GDSII协议解析
去年圣诞节翻译了OASIS协议,今年圣诞在邮轮上利用被喂养的时间,把GDSII协议翻译了一下。这篇文档基本是按照GDSII Stream Format Manual ?Release 6.0版本的中文解释。这篇文档的组织结构跟原协议是一样的。因为Calma Company拥有原来协议的所有版权,所以我无法提供原协议在这里。请另外设法想办法查找下载。本文仅作兴趣研究,对其中的错误概不负责。希望能为支持国内半导体产业做点微薄贡献。为避免版权的一些问题,本文仅限非盈利场合交流使用,不限制转载,但请注明原文来自CSDN的内核中的洋葱。
目录
1 用户使用说明
2. 记录的描述
3. 数据类型的描述
4. 记录类型
5. 流格式语法
1.0 用户的使用说明(Notes to the User)
流格式(Stream Format)是GDSII数据的标准输入格式。流格式是一种用OUTFORM和STREAMOUT来写, 用INFROM来读的格式。 库(Libraries)用这种格式来保存,可以很容易的传送给其他系统处理。流格式在不同的版本之间是前向兼容(Upward Compatible)。 旧版本保存的库资料用新版本总是可以打开。
下面的第二章到第四章描述的是流格式的各部分组件(Stream?format?components)。 第五章和第六章描述的是流语法(Stream?Syntax)。 第七章提供了一个流格式的文件例子和描述。
2.0 记录的描述(Record Description)
流格式的输出文件是由不同长度的记录组成。最小的记录长度是4Bytes. 记录可以无限长。记录的最开始4个字节组成了记录的头部。记录头部最开始的两个字节表示的是记录的长度(基于8?bits的Byte为单位的计数)。这个长度计数告诉了一个记录到哪里结束,以及下一个记录的开始。吓一条记录是紧接着前一条记录的最后一个字节。
记录头部的第三个字节是记录的类型。第四个字节是记录中数据的类型。第五个到最后一个字节是记录的数据。 Fig?2-1 表示了一个典型的记录的头部。

如果输入文件是写在磁带(magnetic tape)里面,那么库的记录是卸载2048 字节的物理块里面。记录可以跨越物理块的边界,一个记录不需要全部的写在一个物理块里面。
一个空字(Null Word) 包括两个连续的0字节(zero Bytes)。 空字用来填充下面的空间:
- 一个库的最后一个记录到它所在物理块的结束位置, 或者
- 在多卷磁带文件中,最后一个记录跟它所在物理块的结束位置。
第三章和第四章描述数据和记录的类型。第五章描述这些记录如何组织成一个GDSII文件。
3.0 数据类型的描述(Data Type Description)
表3-1列举了可能的数据类型和他们对应的值。你可以在一个记录的头部的第四个字节找到记录数据类型的值。

下面的段落将描述表3-1中列出来的数据类型。
请记住:一个字包含16个bits。 标号0?到15 分别表示从左到右的顺序。
3.1 ?比特数组(Bit Array, 数据类型1)
一个比特数组是一个字, 这个字用特定的某个比特或者多个比特的值来表示数据。 比特数组可以让一个字表示多个简单的信息。
3.2 两个字节的有符号整数 (Two-Byte Signed Integer, 数据类型2)
两个字节的整数 =?一个字的带符号的2进制补码表示。
(2-byte integer ?= ?1 word 2s-complement representation).
(译者备注:就是计算机里面带符号的16bit补码整数表示)
两个字节的有符号整型的范围是-32768到32767.
下面是一个两字节整数的表示, 其中的S是符号, M表示大小。
SMMMMMMM ?MMMMMMMM
下面是一些两字节整数的例子:
00000000 ?00000001 = 1
00000000 ?00000010 ?= 2
00000000 ?10001001 ?= 137
11111111 ?11111111 ?= ?-1
11111111 ?11111110 ?= -2
11111111 ?01110111 ?= ?-137
3.3 四字节的有符号整型??(Four-Byte Signed Integer, 数据类型3)
4字节整数 ?= ?2 字 的有符号二进制补码表示
(4-byte?Integer = 2 word 2s-complement representation)
?(译者备注:就是计算机里面带符号的32bit补码整数表示)
??4字节有符号整型的范围是 -2, 147,483, 648到 2,147,483,647.
