PyCharm连接远程服务器上Docker容器,使用远程服务器的python intercepter解释器和GPU资源 [本地调试深度学习代码]
概述
在编写常规深度学习代码时,总是需要使用服务器上的GPU资源,所以一般要写完代码,放到服务器,然后使用GPU运行。但是由于之前的习惯,总想本地调试一下或者本地直接跑测试结果,再放到服务器去跑。
网上查了一些文档,遇到了一系列问题,最终还是完美的解决了。整理一下分享出来希望对大家有用。
文档包括三个方面:
- 服务器Docker启动,在Docker中使用GPU资源
- Docker开启ssh登录
- PyCharm连接远程服务器Docker,使用python解释器和远程GPU
1. Docker中使用GPU
我这里使用的镜像是 registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.3.0-py38-torch1.11.0-tf1.15.5-1.6.1
这个影响不大。
为什么要使用Docker呢,因为这样能保证开发环境的一致性。
启动命令:
docker run -p 2017:22 --name="gpu-test" --gpus all -it -v /root/localpath:/workspace registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.3.0-py38-torch1.11.0-tf1.15.5-1.6.1 bash
-p 2017:22 : 映射了一个宿主机的2017端口到容器的22端口,为了之后连接容器
-v /root/localpath:/workspace : 加了映射容器的磁盘到宿主机上
这样启动后,容器中就可以看到所有的GPU资源
