python_selenium_安装&基础学习
目录
1.为什么使用selenium
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
2.安装selenium
Selenium Python 教程 - 知乎 (zhihu.com)
我是根据这个博主的文章学习下载安装的。
因为一直用的是Edge的浏览器,所以在后面就遇到了很多问题。
忙活半小时终于成功了。报了各种错误。现在终于弄好了。
第一次报误:
ValueError: Timeout value connect was <object object at 0x000001DF6F6800B0>, but it must be an int, float or None.
第二次报错:
AttributeError: 'str' object has no attribute 'capabilities'
第三次报错:
DeprecationWarning: executable_path has been deprecated, please pass in a Service object
最后协调了各个版本:
2.1Chrome浏览器
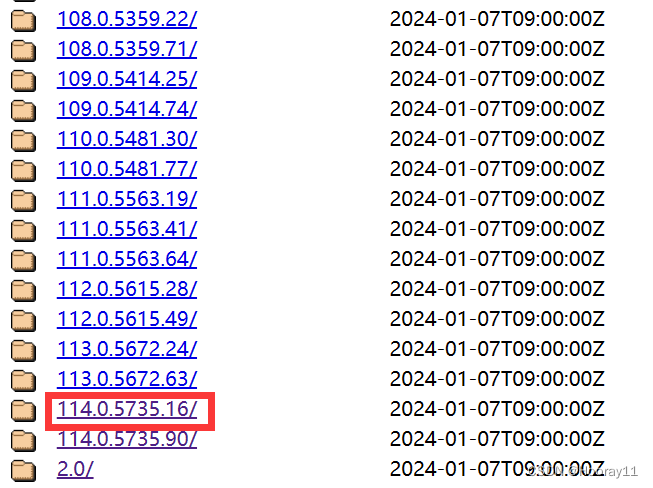
Chrome浏览器版本,一开始下的120最新版,结果发现下载最新版本的驱动网站进不去,然后就去下载之前的老版本
这里可以分享一个安装包,自行下载。链接:https://pan.baidu.com/s/19kURAxzB5Nib0eyOOU0jew?pwd=1234?
提取码:1234

2.2驱动
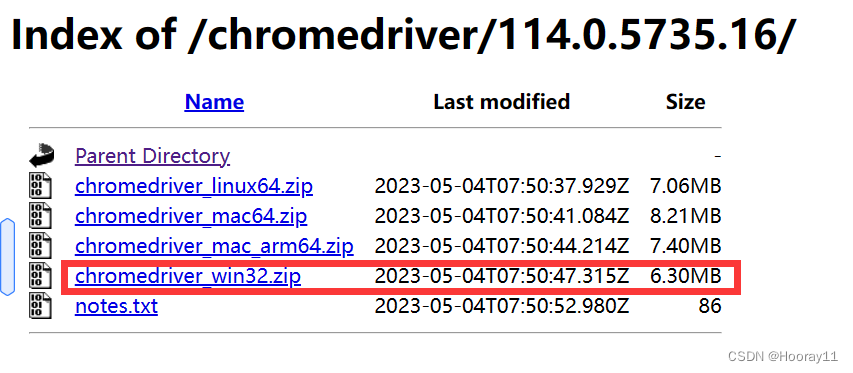