下面是4字节整数的表示, 其中S表示符号位, M表示大小。
SMMMMMMM ?MMMMMMMM ?MMMMMMMM ?MMMMMMMM
下面是一些四字节整数的例子:

3.4 四字节实数和八字节实数(Four-Byte Real and?Eight-Byte Real, 数据类型分别是4和5)
四字节实数 = 两字的浮点数表示
八字节实数 = 四字的 浮点数表示
对于所有的非零值:
- 一个浮点数由三个部分组成: 符号位, 指数域, 和尾数(mantissa)。
- 一个浮点数的值由下面的公式定义: (尾数) X??(16为底数,指数域的值为指数的数值)。
- 指数域(由比特位1-7组成)是用 Excess-64 表示法表示的数。 其中指数中7个比特表示的数比实际的指数值大于64。?(译者注:这种表示法请参考https://people.cs.pitt.edu/~wiebe/courses/CS273/lecnotes15.html对浮点数的解释。简单说,如果指数部分表示的二进制数是E, 那么实际上指数部分的值就是?E' = E + 64)
- 尾数总是一个大于等于?1/16, 并且小于1的正分数。对于4字节的实数,尾数部分是8到31比特位。对于8字节的实数,尾数是8-63比特位。
- 二进制的小数点是在第8比特的左边。
- 比特位8表示的值是1/2, 比特位9表示的值是1/4, 依次类推。
- 为了使尾数的范围在1/16和1之间, 实际的数值是正则化(Normalization)以后的数据。 正则化的过程是把尾数每次左移一个16进制的数,一直到它最左边的四个比特表示一个非零的数值为止。对于每次16进制移位, 指数值减一。因为尾数每次移动4个比特, 有可能正则化尾数的最左边的三个比特是零。一个零值, 也叫做真正的零值(True?Zero), 表示的是一个数所有的比特都是零。
下面是4字节和8字节的实数的表示。其中S表示符号位, E表示指数域, M表示大小。 例子里面包括4字节的实数。 正实数和负实数的表示是相同的,除了最高位的符号位是1而不是0.
在8字节的实数表示中,前面四个字节跟四字节的实数表示完全相同。最后的四个字节包含了更多的二进制数以提高解析度。
4字节的实数:
SEEEEEEE ?MMMMMMMM ??MMMMMMMM ?MMMMMMMM
8字节的实数:
SEEEEEEE ?MMMMMMMM ??MMMMMMMM ?MMMMMMMM
MMMMMMMM ?MMMMMMMM ??MMMMMMMM ?MMMMMMMM
一些四字节实数的例子:
提示:在下面的第六行例子中,7比特的指数域=65, 实际的指数值是65-64=1.


3.5 ASCII字符串(ASCII string, 数据类型是6)
它是一些ASCII字符串的集合,每个字符用一个字节表示。所有奇数长度的字符串需要用一个空字符(数值编号是0)放在末尾来填充。当统计记录长度的时候,需要将这个空字符包含在内。流的读入程序,必须读入这个空字符,如果发现最后一个字符是空字符那么在生成字符串长度的时候需要减一。
4.0 记录类型(Record Types)
一个记录总是偶数字节的长度。如果一个字符串是奇数个字节长,那么它需要在末尾填充一个空字符。
下面是每种记录以及它的简单描述。下面每条记录说明中,中括号中的前两个数字是记录的类型,后面两个数字是数据的类型。所有的记录数字都是用16进制表示。
4.1 头记录 (Header)[0002]
记录类型:0.
数据类型:两个字节有符号整型
包括两个字节的数据,用来表示版本号。表4-1列举了对应的版本号(version number)和GDSII发行号(release number)。请注意在6.0的发行号中,版本号变成了三个数字。

4.2 库开始记录(BGNLIB)[0102]
记录类型:01
数据类型:02, 两个字节的带符号整数
包含库(Library)的最后修改时间(分别用两个字节用来保存年月日小时分钟和秒)和最后的访问时间(同样的时间格式), 同时标识一个库的开始。参考Figure 4-1.
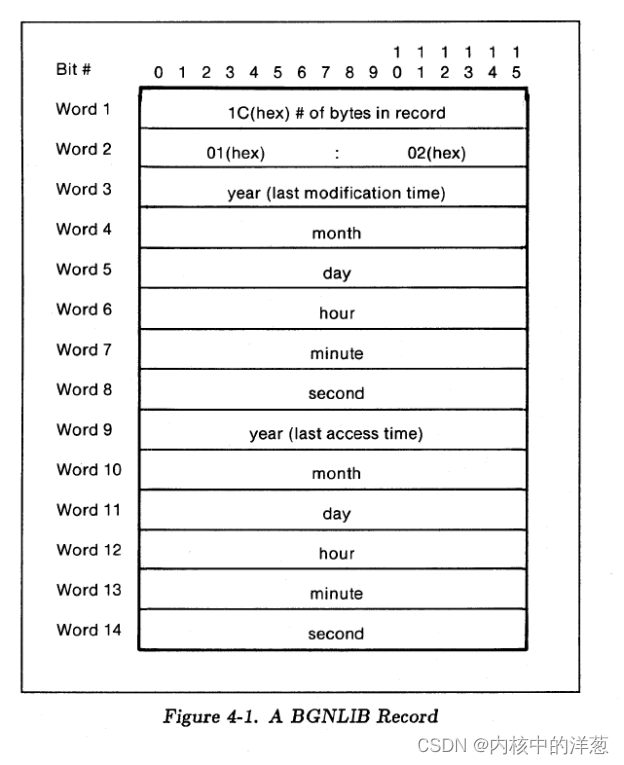
4.3 库名字(LIBNAME)[0206]?
