【论文解读】3D视觉标定的显式文本解耦和密集对齐(CVPR 2023)
来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://arxiv.org/abs/2209.14941
开源代码:https://github.com/yanmin-wu/EDA

图1所示。文本解耦,密集对齐的3D视觉标定。文本中的不同颜色对应不同的解耦分量。(a)常规的3D视觉标定:定位对象需要综合考虑外观属性、对象名称、空间关系等多种语义线索。(b)无对象名称标定:不提及对象名称,避免走捷径,迫使模型根据其他属性预测目标。
摘要:
三维视觉标定的目的是寻找具有丰富语义线索的自由形式的自然语言描述所提到的点云中的物体。然而,现有的方法要么提取与所有单词耦合的句子级特征,要么更多地关注对象名称,这将失去单词级信息或忽略其他属性。为了缓解这些问题,我们提出了显式解耦句子中的文本属性的EDA,并在这种细粒度语言和点云对象之间进行密集对齐。具体来说,我们首先提出了一个文本解耦模块,为每个语义组件生成文本特征。然后,我们设计了两个损失来监督两个模态之间的密集匹配:位置对齐损失和语义对齐损失。在此基础上,我们进一步引入了一个新的视觉标定任务,定位没有对象名称的对象,可以彻底评估模型的密集对齐能力。通过实验,我们在两个广泛采用的3D视觉标定数据集scanreference和SR3D/NR3D上实现了最先进的性能,并在我们新提出的任务中获得了绝对的领先地位。
1.引言
多模态线索可以非常有利于代理的3D环境感知,包括2D图像、3D点云和语言。近年来,3D视觉标定(3D visual grounding, 3D VG),又称3D object reference,作为一项重要的3D跨模态任务受到了广泛关注。它的目标是通过分析描述性查询语言来找到点云场景中的目标物体,这需要同时理解3D视觉和语言上下文。
语言话语通常涉及描述外观属性、对象类别、空间关系等特征的词语,如图1(a)中不同的颜色所示,需要模型整合多个线索来定位所述对象。与2D Visual Grounding相比,点云的稀疏性和不完全性,以及3D多视图产生的语言描述的多样性,使得3D VG更具挑战性。现有工作在以下几个方面取得了重大进展:改进了稀疏卷积的点云特征提取或二维图像辅助;通过实例分割或语言调制生成更具判别性的候选对象;通过图卷积或注意力识别实体之间复杂的空间关系。
然而,我们观察到两个尚未探讨的问题。 1)不平衡:对象名称可以排除大多数候选对象,甚至在某些情况下,只有一个名称匹配的对象,如图1(b1,b2)中的“门”和“冰箱”。这种捷径可能会导致模型出现归纳偏差,即更加关注对象名称,而削弱外观和关系等其他属性,从而导致学习不平衡。 2)歧义:话语经常涉及多个对象和属性(例如图1(b4)中的“黑色物体,高架子,扇子”),而模型的目标是仅识别主要对象,导致理解模糊的语言描述。现有工作的这些不足源于其特征隐式耦合和融合的特点。他们输入一个具有不同属性词的句子,但仅输出一个全局耦合的句子级特征,该特征随后与候选对象的视觉特征相匹配。耦合特征是不明确的,因为有些词可能不描述主要对象(图1中的绿色文本),而是描述其他辅助对象(图1中的红色文本)。或者,自动隐式地使用 Transformer的跨模式注意力来融合视觉和文本特征。然而,这可能会鼓励模型采取捷径,例如关注对象类别并忽略其他属性,如前所述。
