[架构之路-261]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 架构设计 - 网络数据交换格式
一、网络数据交换格式
1.1 什么是网络数据交换格式
网络数据交换格式指的是在计算机网络中传输和存储数据时所采用的特定格式。
它定义了数据的组织方式、结构和编码规则,以便不同系统和应用程序之间能够准确地解析和处理数据。
网络数据交换格式的主要目的是:确保数据在不同系统之间的互操作性和兼容性。
通过使用统一的数据格式,数据可以在网络中进行有效传输,并能够被接收端正确解析和使用。
1.2?网络数据交换格式的好处
有以下几点:
-
可扩展性:网络数据交换格式可以根据数据的需求和复杂性进行灵活的扩展和定制。例如,JSON(JavaScript Object Notation)和XML(eXtensible Markup Language)等格式都支持层次结构和嵌套数据,可以轻松地表示复杂的数据关系。
-
可读性和可理解性:网络数据交换格式通常使用简单明了的语法和结构,使得数据易于阅读和理解。这对于开发人员、系统管理员和其他技术人员来说非常重要,因为他们可以更轻松地解析、操作和调试数据。
-
兼容性:网络数据交换格式通常是跨平台和跨语言的,这意味着它们可以在不同的操作系统、编程语言和应用程序之间进行数据交换。这种兼容性有助于促进不同系统之间的集成和协作,提高数据的互通性和可用性。
-
网络效率:相对于自定义的数据格式,网络数据交换格式通常具有较小的数据体积和高效的编解码方式,可以降低数据传输的带宽消耗和时间延迟。这对于移动应用、大规模数据交换和实时通信等场景下的网络效率至关重要。
-
可扩展性和易用性:网络数据交换格式的标准化和广泛应用使得开发人员能够轻松地使用各种工具和库来处理和操作数据。这方便了数据的生成、解析、验证和转换,提高了开发效率和代码的可维护性。
综上所述,网络数据交换格式的好处包括可扩展性、可读性和可理解性、兼容性、网络效率以及可扩展性和易用性等方面。这些好处使得网络数据交换格式成为现代应用程序和系统中数据交换和集成的重要工具。
备注:
网络数据交换格式的定义,最高效的方式采用二进制的数据结构。然而,考虑到上述特征的需要,不同应用程序之间往往不会采用最简单高效的二进制数据结构。而是采用文本格式,为了满足易用性、易读性、可扩展性、兼容性等特征,牺牲一定的效率。当然,有时候,数据交换格式在可视化和实际编码传输采用不同的格式:可视化时采用文本,传输编码时采用压缩的二进制格式,比如google的protobuf。
1.3?使用标准的网络数据交换格式的好处
使用标准的网络数据交换格式有以下好处:
-
互操作性:标准的网络数据交换格式可被广泛支持和理解,使不同系统、平台和语言之间实现数据交换变得更加容易。使用标准格式可以确保数据在不同技术环境中的正确解析和处理,提高系统的互操作性和集成性。
-
设计一致性:标准的网络数据交换格式具有一致的语法和结构规范,这有助于确保不同应用程序之间的数据交换的一致性和可靠性。开发人员可以遵循相同的规范,以一致的方式生成、解析和处理数据,减少因格式差异而引起的错误和混淆。
-
社区支持和工具生态系统:标准的网络数据交换格式通常拥有庞大的用户社区和丰富的工具生态系统。这意味着开发人员可以轻松地找到各种处理和操作数据的工具、库和框架。此外,标准格式也有许多文档、教程和示例可供参考和学习。
-
安全性和可靠性:标准的网络数据交换格式通常经过广泛的测试和验证,可以提供一定的安全性和可靠性。这些格式往往具有对数据结构和内容进行验证和约束的机制,以确保数据的有效性和一致性。此外,标准格式还可以使用加密和数字签名等技术来增强数据的安全性。
-
未来兼容性:标准的网络数据交换格式通常会持续演化和改进,以适应新的需求和技术发展。这意味着使用标准格式能够提供未来兼容性,减少因需求变化而带来的数据迁移和修改的工作量。
综上所述,使用标准的网络数据交换格式能够提供互操作性、设计一致性、社区支持和工具生态系统、安全性和可靠性,以及未来兼容性等好处。这些优势使得标准格式成为数据交换和集成的首选方案,并促进了系统的可靠性、可扩展性和可维护性。
二、常见网络数据交换格式
2.1 概述
网络数据交换格式(Network Data Exchange Format)是指在计算机网络中传输和存储数据时所使用的特定格式。
以下是一些常见的网络数据交换格式:
-
JSON(JavaScript Object Notation):一种轻量级的数据交换格式,易于阅读和编写,广泛应用于Web应用程序和API中。
-
XML(Extensible Markup Language):一种可扩展的标记语言,用于描述数据的结构和内容。常见用于数据存储、数据传输和Web服务中。
-
CSV(Comma Separated Values):一种简单的表格数据格式,以逗号为分隔符,用于存储和传输结构简单的数据。
-
YAML(YAML Ain’t Markup Language):一种人类易读的数据序列化格式,常用于配置文件和数据交换。
-
Protocol Buffers:一种由Google开发的二进制数据序列化格式,可用于高效地存储和传输结构化数据。
-
MessagePack:一种高效的二进制序列化格式,可用于快速和紧凑地传输数据。
-