记录类型:02
数据类型:06, ASCII字符串
包含库名字的字符串。一个库名字必须遵循CDOS操作系统的命名规范。库名字可以包括文件的扩展名(通常用.DB作为扩展名)。
4.4 单位(UNITS)[0305]?
记录类型:03
数据类型:05, 八比特的实数
记录包含两个八比特的实数。第一个表示用用户单位(user?unites)表示的数据库单位(database unit)大小。第二个则表示用米做单位表示的数据库单位大小。 ?举个例子, 如果你的库用缺省的单位创建(缺省的用户单位是1毫米,数据库单位是1000每用户单位),那么第一个实数将是0.001, 第二个实数就是1E-9。 典型的第一个实数小于1, 因为你通常使用的每个用户单元大于1数据库单元。
(译者注: 现在通常database unit都是nm甚至0.01nm级别,而用户单元基本都是1mm。 如果database unit是1nm, ?user unit 是1mm,因为1nm= 0.001mm, 所以第一个数就是0.001。而第二个数是1nm = 1E-9m, 所以第二个数就是1E-9.)
为了用米为单位计算用户单位,用第二个数除于第一个数。
4.5 库结束记录(ENDLIB)[0400]?
记录类型:04
数据类型:没有数据。
表示一个库的结束。
4.6 结构开始记录(BGNSTR)[0502]?
记录类型:05
数据类型:两个字节的有符号整型数据
记录包含了一个结构(structure)的创建和最后修改时间(时间格式跟BGNLIB记录中的格式一样), 同时标识一个结构的开始。
4.7 结构名字记录(STRNAME)[0606]?
记录类型:06
数据类型:ASCII字符串
这个记录包括了一个表示结构名字的字符串。一个结构的名字最多有32个字符长。有效的名字字符包括下面这些:
- Z
- a - z
- 0-9
- 下划线 _
- 问号 ?
- 美元符号 $
4.8 结构结束记录(ENDSTR)[0700]?
记录类型:07
数据类型:没有数据。
标识着一个结构的结束。
4.9 边界记录(BOUNDARY)[0800]?
记录类型:08
数据类型:没有数据。
标识着一个边界元素(Boundary element)的开始。
4.10 路径记录(PATH)[0900]?
记录类型:09
数据类型:没有数据。
标识着一个路径元素(Path?element)的开始。
4.11 结构引用记录(SREF)[0A00]?
记录类型:0A
数据类型:没有数据。
标识着一个结构引用元素(Structure reference element)的开始。
4.12 数组引用记录(AREF)[0B00]?
记录类型:0B
数据类型:没有数据。
标识着一个数组引用元素(Array reference element)的开始。
4.13 文本记录(TEXT)[0C00]?
记录类型:0C
数据类型:没有数据。
标识着一个文本元素(text?element)的开始。
4.14 层记录(LAYER)[0D02]?
记录类型:0D
数据类型:两字节的符号整型。
这个结构包含两字节的有符号整数用来表示层数(layer)。层数的范围必须在0-63之中。
4.15 数据类型记录(DATATYPE)[0E02]?
记录类型:0E
数据类型:两字节的符号整型。
这个结构包含两字节的有符号整数用来表示数据类型(datatype)。层数的范围必须在0-63之中。
4.16 宽度记录(WIDTH)[0F03]?
记录类型:0F
数据类型:四字节的有符号整型
这个结构包含一个四个字节的有符号整数,用来表示路径(path)或者文本(text)记录的宽度,它的单位是数据库单位(database units)。如果宽度是负值,表示它不受任何父引用(parent reference)的放大因子(magnification factor)的影响。如果是0表示忽略。
(译者备注:忽略表示这个path或text不显示出来?)
4.17 坐标记录(XY)[1003]?
记录类型:10
数据类型:四字节的有符号整型。
这个记录包含了用数据库单位表示的XY坐标的数组。每个X和Y坐标都是一个四字节的整数。
路径(path)和边界(boundary)元素最多可以包含200对的XY坐标。一个路径最少含有两对坐标,一个边界最少含有4对坐标。边界元素的第一个和最后一个点必须一致(coincide).
一个文本(text)或者结构引用(SREF)元素必须有且只有一对坐标。
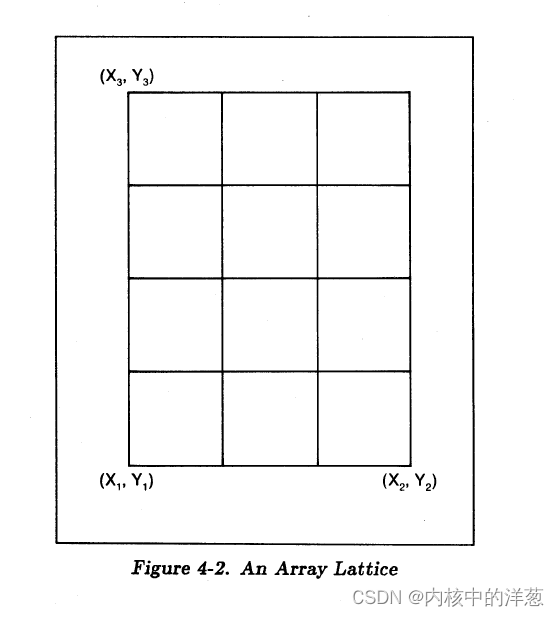
一个数组引用(AREF)有且只有三对坐标,用来指定 the?orthogonal array lattice. ??在一个数组引用中,第一个点是数组引用点(array?reference point)。 第二个点表示以数组引用点为原点, 列的间隔距离乘以列数的位置。第三个点表示以数组引用点为原点, 行的间隔距离乘以行数的位置。(译者注:这里可以参考Fig?4-2中的坐标来理解。)
一个节点(node)可以含有1-50对坐标。
一个范围(box)必须含有5对坐标, 第一个和最后一个点要相同。
下面Figure 4-2是一些数组格子(array lattice)的例子。
4.18 元素结束记录(ENDEL)[1100]?
