redis之缓存穿透,击透,雪崩~
以下为一个我们正常的缓存流程:

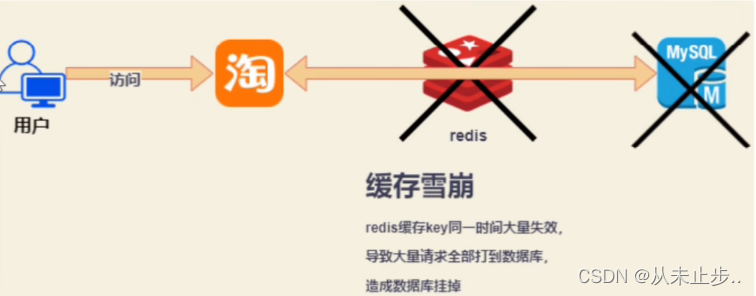
缓存雪崩:
在双十一的时候,淘宝的首页访问量是非常大的,所以它的很多数据是放在redis缓存里面,对应redis中的key,假设设置了缓存失效的时间为3小时,超过这三个小时后,在一瞬间redis缓存key大量失效,导致所有的请求都要直接和数据库交互,就会导致数据库响应不及时挂掉,此时首页就没办法向外界提供服务了,这就是缓存雪崩。
缓存雪崩解决方案:
1:设置缓存的失效时间,在初始化的时候,我们可以随机初始化它的失效时间,不要让他们都在同一时间失效
2:设置过期标志更新缓存,记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
3:构建多级缓存架构:nginx缓存+redis缓存+其他缓存等
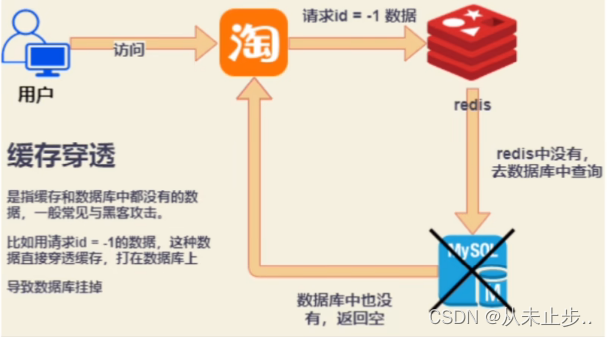
缓存穿透:
缓存穿透解决方案:
1:如果这个请求穿透redis直接到数据库,那么数据库无论查询到什么样的结果,都将结果缓存到redis中去,那么等下次,它使用同样的恶意数据,就不会穿透redis,但如果这个老六换了不同的参数,该解决办法就失效了
2:将这个老六的ip拉黑,但这个老六也可能换不同的ip