相反,我们提出了一种更直观的解耦和明确的策略。首先,我们解析输入文本以解耦不同的语义组件,包括主宾词、代词、属性、关系和辅助宾语词。然后,在点云对象和多个相关解耦组件之间进行密集对齐,实现细粒度的特征匹配,从而避免因不同文本组件的不平衡学习而产生的归纳偏差。作为最终的标定结果,我们明确选择与解耦文本组件(而不是整个句子)相似度最高的对象,避免由不相关组件引起的歧义。此外,为了探索 VG 的局限性并检验模型视觉语言感知的全面性和细粒度,我们提出了一项具有挑战性的新任务:无对象名称的标定(VG-w/o-ON),其中名称为被“对象”取代(见图1(b)),迫使模型根据其他属性和关系来定位对象。这个设置是有意义的,因为不提及对象名称的话语是日常生活中的常见表达方式,此外还可以测试模型是否走捷径。受益于我们的文本解耦操作和密集对齐损失的监督,所有文本组件都与视觉特征对齐,使得独立于对象名称来定位对象成为可能。
综上所述,本文的主要贡献如下:
1)我们提出了文本解耦模块,将语言描述解析为多个语义成分,然后提出了两种精心设计的密集对齐损失来监督细粒度的视觉语言特征融合并防止不平衡和歧义学习。
2)提出了具有挑战性的新3D VG任务,即没有对象名称的标定,以全面检验模型的鲁棒性能。
3)我们在常规 3D VG 任务上的两个数据集(ScanRefer 和 SR3D/NR3D)上实现了最先进的性能,并且在无需重新训练的情况下在由相同模型评估的新任务上实现了绝对领先。
2.相关工作
2.1 「3D 视觉和语言」
3D视觉和语言是人类理解环境的重要方式,也是机器进化到像人类一样的重要研究课题。此前,这两个领域是独立发展的。由于多模态的进步,最近推出了许多跨 3D 视觉和语言的有前途的工作。在 3D 视觉标定中,说话者(如人类)用语言描述一个对象。听者(例如机器人)需要理解语言描述和 3D 视觉场景才能确定目标对象。相反,3D 密集字幕类似于一个逆过程,其中输入是 3D 场景,输出是每个对象的文本描述。语言调制 3D 检测或分割通过匹配视觉语言特征空间而不是预测一组类别的概率来丰富文本查询的多样性。此外,一些研究探索了 3D 视觉语言在机器人感知、视觉和语言导航 (VLN) 和具身问答 (EQA) 。在本文中,我们重点关注基于点云的 3D 视觉基础,这是许多具体人工智能任务的基础技术。
2.2 「3D视觉标定。」
目前大多数主流技术都是两阶段的。在第一阶段,通过预训练的语言模型和预训练的3D检测器或分割器独立地获取查询语言和候选点云对象的特征。在第二阶段,研究人员专注于融合两种模态特征,然后选择最匹配的对象。
1)最直接的解决方案是连接两个模态特征,然后将其视为二元分类问题,由于两个特征没有充分融合,因此性能有限。
2)利用Transformer天生适合多模块特征融合的注意力机制,He等人和Zhao等人通过对特征进行自注意力和交叉注意力,取得了显着的性能。
3)相比之下,其他研究将特征融合视为匹配问题而不是分类问题。 Yuan等人和Abdelreheem等人在对比损失的监督下,计算视觉特征和文本特征的余弦相似度。Feng等人解析文本生成文本场景图,同时构建视觉场景图,然后进行图节点匹配。
4)点云的稀疏、噪声、不完整和缺乏细节使得学习对象的语义信息具有挑战性。 Yang等人和Cai等人使用2D图像来辅助视觉文本特征融合,但以额外的2D-3D对齐和2D特征提取为代价。
