Hadoop Single Node Cluster的安装
Hadoop Single Node Cluster的安装
安装JDK
hadoop是基于java开发的,所以要先安装java环境
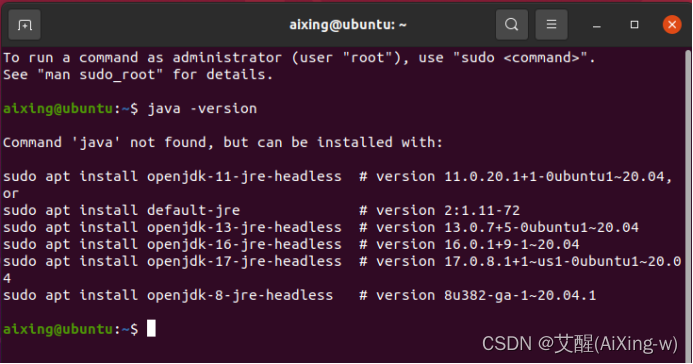
查看java -version
打开terminal执行命令java -version,如果显示如下图所示,说明没有安装java。
更新本地软件包
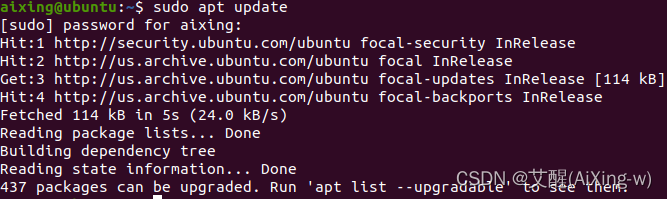
要安装Java 先更新一下本地软件包,使用如下命令:
sudo apt update
安装JDK
执行以下命令安装 OpenJDK:
sudo apt install default-jre
安装完成后,验证一下安装 JDK 的版本:
java -version

sudo apt-get install default-jdk

查看java安装位置
update-alternatives --display java
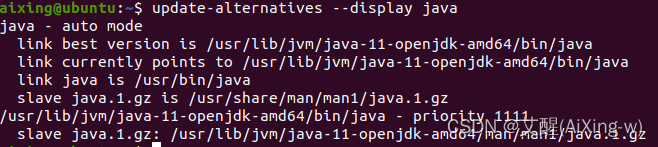
其中/usr/lib/jvm/java-11-openjdk-amd64/bin/java就是java的路径
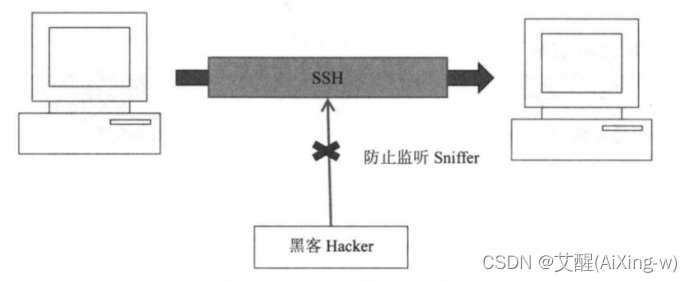
设置SSH无密码登录
Hadoop是有很多台服务器组成的,当我们启动hadoop系统时,namenode必须与datanode连接并管理这些节点(datanode)。此时系统会要求用户输入密码。为了让系统顺利运行而不手动输入密码,需要将SSH设置成无密码登录。注意,无密码登录并非不需要密码,而是事先交换SSH Key(密钥)来进行身份认证。
安装ssh
sudo apt-get install ssh
安装rsync
sudo apt-get install rsync
产生ssh key(密钥)进行后续身份验证
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
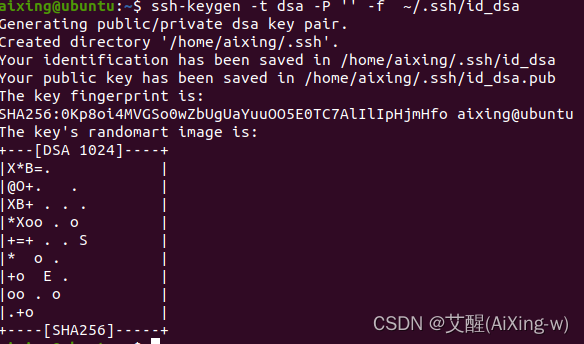
查看产生的SSH Key(密钥)