3:对参数的合法性检验,在判断这个参数不合法的时候就直接return
4:使用布隆过滤器(推荐!),下文有讲述
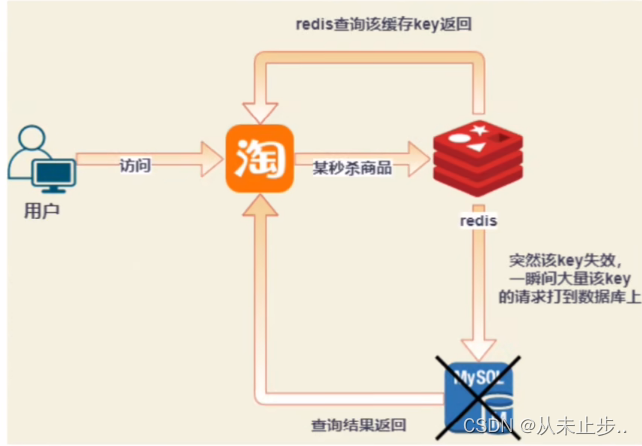
缓存击穿:
商品的秒杀,在秒杀之前程序员会将该商品的数据放到redis缓存中,对应redis中的一个key,假设设置key的过期时间为4个小时,但直到4个半小时,秒杀依然没有结束,而此时该商品的key缓存突然失效了,导致大量的请求在redis缓存中查询不到数据,那么就会直接访问数据库,从而导致数据库响应不及时而挂掉,该过程就叫缓存击穿
缓存击穿解决方案:
1:预先设置热门数据:在redis高峰访问之前,把一些热门的数据提前存入到redis里面,加大这些热门数据key的时长。
2:实时调整:现场监控那些数据热门,实时调整key的过期时间。
3:让数据对应的key永远不过期
4:使用分布式锁,单体应用使用互斥锁
布隆过滤器:
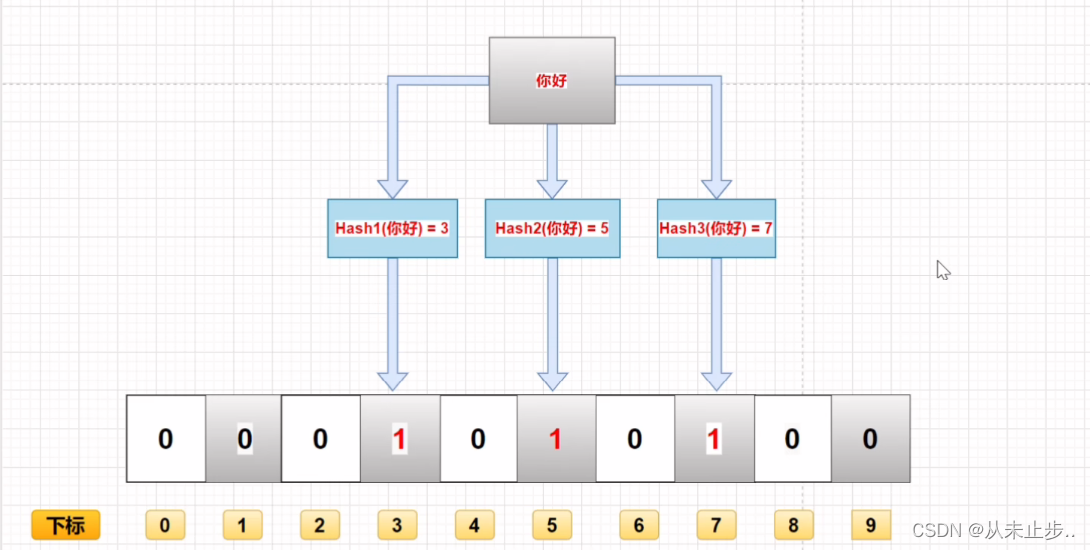
它其实就是一个很长的二进制向量,如下所示:

布隆过滤器的作用就是判断一个数据存不存在这个数组里面,如果不存在就是0,存在就是1
它是由一串二进制数组组成的数据,所以它占据的空间是非常小的,它插入和查询的操作是非常快的,因为它是计算这个数据的哈希值,再由哈希值映射到这个数组的下标,只需要根据算好的下标找对应的值即可,所以它的时间复杂度为O(K),之所以是O(K)不是O(1),是因为哈希函数的个数是不确定的,并且由于过滤器本身的数据就是二进制只有数字0和1,不存储原始数据,那么就使得保密性非常好。