记录类型:11
数据类型:没有数据。
标识着一个元素(element)的结束。
4.20 行列记录(COLROW)[1302]?
记录类型:13
数据类型:两比特的有符号整型
这个记录包含四个字节。前两个字节表示在一个数组(array)中列的数量。后两个字节表示行的数量。行数量和列数量都不能超过32767,?两者都要是正数。
4.21 文本节点记录(TEXTNODE)[1400]?
记录类型:14
数据类型:没有数据。
标识着一个文本节点(text?node)的开始。
4.22 节点记录(NODE)[1500]?
记录类型:15
数据类型:没有数据。
标识着一个文本节点(node)的开始。
4.23 文本类型记录(TEXTTYPE)[1602]?
记录类型:16
数据类型:两字节的有符号整型
包含两个字节用来表示文本类型(texttype)。 文本类型的大小必须在0-63之间。
4.24 文本呈现记录(PRESENTATION)[1701]?
记录类型:17
数据类型:比特数组(Bit?Array)
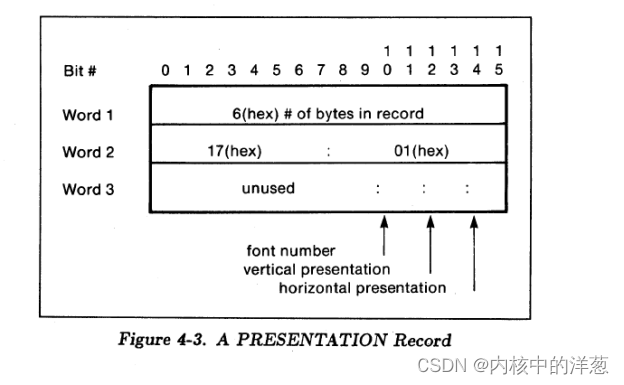
这个记录用两个字节的比特位来标识如何呈现文本。比特位10和11在一起,组成一个二进制数,用来表示字体。(00表示字体0, 01表示字体1,10表示字体2, 11表示字体3.)。 比特位12和13表示垂直方向的呈现(00表示顶部对齐,01表示中间对齐,10表示底部对齐)。比特位14和15表示水平方向的呈现(00表示左边对齐,01表示中间对齐,10表示右边对齐)。比特位0到9目前没有定义,保留给将来使用,当前要为0。
如果这个记录被省略, 那么缺省使用顶部-左边(top-left)对齐,字体使用字体0.
Fig 4-3 显示了一个文本呈现记录的结构。
4.25 空记录(SPACING)?
记录类型:18
这个记录不被再使用。
4.26 字符串记录(STRING)[1906]?
记录类型:19
数据类型:ASCII字符串。
这个记录包含需要呈现的文本字符串。最多可以有512个字符长度。
4.27 ?结构变形记录(STRANS)[1A01]?
记录类型:1A
数据类型:比特数组(Bit Array)
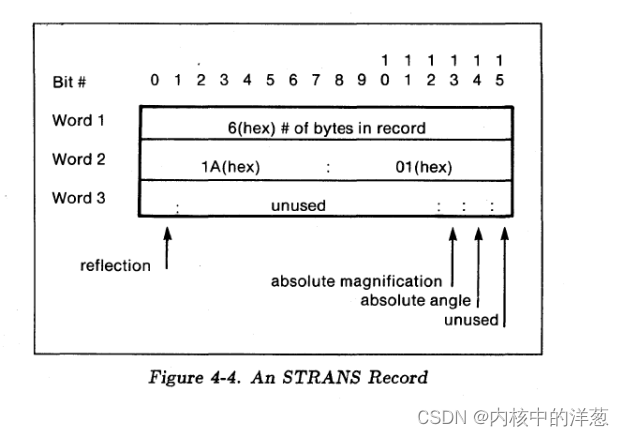
这个结构用两个字节的比特位,控制了结构引用记录(SREF), 数组引用记录(AREF)和文本记录(text)的变形。比特0(最左边的bit)定义了反射(reflection)。如果这个比特位被设置了,那么图形在做任何角度变化之前,需要沿X轴做一次反射变化。对于数组引用记录(AREF),需要对整个数组网格做反射变化,对于每个单独的数组元素跟随这个网格严格贴在一起做变化。比特13表示绝对大小变化。比特14表示绝对角度变化。 比特15(最右边的一个比特)和其他比特都保留给将来使用,需要将这些比特位清0。如果省略这个记录,那么所有元素都认为没有反射,大小和角度都没有变化。
图4-4表示了一个结构变形记录。
4.28 幅度变化记录(MAG)[1B05]?
