【Spark精讲】一文讲透Spark宽窄依赖的区别
2023-12-28 19:39:35
宽依赖窄依赖的区别
- 窄依赖:RDD 之间分区是一一对应的
- 宽依赖:发生shuffle,多对多的关系
- 宽依赖是子RDD的一个分区依赖了父RDD的多个分区
- 父RDD的一个分区的数据,分别流入到子RDD的不同分区
- 特例:cartesian算子对应的CartesianRDD,是通过创建了两个 NarrowDependency 完成了笛卡尔乘积操作,属于窄依赖。

窄依赖
搜索源码,RangeDependency只有UnionRDD使用到了
val rdd1 = sc.parallelize(List(("a",1),("b",2)))
rdd1.partitions.size
//val res4: Int = 2
val rdd2 = sc.parallelize(List(("c",3),("d",4),("a",1)))
rdd2.partitions.size
//val res5: Int = 2
val rdd3 = rdd1.union(rdd2)
//val rdd3: org.apache.spark.rdd.RDD[(String, Int)] = UnionRDD[3] at union at <console>:1
rdd3.partitions.size
//val res7: Int = 4
rdd3.foreach(print)
//输出结果为:(a,1)(b,2)(c,3)(d,4)(a,1)
宽依赖
情况一

举例:cogroup算子、join算子
功能:将两个RDD中键值对的形式元素,按照相同的key,连接而成,只是将两个在类型为(K,V)和(K,W)的 RDD ,返回一个(K,(Iterable<V>,Iterable<W>))类型的 RDD
//cogroup
val rdd1 = sc.parallelize(List(("a",1),("b",2)))
rdd1.partitions.size
//val res4: Int = 2
val rdd2 = sc.parallelize(List(("c",3),("d",4),("a",1)))
rdd2.partitions.size
//val res5: Int = 2
val newRDD = rdd1.cogroup(rdd2)
//val newRDD: org.apache.spark.rdd.RDD[(String, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[8] at cogroup at <console>:1
newRDD.foreach(println)
//(a,(Seq(1),Seq(1)))
//(c,(Seq(),Seq(3)))
//(d,(Seq(),Seq(4)))
//(b,(Seq(2),Seq()))
//join
val join = rdd1.join(rdd2)
//val join: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[11] at join at <console>:1
join.foreach(println)
//(a,(1,1))情况二
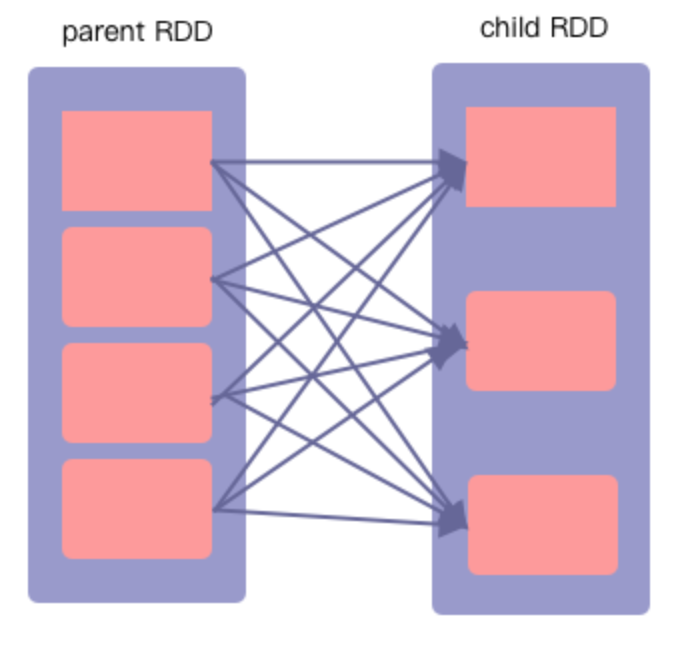
举例:groupByKey算子、reduceByKey算子
//groupByKey
val rdd = sc.parallelize(List(("a",1),("b",2),("a",1),("b",2)))
val groupRdd = rdd1.groupByKey()
//val groupRdd: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[16] at groupByKey at <console>:1
groupRdd.foreach(println)
//(b,Seq(2, 2))
//(a,Seq(1, 1))
//reduceByKey
val reduceRdd = rdd.reduceByKey(_+_)
//val reduceRdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[18] at reduceByKey at <console>:1
reduceRdd.foreach(println)
//(a,2)
//(b,4)
特例:cartesian算子
val rdd1 = sc.parallelize(List(("a",1),("b",2)))
rdd1.partitions.size
//val res4: Int = 2
val rdd2 = sc.parallelize(List(("c",3),("d",4),("a",1)))
rdd2.partitions.size
//val res5: Int = 2
val cartesianRdd = rdd1.cartesian(rdd2)
//val cartesianRdd: org.apache.spark.rdd.RDD[((String, Int), (String, Int))] = CartesianRDD[20] at cartesian at <console>:1
cartesianRdd.partitions.size
//val res24: Int = 4
cartesianRdd.foreach(println)
//((a,1),(c,3))
//((b,2),(c,3))
//((a,1),(d,4))
//((a,1),(a,1))
//((b,2),(d,4))
//((b,2),(a,1))
文章来源:https://blog.csdn.net/weixin_40035038/article/details/135271693
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!