ll ~/.ssh
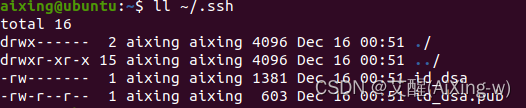
其中id_dsa和id_dsa.pub为产生的密钥文件
将产生的公钥加入许可证文件
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
重定向符号“>>”会将命令运行产生后的标准输出(stdout)重定向附加在该文件之后,当上述命令运行后,会将/.ssh/id_dsa.pub附加到/.ssh/authorized_keys许可证文件之后。
安装hadoop
下载
来到下载页面
https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/
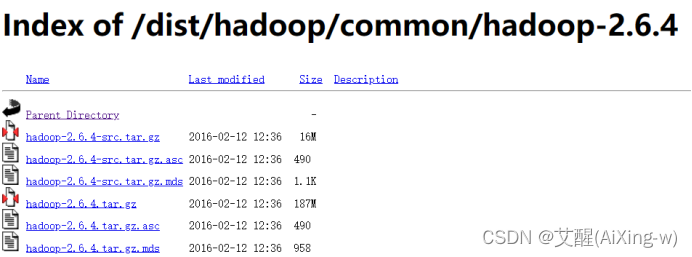
选中hadoop-2.6.4.tar.gz
右键,选复制链接
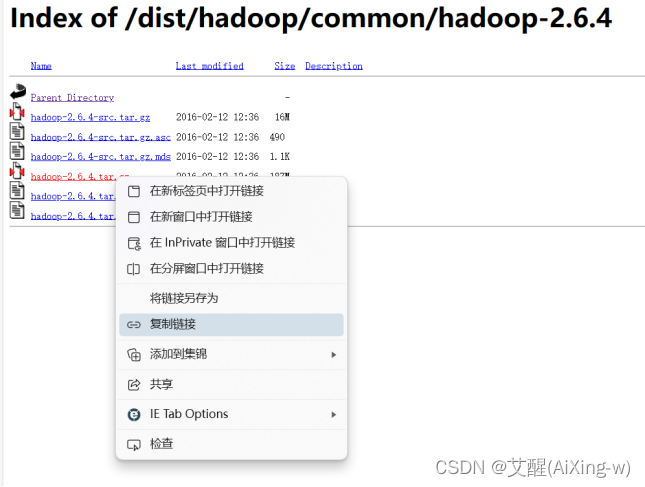
复制后的链接如下:
https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
使用wget执行下载命令
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
其实更好的方法是直接下载下来然后传到虚拟机上
安装
解压压缩包
sudo tar -zxvf hadoop-2.6.4.tar.gz
移动文件夹
将解压出的文件夹移动到 /usr/local/hadoop目录
sudo mv hadoop-2.6.4 /usr/local/hadoop
查看hadoop安装目录
ll /usr/local/hadoop
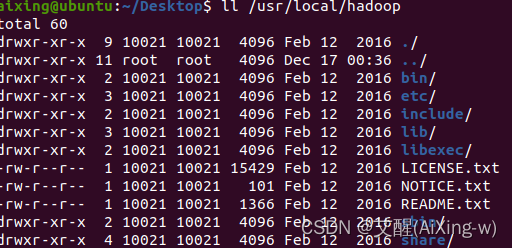
常用目录说明
| 目录 | 说明 |
|---|---|
| bin/ | 各项运行文件,包括hadoop、hdfs、yarn等 |
| sbin/ | 各项shell运行文件,包括start-all.sh、stop-all.sh |