BSON(Binary JSON):一种二进制JSON格式,支持更多的数据类型和功能,常用于NoSQL数据库中。
-
HTML(HyperText Markup Language):一种用于创建Web页面的标记语言,用于描述页面的结构和内容。
-
SGML(Standard Generalized Markup Language):一种通用的标记语言,被HTML和XML所继承。
-
RSS(Rich Site Summary):一种用于发布和订阅网站内容的标准格式,包括文章、新闻和博客等。
以上只是一些常见的网络数据交换格式,还有其他格式如INI、HDF5、Avro等,选择合适的数据交换格式应根据具体应用和需求来决定。
2.2 关于HTML
HTML(HyperText Markup Language)并不是一种网络数据交换格式,而是一种用于创建网页的标记语言。
HTML主要用于定义网页的结构和内容(这一点与XML是一样的),包括文字、图像、链接、表格等元素的排列和呈现方式。它通过使用标签和属性来标记和描述网页中的不同部分,并将其呈现为用户可见的网页。
当浏览器请求一个网页时,服务器会将网页的HTML内容发送给浏览器。浏览器会解析HTML,并根据其中的标记和内容,进行网页布局、样式渲染和交互处理,最终显示出用户所看到的网页。
对于网络数据交换,一种更常用的格式是JSON(JavaScript Object Notation)或XML(eXtensible Markup Language)。它们是通用的数据格式,可以在不同的系统和平台之间进行数据交换和共享。这些格式具备更灵活、精简的语法,以及更适合数据交换的结构。
因此,HTML适合用于创建和呈现网页内容,而不是作为网络数据交换的格式。对于数据交换,JSON或XML更常用。
备注:
HTML不仅仅用了客户端与服务器之间承载数据,即在不同网络节点之间交换数据。更重的是HTML还定义了如何呈现和展现数据。
2.3?网络数据交换格式XML
XML(eXtensible Markup Language)是一种标准的网络数据交换格式,它具有以下特点和好处:
-
可扩展性:XML允许用户自定义标签和数据结构,因此非常适用于表示复杂的数据关系和层次结构。它可以灵活地扩展和定义新的标签和元素,以适应不同领域和需求的数据表示。
-
可读性和可理解性:XML使用简单的文本格式,可读性强,并且易于解析和理解。每个元素和属性都以明确的标签表示,使得数据的结构和含义相对清晰,便于开发人员和其他技术人员理解和操作。
-
平台和语言无关:XML是一种与平台和编程语言无关的格式。它可以在各种操作系统和环境中使用,并且可以被不同的编程语言(如Java、C++、Python等)进行解析和处理,实现跨系统和跨语言的数据交换。
-
兼容性:由于XML的广泛应用和标准化,许多软件和应用程序都提供了对XML的支持。这意味着可以方便地使用各种工具、库和框架来处理和操作XML数据。
-
可验证性:XML提供了一种用于验证数据结构和规则的机制,即XML Schema。开发人员可以定义XML Schema来验证数据的有效性、一致性和合法性,减少数据错误和不一致性带来的问题。
-
扩展性和转换性:XML具有广泛的扩展性和转换性。可以使用XSLT(eXtensible Stylesheet Language Transformations)等技术将XML文档转换为其他格式,如HTML、JSON等,实现不同格式之间的互转和适配。
需要注意的是,虽然XML具有上述优点,但在某些情况下,它可能会产生较大的数据体积和解析复杂性。因此,在选择网络数据交换格式时,需要综合考虑具体的需求、场景和技术栈,选择最合适的格式。
下面是一个简单的XML示例:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="fiction">
<title>The Great Gatsby</title>
<author>F. Scott Fitzgerald</author>
<year>1925</year>
<price>10.99</price>
</book>
<book category="fiction">
<title>To Kill a Mockingbird</title>
<author>Harper Lee</author>
<year>1960</year>
<price>12.95</price>
</book>
<book category="non-fiction">
<title>Sapiens: A Brief History of Humankind</title>
<author>Yuval Noah Harari</author>
<year>2014</year>
<price>15.99</price>
</book>
</bookstore>
在这个示例中,XML文档以<?xml version="1.0" encoding="UTF-8"?>声明开始,指定了XML的版本和字符编码。然后是根元素bookstore,其中包含了多个book子元素。
每个book元素都有category属性指定了书籍的类别。在每个book元素中,有title、author、year和price等子元素,分别表示书名、作者、出版年份和价格。
这个简单的XML示例演示了XML的层次结构和标签嵌套的特点。