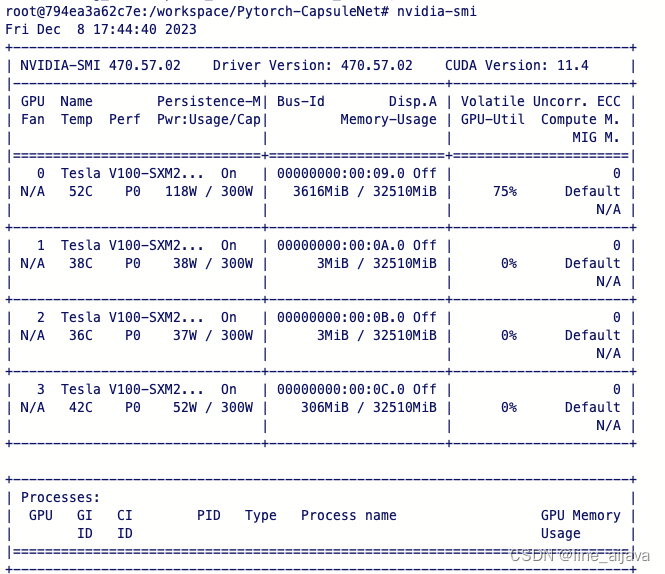
可以验证下是否可以使用gpu
import torch
print(f'\nAvailable cuda = {torch.cuda.is_available()}')
print(f'\nGPUs availables = {torch.cuda.device_count()}')
print(f'\nCurrent device = {torch.cuda.current_device()}')
print(f'\nCurrent Device location = {torch.cuda.device(0)}')
print(f'\nName of the device = {torch.cuda.get_device_name(0)}')
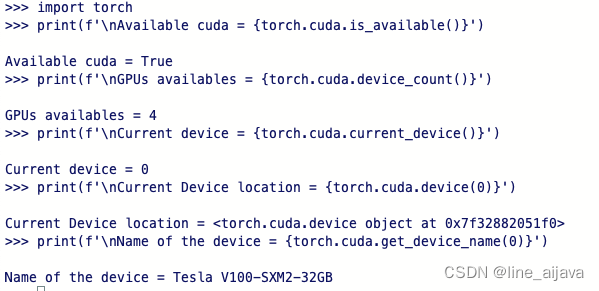
