Hadoop/HDFS/MapReduce/Spark/HBase重要知识点整理
本复习提纲主要参考北京大学计算机学院研究生课程《网络大数据管理与应用》课程资料以及厦门大学计算机科学系研究生课程 《大数据技术基础》相关材料整理而成,供广大网友学习参考,如有版权问题请联系作者删除:guanmeige001@pku.edu.cn
Part1 Hadoop
Hadoop简介
-
Hadoop的功能和作用:
-
高效地存储,管理,分析海量数据
-
Hadoop采用分布式存储方式, 提高了读写速度,并扩大了存储容量,通过冗余存储保证了安全性。MapReduce可以高效地分析和处理数据。
-
-
为什么不用关系型数据库加上更多磁盘来做大规模批量分析?
-
B树适合更新小部分数据,在更新大部分数据库数据的时候,B 树的效率没有 MapReduce 的效率高,因为它需要使用排序/合并来重建数据库。
-
MapReduce适合批处理,关系型数据库适合交互型访问和批处理
-
关系型数据是结构化的,MapReduce可以处理非结构化或半结构化数据
-
-
Hadoop的优点:
-
高容错性、高可靠性:通过冗余存储,维护多个数据副本,确保能处理节点崩溃的情况
-
高效性:通过并行处理加快数据处理速度
-
高可扩展性:在可用的计算机集群之内分配数据并完成计算任务,可以在节点之间动态迁移数据,集群大小可伸缩
-
低成本:依赖于廉价服务器
-
Linux平台,支持多种编程语言
-
-
缺点(GPT):
-
不适合交互式查询和实时数据处理
-
延迟高,不适合对延迟要求高的场景
-
冗余存储占用额外空间
-
Hadoop的结构
-
最底层是HDFS,存储Hadoop所有存储节点上的文件
-
上一层是MapReduce计算引擎(包括JobTrackers和TaskTrackers)
-
再上层是Pig,Hive等各种应用

Part2 HDFS
HDFS的优缺点
-
硬件出错:能快速恢复
-
流数据读写:假设程序是批量处理数据的,要求程序使用流读取来提高数据吞吐量。重视吞吐量而非响应速度
-
大数据集:文件通常是GB/TB级别
-
简单的文件模型:假设文件只有一次写入和多次读取。(适合搜索引擎)
-
强大的跨平台兼容性(基于Java实现,只要是JDK支持的平台都可兼容)
相应的问题:
-
满足不了低延迟
-
无法高效存储大量小文件(NameNode压力会增加)
-
不支持多用户写入同一个文件,以及在任意位置修改文件(只能进行追加操作)
基本概念
-
块:与文件系统的块(几百~几千byte)相比更大,默认为64MB,是文件存储和处理的逻辑单元
-
NameNode目录节点:维护和管理文件名,保存数据块和DataNode的的映射关系,通常由性能较好的机器负责
-
DataNode数据节点:存储数据块
-
默认副本数为3;一个文件存储的份数称为冗余因子,可以在文件创建时指定,之后再改
-
客户端向某个节点的写入 和 节点向其他节点的数据备份是pipeline进行的
-
DataNode定时向NameNode发送心跳表明存活,并发送数据块列表(包括了节点上所有数据块编号)
-
-
文件复制功能,除了提高容错性,还提高了服务的伸缩性scalability(多个client同时请求同一个文件时可以从多个副本处读取)
Part3 MapReduce
-
一个job会把数据切分成若干数据块,由map task并行地处理它们
-
框架包含1个JobTracker和一堆TaskTracker, JobTracker负责创建和提交任务
计算流程
-
Map阶段
-
输入:<k1, v1> 输出:一个或多个<k2, v2>
-
相同key的输出会被分发到同一个reducer
-
map的输出系统会先自动排序,然后发给reducer
-
-
Reduce阶段
-
输入:<k2, list{v2}> 输出:<k3, v3>
-
-
Combine阶段:可以将map的结果先进行一次合并
-
类似提前做一次reduce操作
-
Combine的输出是reduce的输入,一定得保证正确性(通常用于reduce的输入输出类型相同的场景,例如求max, sum等等)
-
-
Partition&Shuffle阶段
-
Shuffle指把map的输出移动到reducer的过程
-
Partitioner负责决定Map阶段产生的<k, v> pair发送到哪个Reducer,默认情况下用key的hash值来分配
-

伪代码
Wordcount
word count (baseline):
class MAPPER
?method MAP(docid a, doc d)
? ?for all str word in d do
emit (word, 1)
?
