那些年听烂了的名词之“高可用“
那些年听烂了的名词之"高可用"
引言
本文想来和大家聊聊那些年我们听烂了的名词之 ‘高可用’ ,那么第一个问题就是: “如何构建一个高可用系统呢?”
为了解答本文这个核心问题,需要分三个阶段来考虑:
- 什么是可用性 ?
- 哪些风险会影响系统的可用性 ?
- 如何应对这些风险,从而确保系统的可用性 ?
什么是可用性 ?
系统可用性 = 平均无故障时间 / (平均无故障时间 + 平均故障修复时间) * 100%
- 平均无故障时间(Mean Time To Failure ,MTTF): 系统无故障运行时间的平均值
- 平均修复时间(Mean Time To Repair,MTTR): 系统从发生故障到修复结束耗费时间的平均值
一般行业内会使用几个9来代指系统可用性:
| 系统可用性% | 宕机时间/年 | 宕机时间/月 | 宕机时间/周 | 宕机时间/天 |
|---|---|---|---|---|
| 90%(1个9) | 36.5 天 | 72小时 | 16.8小时 | 2.4小时 |
| 99%(2个9) | 3.65 天 | 7.2小时 | 1.68小时 | 14.4分 |
| 99.9%(3个9) | 8.76小时 | 43.8分 | 10.1分 | 1.44分 |
| 99.99%(4个9) | 52.56分 | 4.38分 | 1.01分 | 8.66秒 |
| 99.999%(5个9) | 5.26分 | 25.6秒 | 6.05秒 | 0.87秒 |
哪些风险会影响系统的可用性 ?
工作中遇到过的故障基本可分为如下三类:
- 应用程序故障
- 业务线程打满
- OOM 内存溢出
- 依赖服务超时
- 依赖服务不可用
- 预估容量过低
- 进程被误杀
- 被突发流量击溃
- 进程挂住
- 环境配置错误
- 心跳异常
- 中间件故障
- JVM 故障
- 负载均衡失效
- 缓存热点key
- 数据库热点
- 数据库宕机故障
- 数据库主从延迟
- 数据库连接池满
- 网络/物理存储故障
- 服务器宕机/断电
- 磁盘满/坏道/数据损坏
- 网络抖动/丢包/超时
- 网卡负载满
- 网络断开
- DNS故障
我们也可以以服务为中心,从上下游依赖和服务自身运行过程为视角进行风险分析:
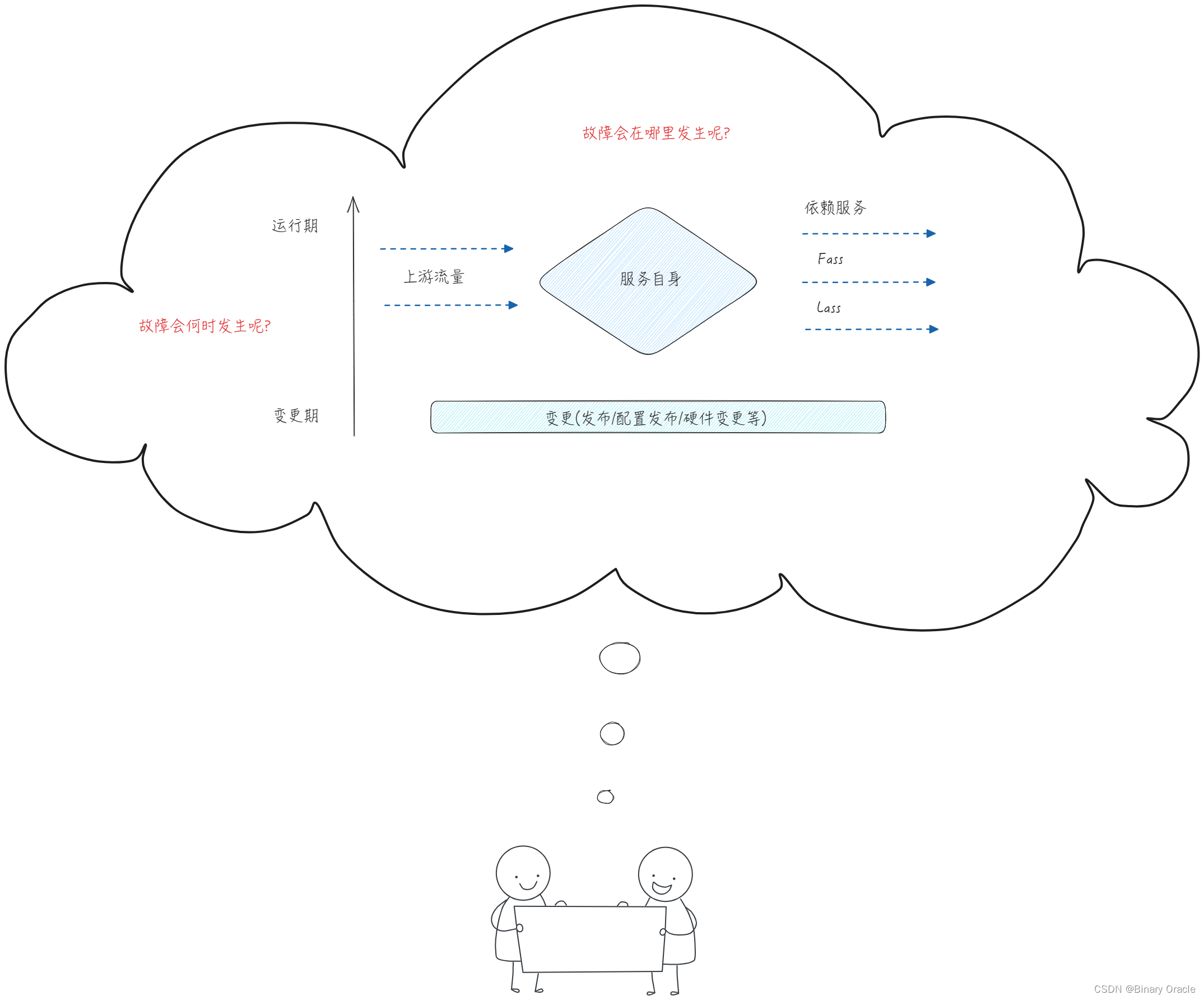
如何应对这些风险,从而确保系统的可用性 ?