这里需要注意宿主机是有GPU驱动的,容器中有cuda等环境。
到这个阶段,就可以在容器中跑程序了,如果没有本地调试需求,可以把代码传到宿主机目录,在容器中可以直接运行。如图:

2. 开启Docker中ssh
因为后续需要PyCharm连接Docker容器,所以容器中需要现有ssh服务,并把22端口暴露出去,我们是映射到宿主机上一个端口上。
docker run -p 2017:22
在我提供的这个镜像上没有ssh,需要手动安装一下,如果有ssh就不需要装了。
安装脚本:
# 更新密码
passwd
# 更新源
apt-get -y update
# 安装sshserver
apt-get install openssh-server
apt-get install openssh-client
# 开启密码登录
vim /etc/ssh/sshd_config
在文件最后加上一行
PermitRootLogin yes #允许root用户使用ssh登录
# 重启ssh服务
/etc/init.d/ssh restart
# 尝试连接远程容器
ssh root@10.22.33.44 -p 2017
3. PyCharm中连接Docker中的Python解释器和GPU
有两个地方需要配置,但是可以一步配置完成。
我使用的PyCharm 2023.2.1 (Professional Editor)版本
使用远程解释器的操作步骤:
-
创建Interpreter
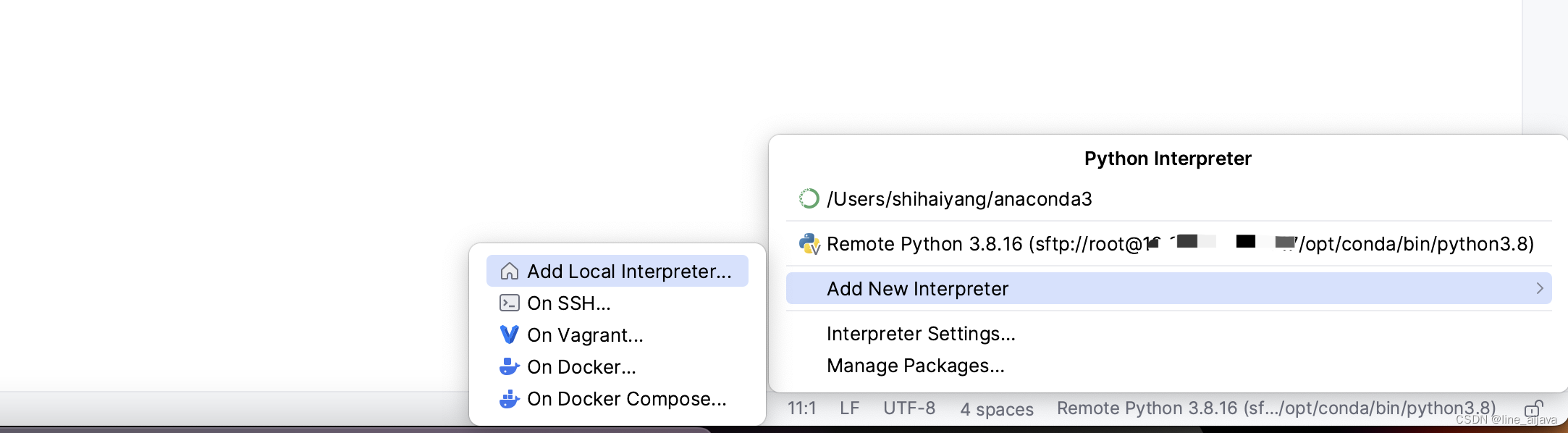
操作路径:Add New Interpreter --> On SSH -
填写远程服务器上Docker容器连接信息
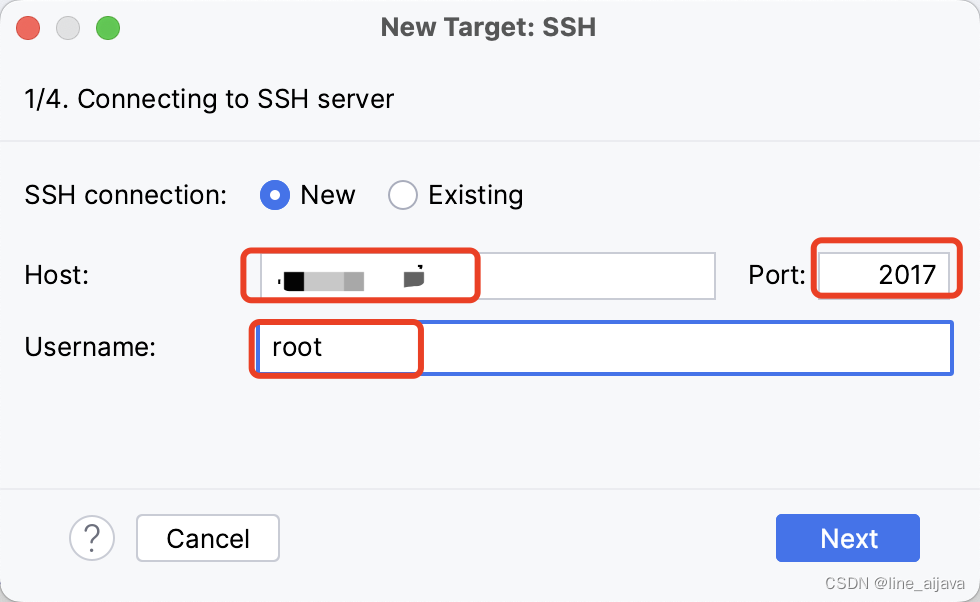