class REDUCER
?method REDUCE(str word, counts[c1, c2, ...])
sum ← 0
? ?for all count in counts do
sum ← sum + c
? ?emit (word, sum)
word count (in-mapper combine):
-
比combiner更高效,因为combiner的执行次数是不一定的
-
主要是在初始化mapper的时候弄一个关联数组,
class MAPPER
?method INIT()
H ← new ASSOCIATIVEARRAY
?method MAP(docid a, doc d)
? ?for all str word in d do
H[t] ← H[t] + 1
method CLOSE
?for all str t in H.keys() do
? ?emit (t, H[t])
?
class REDUCER
?method REDUCE(str word, counts[c1, c2, ...])
sum ← 0
? ?for all count in counts do
sum ← sum + c
? ?emit (word, sum)
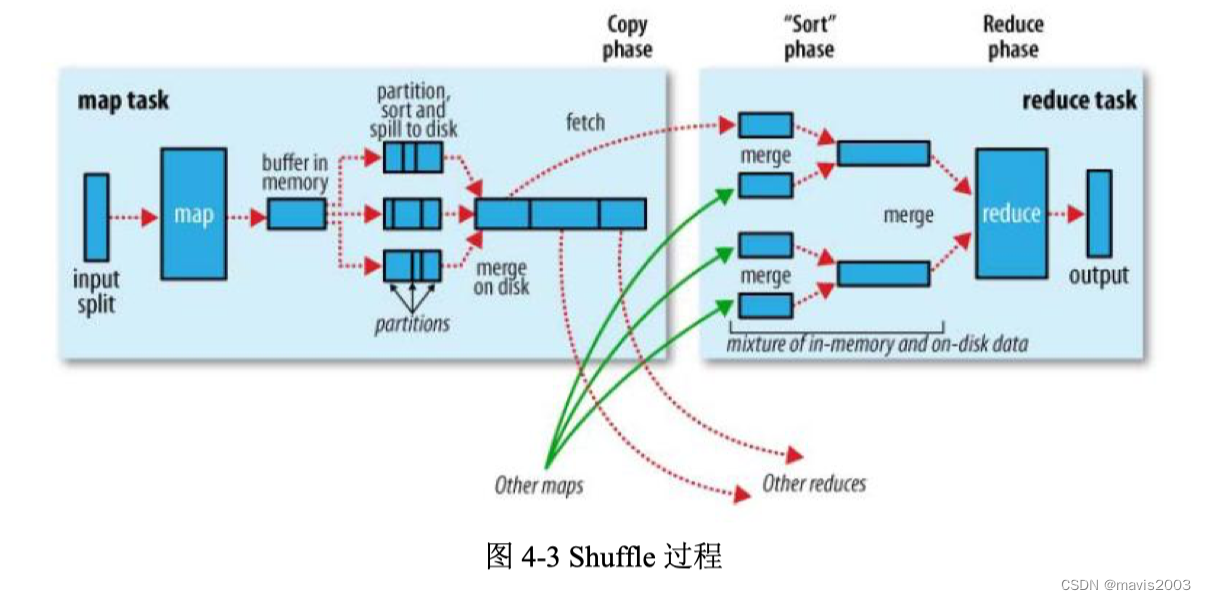
Shuffle实现细节
-
Mapper端
-
mapper端有一个memory buffer, 每次buffer达到一定阈值(如80%)时先排序,然后向磁盘溢写(spill),最终在disk上形成很多个段。
-
在发送给reducer之前,要对相同key的段进行merge,这里如果有combiner也可以先combine
-
-
Reducer端
-
不断从各个map task拉取最终结果,对来自不同的mapper的结果做合并,
-
首先请求map task所在的TaskTracker获取map task的输出文件
-

新框架Yarn
-
即新版本Mapreduce采取的MapreduceV2架构
-
将JobTracker两个主要功能分离为单独的组件:资源管理+任务调度/监控
-
原框架中核心的 JobTracker 和 TaskTracker 不见了,取而代之的是 ResourceManager、ApplicationMaster 与 NodeManager 三个部分
-
container类似于机器的概念
-
ResourceManager:
-
ResourceManager中心化地进行job和资源的调度——一部分JobTracker功能
-
负责接收 JobSubmitter 提交的作业,调度、启动每一个 Job 所属的 ApplicationMaster,并且监控 ApplicationMaster 的存在情况。
-
-
NodeManager:负责Container状态的维护,并向ResourceManager发送心跳。
-
ApplicationMaster:
-