为了提高系统的可用性,我们可以从下面这个基础公式出发:

- 提高MTTF : 规范,容灾设计,巡检预防,复盘等
- 缩短MTTR : 快速发现,定位,止损等
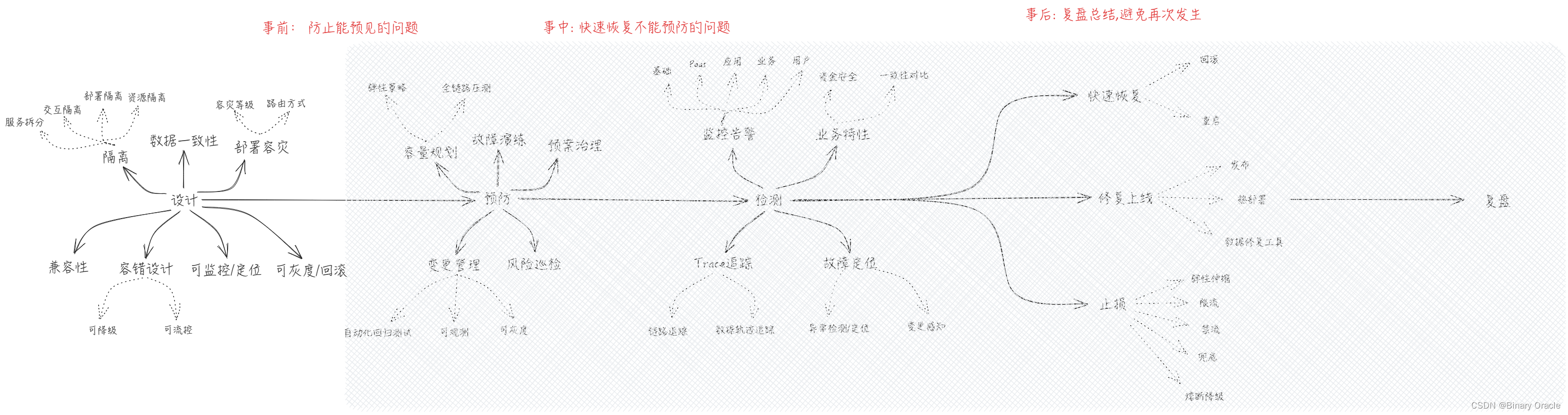
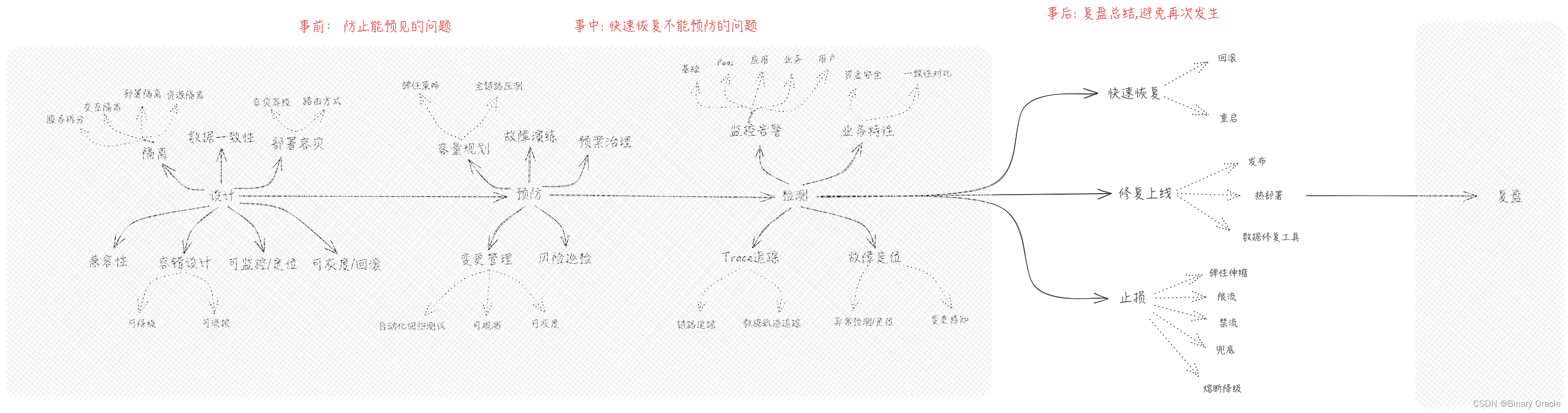
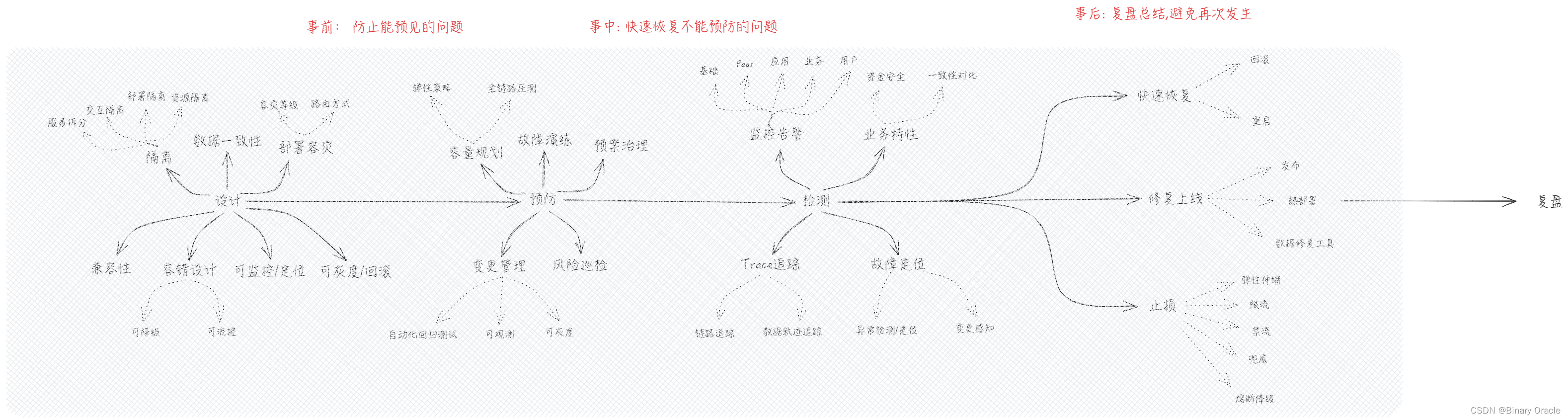
为了应对可能会发生的风险,我们可以采用五段式分析法,将研发流程划分为五个阶段,依次做好每个阶段的风险应对措施:
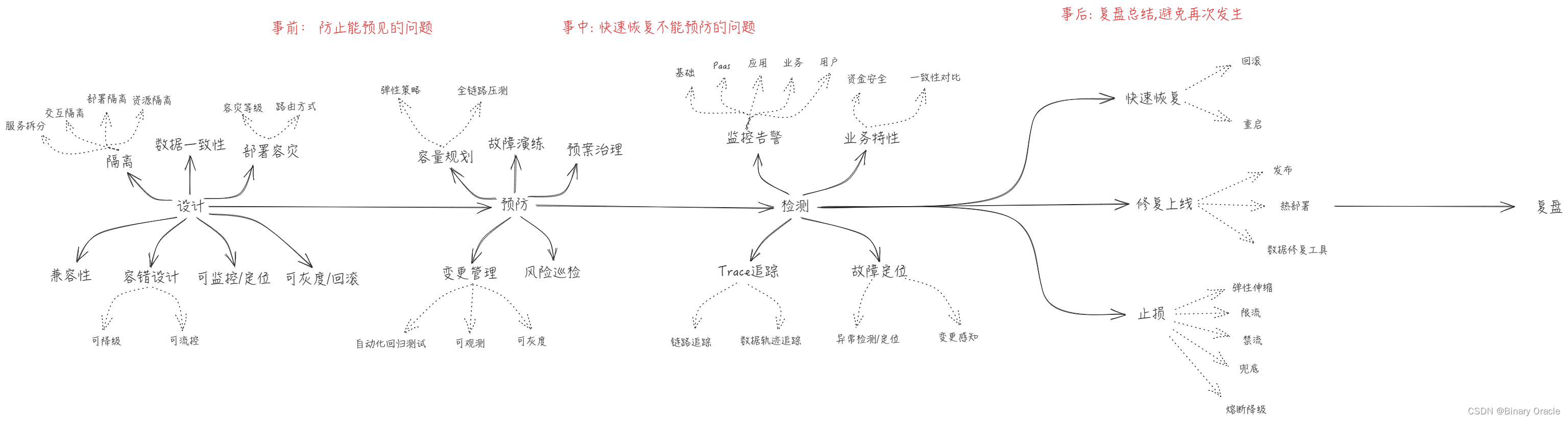
Phase: 设计
系统设计阶段:
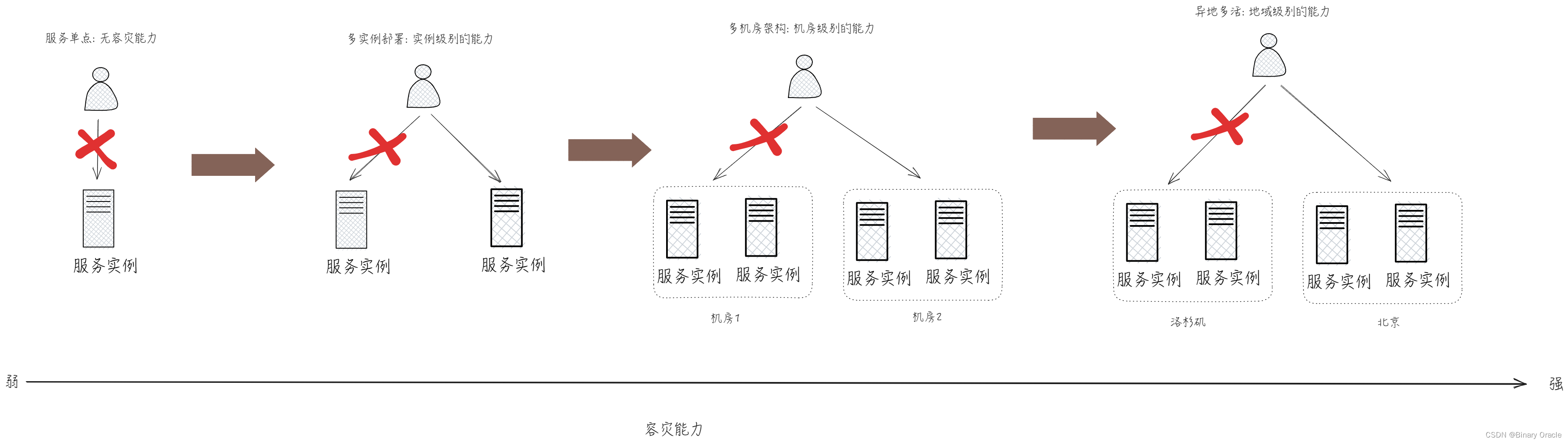
- 容灾能力: 同城容灾,异地容灾,双活数据中心,两地三中心等
- 容错能力: 针对任意依赖方(包括依赖的数据,数据库,服务,第三方等)的错误,都具备错误的处理能力
- 隔离能力: 业务隔离,用户隔离,资源隔离等
- 可扩展/伸缩能力: 系统水平伸缩,弹性扩容能力
- 数据一致性: 并发处理,幂等处理,事物等保持数据一致性
- 兼容能力: 具备版本兼容,上下游服务兼容,新老数据兼容,软硬件兼容等兼容能力
- 可灰度/回滚; 针对变更可以灰度,可以回滚
- 可监控/定位: 如健康检查,业务上下文传递,trace跟踪,日志设计,错误码设计等
- …
做好容灾和多活处理
做好容错设计
- 强弱依赖治理: 对外部RPC依赖进行梳理与强弱标注
- 超时设置: 建议根据服务的SLA,下游TP999,QPS等参数综合确定
- 熔断: 弱依赖需要覆盖熔断器,关注熔断器熔断阈值等
- 限流: 如直接面向C/B端的入口层服务需要配置限流等
- 重试: 常见补偿重试次数不要超过3次等
做好资源隔离
- 服务间交互隔离
- 线程池隔离