然而,两阶段方法有一个很大的检测瓶颈:第一阶段忽略的对象无法在第二阶段匹配。相比之下,单阶段方法中的对象检测和特征提取是由查询文本调制的,使得更容易识别文本相关的对象。 Liu等人建议在底层融合视觉和语言特征并生成文本相关的视觉热图。类似地,Luo 等人提出了一种单阶段方法,利用文本特征来指导视觉关键点选择并逐步定位对象。 BUTD-DETR也是一个单阶段能力的框架。更重要的是,受到 2D 图像语言预训练模型(如 MDETR、GLIP)的启发,BUTD-DETR 测量每个单词和对象之间的相似度,然后选择与对象名称对应的单词特征来匹配候选对象。然而,有两个限制:1)由于句子中可能会提到多个对象名称,因此需要真实值注释来检索目标名称,这限制了其泛化性。
我们的文本解耦模块将文本组件分离,并通过语法分析确定目标对象名称,以避免这种限制。 2)BUTDDETR(以及2D任务中的MDETR和GLIP)仅考虑主要对象词或名词短语与视觉特征的稀疏对齐。相反,我们将所有与对象相关的解耦文本语义组件与视觉特征对齐,我们称之为密集对齐,显着增强了多模态特征的可辨别性。

图 2. 文本组件解耦:(a) 查询文本。 (b) 依赖树分析。 (c) 解耦为五个组成部分。
3.提出的方法
该框架如图3所示。首先,将输入文本描述解耦为多个语义组件,并获得其附属文本位置和特征(第3.1节)。同时,基于 Transformer 的编码器从点云和文本中提取和调制特征,然后解码候选对象的视觉特征(第 3.2 节)。最后,在解耦的文本特征和解码的视觉特征之间导出密集对齐损失(第 3.3 节)。标定结果是视觉特征与文本特征最相似的对象(第 3.4 节)。
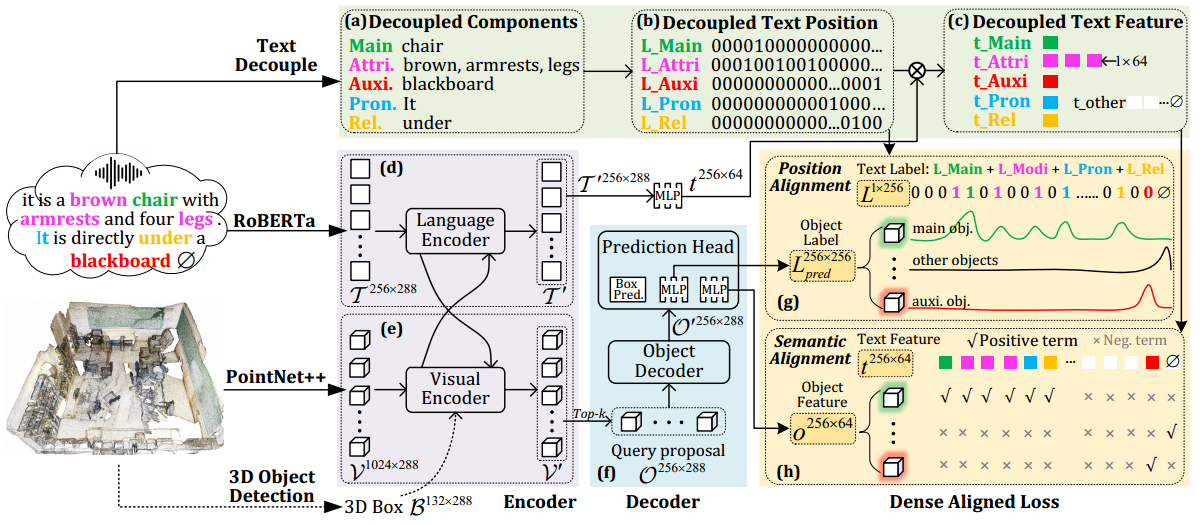
图 3. 系统框架。 (a-c):将输入文本解耦为多个组件,以获得解耦文本的位置标签 L 和特征 t。 (d-e):基于 Transformer 的编码器,用于跨模式视觉文本特征提取。 (f):除了用于边界框回归的框预测头之外,解码提议特征O′并将它们线性投影为对象位置标签Lpred和对象特征o。 (g-h):视觉文本特征密集对齐。请注意,附加的 3D 对象检测过程是可选的。
3.1文本解耦
耦合策略的文本特征是不明确的,多个对象和属性的特征是耦合的,例如“黑色桌子旁边的棕色木椅”。其中,易于学习的线索(例如类别“椅子”或颜色“棕色”)可能占主导地位,削弱其他属性(例如材料“木质”);其他物体(例如“黑桌”)的文字可能会造成干扰。为了产生更具辨别力的文本特征和细粒度的跨模态特征融合,我们将查询文本解耦为不同的语义组件,每个语义组件独立地与视觉特征对齐,避免了特征耦合引起的歧义。
「文本组件解耦。」 分析单词之间的语法依赖关系是 NLP 的一项基本任务。我们首先使用现成的工具对语言描述进行语法解析,生成语法依存树,如图2(b)所示。每个句子只包含一个ROOT节点,其余每个单词都有一个对应的父节点。
然后根据单词的词性和依赖关系,我们将长文本解耦为五个语义成分(见图2(c)): 主要对象 - 话语中提到的目标对象;辅助物体——用于辅助定位主要物体的物体;属性——物体的外观、形状等;代词——代替主宾语的词;关系——主对象和辅助对象之间的空间关系。请注意,附属于代词的属性相当于附属于主宾语,从而连接话语中的两个句子。
「文本位置解耦。」 解耦每个文本组件后(图 3(a)),我们生成组件关联词的位置标签(类似于掩码)Lmain, Lattri, Lauxi, Lpron, Lrel ∈ R 1×l(图 3(b) ))。其中l=256是文本的最大长度,每个组件的单词位置设置为1,其余设置为0。标签将用于构造位置对齐损失并监督对象的分类。分类结果不是预定数量的对象类别之一,而是具有最高语义相似度的文本的位置。
