一个例子带你入门影刀编码版(三)
2023-12-13 13:47:54
摘要
将通过一个电商业务场景下的真实需求,带领大家零基础入门影刀编码版,本系列将会分三步讲解,从接到需求到最后完成发版,整个过程中我们需要做些什么?带你们走一个完整开发流程。
接前文
《影刀自动化采集底层逻辑》
《一个例子带你入门影刀编码版(一)》
《一个例子带你入门影刀编码版(二)》
代码整合思路
前面从需求拆分到模块,把每个模块都实现了,下面把每个模块组合起来封装成可执行程序,前面为了帮大家把基本功能都过一遍,有一些冗余,封装时候会考虑去掉
精简后代码结构规划:
- 主流程调用
- 分两个,抓全店在售ID
- 按ID去转宝贝详情信息
设计思路和原理
- 从业务场景出发,这可以是两个独立需求,一是我想要知道在售商品有哪些,一个是我想知道某些宝贝的具体信息,比如Top款、指定类目等
- 从开发角度出发,每个宝贝详情页都是一个独立页面,且有固定规律,我直接用URL跳转可以减少大量窗口切换工作,一方面可以一定程度上避免反爬,另一方面可以增强代码健壮性
代码整合设计

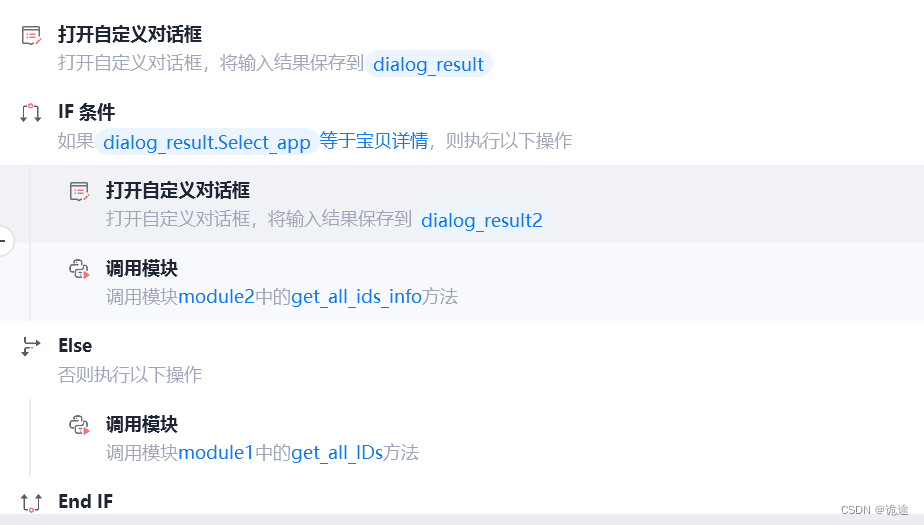
# modul1.py
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import random
def login_info():
"""
登录验证
@ return: webBrowser 网页对象
"""
webBrowser = xbot.web.create("www.taobao.com",mode="chrome")
user_name_elements = webBrowser.find_all_by_xpath('//div[@class="site-nav-user"]/a',timeout=3)
if not len(user_name_elements):
xbot.app.dialog.show_message_box("提示","请先登录您的个人淘宝账号")
user_name_elements = webBrowser.find_all_by_xpath('//div[@class="site-nav-user"]/a')
user_name = user_name_elements[0].get_text()
return webBrowser
def get_all_IDs():
webBrowser = login_info()
page_count = 0
while True:
all_id_elements = webBrowser.find_all_by_xpath('//div[@class="J_TItems"]/div')
# print(len(all_id_elements))
result = []
for element in all_id_elements:
if element.get_attribute("class")=="pagination":
# print("到底了,点击下一页翻页")
# break
next_page_btn = element.find_by_xpath('//a[text()="下一页"]')
# 判断下一页是否可用,不可用则到末尾页了
next_page_btn_stau = next_page_btn.get_attribute("class")
if next_page_btn_stau !="disable":
next_page_btn.click()
break # 跳出当前循环
else:
# 获取每一组(一排5个)商品
dl_elements = element.find_all_by_xpath("dl")
for dl_element in dl_elements:
ID = dl_element.get_attribute("data-id")
ID_element = dl_element.find_by_xpath('dt/a/img')
ID_title = ID_element.get_attribute("alt")
ID_main_pic = ID_element.get_attribute("src")
print([ID,ID_title,ID_main_pic])
result.append([ID,ID_title,ID_main_pic])
page_count+=1
print(f"第{page_count}页抓取完成!")