- 熔断隔离
- 超时隔离
- 服务内资源隔离
- JVM 租户隔离
- 类隔离
- 容器隔离
- 物理部署隔离
- git仓库隔离
- 集群隔离
- 存储隔离
- 热点隔离
做好扩展性设计
- 伸缩性: 系统能够通过增加(或减少)自身资源规模的方式增加(或减少)自己计算事务的能力。在网站架构中,通常是指利用集群的方式增加(或减少)服务器数量,从而提高(或降低)系统的整体事务吞吐能力。
- 扩展性: 对现有系统影响最小的情况下,系统功能可持续扩展或提升的能力。具体表现在系统基础设施稳定不需要经常变更,应用之间耦合较少,可以对需求变更作出敏捷响应。系统架构设计层面要遵循开闭原则,做到新增功能时,无需对现有系统进行改造。
做好数据一致性处理
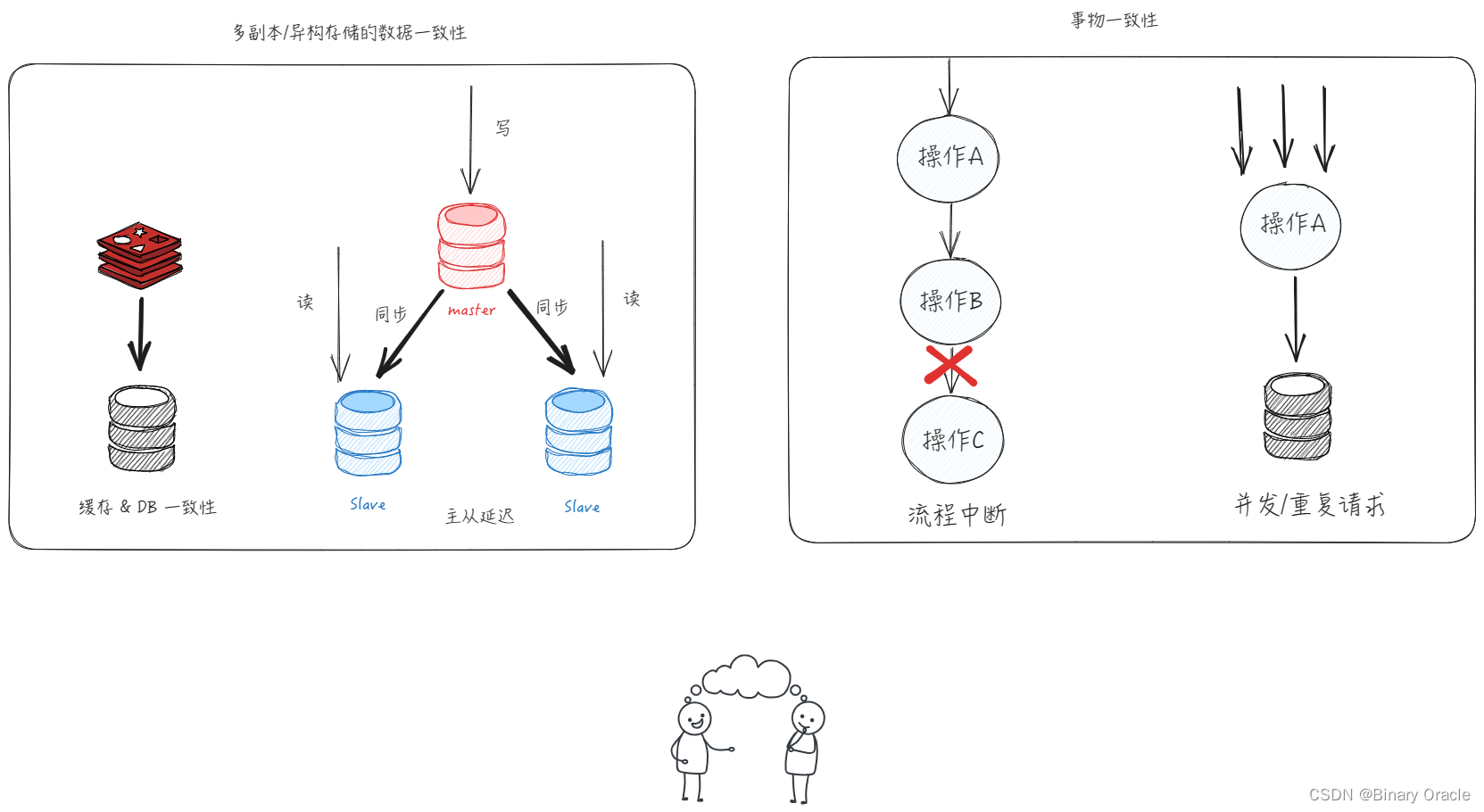
常见的数据一致性问题解决方案如下:
- 多副本数据一致性
- 异构数据存储一致性
- 写入策略,一致率对比
- 主从同步延迟
- 强制读主
- 异构数据存储一致性
- 事物一致性
- 流程中断问题
- 本地事务
- 分布式事务(本地消息表,MQ事务消息)
- 最终一致性(重试,失败补偿)
- 数据对账(diff)
- 最终一致性(重试,失败补偿)
- 并发问题
- 并发锁,分布式锁,UK
- 重复请求问题
- 幂等机制: 状态机,唯一主键,Token等
- 接口/信息乱序问题
- 状态机,版本号,时间戳,全局有序队列,延迟处理等
- 流程中断问题
Phase: 预防
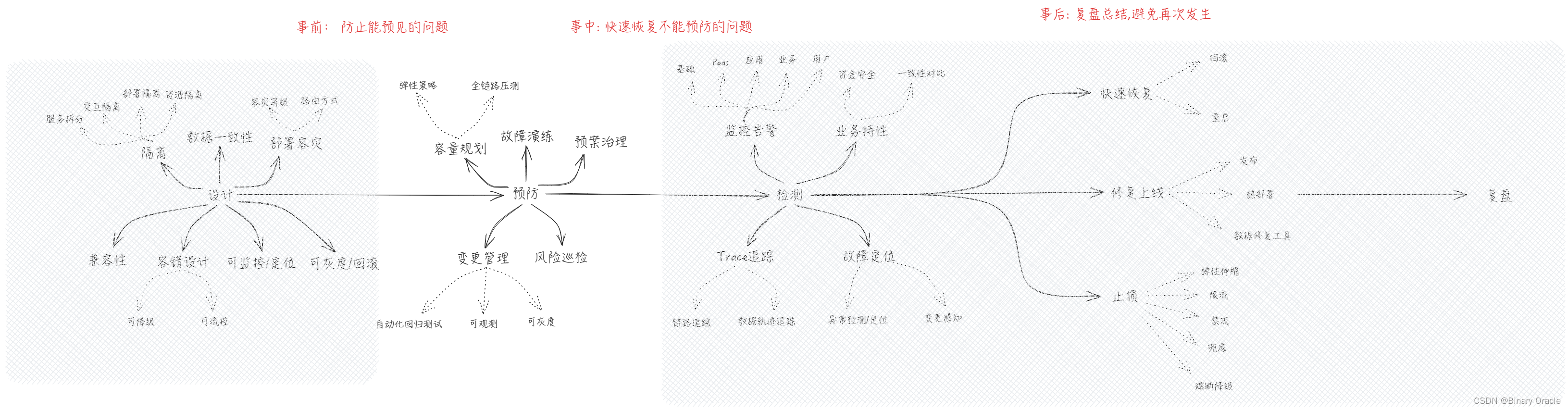
做好容量评估
- 部署容量: 当前部署情况能承载的极限值,也就是当前机器实际能抗的容量值。
- 实施容量: 当前部署实施架构能承载的极限值,可以通过增加机器来扩大承载极限值
- 设计容量: 当前架构扩展性能承载的极限值,可以通过调整部署架构,如分库分表来扩大极限值