文本特征解耦。每个单词(token)的特征是在多模态特征提取的主干中产生的(图3(d))。解耦组件的文本特征可以通过将所有单词的特征t与其位置标签L点乘来获得,如图3(c)所示。解耦的文本特征和视觉特征将在语义对齐损失的监督下独立对齐。请注意,在解耦的文本特征中,相应组件的语义绝对占主导地位,但由于 Transformer 的注意力机制,它也隐式包含了全局句子的信息。换句话说,特征解耦产生单独的特征,同时保持全局上下文。
3.2多模态特征提取
我们采用 BUTD-DETR 的编码器-解码器模块进行特征提取和跨模态特征的互调。我们强烈建议读者参考图3。
「输入模态标记化。」 输入文本和 3D 点云由预先训练的 RoBERTa和 PointNet++进行编码,并生成文本标记 T ∈ R l×d 和视觉标记 V ∈ R n×d 。此外,GroupFree检测器用于检测 3D 框,随后将其编码为框标记 B ∈ R b×d 。请注意,GroupFree 是可选的,网络的最终预测对象来自预测头(见下文),而 box token 只是为了辅助目标对象更好的回归。
「编码器-解码器。」 在编码器中执行自注意力和交叉注意力来更新视觉和文本特征,在保持维度的同时获得跨模态特征 V ' , T ' 。选择 top-k (k=256) 视觉特征,线性投影为查询提议特征 O ∈ R k×d ,并在解码器中更新为 O′。
**预测头。 **1)解码后的提议特征 O′ ∈ R k×d 被输入 MLP 并输出预测位置标签 Lpred ∈ R k×l ,然后用于计算解耦文本位置标签 L ∈ R 1 的位置对齐损失×l。 2)此外,提案特征由另一个MLP线性投影为对象特征o ∈ R k×64,然后利用类似的线性投影文本特征t ∈ R l×64来计算语义对齐损失。 3)最后,框预测头[44]回归对象的边界框。
3.3 密集对齐损失
「3.3.1 密集位置对齐损失」
位置对齐的目的是确保语言调制的视觉特征的分布与查询文本描述的分布紧密匹配,如图3(g)所示。这一过程类似于标准目标检测的单热标签预测。然而,我们并不受类别数量的限制,而是预测与对象相似的文本的位置。
上述主要对象的构建的真实文本分布是通过对相关解耦文本组件的位置标签进行元素求和来获得的:
![]()
其中 λ 是不同部分的权重(请参阅补充材料中的参数搜索)。 Pauxi = Lauxi 表示辅助对象的文本分布。其余候选对象的文本分布为Poth,最后一位设置为1(见图3(g)中的?)。因此,所有 k 个候选对象的真实文本分布为 Ptext = {Pmain, Paxi, Poth} ∈ R k×l 。
k 个对象的预测视觉分布是通过将 softmax 应用于预测头的输出 Lpred ∈ R k×l 来生成的:
![]()
它们的 KL 散度定义为位置对齐损失:

我们强调,“密集对齐”表示目标对象与多个组件的位置对齐(方程(1)),与 BUTD-DETR(以及用于 2D 任务的 MDETR)显着不同,后者仅与对象名称的位置稀疏对齐位置Lmain。
「3.3.2 密集语义对齐损失」
语义对齐旨在通过对比学习来学习视觉文本多模态特征的相似性。语义对齐的对象丢失定义如下:
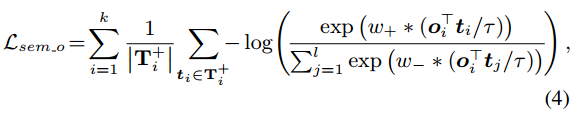
其中o和t是线性投影后的对象和文本特征,o?t/τ是它们的相似度,如图3(h)所示。 k 和 l 是对象和单词的数量。 ti 是第 i 个候选对象的正文本特征。以主对象为例,其对应的正文本特征T+i为:
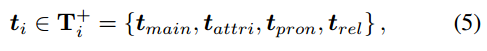