XML可以根据需求定义更复杂和嵌套的数据结构,以表示各种类型的数据。
2.4?网络数据交换格式JSON
JSON(JavaScript Object Notation)是一种常用的网络数据交换格式,它具有以下特点和示例:
-
简洁性:JSON使用简洁的键值对表示数据,易于阅读和编写。它采用类似于JavaScript的语法,包括对象(object)和数组(array)等数据结构。
-
可读性和可理解性:JSON的结构和语法相对简单清晰,易于理解和解析。键值对的结构使得数据的含义和结构更易于推断和理解。
-
平台和语言无关:JSON是一种独立于平台和编程语言的数据交换格式。它可以在各种操作系统、编程语言和应用程序之间进行快速和无缝的数据交换。
-
兼容性:JSON得到了广泛的支持和应用。大多数编程语言都提供了内置的JSON解析和生成功能,并有许多支持JSON的库和工具可供使用。
-
易于扩展:JSON支持嵌套、数组和对象的复杂数据结构,可以轻松表示多层次和复杂的数据关系。这使得JSON非常适合表示复杂的数据集合和树状结构。
-
可与JavaScript无缝集成:JSON的语法与JavaScript对象字面量的语法非常相似,因此,它可以直接在JavaScript中使用,实现方便的数据交换和解析。
下面是一个简单的JSON示例:
{
"bookstore": {
"book": [
{
"category": "fiction",
"title": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"year": 1925,
"price": 10.99
},
{
"category": "fiction",
"title": "To Kill a Mockingbird",
"author": "Harper Lee",
"year": 1960,
"price": 12.95
},
{
"category": "non-fiction",
"title": "Sapiens: A Brief History of Humankind",
"author": "Yuval Noah Harari",
"year": 2014,
"price": 15.99
}
]
}
}
在这个示例中,JSON使用花括号?{}?表示一个对象,对象中有一个键值对?"bookstore": {...}。对象中的值是另一个对象,其中有一个键值对?"book": [...],值是一个包含多个元素的数组。
每个数组元素表示一本书,它们使用花括号?{}?表示书的属性和值。例如,第一本书有?"category": "fiction"、"title": "The Great Gatsby"?等等。
这个示例演示了JSON的层次结构和键值对的特点。JSON可以根据需求定义更复杂和嵌套的数据结构,以表示各种类型的数据。
2.5 XML与JSON的比较
XML和JSON都是常用的数据格式,它们各有优点与不足,下面对比一下它们的特点:
-
数据结构:XML和JSON都可以表示复杂的数据结构,但它们的基本结构不同。XML使用标签来表示数据元素,具有树形结构。JSON使用键值对和数组表示元素,具有层次结构。相对而言,JSON的语法更简洁明了,更容易理解和处理。
-
文件大小:相同的数据在XML和JSON格式中,JSON的文件大小通常比XML更小。因为XML使用大量标记和属性来描述结构,并放置在文档的开始部分,而JSON只需使用少量字符来描述结构。
-
传输效率:相同的数据在XML和JSON格式中,JSON的传输效率通常比XML更高。因为JSON文件更小,可以更快地传输到远程服务器,并占用更少的网络带宽。
-
处理速度:JSON的处理速度比XML更快,因为JSON的语法更简洁,更容易解析。
-
兼容性:XML是一种标准化的格式,被广泛支持和应用于各种语言和平台。JSON虽然不像XML那样全面,但由于其短小精悍的结构和容易使用的语法,得到了广泛的支持和应用。
-
扩展性:XML支持扩展自定义标记和数据类型,可以为各种文档提供更丰富和灵活的数据结构。JSON虽然支持键值对和数组的复杂结构,但不能扩展自定义数据类型。
总的来说,XML比JSON更灵活、丰富和可扩展,但JSON比XML更易于使用、快速和高效。选择哪种格式,根据其具体的应用场景和需求来决定。
2.6 XML与HTML比较
XML(eXtensible Markup Language)和HTML(HyperText Markup Language)都属于标记语言,但它们有以下区别和比较:
-
设计目的:XML的设计目的是作为一种通用的数据交换格式,用于描述和传输数据,重点在数据的结构和内容。HTML的设计目的是用于创建和呈现网页内容,重点在内容的展示和呈现。HTML本质上也是客户端与服务器之间承载数据(文字文本、图片、视频)。
-
语法和语义:XML是一种通用的标记语言,强调数据的结构和语义上的准确性。它使用自定义的标记和元素来描述数据,标记和元素的名称可以任意定义。而HTML是一种专用的标记语言,用于创建网页,使用预定义的标签和元素来描述网页内容和结构。
-
标签和元素:XML允许用户自定义标记和元素,可以根据需求创建自己的标记和元素来描述数据。HTML则使用预定义的标签和元素,每个标签都有特定的语义和功能,如?