记录类型:1B
数据类型:八字节的实数
这个记录包含一个双精度的实数(8字节), 用来表示幅度变化因子(Magnification factor)。 如果省略这个记录,默认幅度变化是1.
4.29 角度变化记录(ANGLE)[1C05]?
记录类型:1C
数据类型:八字节的实数
包括一个双精度的实数(8字节),用来表示角度旋转因子(Angular rotation factor), 单位用度(degree)表示并且以逆时针(counterclockwise direction)方向来表示。
对于AREF, 角度的旋转是以数组参考点(array reference point)为基点对整个数组格子(array?lattice)进行旋转。数组中的各个单独的元素都紧紧附在数组格子上一起旋转。如果省略这个记录,那么认为角度旋转是0。
4.30 用户整型数据记录(UINTEGER)?
记录类型:1D, ?不再使用。
数据类型:用户整型数据(不再使用)。
用户整型数据(User Integer data)只在发行版本2.0里面使用了。如果任何流格式文件的发行版本是2.0, 那么当流格式读入程序INFORM遇到用户整型数据(User?Integer data)时,需要将它转成包含参数126的适当的数据格式。参见记录PROPATTR和PROPVALUE。
4.31 用户字符串型记录(USTRING)?
记录类型:1E
数据类型:ASCII字符串。(不再使用)
用户字符串数据(User?String Data),?正式的名称叫做字符串数据(Character?String Data: CSD),?只在发行版本1.0和2.0中使用。
当流格式读入程序INFORM读取发行版本是1.0或者2.0的流格式文件的时候,需要将用户字符串数据转成包含参数127的适当的数据格式。如果这个记录没有提供,那么它就是空字符串(NULL string)。 参见记录PROPATTR和PROPVALUE。
4.32 引用库记录(REFLIBS)[1F06]?
记录类型:1F
数据类型:ASCII字符串
这个记录包含引用库(reference libraries)的名字。如果有任何引用库跟当前库绑定在一起,那么必须提供这条类型的记录。
第一个引用库的名字从字节0开始, 第二个引用库的名字从字节45(十进制数)开始。引用库的名字可以包括特定的目录(用“:” 分割)和一个扩展名字(用“.”分割)。如果任何一个库没有命名,它对应的位置填充空字符。
4.33 字体记录(FONTS)[2006]?
记录类型:20
数据类型:?ASCII字符串
这个记录包含了定义字体的文件(textfont?definition file)的名字。如果4种字体中的任何一个字体有对应的字体定义文件,那么必须提供这个记录。如果任何一个字体都没有字体定义文件,?那么就不应该提供这个记录。 字体0的名字在这个记录的开始,紧接着其余的三种字体。每个名称都是44个字节长,如果没有对应的字体定义文件,那么用空字符填充。每个名字如果比44个字节短,那么用空字符填充末尾。字体定义文件的名字可以包括特定的目录(用”:”分割)和开一个扩展名字(用“.”分割)。
4.34 路径类型记录(PATHTYPE)[2102]?
记录类型:21
数据类型:两字节的有符号整型数据
这个记录包含了表示路径末端形状的数据。0表示路径的末端是正方形并且末端穿过它的终点, 1表示圆形末端, 2表示末端是正方形并且比它的重点往外延展半个宽度。 路径类型4(只用来给用户自定义产生的路径)表示各种变化的正方形末端扩展(参考记录48和49)。如果没有指定,缺省的路径类型是0. Fig 4-5显示了不同的路径类型。
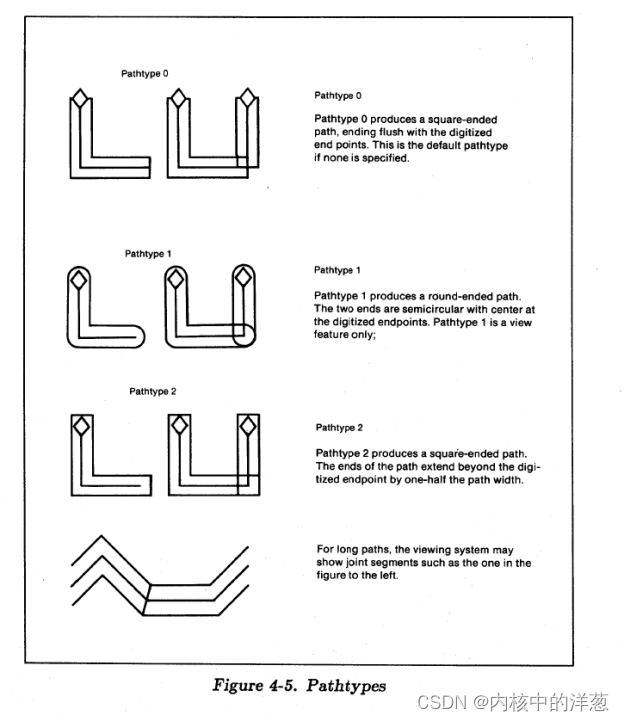
4.35 生成数量记录(GENERATIONS)[2202]?
