8-高可用-压测与预案
在大促来临之前,研发人员需要对现有系统进行梳理,发现系统瓶颈和问题,然后进行系统调优来提升系统的健壮性和处理能力。
一般通过系统压测来发现系统瓶颈和问题,然后进行系统优化和容灾(如系统参数调优、单机房容灾、多机房容灾等)。
即使已经把系统优化和容灾做得非常好了,但也存在一些不稳定因素,如网络、依赖服务的SLA不稳定等,这就需要我们制定应急预案,在出现这些因素后进行路由切换或降级处理。
在大促之前需要进行预案演习,确保预案的有效性。
系统压测
压测一般指性能压力测试,用来评估系统的稳定性和性能,通过压测数据进行系统容量评估,从而决定是否需要进行扩容或缩容。
压测之前要有压测方案(如压测接口、并发量、压测策略(突发、逐步加压、并发量)、压测指标(机器负载、QPS/TPS、响应时间)),之后要产出压测报告(压测方案、机器负载、QPS/TPS、响应时间(平均、最小、最大)、成功率、相关参数(JVM参数、压缩参数)等),最后根据压测报告分析的结果进行系统优化和容灾。
线下压测
通过如JMeter、Apache ab压测系统的某个接口(如查询库存接口)或者某个组件(如数据库连接池),然后进行调优(如调整JVM参数、优化代码),实现单个接口或组件的性能最优。
线下压测的环境(比如,服务器、网络、数据量等)和线上的完全不一样,仿真度不高,很难进行全链路压测,适合组件级的压测,数据只能作为参考。
线上压测
线上压测的方式非常多,按读写分为读压测、写压测和混合压测,按数据仿真度分为仿真压测和引流压测,按是否给用户提供服务分为隔离集群压测和线上集群压测。