<div>、<p>、<table>等。 -
数据交换和展示:XML主要用于数据交换和存储,重点在数据的结构、格式和内容的准确性。HTML主要用于网页展示和呈现,重点在内容的可视化展示和交互。
-
扩展性:由于XML的灵活性和自由度,它具有很高的扩展性,可以定义自定义的标记和数据类型,以满足各种复杂的需求。HTML相对较为固定,对标签和元素的扩展性有限。
尽管XML和HTML有所区别,但它们也存在联系。HTML是一种基于XML的应用,使用XML的语法和规则来创建和描述网页内容和结构。同时,HTML也可以使用标准的XML解析器解析和处理。
总结起来,XML主要用于数据交换和描述,注重数据的结构和内容;HTML主要用于网页展示和交互,注重内容的可视化呈现。它们在语法、语义和使用方式上都有区别,适用于不同的应用场景和需求。
2.7?网络数据交换格式Protocol Buffers
Protocol Buffers(简称ProtoBuf)是一种由谷歌开发的高效的网络数据交换格式。
Protocol Buffers使用一种语言无关的数据描述语言来定义数据结构,然后根据此描述生成对应的编码和解码代码。这使得在不同的编程语言中,可以使用统一的描述文件来定义数据结构,并通过生成的代码来实现数据的序列化和反序列化,从而实现跨语言的数据交换。
与其他常见的数据交换格式相比,Protocol Buffers具有以下优点:
-
高效的编码:Protocol Buffers使用二进制编码,相对于文本格式的数据交换,可以大大减少数据的体积。这带来了更快的数据传输速度和更小的网络负载。
-
快速的解析:Protocol Buffers的解析速度非常快,因为它使用的是事先生成的高效的解析代码。这使得在数据交换过程中可以迅速地序列化和反序列化数据。
-
可读性和扩展性:Protocol Buffers的描述文件使用简洁的语法,易于理解和维护。同时,它们支持版本控制和向后兼容性,可以方便地对数据结构进行扩展和演化。
-
多语言支持:Protocol Buffers支持多种编程语言,包括C++、Java、Python等,使得在不同的平台和系统之间进行数据交换更加方便。
然而,使用Protocol Buffers也有一些限制和挑战。例如,由于其使用二进制编码,无法直接通过文本编辑器查看和编辑数据;此外,数据结构的更改可能需要更新生成的代码,这可能会引入一些额外的开发和维护成本。
总的来说,Protocol Buffers是一种高效、灵活且跨语言的网络数据交换格式,适用于需要快速、高效地传输和解析数据的场景。
下面是一个使用Protocol Buffers的简单示例,展示如何定义、序列化和反序列化数据。
首先,我们需要创建一个Protocol Buffers的定义文件(.proto文件),定义要序列化的数据结构。例如,我们创建一个名为"person.proto"的文件,定义一个Person的数据结构,包含id、name和email字段:
syntax = "proto3";
message Person {
int32 id = 1;
string name = 2;
string email = 3;
}
然后,通过使用Protocol Buffers的编译器将定义文件编译成所使用的编程语言的代码。例如,使用protoc编译器生成Java代码:
