数据库设计——DQL
D
Q
L
\huge{DQL}
DQL
?????
DQL:数据库查询语言,用来查询数据库中的记录,非常的重要,对于数据库的操作修改相对来讲还是较少部分,绝大多数操作都是数据查询。
整体的语法结构:

基本查询

示例:
-- ---------------DQL基本查询-----------------
-- 1. 查询指定字段 name,entrydate 并返回
select name,entrydate from tb_emp;
-- 2. 查询返回所有字段
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp;
-- 不推荐(性能低)
select * from tb_emp;
-- 3. 查询所有员工的 name,entrydate,并且起一个别名
select name as 姓名,entrydate as 入职日期 from tb_emp;
select name 姓名,entrydate 入职日期 from tb_emp;
-- 4. 查询已有的员工关联了哪几种职位(不要重复)
select distinct job from tb_emp;
?注意事项:
- distinct关键字用来去重
- 如果要查询表中所有字段的数据,最好还是将所有的字段都列一遍。使用 * 的表示法效率比较低(底层实现问题)。
条件查询
有了限制条件的查询(where)

常见的条件关系表:
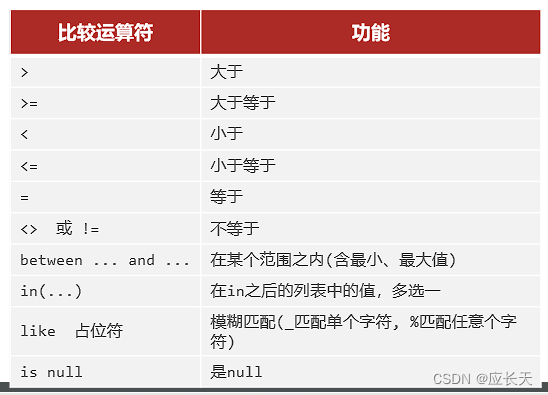
???注意:
- 注意相等的匹配符号,不是其他编程语言中的"==“,而是”="。
- 如果判断一个字段是不是空,不是用" = null",而是"is null"
- 模糊匹配很重要
示例:
-- ------------------DQL条件查询------------------
-- 1. 查询姓名为夜神月的员工
select * from tb_emp where name = '夜神月';
-- 2. 查询ID小于等于5
select * from tb_emp where id <= 5;
-- 3. 查询没有分配职位的员工信息(职位为空)
select * from tb_emp where job is null;
-- 4. 查询有职位的员工信息(职位不为空)
select * from tb_emp where job is not null;
-- 5. 查询密码字段不是'123456'的员工信息
select * from tb_emp where password != '123456';
select * from tb_emp where password <> '123456'; -- <>也是不等于
-- 6. 查询入职日期在’2000-01-01‘(包含)到’2010-01-01’(包含)之间的员工信息
select * from tb_emp where entrydate >= '2000-01-01' and entrydate <= '2010-01-01';
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';
-- 7. 查询入职时间在'2000-01-01'(包含)到‘2010-01-01’(包含)之间并且性别是女的员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2;
-- 8. 查询职位是2(讲师),3(学工主管),4(教学主管)的员工信息
select * from tb_emp where job = 2 or job = 3 or job = 4;
select * from tb_emp where job in (2,3,4);
-- 9. 查询姓名为两个字的员工信息
select * from tb_emp where name like '__';
-- 10. 查询姓张的员工
select * from tb_emp where name like '张%';
💥💥💥💥上述代码中的一些细节和其他实现方式:
- 判空is null,判非空 is not null
- <>也是不等于的意思
- 关于between and:and左边是最小值,and右边是最大值,并且这个范围是闭区间。
- 多值判断可以用in (范围值集合)
- 模糊匹配中:一个
_就代表一个字符。一个%代表任意多的字符,所以’张%'的意思就是以’张’为开头,任意长度的名字。
分组查询
分组查询就是将已知的数据进行分组,然后可能会求组内的整体数据特征。首先要先知道怎么求一些整体数据特征,DQL中的聚合函数可以完成这个任务。


常见的聚合函数:
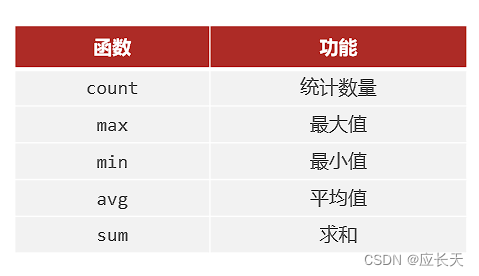
示例:
-- 聚合函数
-- 1. 该企业员工的数量 -- count
-- A.count(字段)
-- count字段的时候是不计数null,所以count求所有记录的个数的时候要count一个非空的字段
select count(id) from tb_emp;
select count(username) from tb_emp;
select count(job) from tb_emp;
-- B.count(常量)
select count('A') from tb_emp;
-- C.count(*)
-- mysql底层对于count(*)做了优化处理,建议使用count(*)
select count(*) from tb_emp;
-- 2. 统计最早入职的员工 -min
select min(entrydate) from tb_emp;
-- 3. 统计最迟入职的员工 -max
select max(entrydate) from tb_emp;
-- 4. 统计该企业员工的ID的平均值 -avg
select avg(id) from tb_emp;
-- 5. 统计该企业员工的ID之和 -sum
select sum(id) from tb_emp;
???代码细节:
- 求记录个数的时候最好用count(*),底层有优化,效率更高
- ???数据表中的null不会参与聚合函数的运算,如果要求数据中的记录总数记得count(非空字段)
分组查询