驱动就可以直接进这个网站下载。CNPM Binaries Mirror (npmmirror.com)
然后选择适合自己电脑的版本就可以啦。
下载完驱动后我是直接将驱动解压缩后放在我日常编写程序的目录下的。不知道这个有啥讲究没。
或者看网上其他大佬们去修改了环境变量。Selenium安装WebDriver最新Chrome驱动(含116/117/118/119)_chromedriver 119-CSDN博客
2.3下载selenium
我下载的是4.5.0版本的,太高的版本就会报错,我也不知道什么原因
![]()
2.4测试连接
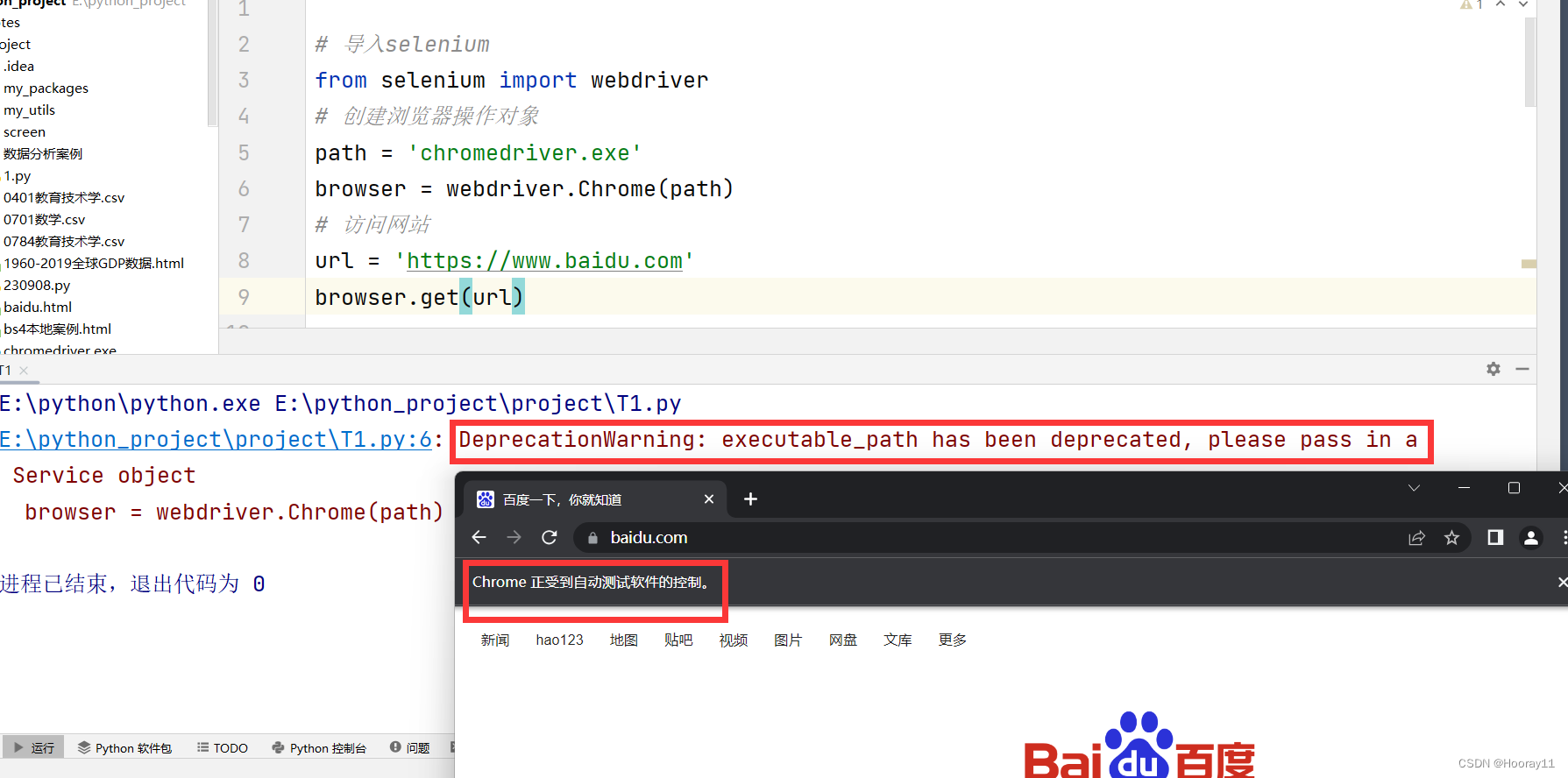
代码一:
# 导入selenium
from selenium import webdriver
# 创建浏览器操作对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# 访问网站
url = 'https://www.baidu.com'
browser.get(url)这个运行后,浏览器倒是有反应,但还是报错呜呜呜呜呜
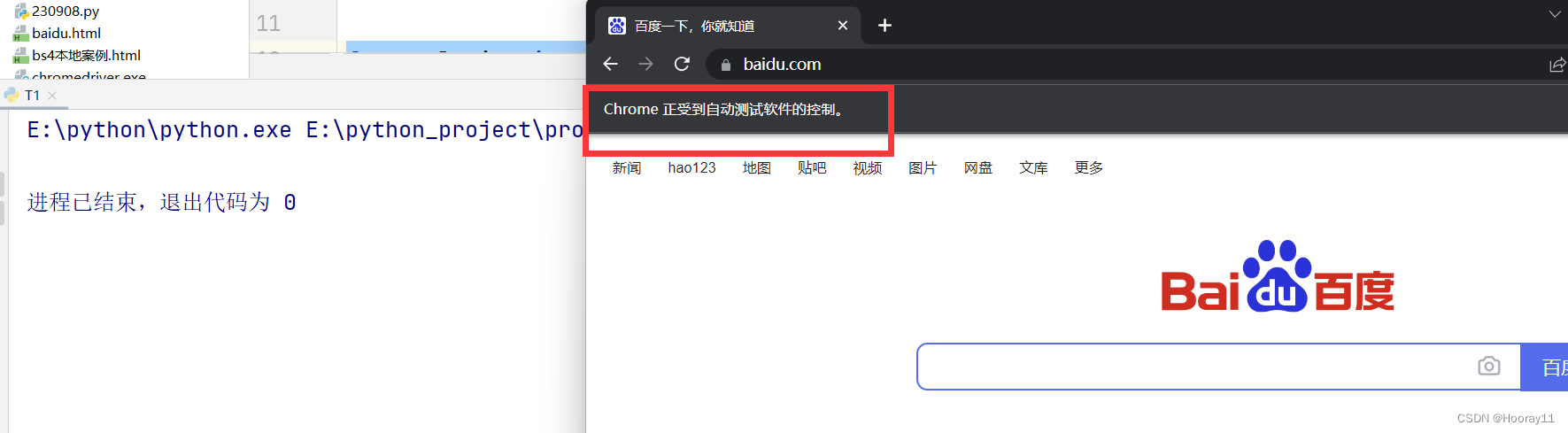
代码二:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
driver = webdriver.Chrome(service=s)
url = 'https://www.baidu.com/'
driver.get(url)那这个就是完全没有问题的。解决方法参考了这个大佬的文章。
3.selenium元素定位
现在的用法变了,跟着网上做的报错了。
现在变成这种传参的了。
并且还要再导入一个库
