从根上理解elasticsearch(lucene)查询原理(2)-lucene常见查询类型原理分析
大家好,我是蓝胖子,在上一节我提到要想彻底搞懂elasticsearch 慢查询的原因,必须搞懂lucene的查询原理,所以在上一节我分析了lucene查询的整体流程,除此以外,还必须要搞懂各种查询类型内部是如何工作,比如比较复杂的查询是将一个大查询分解成了小查询,然后通过对小查询的结果进行合并得到最终结果。
今天就来看看几种比较常见的查询其内部的工作原理。
BooleanQuery 查询分析
首先来看下布尔查询,拿下面这段代码举例,我用lucene写了一个布尔查询的例子,布尔查询由两个term查询组成,其中一个term是用must,一个term用的是should。
BooleanQuery.Builder query = new BooleanQuery.Builder();
query.add(new TermQuery(new Term(field1, "w3")), BooleanClause.Occur.MUST);
query.add(new TermQuery(new Term(field2, "xx")), BooleanClause.Occur.SHOULD);
int[] expDocNrs = {2, 3, 1, 0};
queriesTest(query.build(), expDocNrs);
布尔查询会将两个term查询的倒排链进行合并,得到最终结果。上一节有提到,计分逻辑是通过bulkScore.score方法实现的。在bulkScore.score方法内部 ,需要先遍历筛选出符合条件的文档,然后对该文档进行计分,无论是筛选出符合条件的文档,还是对文档计分,都与weight对象创建的scorer对象有关,遍历用到的是DocIdSetIterator,计分用到的是score() 方法,scorer涉及到的方法如下,