| etc/ | etc/hadoop子目录包括hadoop配置文件,例如hadoop-env.sh、core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml |
| lib/ | hadoop函数库 |
| logs/ | 系统日志,可以查看系统运行情况,运行有问题时可以从日志找出错误原因 |
设置hadoop环境变量
编辑 ~/.bashrc
sudo gedit ~/.bashrc
打开结果如下
在后边加入输入以下内容然后保存
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
其含义为
设置JDK安装路径(需要读者根据自己安装的java版本自行调整)
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Hadoop的安装路径
export HADOOP_HOME=/usr/local/hadoop
设置PATH
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
设置HADOOP其他环境变量
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
链接库相关设置
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
使得~/.bashrc设置生效
source ~/.bashrc
修改hadoop配置设置文件
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
打开如下
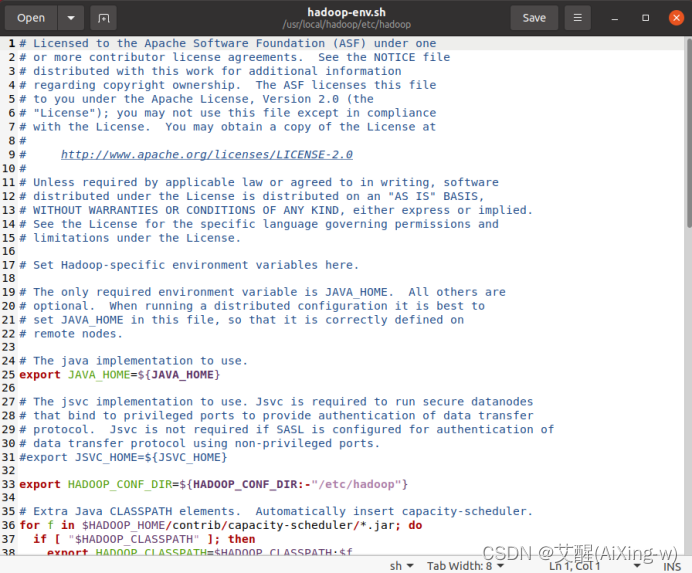
原本文件中的JAVA_HOME的设置为
export JAVA_HOME=${JAVA_HOME}
修改为
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
保存并关闭
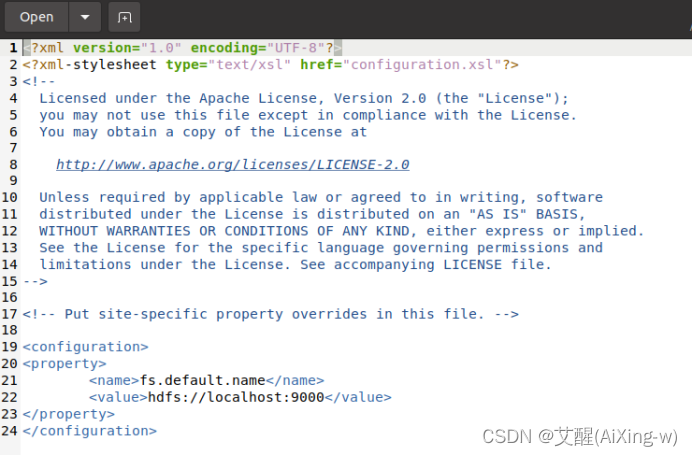
设置core-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
打开后如下
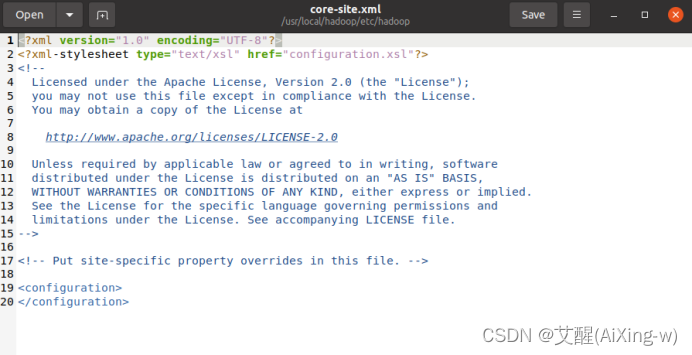
