源码级详解Spring的三级缓存,循环依赖的处理流程
一.什么是三级缓存
1.一级缓存:存放已经初始化完成的Bean
2.二级缓存:存放半成品Bean,既实例化完成未初始化的Bean。
3.三级缓存:存放bean工厂
二.为什么是三级缓存
一级缓存是必须的,这个我们没有什么疑问。那为什么要有二级缓存,二级缓存主要是用来解决循环依赖的问题。
2.1什么是循环依赖
循环依赖就是指循环引用,是两个或多个Bean相互之间的持有对方的引用。
举个简单的例子:
kotlin
复制代码@Service
public class AService {
@Resource
private BService bService;
}kotlin
复制代码@Service
public class BService {
@Resource
private AService aService;
}AService中依赖了BService,而BService又依赖了AService,这样就构成循环依赖。
Spring是允许单例bean进行循环依赖的。
2.2循环依赖的bean注入流程

下面我就带大家从源码的层面,讲解三级缓存是如何解决循环依赖问题的。
1.doCreateBean方法会调用createBeanInstance方法来对beanA进行实例化。
2.addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));会将生成代理对象的工厂放入到三级缓存。
3.beanA调用populateBean方法,注入beanB实例。
在注入beanB实例的过程中,发现beanB依赖了beanA,需要将beanA加载出来。
会再次对beanA调用doGetBean方法。这时候,getSingleton方法就真正派上用场了。
4.在getSingleton方法中,会将beanA的bean工厂从三级缓存中取出来,调用getObject方法,也就是getEarlyBeanReference方法,将返回结果放入二级缓存,同时从三级缓存移除掉。
5.把不完整的beanA注入到beanB中
6.beanB执行addSingleton(beanName, singletonObject)方法,这个方法将beanB放入到一级缓存,且从二级缓存中移除掉。
7.beanA注入beanB实例。
8.beanA完成属性填充和初始化,执行addSingleton(beanName, singletonObject)方法,将BeanA放入到一级缓存。
从上面注入的流程,可以看出,如果没有存放半成品的二级缓存,那么循环依赖是无法解决的。如果我们在实例化完beanA,立刻创建出代理对象放到二级缓存,再填充beanA的属性以及初始化,这样也可以正常完成BeanA,BeanB的注入。这样就省掉了第三级缓存。那第三级缓存存在的原因是什么呢?
2.3.第三级缓存在的原因
要理清楚,三级缓存存在的原因主要原因有两个,一是因为AOP,二是循环依赖。如果没有Spring AOP和循环依赖,那么就不需要使用三级缓存。
我们先看下,不存在循环依赖的代理对象是如何生成的?
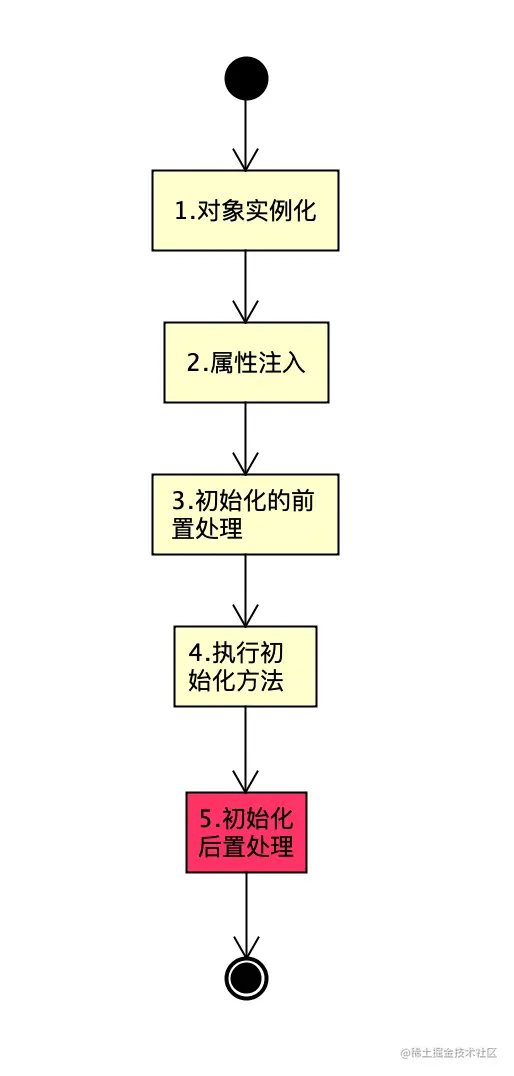
上图第五步的时候,会调用AbstractAutoProxyCreator类的
postProcessAfterInitialization方法,创建代理对象。对于不涉及到循环依赖的bean,会在初始化之后,创建代理对象。
而对于涉及到循环依赖的bean,如果没有三级缓存,在对象实例化后,就要立刻生成其代理对象,这样会影响到bean注入整个代码的逻辑。增加三级缓存,一可以防止循环依赖的对象多次被代理;还可以做到循环引用的bean,在被循环引用时,代理对象被创建且注入进去,不涉及到循环引用的bean,等到初始化之后创建代理对象。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!