w+ 是每个正项的权重。 tj 是第 i 个文本的特征,但请注意,辅助对象术语 tauxi 的负相似权重 w? 为 2,而其余权重为 1。语义对齐的文本损失定义类似:
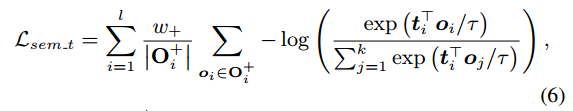
其中oi ∈ O+ i 是第i 个文本的正对象特征,oj 是第j 个对象的特征。最终的语义对齐损失是两者的平均值:Lsem = (Lsem o + Lsem t)/2。
同样,多个文本组件(等式(5))与视觉特征的语义对齐也说明了我们对“密集”的理解。这是直观的,例如“黑板下面是一把有腿的棕色椅子”,其中主要物体的视觉特征不仅应该与“椅子”相似,而且与“棕色,腿”相似,而与“黑板”不同,因为可能的。
训练的总损失还包括框回归损失。有关详细信息,请参阅补充材料。
3.4 显式推理
由于我们的文本解耦和密集对齐操作,对象特征融合了多个相关的文本组件特征,从而允许计算各个文本组件和候选对象之间的相似度。例如,Smain = Sof tmax(o ?tmain/τ ) 表示对象 o 和主要文本组件 tmain 之间的相似度。因此,可以显式地组合对象和相关组件的相似度来获得总分并选择得分最高的候选者:

其中 Sattri、Spron、Srel 和 Sauxi 的定义与 Smain 类似。如果在训练过程中提供对辅助对象的监督,则可以通过仅计算对象特征与辅助组件的文本特征之间的相似度来识别辅助对象:Sall = Sattri。能够根据文本的一部分推断对象是网络已经学习了对齐良好且细粒度的视觉文本特征空间的重要标志。
4.实验
首先,我们在第 4.1 节中的常规 3D 视觉标定设置中与 SOTA 方法进行全面、公平的比较。然后,在4.2节中,我们介绍了我们提出的新任务,Grounding without Object Name,并进行比较和分析。补充材料中详细介绍了实施细节、额外实验和更多定性结果。

表1. ScanRefer上的3D视觉基础结果,通过IoU 0.25和IoU 0.5评估精度。 ? 使用我们解析的文本标签重新评估准确性,因为 BUTD-DETR 报告的性能使用真实文本标签并忽略了一些具有挑战性的样本(有关更多详细信息,请参阅补充材料)。 § 我们的单阶段实现无需额外的 3D 对象检测步骤的帮助(图 3 中的虚线箭头)。 ? BUTD-DETR 没有提供单阶段结果,我们重新训练了模型。
4.1 正常3D视觉标定
4.1.1 实验设置
我们保留与现有作品相同的设置,以 ScanRefer和 SR3D/NR3D作为数据集,以 Acc@0.25IoU 和 Acc@0.5IoU 作为指标。基于 ScanNet的视觉数据,ScanRefer 添加了 51,583 个关于对象的手动注释文本描述。这些复杂且形式自由的描述涉及对象类别和属性,例如颜色、形状、大小和空间关系。 SR3D/NR3D也是基于ScanNet提出的,SR3D包含83,572个简单的机器生成的描述,NR3D包含41,503个描述,类似于ScanRefer的人工注释。不同的是,在ScanRefer配置中,需要检测和匹配对象,而SR3D/NR3D更简单。它为所有候选对象提供GT框,只需要对框的类别进行分类并选择目标对象。
4.1.2 与SOTA的比较
