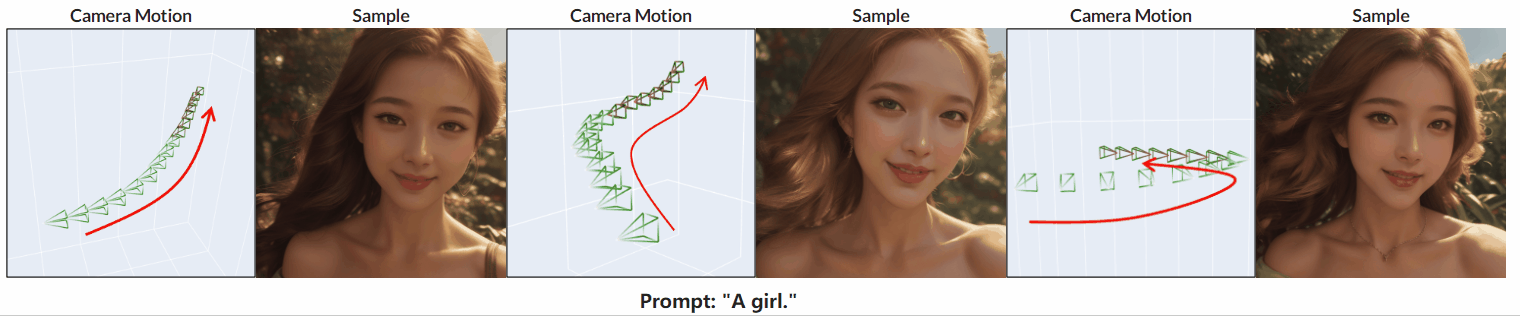
(B) 物体运动控制
有特定物体运动的结果。

参考
[1] Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:2211.13221, 2023.
[2] Chen H, Xia M, He Y, et al. Videocrafter1: Open diffusion models for high-quality video generation[J]. arXiv preprint arXiv:2310.19512, 2023.
[3] Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023.
[4] Blattmann A, Dockhorn T, Kulal S, et al. Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets[J]. arXiv preprint arXiv:2311.15127, 2023.
[5] Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. arXiv preprint arXiv:2306.02018, 2023.
欢迎加入AI杰克王的免费知识星球,海量干货等着你,一起探讨学习AIGC!
 移步公众号 「AI杰克王」,更多干货
移步公众号 「AI杰克王」,更多干货
喜欢的话就点个【赞】呗,您的鼓励和认可是我继续创作的动力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!