添加以下配置
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改后结果如下
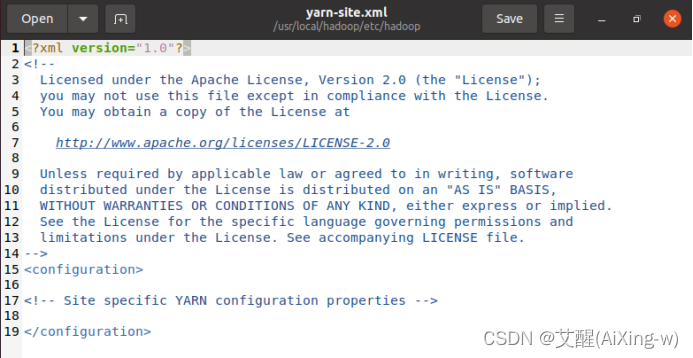
设置YARN-site.xml
输入以下命令
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
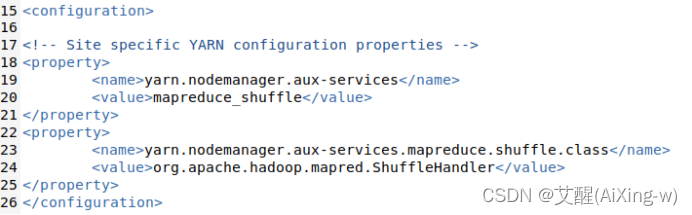
输入以下配置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
添加结果如下
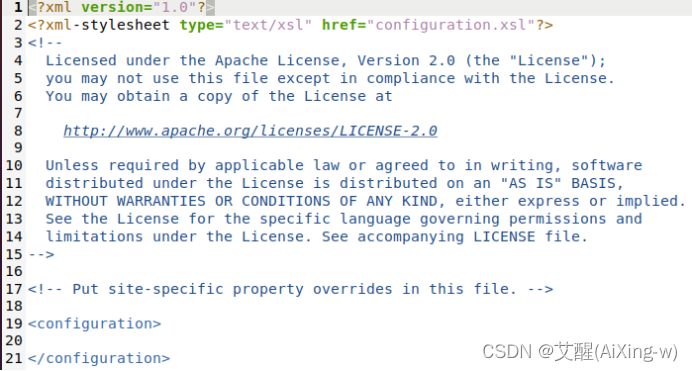
设置mapred-site.xml
Mapred-site.xml用于设置监控Map与Reduce程序的JobTracker任务分配情况以及TaskTraker任务的运行情况。Hadoop提供了设置的模板文件,可以自行复制修改
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
编辑mapred-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
打开后的结果如下:
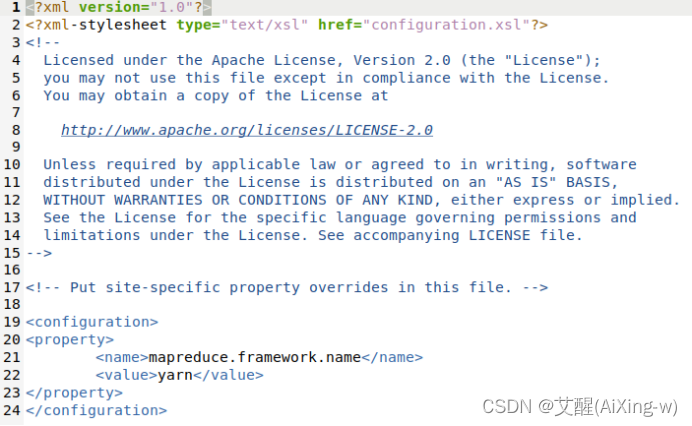
添加以下配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
添加后的结果如下:
设置HDFS分布式文件系统
打开hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
插入以下内容
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
默认的blocks副本备份数量是每一个文件在其他node的备份数量,默认值为3。编辑完成后,先保存,再关闭gedit。
创建并格式化HDFS目录
创建namenode数据存储目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