- 容量水位: 当前QPS/压测容量 * 100% , 如果超过70%则需要重点关注
- QPS: 每秒处理的请求数量
- 并发量: 系统同时处理的请求数
- 响应时间: 一般取平均响应时间
容量评估就是评估系统在宕机前所能承受的最大流量;常见的容量评估包括流量,带宽,CPU,内存,磁盘等一系列内容,也可以通过一定的技术手段(压测)来检验系统是否达到了预估容量阈值。
做好全链路压测
我们可以通过全链路压测来检验系统容量,同时也可以验证系统瓶颈,验证预先准备方案的有效性等。
全链路压测的目标如下:
- 容量评估: DID原则 - 预估峰值1.5倍容量验证
- Desgin 设计20倍容量
- Implement 实施3倍的容量
- Deploy 部署1.5倍的容量
- 瓶颈发现: 验证单机/链路中的瓶颈,提升性能与容量
- 预案验证: 通过压测流量验证预案的有效性
- 故障演练: 基于压测流量做故障演练
- 预热: 服务启动预热
具体压测过程如下图所示:
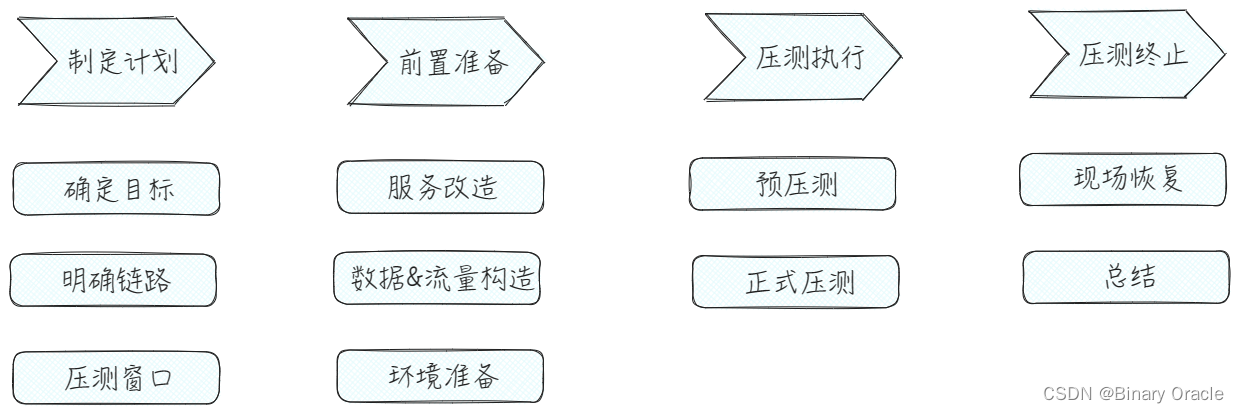
这里重点关注压测安全性和压测结果置信度。
做好故障演练
‘ 混沌工程 ’ 是指在生产环境的分布式系统中进行的一些实验,用来考验系统在动荡的环境下的健壮性,从而增强对系统稳定运行的信心。它的目标是减少业务损失,构建韧性系统。
混沌工程的目标是:
- 减少业务损失,提前暴露风险
- 构建韧性系统,验证系统容错能力
- 增强团队信心,验证预案有效性
类型:
- 围绕系统: 围绕核心链路,基于故障注入进行预案演练,如容灾,限流,强弱依赖验证,降级等
- 围绕人: 运维团队进行红蓝对抗
实践原则:
- 基于稳态行为建立假设-定义业务/系统健康指标
- 模拟多样的真实事件-构建故障测试用例
- 在生产环境试验
- 可持续的自动化试验
- 最小化影响范围-压测流量