读压测是压测系统的读流量,比如,压测商品价格服务。
写压测是压测系统的写流量,比如下单。写压测时,要注意把压测写的数据和真实数据分离,在压测完成后,删除压测数据。
只进行读或写压测有时是不能发现系统瓶颈的,因为有时读和写是会相互影响的,因此,这种情况下要进行混合压测。
仿真压测是通过模拟请求进行系统压测,模拟请求的数据可以是使用程序构造、人工构造(如提前准备一些用户和商品),或者使用Nginx访问日志,如果压测的数据量有限,则会形成请求热点。
而更好的方式可以考虑引流压测,比如使用TCPCopy复制线上真实流量,然后引流到压测集群进行压测,还可以将流量放大N倍,来观察服务器负载能力。
隔离集群压测是指将对外提供服务的部分服务器从线上集群摘除,然后将线上流量引流到该集群进行压测,这种方式很安全。
有时也可以直接对线上集群进行压测,如通过缩减线上服务器数量实现,通过增大单台服务器的负载进行压测,这种方式风险很大,通过逐步减少服务器进行,并且在后半夜用户少的时候进行。
单机压测是指对集群中的一台机器进行压测,从而评估出单机极限处理能力,发现单机的瓶颈点,这样可以把单机性能优化到极致。
但实际集群的瓶颈往往是其依赖的系统或服务,如数据库、缓存或者调用的服务,因此单机压测的结果不能反映集群整体处理能力,也需要进行集群压测,从而评估出集群的极限处理能力,从而有针对性地对集群依赖的系统或服务进行优化。