创建datanode数据存储目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
将hadoop目录的所有者更换为当前用户名
我这里用户名是aixing,大家可以自行更换
sudo chown aixing:aixing -R /usr/local/hadoop
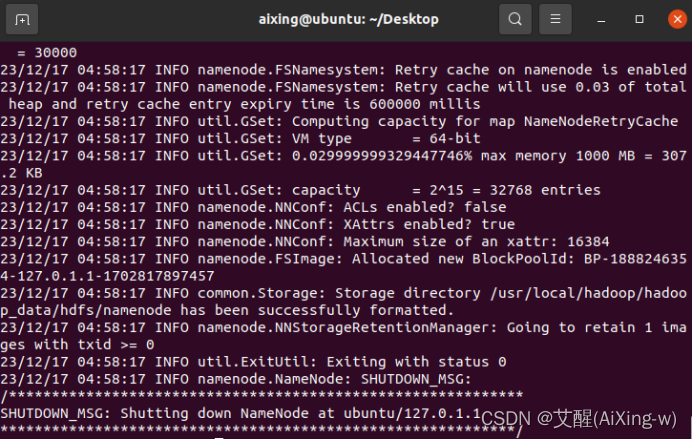
格式化HDFS
如果HDFS已有数据,执行会删除掉所有数据
hadoop namenode -format
启动hadoop
启动HDFS
start-dfs.sh
启动hadoop mapreduce 框架yarn
start-yarn.sh
同时启动HDFS、yarn
start-all.sh
查看namenode、datanode进程是否启动
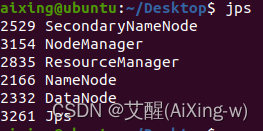
其中ResourceManager和NodeManager是Yarn相关进程,NameNode、SecondNameNode、DataNode是HDFS相关进程
打开hadoop resource-manager web页面
打开Hadoop ResourceManager web
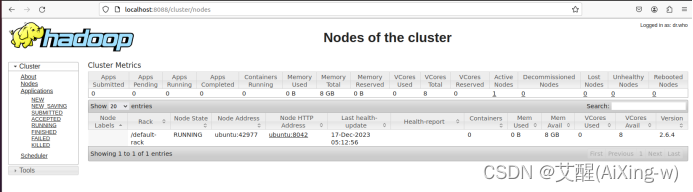
点开浏览器,访问链接:http://localhost:8088/
打开后页面如下:
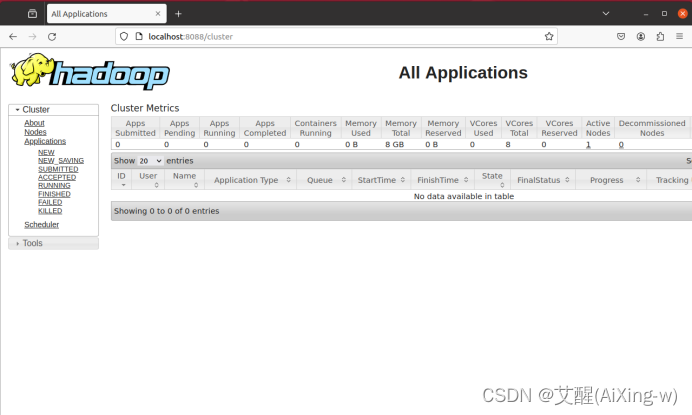
点击Nodes就会显示当前所有节点,不过我们安装的是single Node Cluster,所有只有一个节点
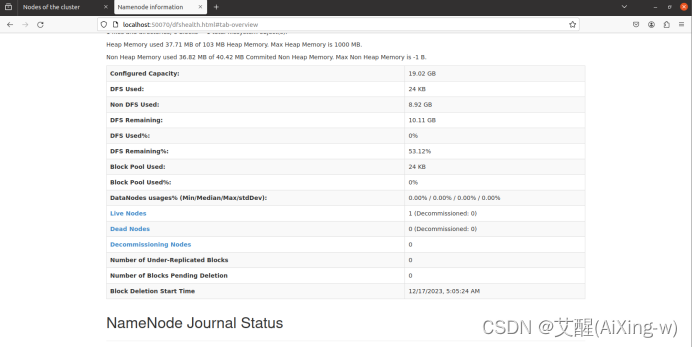
Namenode HDFS Web 界面
打开浏览器访问:http://localhost:50070/
查看Live Nodes,可以看到启动了1个节点
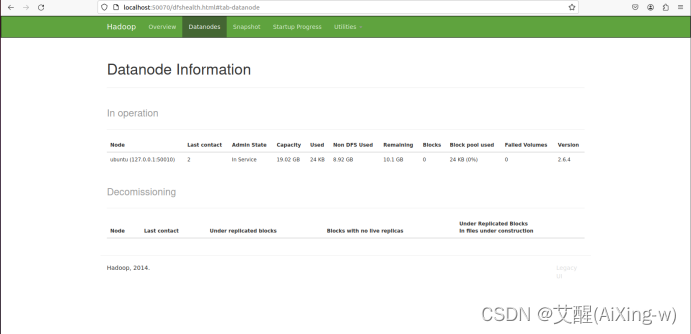
查看DataNode
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!