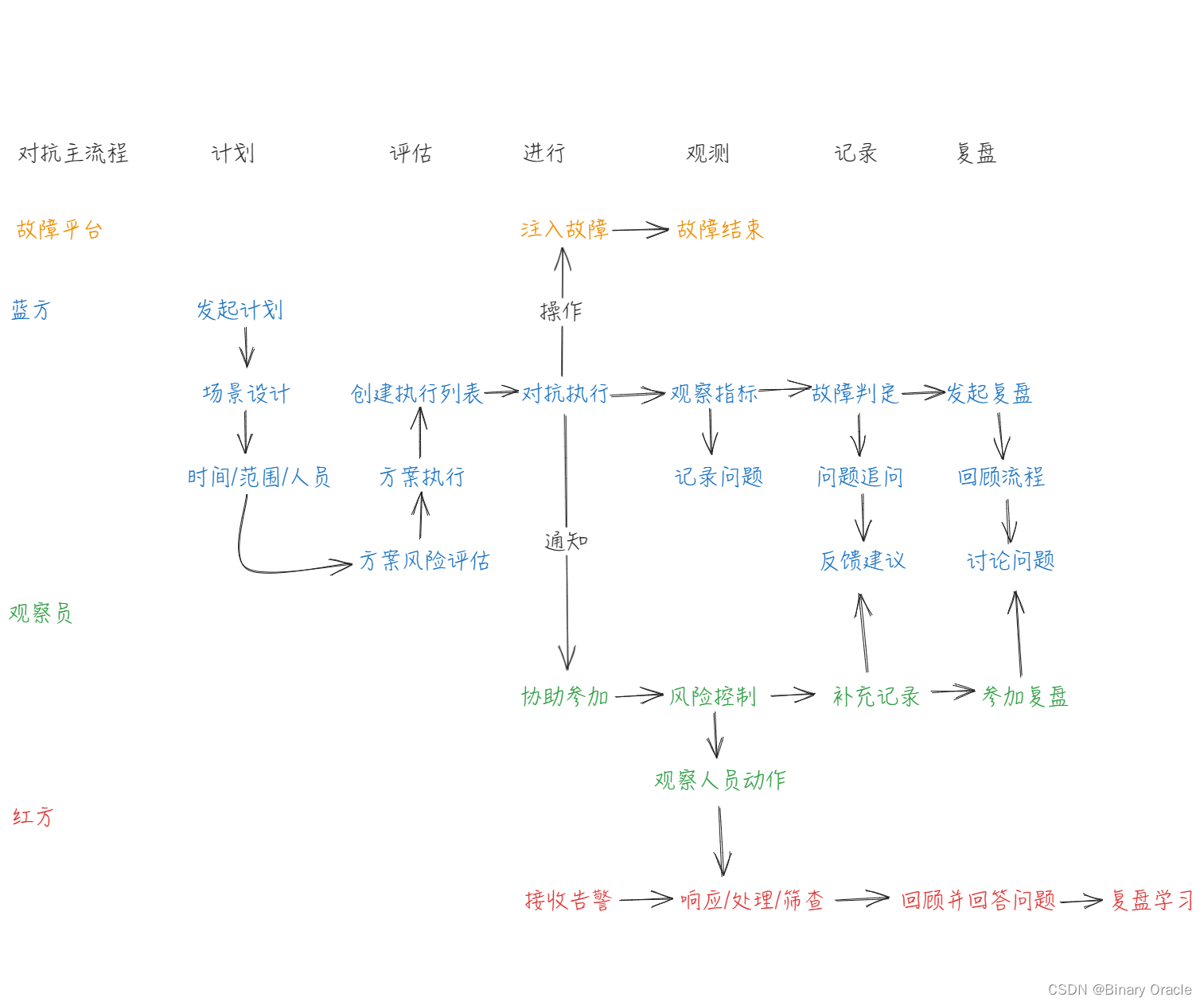
红蓝对抗:
- 红蓝对抗是指网络安全攻防演练,蓝军模拟真实的攻击,评估企业现有防守体系的安全性。红方通过演练可以发现自身更多的安全问题,快说完成查漏补缺。通过红蓝对抗,可以考察研发人员对系统运维的基本功和应急预案。
做好变更管理
系统功能迭代是研发流程中最常见,最容易出问题的环节,因此我们需要重点关注发布前,发布中,发布后三个关键点。通过流程制度规范的指定,让研发对规范操作形成肌肉记忆,减少功能迭代变更过程中可能会出现的低级问题。
功能迭代过程中常见的错误有:
- 测试不充分,上线后出现bug
- 忘记建表,加配置,上线后报错
- 线上运行代码版本不一致
- 上线后没有经过验收
- 不小心把线下配置放到了线上
- 数据高峰期创建索引
- 发布并行度设置不合理
- …
为了避免上面可能出现的错误,我们需要遵循一定的发布流程规范:
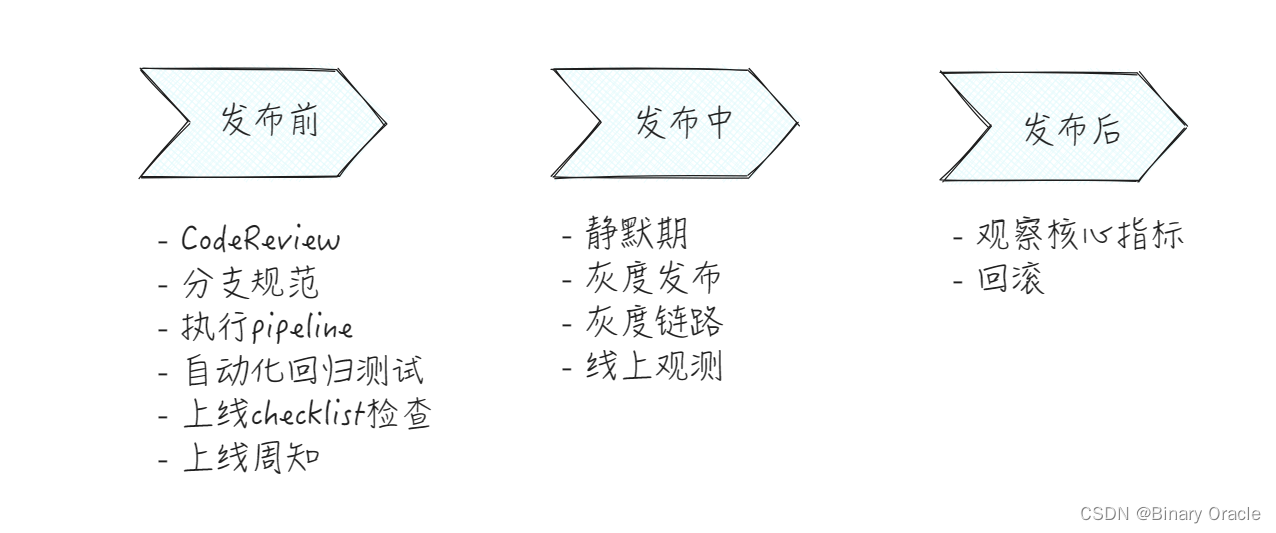
做好风险巡检
增加系统监控并持续关注系统监控告警,可有效降低系统出问题的概率,并能够让系统owner第一时间获取系统健康情况。常见的风险监控指标如:
- 慢查询/大Key
- 性能指标巡检
- 可用性指标巡检
- 超时治理
- 强弱依赖治理
- 熔断治理
- 限流治理
- 告警治理
- 其他业务自定义规则
Phase: 检测
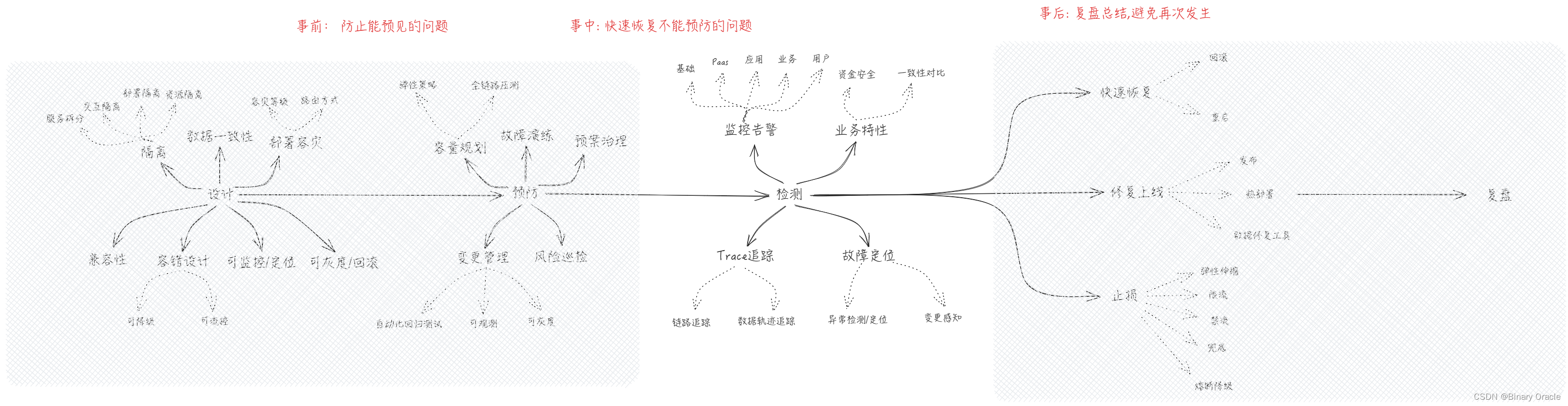
做好指标监测
检测阶段我们需要重点关注以下四个指标:
- 延迟: 服务处理某个请求所需要的时间
- 区分成功和失败请求很重要。例如: 某个由于数据库连接丢失或者其他后端问题造成的500错误可能延迟很低。因此在计算整体延迟时,如果将500回复的延迟也计算在内,可能会产生误导性的结果。
- “慢” 错误要比 “快” 错误更糟糕。