记录类型:22
数据类型:2字节的整数
这个记录包含了一个正整数,它用来指定删除或者备份结构时,需要生成的拷贝数量。这个数据必须至少是2并且不能超过99。 如果GENERATIONS记录没有提供,那么缺省是3。
(译者注:对库文件中的结构做任何编辑之前,编辑软件应该做备份。这个记录用来指定备份的数量。这里用来指定应该做多少份备份。但感觉这个好像并没有什么用。)
4.36 ?参数表记录(ATTRTABLE)[2306]?
记录类型:23
数据类型:ASCII字符串类型
这个记录包含了参数定义文件(Attribute?definition file)的名字。只有当一个参数定义文件跟当前库绑定在一起时才提供这个记录。参数定义文件的名字可以包括特定的目录(用”:”分割)和开一个扩展名字(用“.”分割)。最大长度是44个字节。
4.37 STYPTABLE记录(STYPTABLE)[2406]?
记录类型:24
数据类型:ASCII字符串
保留给将来的特性(Unreleased feature)。
4.38 STRTYPE记录(STRTYPE)[2502]?
记录类型:25
数据类型:两字节的有符号整型数据
保留给将来的特性(Unreleased feature)。
4.39 外部标记记录(ELFLAGS)[2601]?
记录类型:26
数据类型:比特数组
这个记录目前包括2个字节的比特标记。比特15(最右边的比特位)指定了模板数据(Template data)。 比特位14指定了外部数据(External Data, 有时候也叫做外围数据Exterior data)。 所有其他比特位目前没有使用,应该清零。如果省略这个记录,所有的比特位都认为是0.
关于模板数据的额外信息,请参考GDSII Reference Manual。 关于外部数据的额外信息,请参考CustomPlus?User’s Manual. ?Fig 4-6描述了ELFLAGS记录的信息。

4.40 ELKEY记录(ELKEY)[2703]?
记录类型:27
数据类型:四字节有符号整型数据
保留给将来的特性(Unreleased feature)。
4.41 ?LINKTYPE记录(LINKTYPE)[28]?
记录类型:28
数据类型:两字节有符号整型数据
保留给将来的特性(Unreleased feature)。
4.42 LINKKEYS记录(LINKKEYS)[29]?
记录类型:29
数据类型:四字节有符号整型数据
保留给将来的特性(Unreleased feature)。
4.43 节点类型记录(NODETYPE)[2A02]?
记录类型:2A
数据类型:两字节有符号整型数据
包含两个字节的整数用来表示节点类型。 节点类型的值必须在0-63之间。
4.44 属性参数记录(PROPATTR)[2B02]?
记录类型:2B
数据类型:两字节有符号整型数据
这个记录用两个字节来指定参数编号(attribute number)。 参数编号是一个1到127的整数。其中参数编号126和参数编号127保留给用户整数属性(User?Integer properties)和用户字符串属性(User?String Properties: CSD properties),?这两个属性在发行版本3.0之前使用。以前发行版本中的用户字符串和用户整型数据在新的协议中需要转化成属性位127和126的属性数据(property data)。
4.45 属性值记录(PROPVALUE)[2C06]?
记录类型:2C
数据类型:ASCII字符串
这个记录紧接着前面的PROPATTR记录,是PROPATTR记录中的参数名字对应的字符串值。最大长度126个字符。跟任何一个元素相关联的参数对(attribute?value?pairs: 参数的名字和值的配对)必须有独一无二的参数号(attribute numbers)。因此跟一个元素相关联的的参数数据(property ?data)的数量是有限制的: 所有字符串的长度,加上参数“名字-值”配对数量的两倍,不能超过128(如果元素是SREF, AREF或者node, 则不能超过512)。
例如,如果一个边界(boundary)元素, 有两个参数,一个参数的编号是2对应的值是“metal”, 另外一个参数的编号是10对应的值是“property”,?那么参数数据的总的大小是18字节。 这里是6个字节的“metal”(因为是奇数要补一个空格,所以长度是6) + 8个字节的“property” + 2倍 * 参数配对数是2?(2*2 =4) = 18.
4.46 ?BOX记录(BOX)[2D00]?
记录类型:2D
数据类型:没有数据。
标志这一个box元素的开始。
4.47 BOX类型记录(BOXTYPE)[2E02]?
记录类型:2E
数据类型:2字节的有符号整型数据
这个记录包含两个字节用来指定BOX类型。 Box类型的范围必须是0-63.
4.48 丛簇记录(PLEX)[2F03]?