from selenium.webdriver.common.by import By
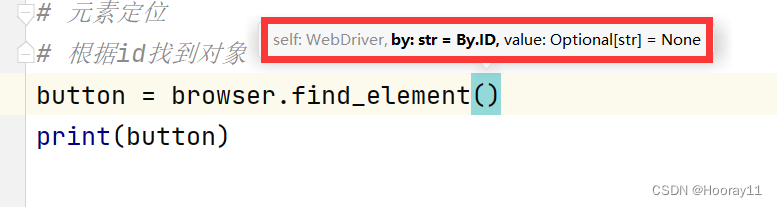
3.1根据id来找到对象

button = browser.find_element(by=By.ID,value='su')
print(button)
3.2根据标签属性的属性值来获取对象
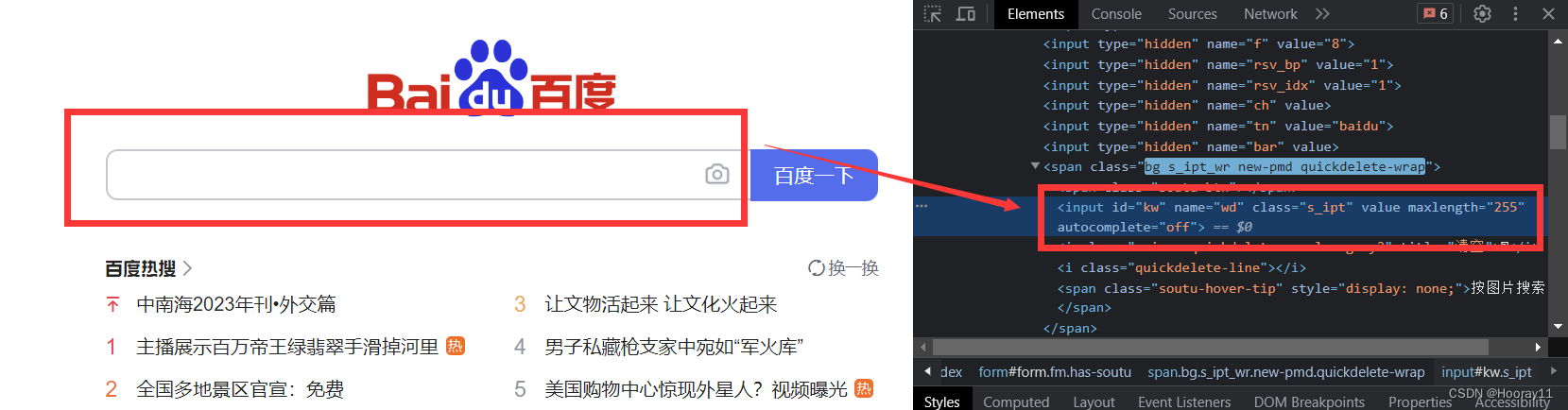
button = browser.find_element(By.NAME,value='wd')
print(button)
3.3根据xpath语句来获取对象
button = browser.find_element(by='xpath',value='//input[@id="su"]')
print(button)
3.4根据标签的名字获取对象
button = browser.find_element(by=By.TAG_NAME,value='input')
print(button)
3.5使用bs4的语法来获取对象
button = browser.find_element(by=By.CSS_SELECTOR,value='#su')
print(button)
3.6使用a标签来获取对象

button = browser.find_element(by=By.LINK_TEXT,value='新闻')
print(button)
3.7所有代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://www.baidu.com/'
browser.get(url)