这里弹框需要填入远程信息,这里的IP是远程宿主机,端口是容器暴露的2017端口,2017会映射到容器内部22端口上,就可以通过2017连接到容器22. -
输入密码
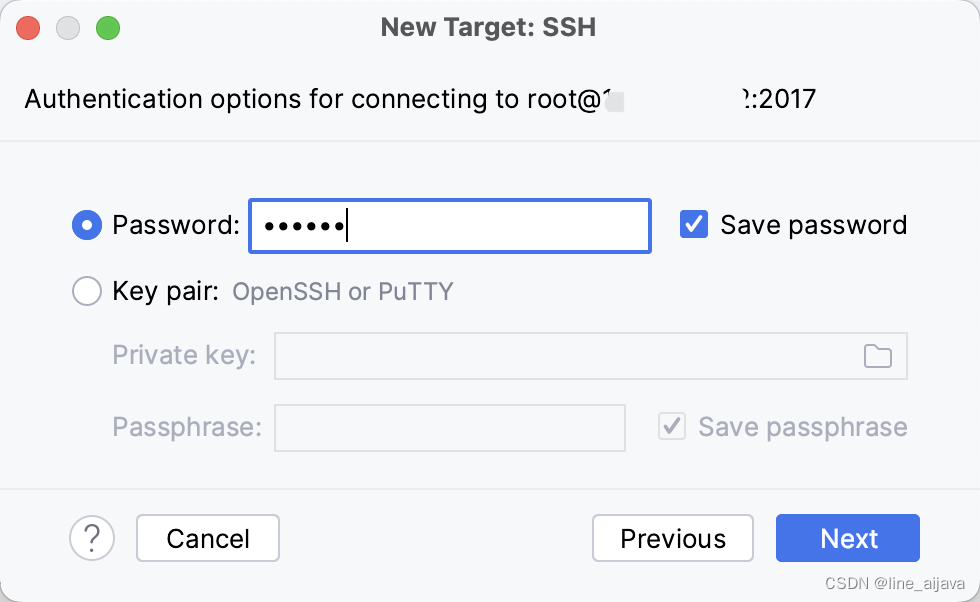
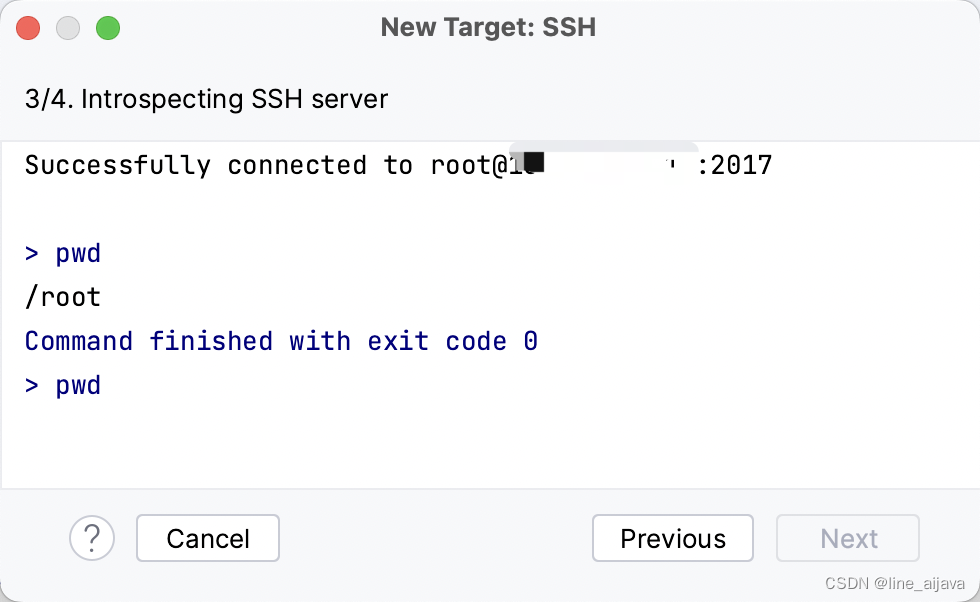
-
设置解释器地址
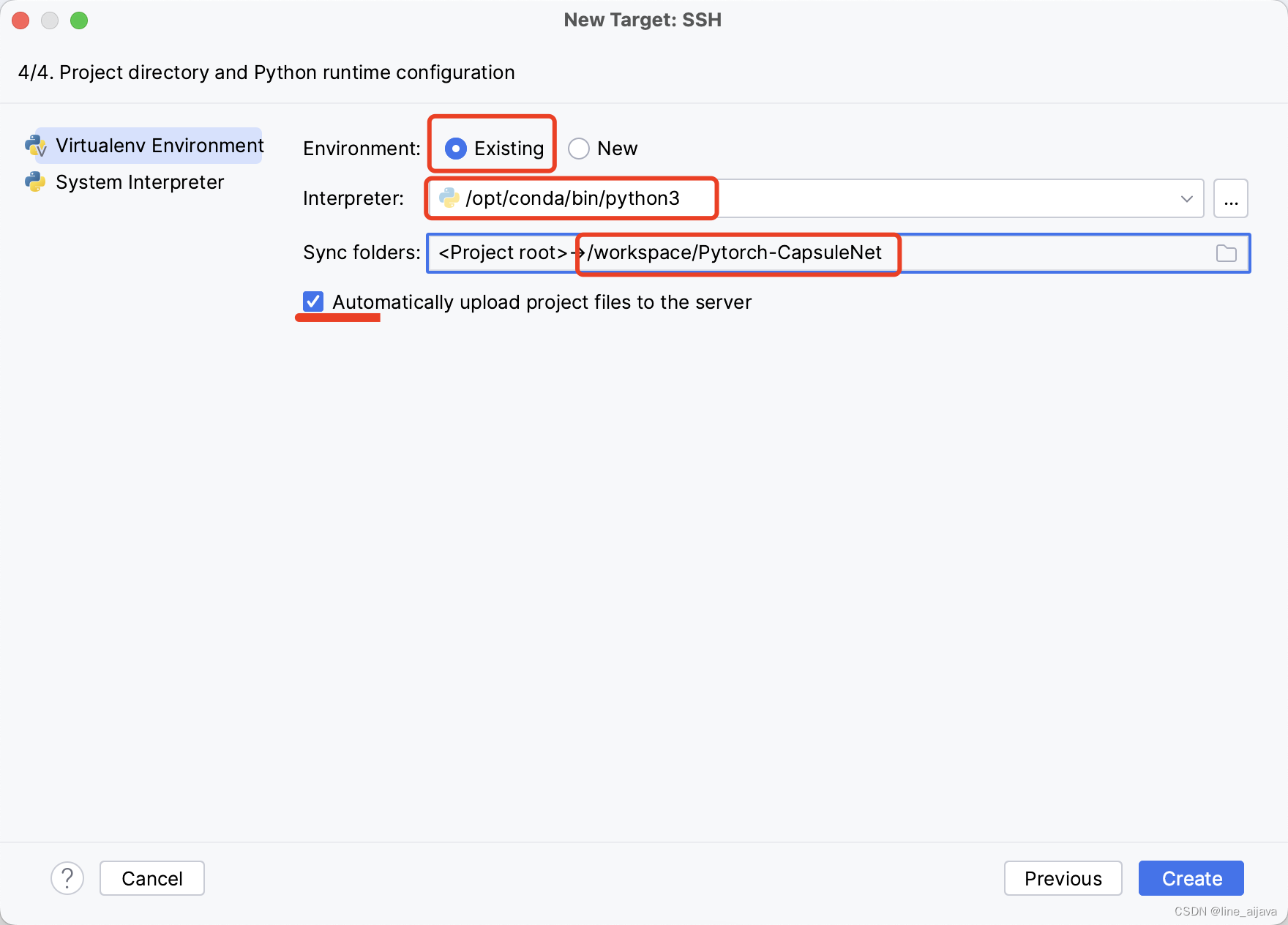
这一步需要特别注意。
第一Environment: 一定选择远程已存在的解释器,不要创建新的解释器。
第二Interpreter: 解释器地址,选择远程容器中的解释器地址,具体位置可以在远程中查询,查询方式:
进入python
import os
print(os.sys.executable) # 会输出解释器地址
# 我使用的镜像的解释器位置,所以我在这一步设置的这个地址
/opt/conda/bin/python