负责监控task的运行情况——另一部分JobTracker功能
-
负责一个 Job 生命周期内的所有工作,每一个 Job都有一个 ApplicationMaster, 它可以运行在 ResourceManager 以外的机器上。用户可以自己配置
-
-
Part4 Spark
Spark简介
-
开源的分布式并行计算系统
-
支持迭代算法、交互式数据分析
-
思想:内存集群计算
-
实现:scala语言
Spark与Mapreduce对比
-
Mapreduce每次读写都需要序列化到磁盘,一个复杂任务需要几十次磁盘读写;Spark只需要一次磁盘读写,大部分处理在内存中进行
-
Spark的优势:
-
部分场景下性能比Mapreduce快很多
-
小数据集:可以达到亚秒级延迟
-
大数据集:迭代类应用快10~100x
-
-
提供比Hadoop更高层的API,算法实现代码量低(1/10或1/100)
-
比Hadoop更通用,有map和reduce之外的更多操作(transformations、actions两大类操作);节点之间的通信模型不像hadoop只有shuffle一种模式;可以控制中间结果的存储和分区等
-
兼容Hadoop存储API,支持读写所有hadoop支持的系统,如HDFS, Hbase等
-
容错性:checkpoint机制
-
可用性:scala, java, python API
-
基本概念
-
RDD: 弹性分布式数据集(Resilient Distributed Dataset),是分布式内存的一个抽象概念,提供一种高度受限的共享内存模型
-
DAG: 有向无环图, 反映RDD之间的依赖关系
-
Executor: 运行在工作节点上的一个进程,负责运行task
-
task:运行在executor上的工作单元
-
Job: 包含多个RDD以及对他们的各种操作
-
Stage: 作业的基本调度单位,一个job分为多个stage, 一个stage包括一组task,互相之间有一定关联且没有shuffle依赖关系
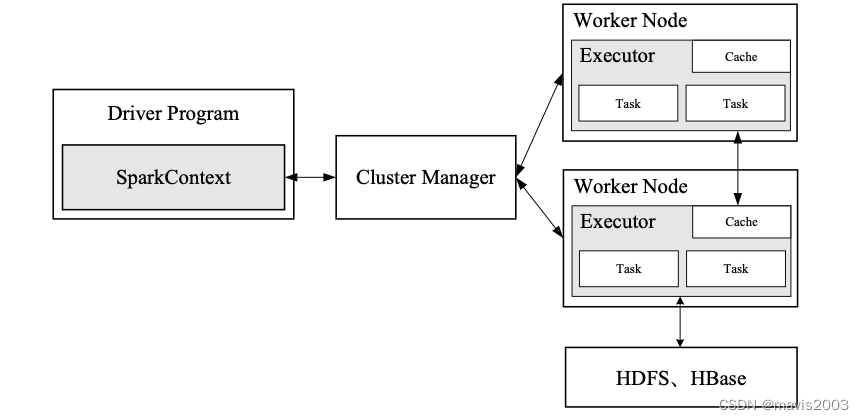
运行架构
-
集群资源管理器cluster manager: master节点,指在集群上获取资源的外部服务,有以下几种
-
standalone:spark原生的资源管理,由master负责资源管理
-
Yarn:由yarn中的resource manager负责资源管理
-
Mesos: 由Mesos的Mesos Master负责资源管理
-
负责给executor分配资源并启动executor进程
-
-
工作节点worker node:worker节点,每个节点包含一个executor用于执行任务
-
standalone中指的是worker
-
spark on yarn模式中指的就是NodeManager
-
Executor(执行进程):负责运行task并将数据存在内存或磁盘上,每个application都有一批自己的executor.
