BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【1】
2024-01-02 15:13:36
预训练模型:A pre-trained model is a saved network that was previously trained on a large dataset, typically on a large-scale image-classification task. You either use the pretrained model as is or use transfer learning to customize this model to a given task.
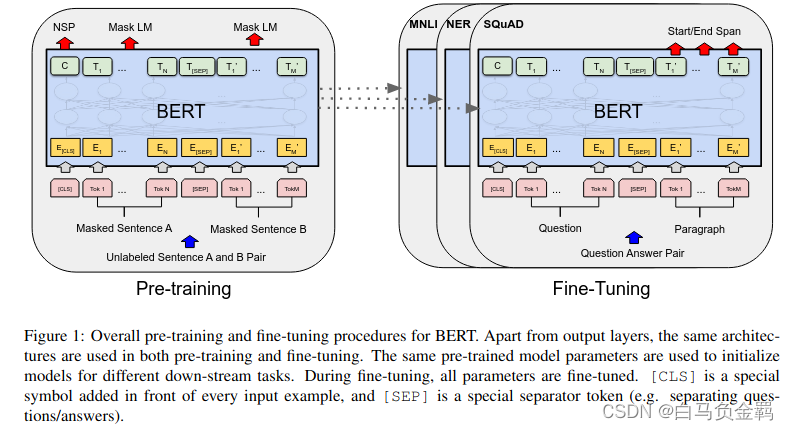
BERT是Google提出的一个基于Transformer的自然语言处理领域的预训练模型。它之所以被称为这个名字,一方面它是Bidirectional Encoder Representations from Transformers首字母的缩写。另一方面,还是为了致敬之前的一个模型ELMO。《Sesame Street》是由美国芝麻街工作室制作的一档儿童教育电视节目,其中的两个卡通人物分别是ELMO和BERT,如下图所示。

ELMO的基本概念就是利用上下文信息来生成一个单词的表达/Embedding(Contextualized word represen
文章来源:https://blog.csdn.net/baimafujinji/article/details/135337389
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!