ENVI IDL:如何提高程序运行效率?
前言
最近突然(并不是)想深入了解IDL底层的一些原理,因此记录一下感受和体会。
给出问题
例如下方题目:
; 问题
arr = findgen(10240, 10240)
for x=0, 10240 - 1 do begin
for y=0, 10240 - 1 do begin
arr[x, y] = arr[x, y] mod 2
endfor
endfor
请问如何提升这段程序性能?
如下是程序运行的时长:

探索问题
数组运算
这当然是非常极易想到的,操作如下:
; 数组运算
start_time = systime(1)
arr = findgen(10240, 10240)
arr = arr mod 2
end_time = systime(1)
print, end_time - start_time, format='数组运算-用时: %0.2f s'
效率提升如下:
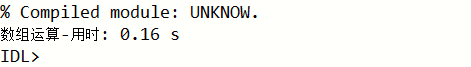
并行运算
当然,我们在不考虑改变时间复杂度和空间复杂度的情况下,如何提升效率?很自然会想到并行处理,这也确实是一个法子。但是很显然对于这种数组逐元素的计算,即便算式稍微复杂如此也是得不偿失,因为进程的创建、销毁等消耗的时间几乎与当次循环中的实际计算时间相当。
由于博客使用IDL88(ENVI5.6),因此实际上并不兼容并行运算,所以会遇到===% Unable to start IDL_IDLBRIDGE worker process: 管道已结束。===
因此此处仅仅简单做了处理如下:
function _mod, value
return, value mod 2
end
pro unknow
; 多线程运算
start_time = systime(1)
core_n = 24
arr_count = 0L
arr = findgen(20, 20)
arr_n = size(arr, /n_elements) - 1
process_arr = objarr(core_n)
for process_n = 0, core_n - 1 do process_arr[process_n] = obj_new('idl_idlbridge')
process_status = make_array(core_n, value=0, /integer) ; 0表示结束, 1表示进程仍在进行
repeat begin
for core_ix = 0, core_n - 1 do process_status[core_ix] = process_arr[core_ix].status()
child_ixs = where(process_status eq 0, child_n)
if child_n eq 0 then continue
foreach child_ix, child_ixs do begin
cur_process = process_arr[child_ix]
cur_process.setvar, 'value', arr[arr_count]
cur_process.execute, 'new_value = _mod(value)', /nowait
arr_count++
endforeach
endrep until (arr_count eq arr_n)
end_time = systime(1)
print, end_time - start_time, format='并行运算-用时: %0.2f s'
end
但是因为时间和版本关系,我并没有从进程中取值,因此代码仅供参考。
CPU缓存机制
这里先给出改进,然后说明原因。
我仅仅修改行列索引的读取顺序,代码如下:
start_time = systime(1)
arr = findgen(10240, 10240)
for x=0, 10240 - 1 do begin
for y=0, 10240 - 1 do begin
arr[y, x] = arr[y, x] mod 2 ; 按行访问
endfor
endfor
end_time = systime(1)
print, end_time - start_time, format='按行访问-用时: %0.2f s'
计算时间如下:

仅仅调换了行列的读取顺序,速度由原来的18s提升了7s。
这里就需要说明了,CPU中的缓存机制,由于CPU是高性能运算,但是如果CPU直接从内存中读取数据,那么相对于CPU而言,内存的效率还是太慢了。
例如内存的数据传送到CPU上需要10s,但是CPU计算仅仅需要0.1s,这就意味着CPU的大量时间都是处于闲置状态。
因此,在CPU和内存之间又建立了缓存机制,如下:
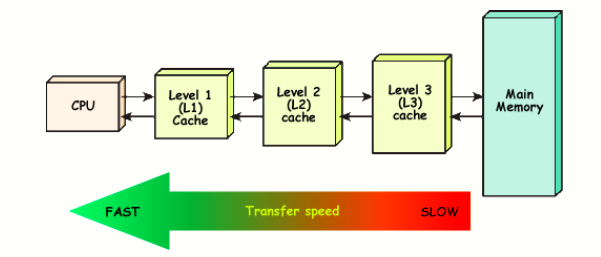
CPU一般现在都有三层缓存机制,L1Cache速度最快,L3Cache速度在三者中速度最慢(但也不是内存可以相比的),与此相比的L1Cache的容量也最小(可以临时存储的数据量)。
CPU是先从缓存 L1 ? L2 ? L3Cache缓存中找数据,如果找到,那么直接Cache中获取数据到CPU计算;如果没有找到,再从内存中寻找数据,并把数据存放在Cache中,以便提高下次访问的效率。
所以,上述中,直接在Cache中找到称之为Cache命中(Cache Hit),没有在Cache中找到称之为Cahce未命中(Cahce Miss)。
那么为什么通过调换行列顺序的读取就可以提高上述数组运行的效率呢?
因为,IDL的数组是列优先(查看: https://www.nv5geospatialsoftware.com/docs/columns__rows__and_array.html),但是大部分列优先是基于第一维度是行而第二维度是列而设置的优先,因此虽然IDL数组是列优先,但是它实际上第一维度是列而第二维度是行。
因此实际上按行读取会得到更多Cache命中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!