-
-
任务控制节点driver: 运行application的main()函数并给任务创建一个SparkContext
-
DAGscheduler:运行在driver节点上,sparkContext根据RDD的依赖关系构建DAG图,DAG图交给DAGScheduler形成stage划分,并提交给taskScheduler
-
taskScheduler: 把任务分发给worker节点执行
-
RDD
-
RDD的特点:在集群节点上不可变的、已分区的数据对象,是可序列化的(可以溢写到磁盘),是静态类型的
RDD是Spark的最基本抽象
-
只能从持久化存储或通过transformations操作产生,相比于分布式共享内存(DSM)可以更高效地实现容错性,不一定要使用checkpoint,丢失的分区可以通过lineage计算出来
-
RDD的不变性使得它可以实现类似Mapreduce的推测式执行
-
当某个机器运行很慢的时候,可以在另一台机器上并行地重新执行该任务,取先执行完的结果
-
-
RDD分区的特点可以通过数据的本地性来提高性能
-
与分布式共享内存(DSM)的区别:
-
DSM需要通过checkpoint来恢复,RDD可以通过lineage来计算丢失的分区
-
RDD是批量处理,最细粒度是哈希或范围分区,不能像DSM一样精确地读写某个内存位置
-
-
RDD有两种类型的操作,transformations和actions
-
transformations: map, filter, groupby, join。并不马上执行,直到遇到actions再真正执行
-
Actions: count, collect, save
-
actions返回某个结果或把结果写到存储系统中,是触发spark计算的动因
-
-
lineage:DAG拓扑排序的结果
-
spark不适用的场景:
-
无法支持细粒度、异步更新的操作
-
比如图计算
-
还有需要细粒度的日志更新和数据checkpoint的应用
-
容错机制
-
总结:基于lineage,也可以指定checkpoint
宽依赖和窄依赖
-
窄依赖:父亲RDD的分区只会对应子RDD的一个分区,没有shuffle操作
-