在压测时,也应该选择离散压测,即选择的数据应该是分散的或者长尾的,比如,刚刚新增的商品一般在缓存中,而去年已经下架的商品已经从缓存中移除,刚刚新增的商品往往是热点数据,而去年已下架的商品是冷数据,所以如果压测的数据是热点数据则是不能反映出系统的真实处理能力。
另外,在实际压测时应该进行全链路压测,因为可能存在一个非核心系统服务调用问题造成整个交易链路出现问题,或者链路中的各个系统存在竞争资源的情况,因此为了保证压测的真实性,应该进行全链路压测,通过全链路压测来发现问题。
系统优化和容灾
拿到压测报告后,接下来会分析报告,然后进行一些有针对性的优化,如硬件升级、系统扩容、参数调优、代码优化(如代码同步改异步)、架构优化(如加缓存、读写分离、历史数据归档)等。不要把别人的经验或案例拿来直接套在自己的场景下,一定要压测,相信压测数据而不是别人的案例。
在进行系统优化时,要进行代码走查,发现不合理的参数配置,如超时时间、降级策略、缓存时间等。在系统压测中进行慢查询排查,包括Redis、MySQL等,通过优化查询解决慢查询问题。
在应用系统扩容方面,可以根据去年流量、与运营业务方沟通促销力度、最近一段时间的流量来评估出是否需要进行扩容,需要扩容多少倍,比如,预计GMV增长100%,那么可以考虑扩容2~3倍容量。
还要根据系统特点进行评估,如商品详情页可能要支持平常的十几倍流量,如秒杀系统可能要支持平常的几十倍流量。
扩容之后还要预留一些机器应对突发情况,在扩容上尽量支持快速扩容,从而出现突发情况时可以几分钟内完成扩容。