if next_page_btn_stau =="disable":
break # 跳出所有循环
xbot.app.databook.clear()
xbot.app.databook.set_range(1,1,result)
xbot.app.databook.export_data("GAP全店商品明细.xlsx")
def main(args):
pass
# module2.py
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
from .module1 import *
def get_one_id_info(webBrowser):
# 获取商品标题
TITLE = webBrowser.find_by_xpath('//h1[contains(@class,mainTitle)]').get_text()
active_price = webBrowser.find_all_by_xpath('//span[contains(@class,"Price--priceText")]')[0].get_text()
discounts = webBrowser.find_by_xpath('//span[text()="优惠:"]/../span[contains(@class,"caption")]').get_attribute("title")
active = webBrowser.find_by_xpath('//span[text()="活动:"]/../span[contains(@class,"caption")]').get_attribute("title")
item_infos = webBrowser.find_by_xpath('//span[text()="宝贝参数:"]/..').get_text()
return TITLE,active_price,discounts,active,item_infos
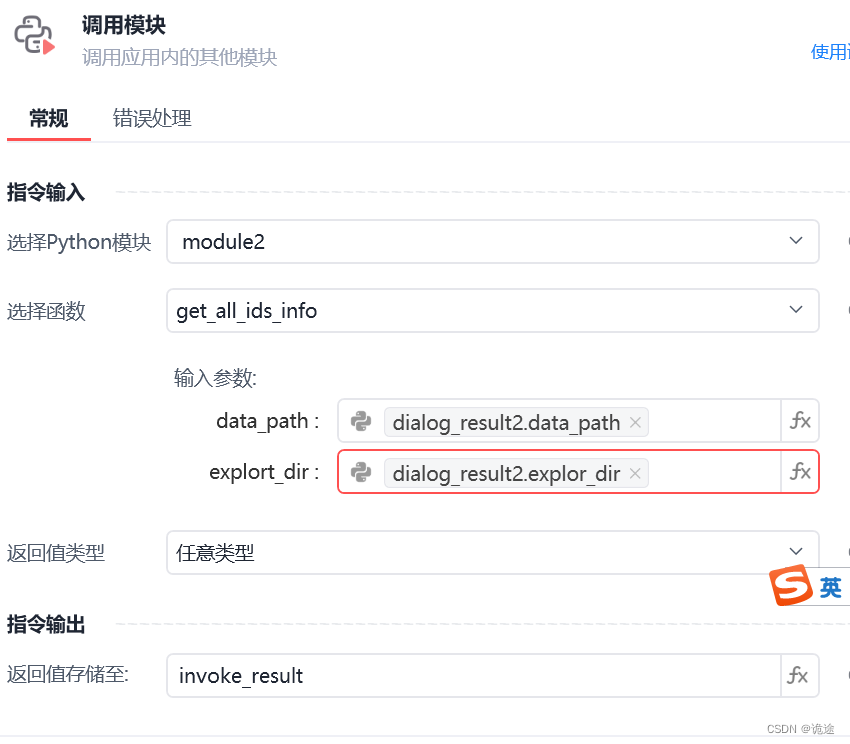
def get_all_ids_info(data_path,explort_dir):
IDs = pd.read_excel(data_path)["商品ID"].values()
webBrowser = login_info()
result = []
count = 0
for ID in IDs:
url = f"https://detail.tmall.com/item.htm?id={ID}"
webBrowser.navigate(url)
try:
TITLE,active_price,discounts,active,item_infos= get_one_id_info(webBrowser)
result.append([ID,"执行成功",TITLE,active_price,discounts,active,item_infos])
except:
result.append([ID,"执行失败"])
count+=1
if count >=3:
break
df_result = pd.DataFrame(result,columns={"商品ID","执行状态","商品名称","活动价","优惠","活动","商品详细信息"})
df_result.to_excel(os.path.join(explort_dir,"商品信息.xlsx"),index=False)
def main(args):
pass
文章来源:https://blog.csdn.net/qq_35866846/article/details/134673458
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!