宽依赖:父亲RDD的分区对应子RDD的多个分区,涉及shuffle操作
-
如果有宽依赖:重新计算某个子RDD的某分区时,其父RDD对应到子RDD其他分区的部分也会被重新计算,造成了冗余的计算;此外一个子RDD通常对应多个父RDD,这就意味着其他父RDD也得重新计算
-
如果是窄依赖,就直接pipeline地计算所有父分区就行了,不用shuffle,效率很高
-
通常把尽量多的窄依赖划分到同一个stage里
Part5 HBase
HBase简介
-
HBase=Hadoop Database
-
高可靠,高性能,面向列,可伸缩的分布式存储系统
-
表通常非常大,可以很稀疏(空的列不占据存储空间)
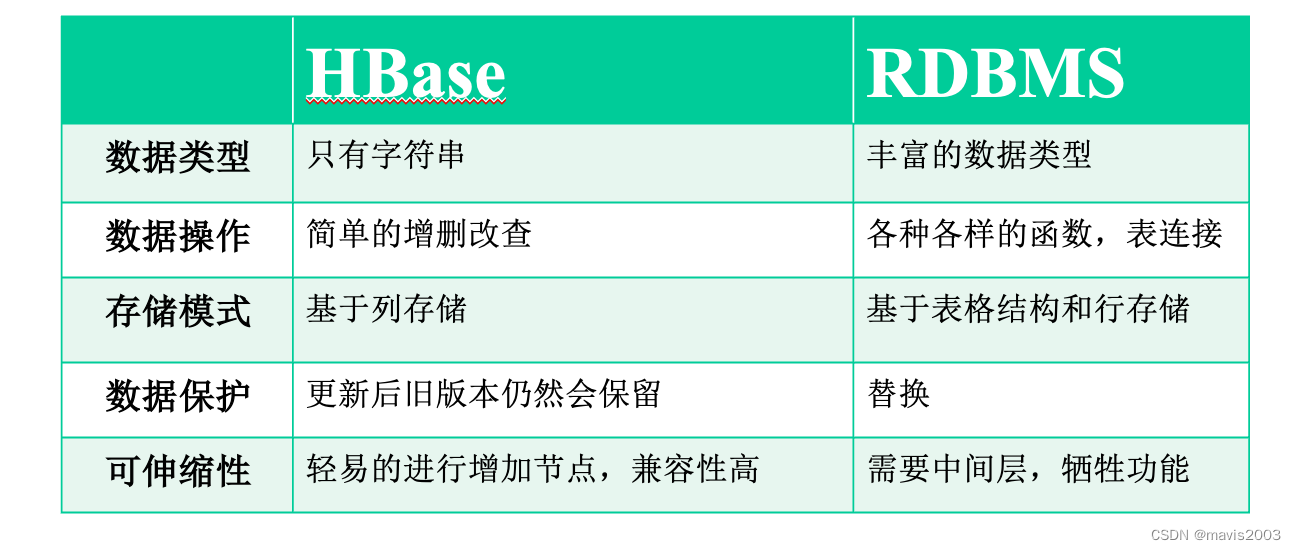
与传统关系型数据库对比
-
数据类型:HBase只有字符串类型,关系数据库有多种类型
-
数据操作:HBase操作简单,只有插入、查询、删除、清空操作;表和表之间没什么关系,不需要实现表的连接等操作;关系型数据库有函数、连接操作
-
存储模式:HBase基于列存储;关系数据库基于表格结构和行模式存储
-
数据维护:HBase更新数据时是插入新版本而不删除旧版本,关系数据库是替换修改
-
可伸缩性:HBase可以轻易地增减硬件数量(主要是为了处理硬件错误的情况),容错性高;关系型数据库需要增加中间层才能实现类似的功能
-
HBase更适合海量存储和互联网应用的需求(互联网应用是以字符为基础的)
以下内容来自GPT3.5:
NoSQL(Not Only SQL)数据库是一类非关系型的数据库管理系统,它们采用了不同于传统关系型数据库的数据存储模型。NoSQL 数据库的出现主要是为了解决传统关系型数据库难以应对大规模、高并发、分布式环境下的数据存储和处理需求。
NoSQL 数据库通常具有以下特点:
- 灵活的数据模型:与固定的表结构相比,NoSQL 数据库通常采用灵活的数据模型,如文档型、键值对、列族、图形等,能够更好地适应不同类型和格式的数据。
- 横向扩展性:NoSQL 数据库设计时考虑了横向扩展的可能性,可以方便地增加节点来处理更大规模的数据和更高的并发请求。
- 高性能:针对特定的使用场景进行了优化,能够提供较高的读写性能和低延迟。