???注意一下group by的位置,是放在了where之后
示例:
-- 分组查询
-- 1. 根据性别分组,统计男性和女性员工的数量 -count(*)
select gender,count(*) from tb_emp group by gender;
-- 2. 查询入职时间在‘2015-01-01’(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
-- where 之后不能用聚合函数,分组过滤的过滤条件就写在 group by 之后
select job,count(*) from tb_emp where entrydate <= '2015-01-01' group by job having count(*) >= 2;
-- where 与 having 之间的区别
-- 1. 执行时机不同:where是分组之前进行过滤,不满足where条件都不会参与分组,而having后面的条件是对结果进行过滤
-- 2. 判断的条件不同:where不能对聚合函数进行判断,但是having可以
-- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段没有任何的意义
-- 执行顺序:where > 聚合函数 > having
解析以下这段代码(个人理解)
select gender,count(*) from tb_emp group by gender;
意思为再tb_emp表中按照gender进行分组,最后表的列有两列,一列是gender,另一列是对应gender下的成员的个数。
查询结果:
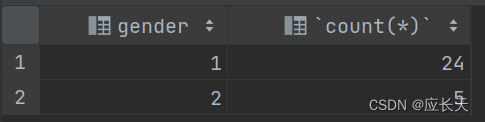
也就是说聚合函数是在group by分组之后才会发生作用,分别求每个组中的成员个数。
??where与having的区别(大重点):
- 执行的时机不同:where是在分组之前进行过滤,不满足where后条件的数据连分组都不会参与。而having是对分组之后的数据进行筛选。
- 判断条件不同:where后面无法跟聚合函数,但是having后面可以跟聚合函数。
- 更多细节:分组之后一般查询的字段就是聚合函数。因为如果分组之后还查询某个数据为什么不一开始就直接查某个数据呢?
语句执行的顺序: where > 聚合函数 > having
排序查询

排序方式就下面两种

示例:
-- 排序查询
-- 1. 根据入职时间,对员工进行升序排序 -asc
select * from tb_emp order by entrydate asc;
select * from tb_emp order by entrydate;
-- 2. 根据入职时间,对员工进行降序排序
select * from tb_emp order by entrydate desc;
-- 3. 根据入职时间,对公司的员工进行 升序排序, 入职时间相同,再按照更新时间进行 降序排序
select * from tb_emp order by entrydate , update_time desc;
-- 只有当第一个字段相同的时候,第二个字段的排序才会生效
???如果多字段查询,当第一个字段相同的时候,才会按照规定的第二个字段的排序顺序进行排序。
select * from tb_emp order by entrydate , update_time desc;
当entrydate相同的时候才会按照update_time的降序进行排序。
还有,排序默认是按照升序进行排序。
分页查询

这种查询的理解就是网站中的翻页功能。数据量太大的时候不可能直接将所有的数据全部一次性加载到网页中,可以一页一页的加载,当前浏览哪一页就查询哪一页的数据。

示例:
-- -----------分页查询-------------
-- 1. 从起始的索引0 开始查询员工数据,每页展示5条记录
select * from tb_emp limit 0,5;
-- 2. 查询第一页员工数据,每页展示5条数据
-- 3. 查询第二页员工数据,每页展示5条数据
select * from tb_emp limit 5,5;
-- 4. 查询第三页员工数据,每页展示5条记录
select * from tb_emp limit 10,5;
-- 起始索引计算公式:起始索引 = (页码 - 1)* 每页展示记录数
limit后面两个参数的通俗理解
起始索引:查询的起始位置
查询记录数:每页展示多少数据
limit 10,5:从10索引开始查询,每页显示5条数据。
?????起始索引计算公式
起始索引
=
(
页码
?
1
)
?
每页展示数据数
起始索引 = (页码 - 1) * 每页展示数据数
起始索引=(页码?1)?每页展示数据数
(索引是从0开始算的)
附带两个SQL函数
if表达式
if(表达式,tvalue,fvalue):表达式为true时,值为tvalue。表达式为false时,值为fvalue
case表达式
case 表达式 when 值1 then 结果1 when 值2 then 结果2 ... else .. end
类似于switch语句
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!