不要把所有鸡蛋放进一个篮子,在扩容时要考虑系统容灾,比如分组部署、跨机房部署。容灾是通过部署多组(单机房/多机房)相同应用系统,当其中一组出现问题时,可以切换到另一个分组,保证系统可用。
应急预案
在系统压测之后会发现一些系统瓶颈,在系统优化之后会提升系统吞吐量并降低响应时间,容灾之后的系统可用性得以保障,但还是会存在一些风险,如网络抖动、某台机器负载过高、某个服务变慢、数据库Load值过高等,为了防止因为这些问题而出现系统雪崩,需要针对这些情况制定应急预案,从而在出现突发情况时,有相应的措施来解决掉这些问题。
应急预案可按照如下几步进行:首先进行系统分级,然后进行全链路分析、配置监控报警,最后制定应急预案。
系统分级可以按照交易核心系统和交易支撑系统进行划分。
交易核心系统,如购物车,如果挂了,将影响用户无法购物,因此需要投入更多资源保障系统质量,将系统优化到极致,降低事故率。
而交易支撑系统是外围系统,如商品后台,即使挂了也不影响前台用户购物,这些系统允许暂时不可用。
实际系统分级要根据公司特色进行,目的是对不同级别的系统实施不同的质量保障,核心系统要投入更多资源保障系统高可用,外围系统要投入较少资源允许系统暂时不可用。
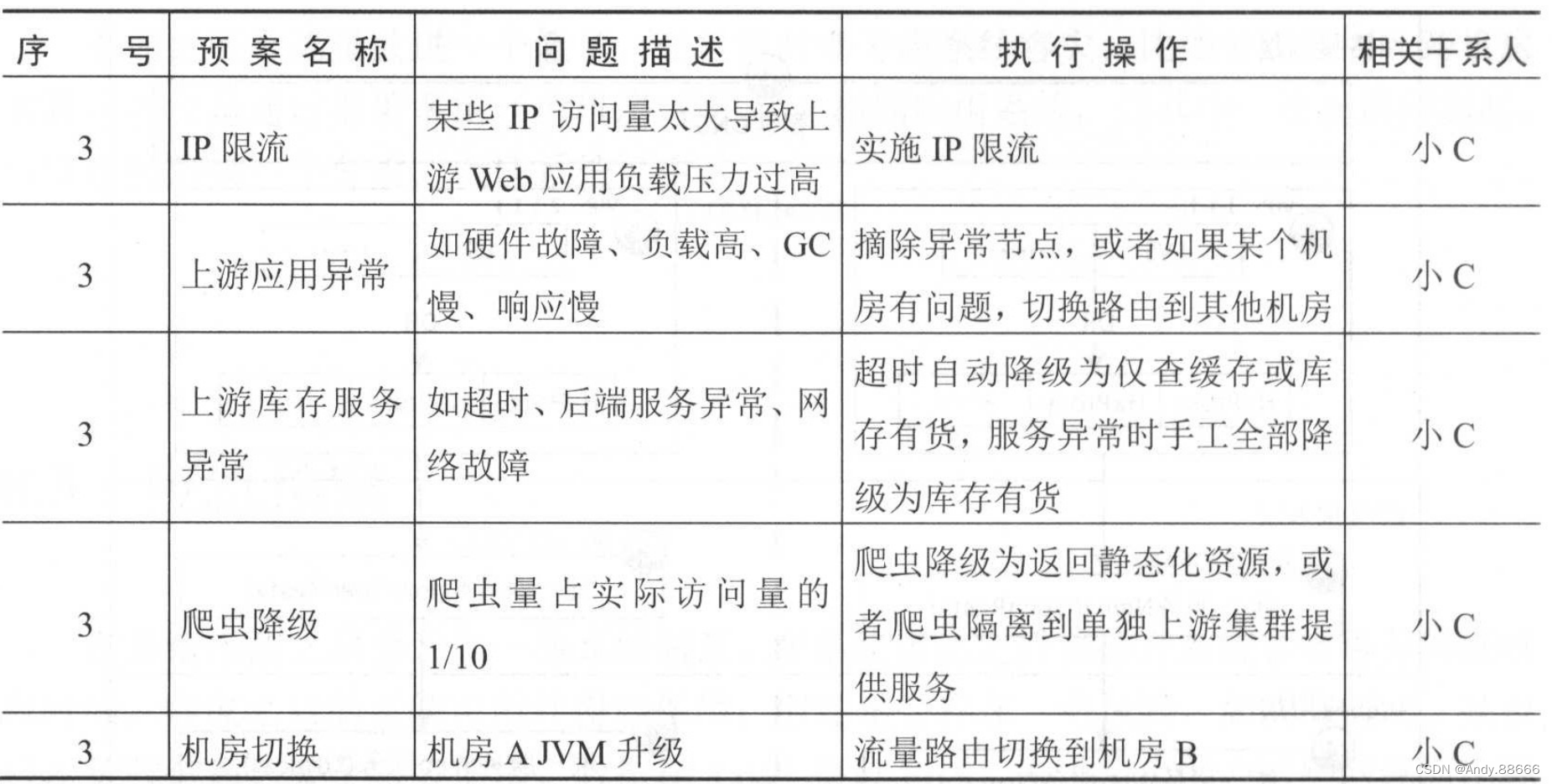
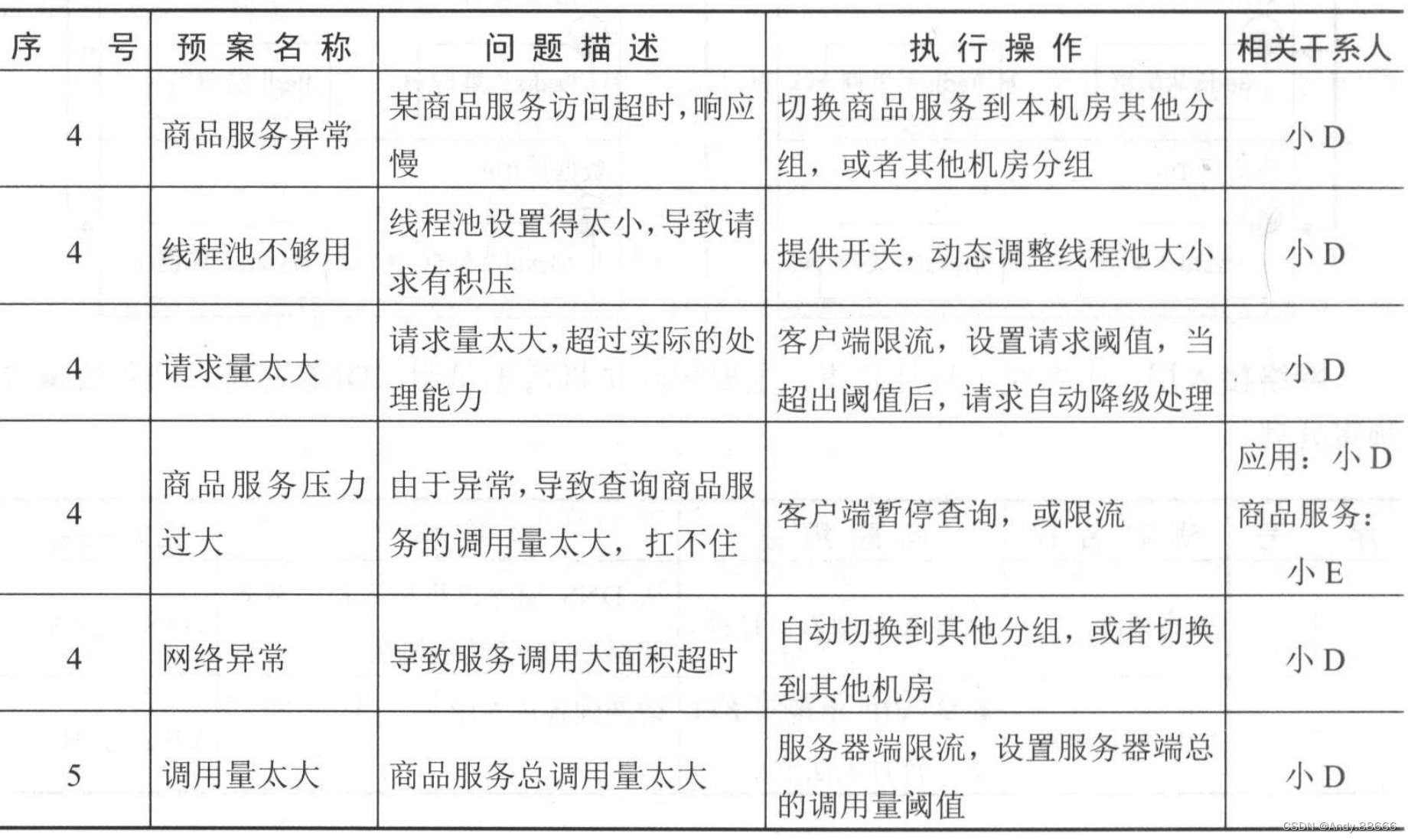
系统分级后,接下来要对交易核心系统进行全链路分析,从用户入口到后端存储,梳理出各个关键路径,对相关路径进行评估并制定预案。即当出现问题时,该路径可以执行什么操作来保证用户可下单、可购物,并且也要防止问题的级联效应和雪崩效应。