但它也存在着许多的缺点,如下所示,布隆过滤器很难完成删除工作
假设有两个数据,“你好”和“hello”,经过哈希值运算,最终都被存储在下标为2的位置,那么我们仅根据下标就无法判断到底存储的是那个数据
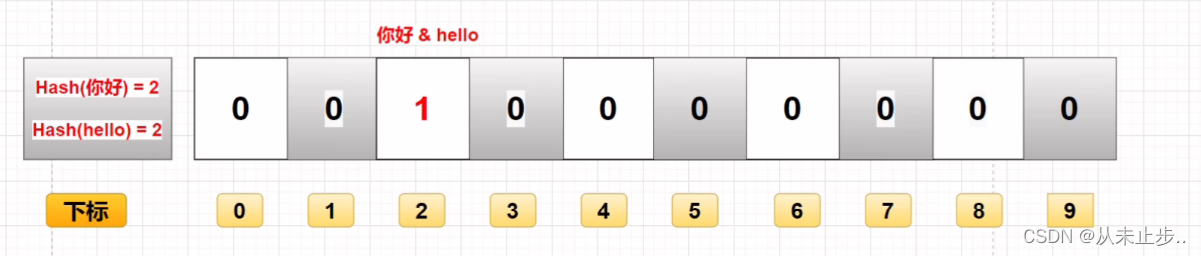
假设此时我们要删除“hello”这个数据,经过一系列运算,算出它在下标为2的这个位置,那么将下标2位置的这个1改成0,就代表已经删除这个数据了,但是由于“你好”这个数据也存储在这里啊,所以删除“hello”的同时把“你好”也删除了,就会造成数据的误删。
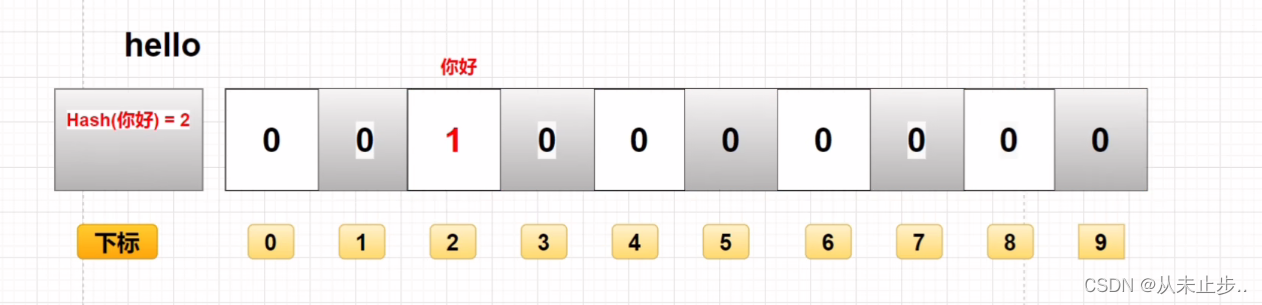
此外,它还有一个最大的缺点,它很容易进行误判,因为不同数据计算出来的哈希值可能是相同的,所以存在相同的哈希值,就会存在误判的情况,如下所示:
假设当前下标位2的位置只存储了数据“你好”,此时数据“hello”经过计算也需要存储在下标为2的位置,但判断过后,发现这里已经有数据了,那么就会误判数据“hello”已经存在了
而上述的这种误判几乎是解决不了的问题,只能减少误判的概率,那么我们怎么去减少误判的概率呢?