- 分布式架构:NoSQL 数据库天生支持分布式架构,能够在多个节点上分布存储和处理数据。
NoSQL 数据库种类繁多,包括文档型数据库(如 MongoDB)、键值对数据库(如 Redis)、列存储数据库(如 HBase)、图形数据库(如 Neo4j)等。每种类型的 NoSQL 数据库都有自己的特点和适用场景。
总的来说,NoSQL 数据库旨在通过提供更灵活、高性能、可伸缩的数据存储和处理解决方案,满足当前互联网时代大规模数据应用的需求。它们在大数据、实时分析、高并发访问等方面有着广泛的应用。
HBase数据模型
-
Hbase的写操作是锁行的,可以按行加锁,每一行有一个时间戳
几个重要概念
-
行键
-
Hbase表的主键,表中的记录根据行键排序
-
可以通过单个行键/行键区间范围/全表扫描访问行
-
-
列族
-
每个列都属于某个列族
-
列族是表的结构的一部分,必须在使用表之前定义;列名可以自己定义
-
-
时间戳
-
通过行和列确定的一个存储单元称为cell,每个cell都有同一数据的多个版本,
-
概念视图

物理视图
按列存储,空白区域不存,请求会返回null
不同列族的数据会存储在不同文件中;同一列族的数据在一个文件内,按行键从小到大排序,同一行的数据按列键排序

HBase的实现
-
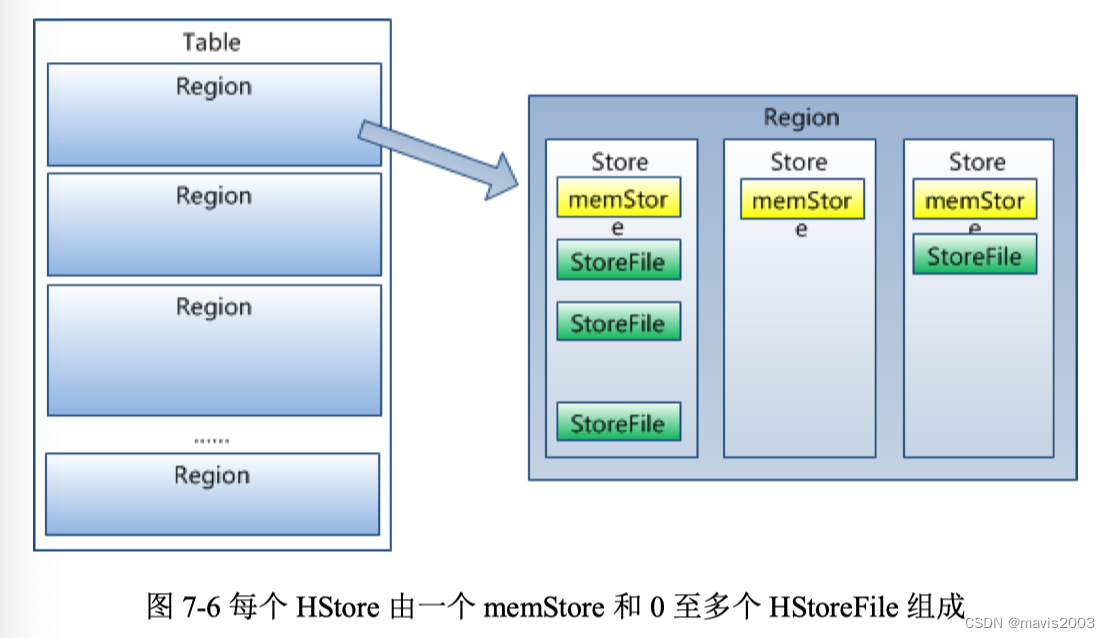
HRegion
-
每个表由一个或多个HRegion组成
-
每个HRegion包含了一段key区间内的很多行,内部也按照行键的字典序排列
-
一开始每个表只有一个HRegion,随着表的增大,HRegion会自动分裂成多个HRegion
-
HRegion是分布式存储的最小单元,但不是物理存储的最小单元,HRegion由多个HStore组成,每个HStore又包含一个memStore和零至多个StoreFile
-
-
HRegion的定位
-
Zookeeper file-ROOT-META-table
-
Zookeeper file记录了ROOT表的位置信息,ROOT表(只有一个root region)记录了meta表的region信息,meta表记录了用户表的HRegion信息
-

-
中间需要多次网络操作,client表会进行缓存?