protoc -I=proto_folder --java_out=output_folder person.proto
接下来,我们在Java中使用生成的代码来实例化、序列化和反序列化Person对象:
import com.example.Person;
// 创建一个Person对象
Person person = Person.newBuilder()
.setId(1)
.setName("Alice")
.setEmail("alice@example.com")
.build();
// 序列化Person对象为字节数组
byte[] serializedPerson = person.toByteArray();
// 反序列化字节数组为Person对象
Person deserializedPerson = Person.parseFrom(serializedPerson);
// 访问Person对象的字段
int id = deserializedPerson.getId();
String name = deserializedPerson.getName();
String email = deserializedPerson.getEmail();
System.out.println("ID: " + id);
System.out.println("Name: " + name);
System.out.println("Email: " + email);
通过以上代码,我们实例化了一个Person对象,设置了id、name和email字段,并进行了序列化和反序列化操作。你可以根据需要使用生成的代码来进行更复杂的操作。
请注意,上述示例是基于Java语言的,如果使用其他编程语言,可能会有不同的语法和代码生成方式。你需要根据所用的编程语言和对应的Protocol Buffers库来进行相应调整。
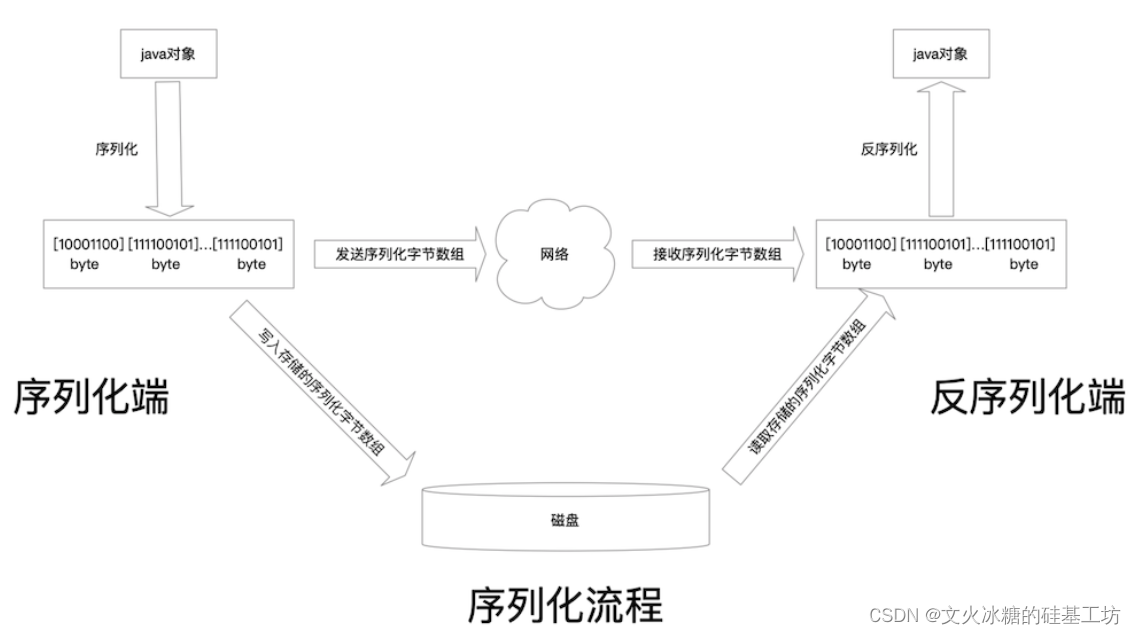
三、序列化和反序列化
序列化和反序列化是指将数据结构转换为一种可传输或可存储的格式,以便在不同的系统、程序或语言之间进行交换或持久化存储。
序列化将数据结构转换为字节流或文本格式,通常用于将数据发送到网络或保存到文件中。反序列化则是将字节流或文本格式的数据还原成原始的数据结构。
在软件开发中,序列化和反序列化是非常常见的操作。例如,在网络通信中,客户端和服务器之间需要传输数据,这些数据结构必须先进行序列化成一个可传输的数据包,服务器在接收到数据包后需要进行反序列化以恢复原始数据结构。
序列化和反序列化也可用于数据存储,例如将一个复杂的数据结构序列化为一个文件,然后在需要时重新加载文件并将其反序列化为数据结构。
一些常见的序列化和反序列化格式包括JSON、XML、Protocol Buffers、Thrift等。不同的格式具有不同的优缺点,例如JSON和XML易于理解和调试,但不如二进制格式高效。Protocol Buffers和Thrift高效但相对复杂。选择哪种格式应该根据具体需求来决定。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!