2023 年中国高校大数据挑战赛 赛题 A 中文文本纠错
中文文本纠错的任务主要是针对中文文本中出现的错误进行检测和纠正,属于人工智能自然语言处理的研究子方向。中文文本纠错通常使用的场景有政务公文、裁判文书、新闻出版等,中文文本纠错对于以中文作为母语的使用者更为适用。基于此,本赛题主要选取中文母语者撰写的网络文本为校对评测数据,要求参赛者从拼写错误、语法错误、语病错误等多个方面考察中文文本纠错系统的自然语言理解能力和纠错能力。
【数据说明及其使用方法】
1、本次赛题选择网络文本作为纠错数据,要求参赛者从中检测并纠正错误, 实现中文文本纠错系统。数据中包含的错误类型有:拼写错误,包括别字和别词; 语法错误,包括冗余、缺失、乱序;语病错误,包括语义重复及句式杂糅。
2、本赛题提供的训练数据及验证数据见“数据集.zip”,训练集规模为 10 万
句,验证集规模为 1000 句。参赛队伍也可以使用公开数据集及其他开放型数据对模型进行训练。
3、训练数据使用方法:
训练数据文件中,每一行为一条训练数据,每一条训练数据为json格式,ID 字段为数据ID,source字:段为待纠正文本,target字段为纠正后的文本。
训练数据样例:
{"ID": "ID18423310", "source": "洛赞曾经看到安妮在她的头发上戴着一条红色缎带,并称这对她来说太“年轻化”,郡钩位骄傲小姐回答说:“我队伍中的人总是年轻”。", "target":?"洛赞曾经看到安妮在她的头发上戴着一条红色缎带,并称这对她来说太“年轻化”,这位骄傲的小姐回答说:“我的队伍中的人总是年轻”。"}
4、验证集使用方式:
具体的输入、输出格式如下:
输入:输入文件每行包含句子ID及相对应的待校对句子,句子ID及相对应的待校对句子之间用“\t”进行分割。
输出:输出文件每行包含句子ID及对应的纠错结果。纠错结果中每处错误包含错误位置、错误类型、错误字词及正确字词。每处错误及多处错误间均以英文逗号分隔,文件编码采用utf-8 编码。
输入文件示例:
pid=0011-1 关于瑞典时装公司拒绝使用新疆产品的言轮在华引发广泛
声讨和抵制浪潮。
pid=0011-2 给老百姓包括少数民族群众提供更多的就业机会,一般正常人都都会觉得是件好事。
pid=0012-1 第三局比赛俄罗女排的气势被完全压制。
pid=0011-4 因为他们自己上历史真的就这么干了上百年,所以现在以己度人;
输出文件示例,:
pid=0011-1, 20,?别字, 轮, 论, pid=0011-2, 28,?冗余, 都, , pid=0012-1, 7, ?缺失, , ?斯,
pid=0011-4, 6, ?乱序, ?上历史, ?历史上,
【相关评价标准】
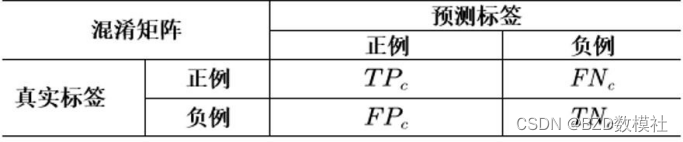
采用字级(Character Level)评价标准,基于整个测试集所有汉字的错误检测或纠正结果确定。错误检测(Error Detection)评估的是错误位置的侦测效果, 错误纠正(Error Correction)评估的是对应位置错误修正的效果。对于每个维度的评测,统一使用准确率(Precision)、召回率(Recall)和F1 作为评价指标。
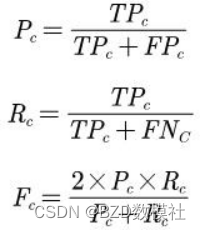
0 基于赛题提供的数据,请自主查阅资料,选择合适的方法完成如下任务: 任务一:分析数据集“train_large_v2.json”,自主进行数据预处理,选择合适
的指标用于中文文本纠错,并说明选择指标的原因。
任务二:根据赛题的描述,请分析问题,并对比业界主流的解决问题方案, 提出你的解决问题的思路,并设计相关模型。
任务三:使用任务二所构建的模型,对所提供的数据集进行模型训练,并纠正验证集中文本的中文错误。
任务四:对比分析优化过程中各个模型、训练方案的优劣势,自主选取评价方式和评价指标评估模型的优劣,并总结分析相关内容。
任务五:探究中文文本中每类错误的主要原因,找出相关的特征属性,并进行模式识别,挖掘可能存在的模式和规则。
补充说明:
1、开发语言不限,推荐使用python 3.8 及以上版本。
2、允许使用公开模型/开源代码,但需要在文档中注明出处。
3、除论文报告外,还需提供完整的程序代码、训练步骤、运行说明(包括依赖包、版本号)、模型文件及其他必要的佐证材料。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!