「ScanRefer」。表 1 报告了 ScanRefer 数据集的结果。 i) 我们的方法大幅提高了最先进的性能,总体提高了 4.2% 和 3.7%,达到 54.59% 和 42.26%。 ii)一些研究证明补充具有详细和密集语义的2D图像可以学习更好的点云特征。令人惊讶的是,我们只使用稀疏的 3D 点云特征,甚至优于 2D 辅助方法。这种优越性说明我们的解耦和密集对齐策略可以挖掘更高效、更有意义的视觉文本共同表示。 iii) 另一个发现是,大多数现有技术在“多重”设置下的准确率低于 40% 和 30%,因为多重意味着语言中提到的目标对象的类别不是唯一的,有更多的干扰候选者同一类别。然而,我们达到了惊人的 49.13% 和 37.64%。为了识别相似的物体,在这种复杂的环境中需要对文本和视觉有更细粒度的理解。 iv) 表 1 中的最后三行比较了单阶段方法,其中我们的方法的单阶段实现在训练和推理中没有对象检测步骤(图 3 中的 B)。结果表明,虽然不需要额外的预训练 3D 对象检测器,但我们的方法也可以实现 SOTA 性能。v) 定性结果如图 4(a-c) 所示,这表明我们的方法对外观属性、空间关系甚至序数具有出色的感知能力。
「SR3D/NR3D」。表 2 显示了 SR3D/NR3D 数据集上的准确性,其中我们实现了 68.1% 和 52.1% 的最佳性能。在SR3D中,由于语言描述简洁且对象易于识别,我们的方法达到了60%以上的准确率。相反,在 NR3D 中,描述过于详细和复杂,给文本解耦带来了额外的挑战。然而,我们仍然使用纯 3D 数据实现了 SOTA 精度,而其他类似方法则依赖于额外的 2D 图像进行训练。表 1 中比较的一些方法此处未讨论,因为它们未在 SR3D/NR3D 数据集上进行评估。此外,由于在此设置中提供了候选对象的 GT 框,因此单阶段方法不适用和讨论。

表 2. 以 Acc@0.25IoU 作为指标在 SR3D/NR3D 数据集上的性能。补充材料中提供了四个子集中 EDA 的详细结果。 ? 通过解析的文本标签重新评估(更多详细信息,请参阅补充)。
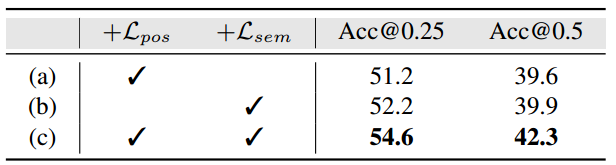
4.1.3 消融实验
「损失消融。」 位置对齐损失和语义对齐损失的消融如表3所示。语义对齐损失的性能稍微好一些,因为它的对比损失不仅缩短了相似文本视觉特征之间的距离,而且扩大了文本视觉特征之间的距离。不匹配特征之间的距离(例如 tauxi 是等式(4)中的负项??)。而位置对齐损失仅考虑与对象相关的组件(如等式(1))。当两种损失一起监督时,可以达到最佳精度,这表明它们可以产生互补的性能。
「密集成分消融。」 为了展示我们对密集对齐的洞察,我们对不同的解耦文本组件进行消融分析,结果显示在表 4 中的“常规 VG”列中。分析:i) (a) 是我们稀疏概念的基线实现,仅使用与文本解耦的“主对象”组件。与 BUTD-DETR 相比,文本解耦模块(第 3.1 节)用于在训练和推理过程中获取文本标签和特征,而不是使用真实标签。 ii)由于更细粒度的视觉语言特征融合,密集对齐子方法(b)-(h)优于稀疏对齐(a)。 iii) (b)-(e) 表明在“主要对象”之上添加任何其他组件可以提高性能,证明每个文本组件的有效性。 “属性”组件有助于识别语言描述中经常提到的特征,例如颜色和形状。出乎意料的是,诸如“it、that、which”之类的“代词”成分单独使用时意义不大,但在我们的方法中却发挥了作用,表明代词从句子中学习了上下文信息。“关系”组件有助于理解对象之间的空间关系。 “辅助对象”分量是损失中的负项(等式(4))。在推理过程中(式(7)),减去其相似度,希望预测的主要对象与其尽可能不相似。 iv) (f)-(h) 集成不同的组件以实现性能提升并在所有组件参与时达到峰值,证明每个组件的功能可以互补,并且每个组件的功能之间可以不存在重叠。结果表明,我们的方法有效地解耦和匹配细粒度的多模态特征。