如下所示,我们使用Java实现布隆过滤器,我这里使用的是guava是由谷歌公司提供的工具包,里面提供了布隆过滤器的实现。
第一步:导入对应的依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
第二步:编写测试类:
package org.example;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.StandardCharsets;
public class bulong {
public static void main(String[] args) {
// 初始化布隆过滤器,设计预计元素数量为1000000L,误差率为3%
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF8), 100_0000, 0.03);
int n = 1000000;
for (int i = 0; i < n; i++) {
bloomFilter.put(String.valueOf(i));
}
int count = 0;
for (int i = 0; i < (n * 2); i++) {
if (bloomFilter.mightContain(String.valueOf(i))) {
count++;
}
}
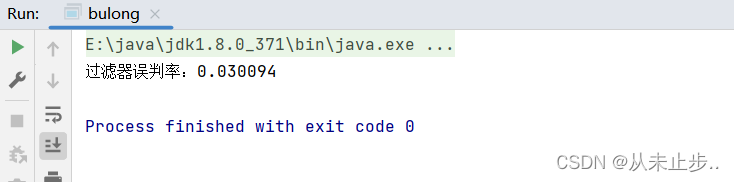
System.out.println("过滤器误判率:" + 1.0 * (count - n) / n);
}
}
将误判率设置为0.01
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 1000000, 0.01);
输出如下所示:

我们所设置的误判率是能影响最终的误判结果的,误判率设置的越低,计算所需的时间会越久,所需要的空间量就越大,所需的哈希函数就越多,原因对同一个数据使用多个不同的哈希函数所得到的哈希值相同的概率就越低,那么它们不同的数据存储在相同的位置的概率就越低,误判的概率就越低,但是由于哈希函数增多了,就会导致计算出的哈希值增多,进而导致二进制数据增多,所以也会占用更多的空间。
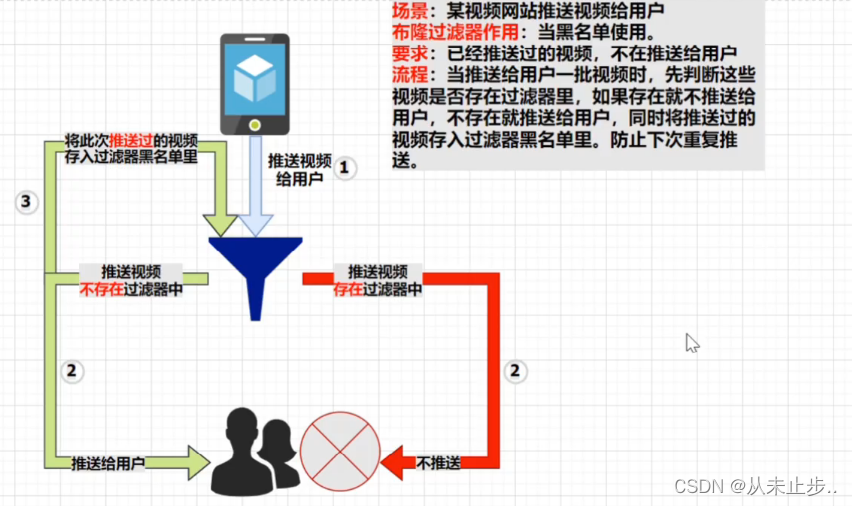
布隆过滤器解决缓存穿透问题:
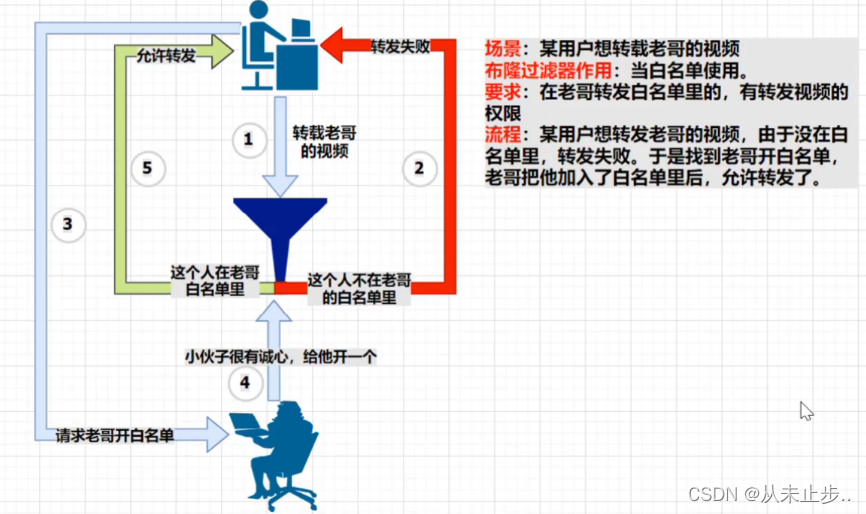
我们可以将布隆过滤器理解为一个黑名单或者白名单,因为它的主要作用就是判断这个元素存不存在这个白名单或者黑名单里面,
布隆过滤器白名单:

布隆过滤器黑名单:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!