其中计分方法score是在scorer抽象类又继承的一个Scorable 抽象类中,如下所示
public abstract class Scorer extends Scorable {
...
}
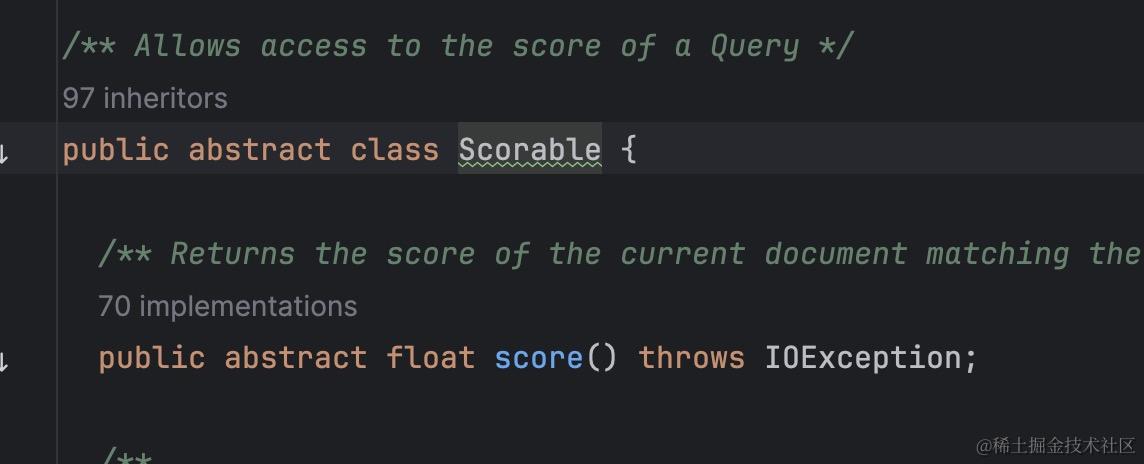
在遍历倒排列表取出文档id时,会调用DocIdSetIterator 的nextDoc 方法取出当前文档id,并将便利指针移动到倒排列表的下一个文档id处。
但是布尔查询往往是多个条件的组合查询,它不可能是只遍历一个倒排链表,所以布尔查询的实现中,针对查询条件生成了特殊的scorer对象,比如ConjunctionScorer 交集scorer,它会将查询条件组合起来,并且利用子查询的DocIdSetIterator 构造新的DocIdSetIterator 用于遍历筛选出符合条件的文档id。ConjunctionScorer 的nextDoc方法就相当于是在执行多个倒排链表合并的过程。
关于倒排链表的合并过程就不在这篇文档继续展开了。除此以外,布尔查询构建的scorer对象还有 并集DisjunctionSumScorer,差集ReqExclScorer,ReqOptSumScorer。它们的nextDoc方法也都是在做遍历倒排链表取出文档id的操作,不过遍历合并倒排链表的逻辑各有不同。
所以,如果你的布尔查询命中结果比较多,并且需要计分的话, 会导致在进行倒排链表合并操作时花费比较长的时间。比如我之前碰到的一个慢查询,经过profile的分析如下,布尔查询在next_doc操作上耗时比较长,next_doc对于布尔查询而言是在进行倒排链表的合并。