4.2 不使用物体名字进行标定
4.2.1 实验设置
为了评估模型的综合推理能力并避免对对象名称的归纳偏差,我们提出了一个新的且更具挑战性的任务:在不提及对象名称的情况下将对象标定(VG-w/o-ON)。具体来说,我们在 ScanRefer 验证集中手动将对象名称替换为“object”。例如:“这是一把棕色的木椅”变成“这是一个棕色的木制物体”。总共对 9253 个样本进行了注释,并丢弃了另外 255 个不明确的样本。我们将该语言集分为四个子集:仅提及对象属性(~15%),仅提及空间关系(~20%),同时提及属性和关系(~63%),以及其他(~2%),作为表 5 中的第一行。请注意,在没有重新训练的情况下,我们使用我们的最佳模型和比较方法针对常规 VG 任务训练的最佳模型进行比较(第 4.1 节)。

图 4. ScanRefer 文本的定性结果。 (a-c):常规 3D 视觉基础。 (d-e):没有对象名称的标定。
4.2.2 结果和分析
表 5 报告了实验结果。 i)所有方法在这个具有挑战性的任务上的性能都明显低于常规VG(见表1),表明对象类别提供了丰富的语义信息,这也有利于对特征进行分类。很容易产生类别的归纳偏差,尤其是在“独特”的环境中。 ii)我们的方法取得了绝对领先,整体性能分别为26.5%和21.2%,比其他方法高出10%以上。这种优势表明,我们提出的文本解耦和密集对齐可以实现细粒度的视觉语言特征匹配,其中模型识别与其他文本组件(例如属性、关系等)最相似的视觉特征。 iii)值得注意的是,在子集“Attri+Rel”中,我们的方法比其他子集中表现更好,因为可以利用额外的线索进行细粒度定位。然而,该子集上的比较方法的性能下降,表明更多的线索使它们遭受歧义。 iv) 表 4 中的“VG-w/o-ON”列显示了针对此新任务的文本组件的消融研究。附加组件提供的性能提升比常规 VG 任务期间更为显着。其中,“关系”组件起着最重要的作用,因为与其他对象的空间关系可以在该设置中提供更明显的指示。 v) 图 4(d-e) 显示了定性示例。即使不知道目标的名称,我们的方法也可以通过其他线索来推断它,而 BUTD-DETR 的性能会急剧下降。
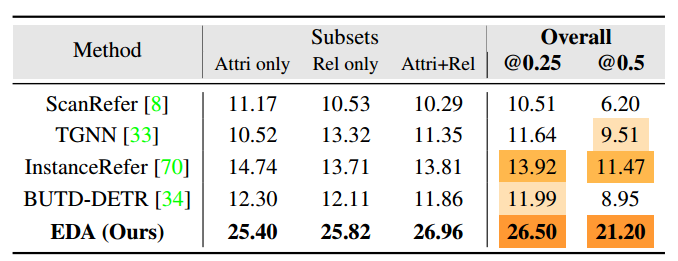
表 5. 不带物体名称的标定性能。子集的准确性通过 acc@0.25IoU 来衡量,其中“其他”子集由于其比例较小而未报告。
5.结论
我们提出了 EDA,一种用于 3D 视觉基础任务的显式密集对齐方法。通过将文本解耦为多个语义组件,并在位置对齐和语义对齐损失的监督下将其与视觉特征紧密对齐,我们实现了细粒度的视觉文本特征融合,避免了现有方法的不平衡和模糊性。大量的实验和消融证明了我们方法的优越性。此外,我们提出了一个新的具有挑战性的 3D VG 子任务,即没有对象名称的标定,以全面评估模型的鲁棒性。然而,我们的局限性是多个模块的性能瓶颈,例如 PointNet++、RoBERTa 和文本解析模块。尤其是当文本较长时,文本解耦可能会失败,导致性能下降。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“CVPR最佳”免费领取近五年CVPR最佳论文合集
码字不易,欢迎大家点赞评论收藏!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!