第三sync folders : 是选择把本地文件同步到远程容器的什么目录。这儿可以选择一个容器的挂载目录,防止容器重启,远程文件丢失,还需要重传。
最后自动上传可以勾选上,修改后会自动上传。
创建完成后,可以在interpreter中查看,依赖是否跟远程相同。
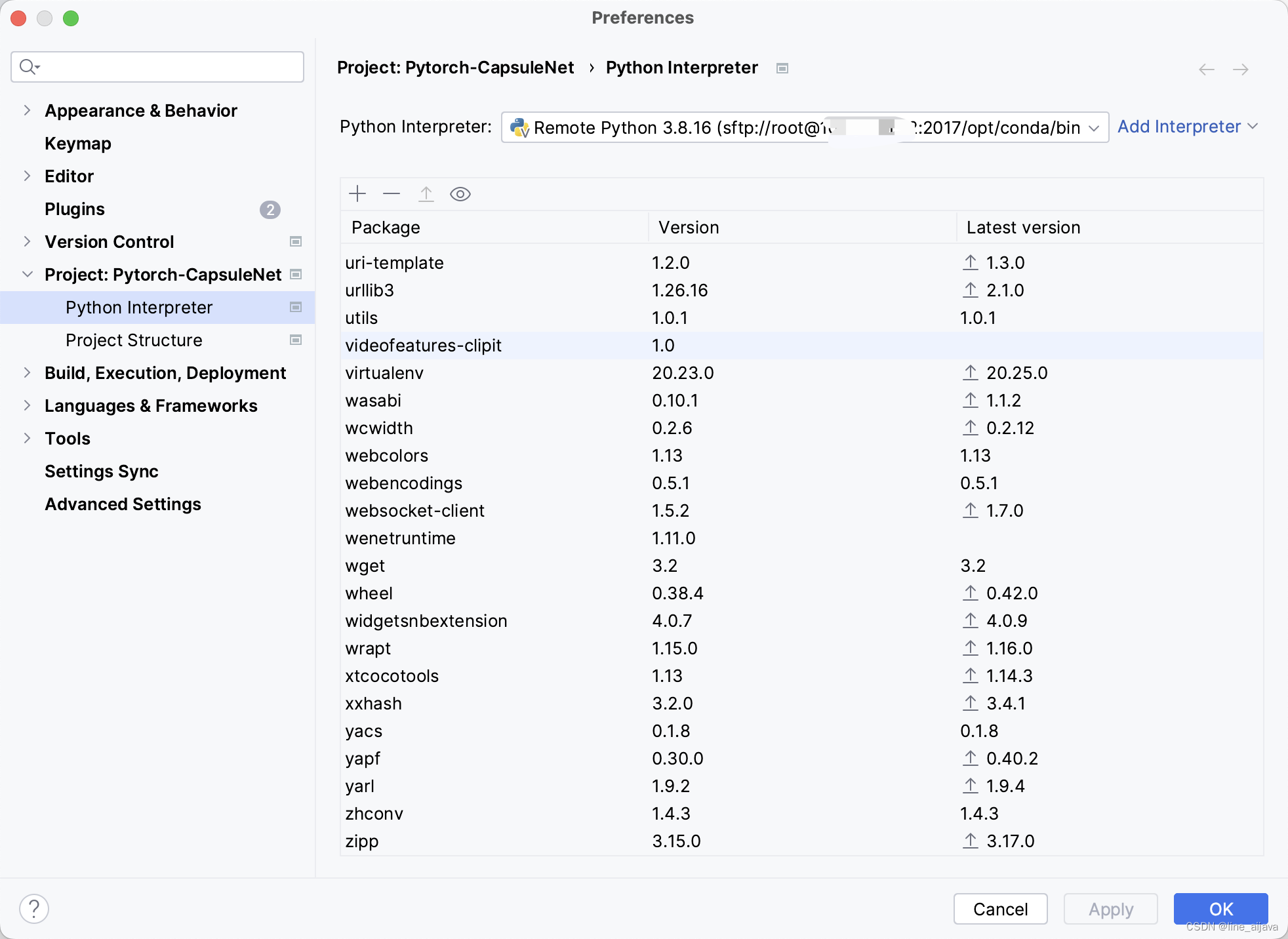
如果显示的远程pip list中依赖,即成功。
然后执行Run试试。
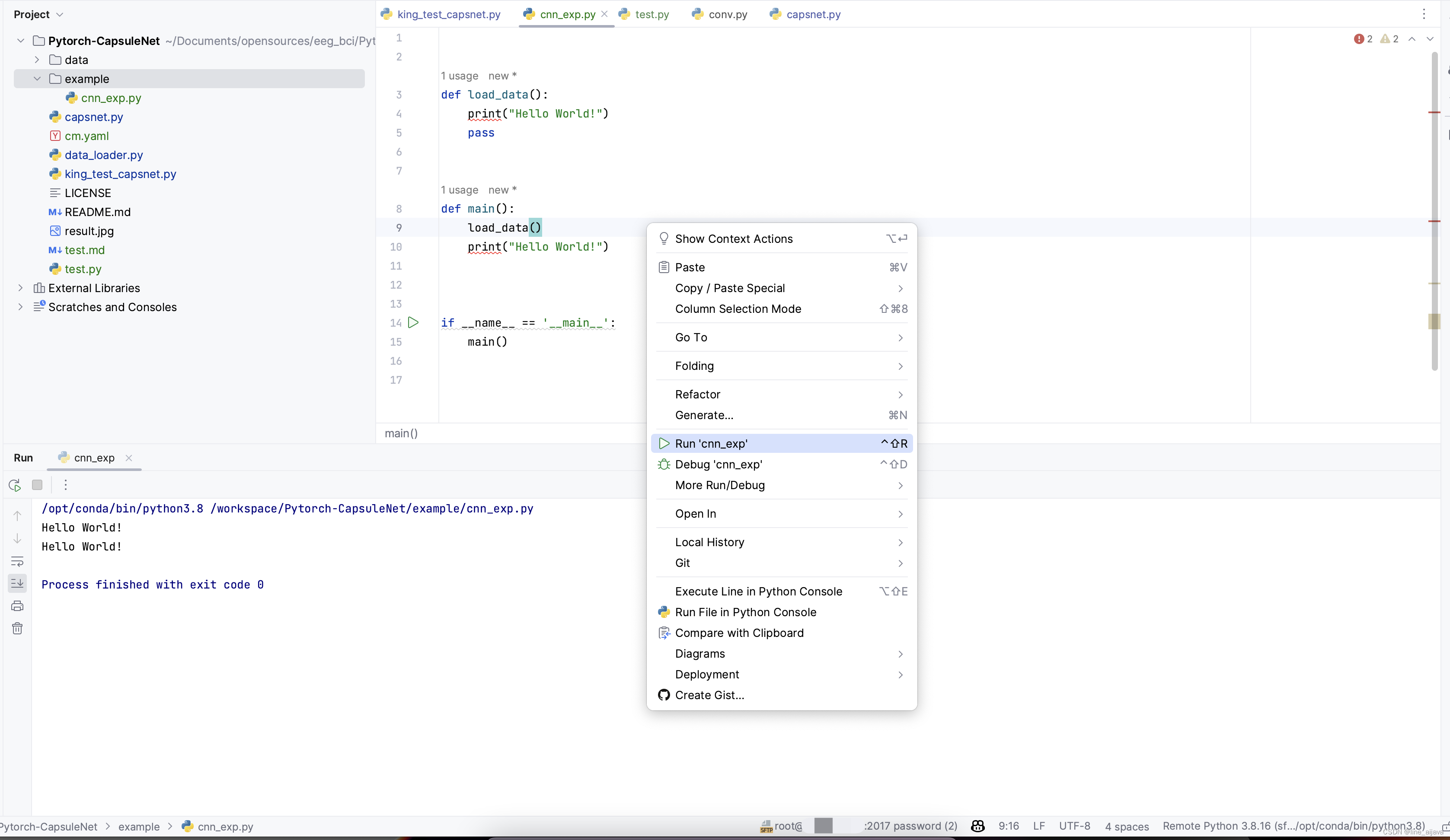
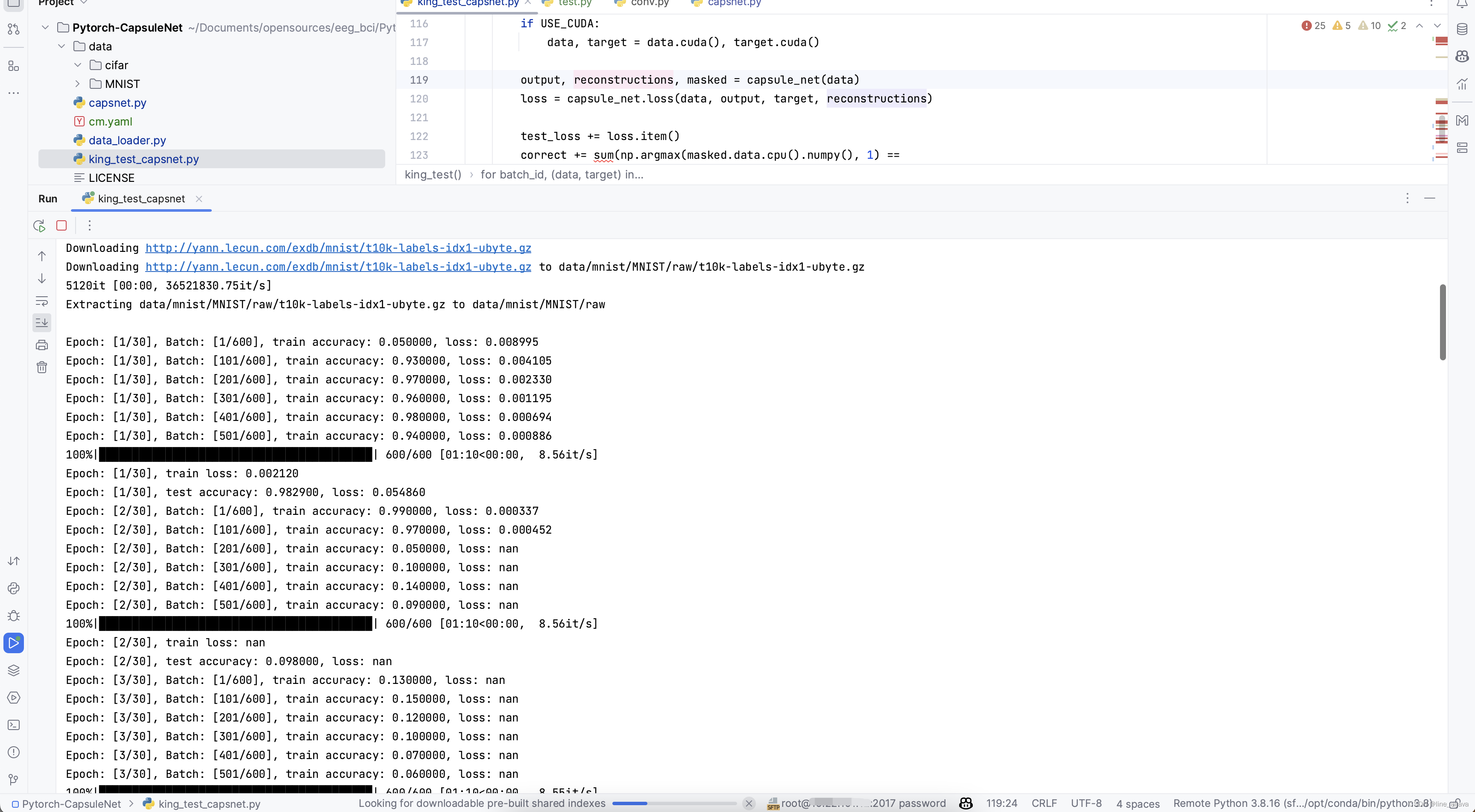
参考链接:https://zhuanlan.zhihu.com/p/605389180
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!