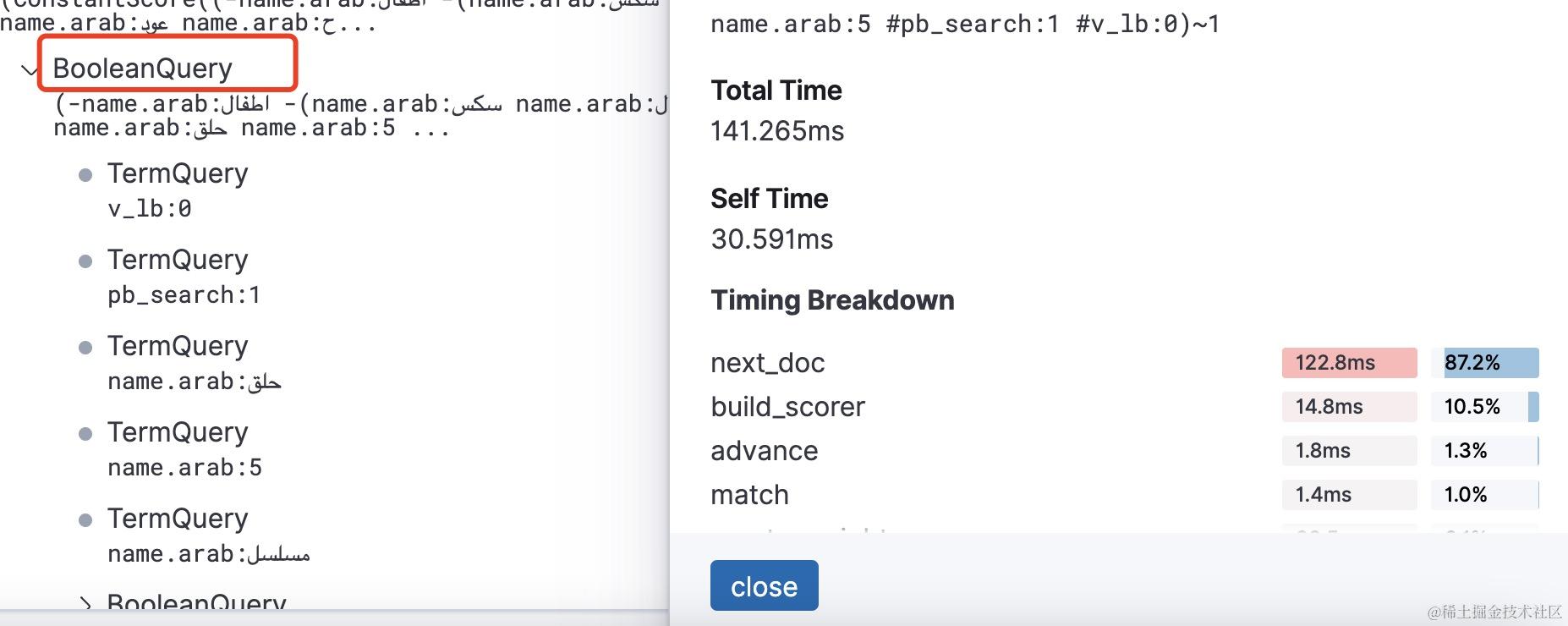
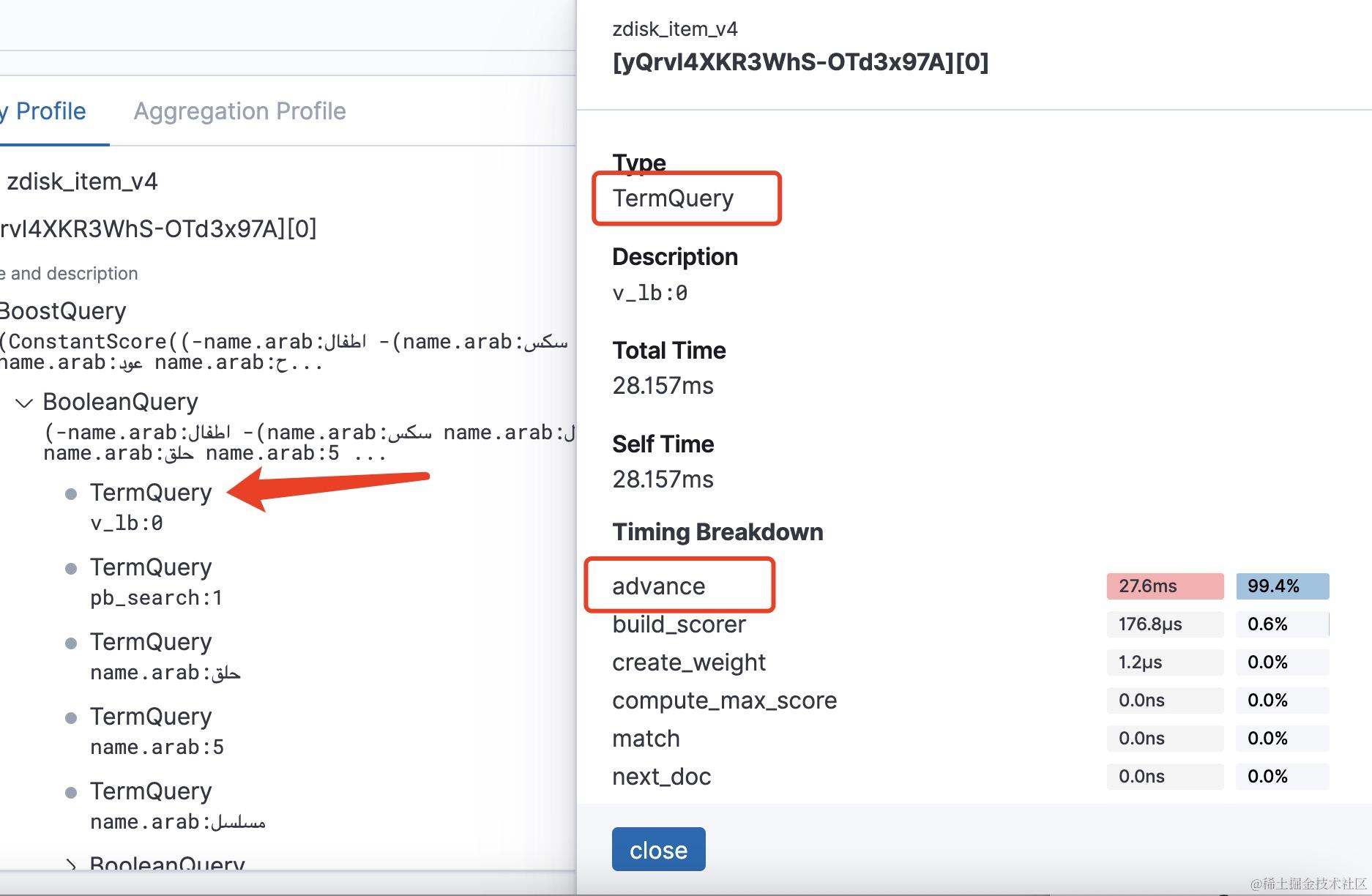
而对于布尔查询的子查询term查询你会发现耗时基本是花在了advance操作上。因为倒排列表合并过程中会有很多移动遍历指针的操作也就是advance操作,所以在倒排列表比较长时,要想完整遍历合并多个倒排列表则会有很多advance操作。
MultiTermQuery 查询分析
接着看另外一个常见的查询类型MultiTermQuery,它的查询重写分好几种类型,具体的重写类型区别可以查看官方文 https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-multi-term-rewrite.html
这里我拿其中一种 CONSTANT_SCORE_BLENDED_REWRITE 举例,这也是在复杂查询例如
默认使用的重写类型。
wildcardQuery这些模糊匹配,正则匹配差询首先是构建自动状态机,然后默认会将查询重写成为了CONSTANT_SCORE_BLENDED_REWRITE类型的MultiTermQuery查询。
之后在创建weight的scorer对象时,会将词典term dictionary中的term与自动状态机做匹配,选出符合条件的term,根据term的个数判断是将查询重写为布尔查询还是直接构建bitset用于后续计分时进行迭代遍历。
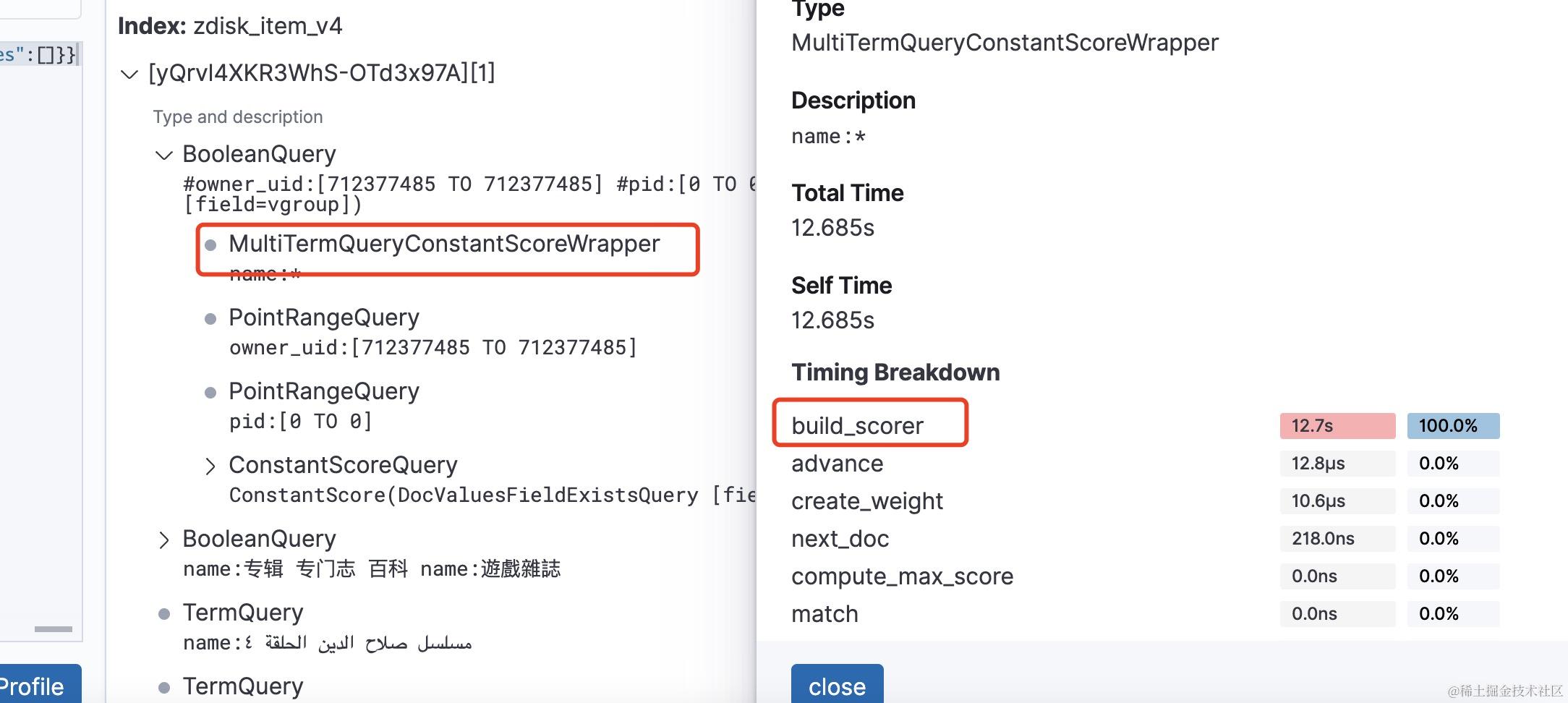