如下图所示,梳理系统全链路关键路径,包括网络接入层、应用接入层、Web应用层、服务层、数据层等,最后可以按照如下表格制定应急预案。
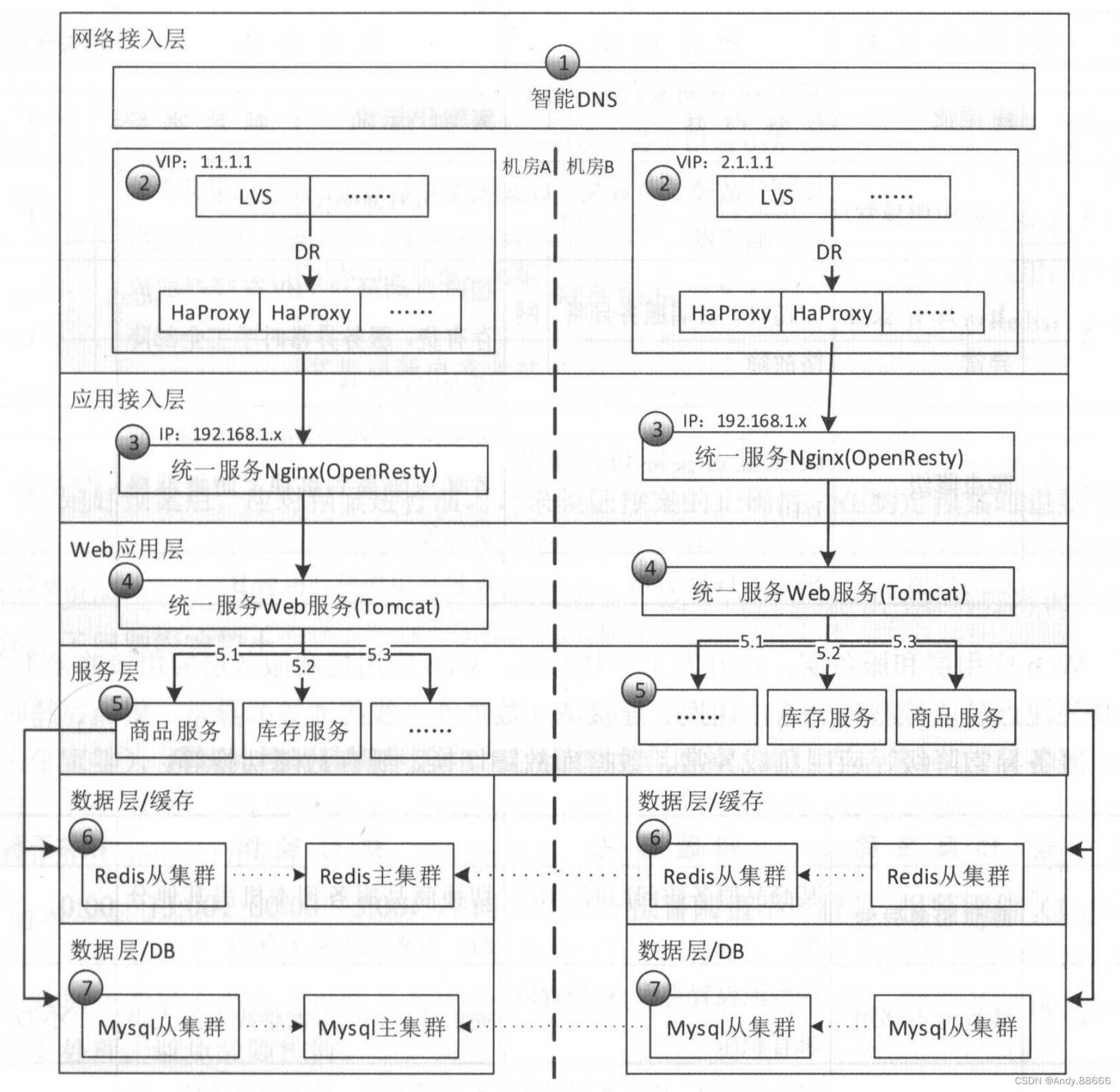
网络接入层

应用接入层
web应用层和服务层
数据层

制定好预案后,应对预案进行演习,来验证预案的正确性,在制定预案时也要设定故障的恢复时间。有一些故障如数据库挂掉是不可降级处理的,对于这种不可降级的关键链路更应进行充分演习。演习一般在零点之后,这个时间点后用户量相对来说较少,即使出了问题影响较小。
最后,要对关联路径实施监控报警,包括服务器监控(CPU使用率、磁盘使用率、网络带宽等)、系统监控(系统存活、URL状态/内容监控、端口存活等)、JVM监控(堆内存、GC次数、线程数等)、接口监控(接口调用量(每秒/每分钟)、接口性能(TOP50/TOP99/TOP999)、接口可用率等〕。
然后,配置报警策略,如监控时间段(如上午10:00—13:00、00:00—5:00,不同时间段的报警阈值不一样)、报警阈值(如每5分钟调用次数少于100次则报警)、通知方式(短信/邮件)。在报警后要观察系统状态、监控数据或者日志来查看系统是否真的存在故障,如果确实是故障,则应及时执行相关的预案处理,避免故障扩散。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!