- 流量: 使用系统中的某个高层次的指标针对系统负载需求所进行的度量。
- 对Web服务器来说,该指标通常是指每秒HTTP请求数量,同时可能按请求类型分类(静态请求与动态请求)
- 针对音频流媒体系统来说,指标可能是网络IO速率,或者并发会话数量
- 针对键值对存储系统来说,指标可能是每秒交易数量,或每秒读写操作数量
- 错误: 请求失败的速率
- 显示失败: HTTP 500
- 隐式失败: HTTP 200 回复中包含了错误内容
- 策略原因导致的失败: 如果要求回复在1秒内发出,那么任何超过1s的请求都是失败请求
- 饱和度: 服务容量有多 ‘满’ ,通常是系统中目前最为受限的某种资源的某个具体指标的度量 ,在内存受限的系统中,即为内存;在I/O受限的系统中,即为I/O;
- 很多系统在达到 100% 利用率之前性能会严重下降,因此可以考虑增加一个利用率目标。
- 延迟增加是饱和度的前导现象,99%的请求延迟(在某一小的时间范围内,例如一分钟) 可以作为一个饱和度早期预警的指标。
- 饱和度需求进行预测,例如: 数据库可能会在4小时内填满硬盘。
如果已经成功度量了这四个指标,且在某个指标出现故障时(或者快要发生故障) 能够发出告警,那么从服务的监控层面来说,基本也就满足了初步的监控诉求。
做好 Logging ,Metrics & Tracing
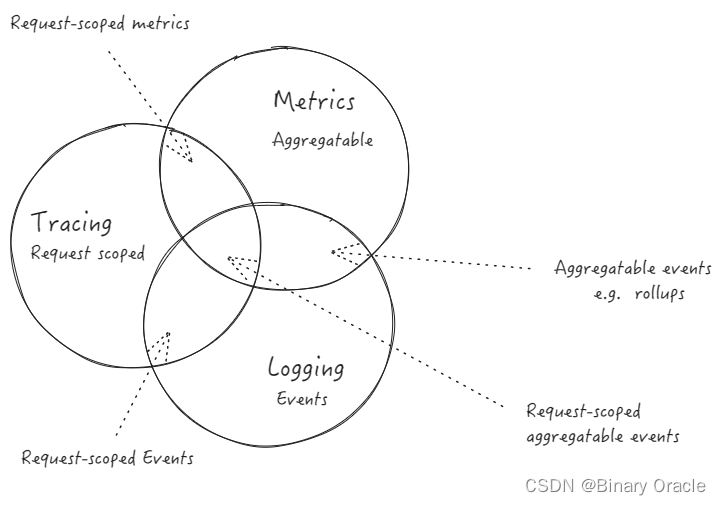
Logging : 用于记录离散的事件
- 包含程序执行到某一点或某一阶段的详细信息
Metrics : 可聚合的数据,且通常是固定类型的时序数据
- 包括Counter,Gauge,Histogram 等
Tracing : 记录单个请求的处理流程
- 其中包括服务调用和处理时长等信息
Logging & Metrics :可聚合事件
- 例如分析某服务的异常日志,统计某段时间内某类型异常的数量