记录类型:2F
数据类型:4字节的有符号整型数据
这个记录用一个独一无二的正整数表示一个丛簇。如果元素(elements)包含相同的丛簇号,那么他们都属于同一个丛簇。丛簇的开始是7个比特的头部,因此丛簇号码只有24个比特的长度。如果省略这个记录,那么这个元素不属于任何一个丛簇, 它不是任何一个丛簇的成员。
4.49 路径开始点扩展记录(BGNEXTN)[3003]?
记录类型:30
数据类型:4字节的有符号整型数据
这个记录只应用于路径类型4?(path type 4)。 它是四个字节长度,所采用的计量单位是数据库单位(database unit)。它用来定义一个路径(path)的第一个节点末端的路径形状(path outline)。这个值可以是负值。
4.50 路径结束点扩展记录(ENDEXTN)[3103]?
记录类型:31
数据类型:4字节的有符号整型数据
这个记录只应用于路径类型4?(path type 4)。 它是四个字节长度,所采用的计量单位是数据库单位(database unit)。它用来定义一个路径(path)的最后一个节点末端的路径形状(path outline)。这个值可以是负值。
4.51 磁带编号记录(TAPENUM)[3202]?
记录类型:32
数据类型:2字节的有符号整型数据
这个记录包含两个字节的数据,用来指定当前的磁带卷(reel of tape)在多卷轴流文件(multi-reel stream file)中的编号。 第一个磁带的TAPENUM编号是1; 第二个磁带的TAPENUM编号是2, 依次类推。
4.52 磁带编码记录(TAPECODE)[3302]?
记录类型:33
数据类型:2字节的有符号整型数据
这个记录一个是12字节长度, 包括了一个独一无二的6个2个字节整数的编码。
对于同一个多卷流文件(multi-reels stream file),?它所有的卷轴(reel)这个编码都是相同的。这个编码用来验证读入的卷轴(reels)都是正确的,都是属于同一个多卷流文件。
4.53 STRCLASS记录(STRCLASS)[3401]?
记录类型:34
数据类型:2字节的比特数组
这个记录包含两个字节的比特数组。这个记录值用在Calma公司内部的用户自定义结构(CustomPlus structures)中。如果流磁带(stream?tape)不是Calma的程序生成的,那么这个记录应该被省略或者被清零。
4.54 保留记录(Reserved)[3503]?
记录类型:35
数据类型:4字节的有符号整型数据
这个记录类型是预留给NUMTYPES记录使用。但目前没有使用。
4.55流磁带类型记录(FORMAT)[3602]?
记录类型:36
数据类型:2字节的有符号整型数据
这个记录用两个字节来定义流磁带(stream tape)的类型。目前之定义了两个值:0表示档案类型(archive format),?1表示过滤类型(filtered format)。
一个档案类型的流文件(Archived Stream file),包含的元素(elements)可以被所有层和数据类型(all?the layers and data types)使用。它是由输出格式(OUTFORM)来创建的。在一个档案流文件中, FORMAT记录是紧接在单位记录(UNITS?Record)后面。如果一个文件没有包含流磁带类型记录(FORMAT record)那么缺省就认为是档案类型文件。
一个过滤流文件(Filtered?Stream??file)只包括用户在执行流输出(STREAMOUT)的时候,指定了的特定的层和数据类型(layer?and data type)的元素。流输出(STREAMOUT)中使用的层数和数据类型(layer?and data type)列表是在FORMAT 记录后面的掩膜(MASK)记录中指定。MASK记录由ENDMASKS记录作为结束标记。至少必须有一个MASK记录紧接在FORMAT记录的后面。过滤的流文件(Filtered?Stream?File)由流输出(STREAMOUT)来创建。
MASK和ENDMASKS记录见下面的说明。
4.56 掩膜记录(MASK)[3706]?
记录类型:37
数据类型:ASCII字符串
这个记录仅在过滤格式的流文件(Filtered Stream file)中出现,并且在过滤格式的流文件中是必需的。
这个记录包含了用户在流输出(STREAMOUT)中指定的层数和数据类型(layer and data type)的列表。在FORMAT的记录后面至少必须要有一个MASK记录。在FORMAT记录后面可以跟多个MASK记录。最后一个MASK记录的后面接着一个ENDMASKS记录。
参考上面的FORMAT记录和后面的ENDMASKS记录。
在MASK列表中,数据类型跟层数之间用分号分开。单独的层数或者数据类型用空格分开。如果层数或者数据类型是一个范围(range),?用中短横线分开。下面是一个掩膜列表的例子:
1 ?5-7 ?10 ?;??0-63
(译者加注:这里表示层数有 1, 5, 6, 7, 10; 而数据类型则从0到63一个有64种。)
4.57 ?掩膜结束记录(ENDMASKS)[3800]?
记录类型:38
数据类型:没有数据。
这个记录仅在过滤格式的流文件(Filtered Stream file)中出现,并且在过滤格式的流文件中是必需的。
这个记录标识(一个或者多个)MASK记录的终止。ENDMASKS记录必须接在最后一个MASK记录的后面。ENDMASKS记录后面必须紧接着UNITS记录。
参考上面的FORMAT和MASK记录。
4.58 库目录大小记录(LIBDIRSIZE)[3902]?
