Python替代Adobe从PDF提取数据
2023-12-13 23:18:46
大家好,PDF文件是官方报告、发票和数据表的通用格式,然而从PDF文件中提取表格数据是一项挑战。尽管Adobe Acrobat等工具提供了解决方案,但它们并不总是易于获取或可自动化运行,而Python则是编程语言中的瑞士军刀。本文将探讨如何利用Python轻松实现PDF数据提取,而无需使用昂贵的软件。
1.使用PyMuPDF提取文本
PyMuPDF是一款轻量级的库,擅长读取PDF文件并提取文本。只需几行代码,就可以读取PDF并从任意页面提取文本。本文从奔驰集团2022年第四季度年度报告中提取“股东权益变动综合报表(Consolidated Statement of Changes in Equity)”,代码如下:
import?fitz??
import?pandas?as?pd
import?re
#?---?PDF处理?---
#?定义PDF文件的路径并打开文档
pdf_path?=?'..../Merc?2022Q4?Rep.pdf'
pdf_document?=?fitz.open(pdf_path)
#?选择要阅读的特定页面
page?=?pdf_document[200]
#?获取页面的尺寸
page_rect?=?page.rect
page_width,?page_height?=?page_rect.width,?page_rect.height
#?定义感兴趣区域的矩形(不包括脚注)
non_footnote_area_height?=?page_height?*?0.90
clip_rect?=?fitz.Rect(0,?0,?page_width,?non_footnote_area_height)
#?从定义的区域提取文本
page_text?=?page.get_text("text",?clip=clip_rect)
lines_page?=?page_text.strip().split('\n')
2.规整数据
提取的文本通常带有不需要的字符或格式,这就是预处理发挥作用的地方。Python的字符串处理功能使用户能够清洗和准备数据以转换为表格格式。
#?---?数据清洗?---
#?定义要搜索的字符串并查找其索引
search_string?=?'Balance?at?1?January?2021?(restated)?'
try:
????index?=?lines_page.index(search_string)
????data_lines?=?lines_page[index:]
except?ValueError:
????print(f"The?string?'{search_string}'?is?not?in?the?list.")
????data_lines?=?[]
#?如果不是数字或连字符,则合并连续字符串条目
def?combine_consecutive_strings(lines):
????combined?=?[]
????buffer?=?''
????
????for?line?in?lines:
????????if?isinstance(line,?str)?and?not?re.match(r'^[-\d,.]+$',?line.strip()):
????????????buffer?+=?'?'?+?line?if?buffer?else?line
????????else:
????????????if?buffer:
????????????????combined.append(buffer)
????????????????buffer?=?''
????????????combined.append(line.strip())
????
????if?buffer:
????????combined.append(buffer)
????
????return?combined
cleaned_data?=?combine_consecutive_strings(data_lines)
3.使用Pandas创建表格
一旦数据清洗完成,就可以使用pandas。这个功能强大的数据分析库可以将一系列数据点转换为DataFrame,即一个二维的、大小可变的、可能是异构的带有标记轴的表格数据结构。
#?---?创建DataFrame?---
#?根据列数将清洗后的数据分割成块
num_columns?=?6
data_chunks?=?[cleaned_data[i:i?+?num_columns]?for?i?in?range(0,?len(cleaned_data),?num_columns)]
#?定义DataFrame的表头
headers?=?[
????'Description',
????'Share?capital',
????'Capital?reserves',
????'Retained?earnings?(restated)',
????'Currency?translation?(restated)',
????'Equity?instruments?/?Debt?instruments'
]
#?使用数据块和表头创建DataFrame
financial_df?=?pd.DataFrame(data_chunks,?columns=headers)
#?Display?the?head?of?the?DataFrame?to?verify?its?structure
financial_df.head()
如下所示是从PDF文件中提取的表格结果:
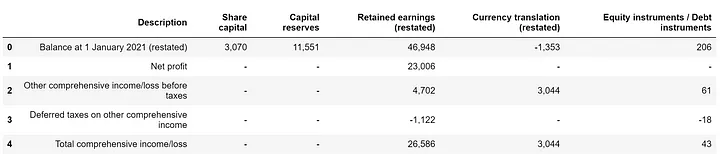
综上,通过利用Python强大的库,可以自动化繁琐的PDF数据提取任务。这种方法不仅成本低,而且提供了Python开发者所喜爱的灵活性和强大功能。
文章来源:https://blog.csdn.net/csdn1561168266/article/details/134842664
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!