符合条件的term 大于16个,则会进行bitset的构建,构建过程则是将符合条件的term对应的倒排列表取出来加到一个bitset中。这个过程是比较耗时的,特别是term对应的倒排列表过大或者term数量过多时,耗时会非常长。注意这个构建过程是发生在scoer对象创建的时候,即build_scorer阶段。拿我之前遇到的一个慢查询举例,这是一个匹配到的term数量比较多的wildcardQuery,
下面是执行的DSL语句,
{"size":1000,"query":{"bool":{"filter":[{"term":{"owner_uid":{"value":712377485,"boost":1.0}}},{"term":{"pid":{"value":0,"boost":1.0}}},{"wildcard":{"name":{"wildcard":"*","boost":1.0}}},{"exists":{"field":"vgroup","boost":1.0}}],"adjust_pure_negative":true,"boost":1.0}},"_source":{"includes":["name"],"excludes":[]}}
经过profile分析可以看到wildcardQuery已经被重写为了MultiTermQueryConstantScoreWrapper,耗时过长最大的阶段则是在build_scorer阶段,对每个阶段不太熟悉的话可以翻看我前一篇文章 https://mp.weixin.qq.com/s/Drhs6lKPYy8vDHa2RouiyA
注意像wildcardQuery,前缀匹配这些查询都会构建自动状态机,构建自动状态机的过程在匹配规则文本比较长时,非常消耗cpu,生产上注意限制匹配规则文本长度,并且构建自动状态机花费的时长不会体现在profile输出结果中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!