记录类型:39
数据类型:2字节的有符号整型数据
这个记录包含了库目录的页数(the?number of pages in the library directory)。这个信息仅仅用在当读入格式程序(INFORM)把数据读进一个新的库的时候使用。如果提供了这个记录,那么它应该在BGNLIB记录和LIBNAME记录之间出现。 (译者注:其实我还不知道这个记录怎么使用。)
4.59 附加规则文件(SRFNAME)[3A06]?
记录类型:3A
数据类型:ASCII字符串
这个记录包含了附加规则文件(Sticks Rules File)的名字, 如果有附加规则文件跟这个库绑定的话。这个信息仅仅用在当读入格式程序(INFORM)把数据读进一个新的库的时候使用。如果提供了这个记录,那么它应该在BGNLIB记录和LIBNAME记录之间出现。 (译者注:其实我还不知道这个记录怎么使用。)
4.60 库安全记录(LIBSECUR)[3B02]?
记录类型:3B
数据类型:2字节的有符号整型数据
这个记录包含一个访问控制列表(Access Control List: ACL)的数组数据。这里可以包含从1到32的ACL条目,每个条目包含下面的内容:
- 一个组号码(group?number)
- 一个用户号码(user number)
- 访问权限(access rights)
这个信息仅仅用在当读入格式程序(INFORM)把数据读进一个新的库的时候使用。如果提供了这个记录,那么它应该在BGNLIB记录和LIBNAME记录之间出现。 (译者注:其实我还不知道这个记录怎么使用。)
5.0 ?流格式语法(Stream Syntax)
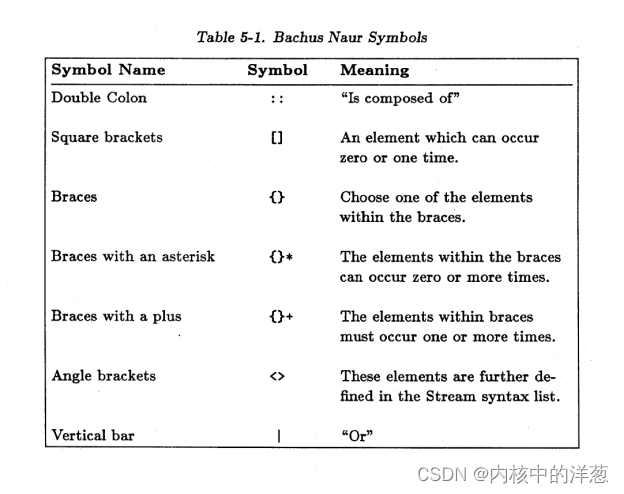
下面是用Bachus Naur表示法表示的流格式语法。用大写字母表示的一个元素是一个实际记录类型的名字。用小写字母表示的元素表示这个名字可以进一步分解成一系列的实际的记录类型。表5-1显示了用到的各种语法的含义。


6.0 ?多卷流格式(Multi-Reel Stream Format)
你可以把一个流格式文件写入到多卷的磁带(multiple reels of tape)中。第一个磁带必须用记录TAPENUM, TAPECODE和LIBNAME结尾,并且要按照上面的顺序。后面的每个磁带必须以上面三个相同的记录开始,并且顺序也要相同,并且以TAPENUM记录结尾。每个流磁带必须只包含完整的流记录,例如一个流记录(stream?record)不能在一个磁带中开始,然后继续写入到另一个磁带中(就是一个流记录不能分开写在不同的磁带中)。
请注意: TAPENUM和TAPECODE只能用在上面描述的地方。这些记录不能出现在流文件的任何其他地方。
TAPENUM, TAPECODE和LIBNAME记录的这种用法,只是用来标明磁带的身份(identification),?不会用在库中的其他地方。LIBNAME可以正常出现在流文件的第三个记录中。磁带的信息,在读完流文件以后就没用了。
下面用来解释多卷流磁带的格式。
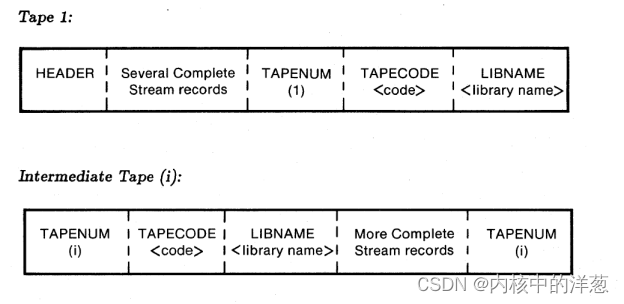

下面是用Nachus Naur表示法表示的多卷流磁带。请参考表5-1的语法解释。

完整的流格式记录,除掉磁带编号(tap-id groups)和TAPENUMs记录以外,其他部分的语法应该遵循第五章中对流格式语法的描述。
7.0 ?一个流格式文件的例子(Example of a Stream Format File )
这个给出了一个gds文件的例子,并对其中的语法做了一些解释。
这个就不再翻译了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!