Metrics & Tracing : 单个请求中的可计量数据
- 例如SQL执行总时长,RPC调用中次数
Tracing & Logging : 请求阶段的标签数据
- 例如在Tracing的信息中标记详细的错误原因
做好监控告警
目标:
- 提前发现问题
- 快速定位现象级问题
- 宏观问题
- 表象问题
关键点:
- 全面性 :监控项覆盖全面
- 有效性 : 告警等级与阈值
- 实时性 : 重要告警要马上出来
- 区分度 : 告警内容要有区分度
| 视角 | 指标 | 实践建议 |
|---|---|---|
| 用户监控 | 5xx,4xx,客户端监控等 | 从用户体验角度出发监控 |
| 业务监控 | 成功率,成功量,失败原因分析,RT值,一致率等 | 核心业务活动,业务流程节点 |
| 应用监控 | 健康检查/异常日志/jvm监控/qps/慢查询/下游依赖等 | 统一模版,通过治理告警优先级和数量避免告警泛滥 |
| Pass监控 | DB/Redis/kafka/MongoDB 等 | 检查为主 |
| 基础监控 | CPU/磁盘/负载/内存/网络/网卡等 | 默认 |
关注告警数量和告警等级,告警响应率,高危告警,高频告警,新增异常等。
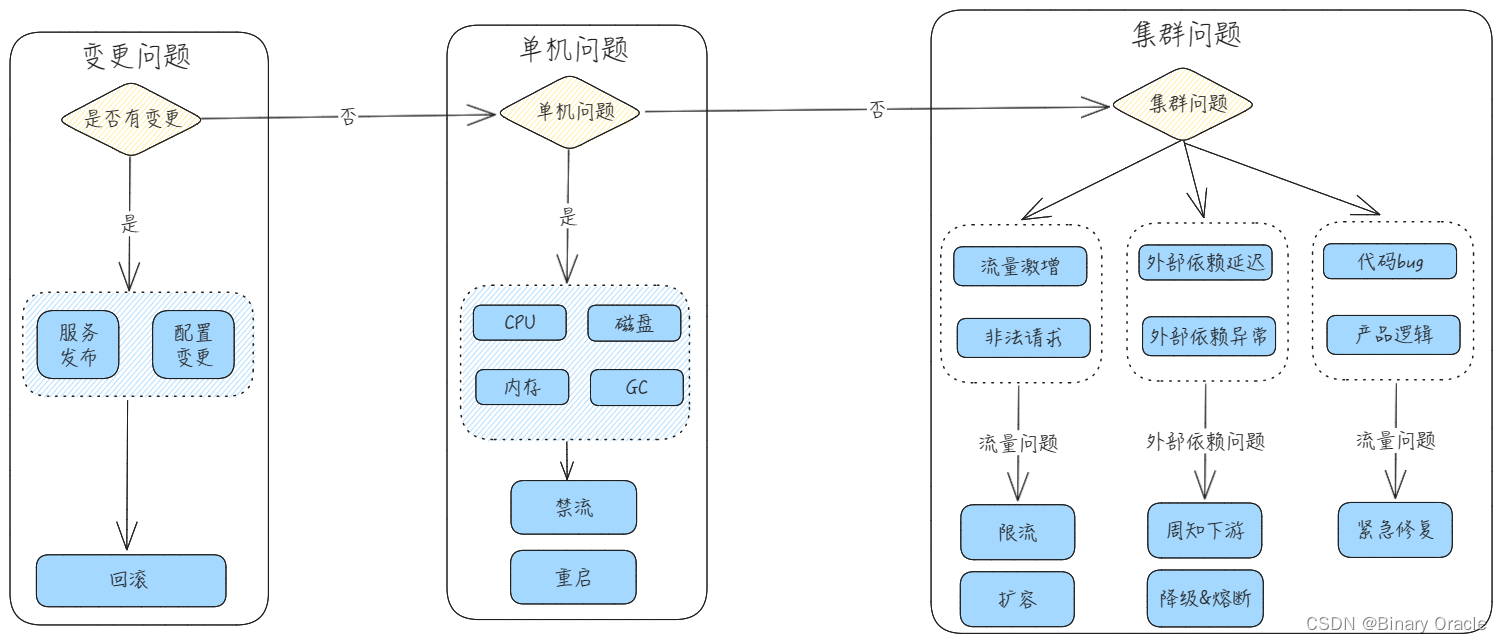
做好定位排查
常见问题:
- 上下游大范围告警无法定位根因
- 业务链路太长,出现bug排查效率低下
常见解决问题的手段有:
- 根因定位
- 链路能力: trace id
- 数据轨迹跟踪: 订单生命周期跟踪
- 数据聚合分析: 小渠道/业务线聚合分析
- 业务自定义日志: 日志规范
Phase: 处理
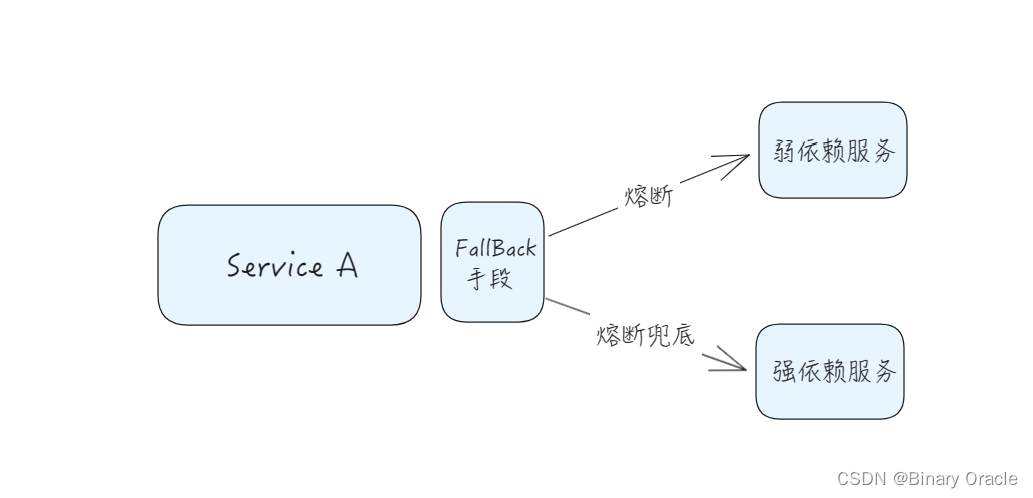
做好熔断 & 降级 & 兜底
场景:

导致以上问题出现的本质原因还是 服务容错能力的缺失!