-

-
server分为两种,master server和region server,主从式结构
zookeeper是一个cluster,会跟每个region server保持心跳联系,master server定时向zookeeper轮询状态
大数据管理系统
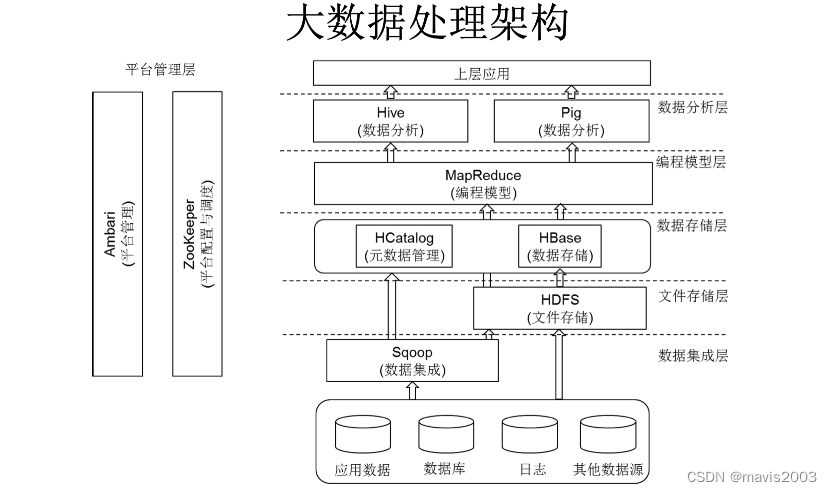
(以下由GPT4生成)
这张图展示的是一个典型的大数据管理系统架构,主要基于Apache Hadoop生态系统。这样的系统设计通常涉及以下几个关键组件和它们之间的交互:
-
数据存储:HDFS(Hadoop分布式文件系统)是基础,用于存储大量数据。它具备高容错性、高可靠性,并且能够存储和处理大量分散的数据。
-
数据处理:MapReduce是一个编程模型,用于处理和生成大数据集。它能够在分布式环境中并行处理大量数据。
-
数据访问:Hive和Pig提供数据仓库功能,允许用户使用类SQL语言(HiveQL)和脚本语言(Pig Latin)进行复杂的数据分析和处理。
-
实时/随机访问:HBase是建立在HDFS之上的非关系型分布式数据库,它支持实时的数据访问。
-
数据集成:Sqoop是用于在关系型数据库和Hadoop之间传输数据的工具,而HCatalog允许用户使用统一的表格视图访问位于不同数据处理工具中的数据。
-
协调服务:ZooKeeper是一个为分布式应用提供一致性服务的软件,它用于维护配置信息、命名、提供分布式同步以及提供组服务。
-
管理监控:Ambari是用于监控和管理Hadoop集群的工具,提供了集群的安装、配置和维护功能。
从设计思路上看,这种架构的目的是为了处理大规模数据集,并提供高效的存储、快速处理、灵活的数据访问以及方便的管理监控功能。一个成功的大数据管理系统应该能够确保扩展性、高性能、容错性和数据一致性。
这样的设计也是模块化的,允许在不同的层面进行优化和定制,以满足特定的业务需求。例如,对于需要快速读写访问的应用场景,可以选择使用HBase。而对于需要复杂数据分析的场景,可以选择使用Hive。
整体上,设计大数据管理系统时,需要考虑数据的来源、大小、处理速度和使用方式,以及系统的可维护性、扩展性和安全性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!