常见解决方案有:
- 强弱依赖梳理
- 熔断降级: 弱依赖接入熔断降级
- 降级开关: 通过开关控制部分流程的执行
- 兜底策略: 强依赖服务可接入兜底策略
做好限流
限流是比较常见的处理突发流量,保护服务的手段;通过对请求数,并发数,用户操作等进行限制,从而实现服务保护措施。
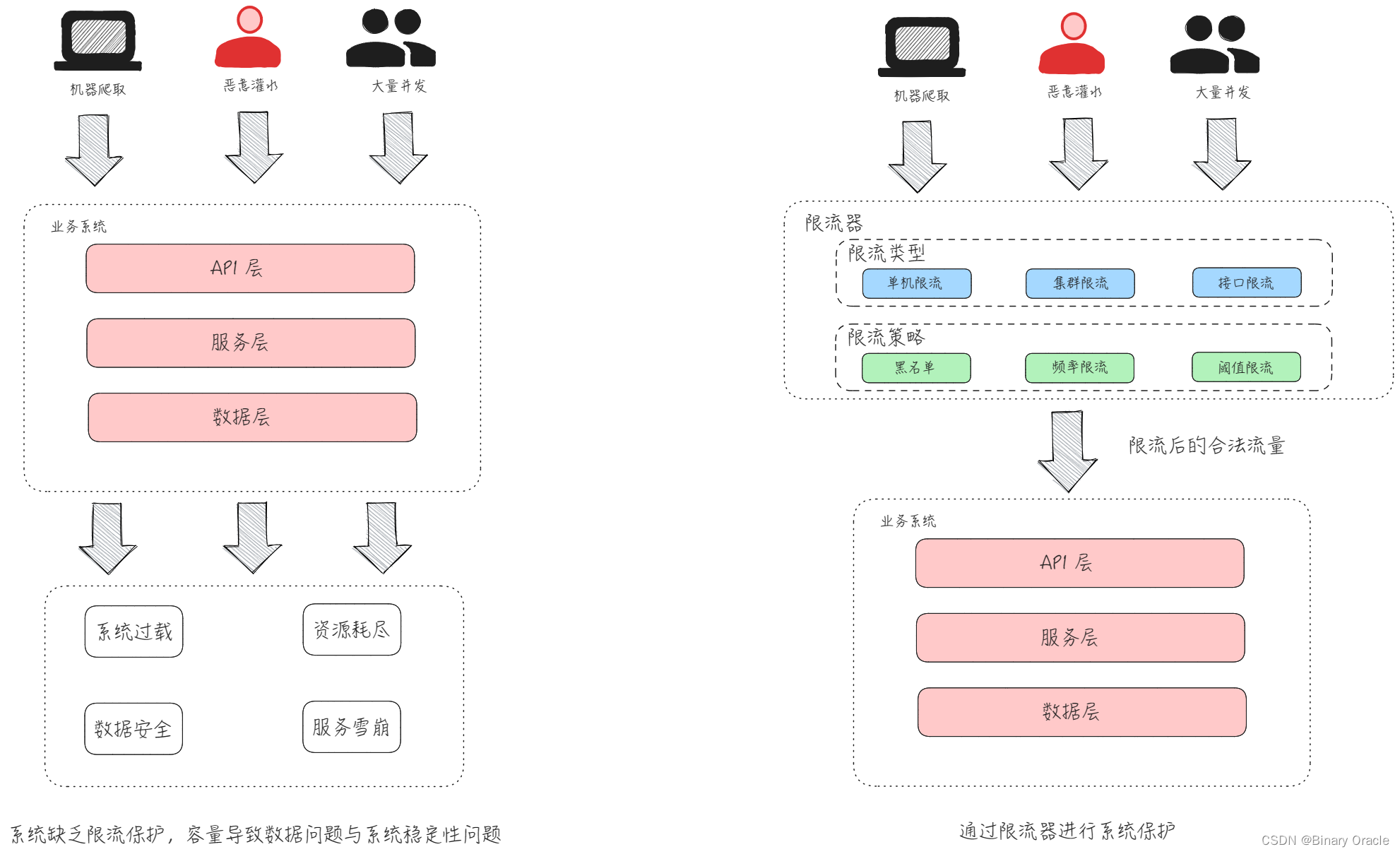
关于限流处理,我们需要注意下面四个方面:
- 哪些服务或接口需求配置限流 ?
- 入口级,平台级,消息队列/定时任务驱动服务
- 限流器如何选择 ?
- 单机限流保护服务器自身,集群限流保护下游/DB
- 限流阈值如何设定 ?
- 部署容量值,基于DB等理论瓶颈值,需要持续维护
- 限流预案原则 ?
- 优先限制非核心接口以及低业务价值的流量,建议通过配置接口进行一键预案
线上故障处理流程
先定位,再通告,即时止损,然后分析根因,最后详细排查。
Phase: 复盘
由管理者指定复盘制度,包括故障定级标准,复盘文档模版,复盘时机,复盘后续待办等。
总结
要构建高可用系统,我们需要遵循"六要两不要"原则:
- 六要:
- 要测试 : 禁止未经测试直接发布
- 要周知: 禁止线上变更不发周知
- 要审核: 禁止未经审批直接修改线上数据和配置
- 要灰度: 禁止未经灰度直接全量发布
- 要观测: 禁止变更上线后不看监控和日志
- 要可回滚: 禁止没有回滚方案的变更直接上线
- 两不要
- 不要瞒报故障
- 不要违规变更数据: 禁止在正式环境进行数据变更操作,如洗数据,修数据等
在研发过程中要遵循五段式分析法:
- 事前: 思考当前业务背景下,是否存在潜在风险问题,若存在风险,如何进行风险规避或风险减缓
- 事中: 思考如何检测与处理风险故障
- 事后: 思考如何让出现的问题不再重复发生
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!