# 元素定位
# 根据id找到对象
# button = browser.find_element(by=By.ID,value='su')
# print(button)
# 根据标签属性的属性值来获取对象
# button = browser.find_element(By.NAME,value='wd')
# print(button)
# 根据xpath语句来获取对象
# button = browser.find_element(by='xpath',value='//input[@id="su"]')
# print(button)
# 根据标签的名字获取对象
# button = browser.find_element(by=By.TAG_NAME,value='input')
# print(button)
# 使用bs4的语法来获取对象
# button = browser.find_element(by=By.CSS_SELECTOR,value='#su')
# print(button)
# 使用a标签来获取对象
button = browser.find_element(by=By.LINK_TEXT,value='新闻')
print(button)4.selenium元素信息
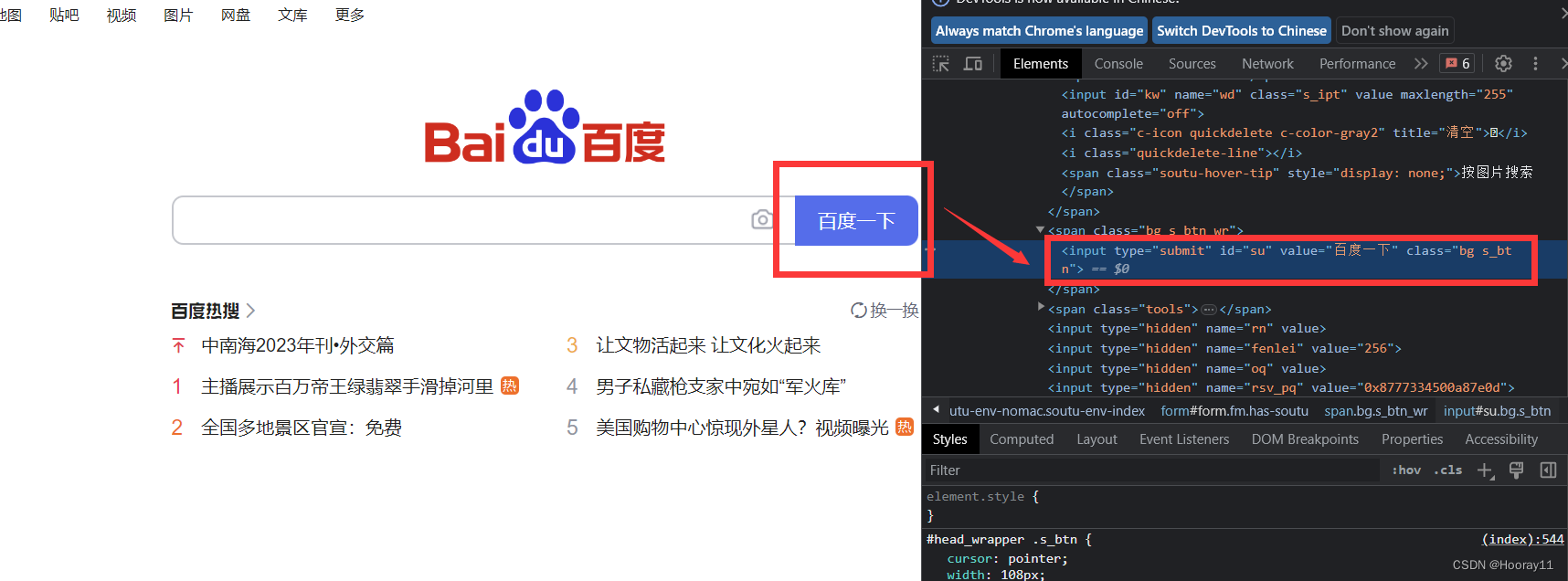
# 获取元素信息
input = browser.find_element(by=By.ID,value='su')
# 获取元素类属性
print(input.get_attribute('class'))
# 获取元素标签属性
print(input.tag_name)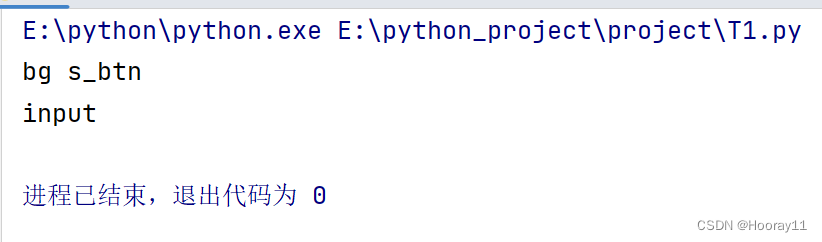
?什么叫做获取文本信息?
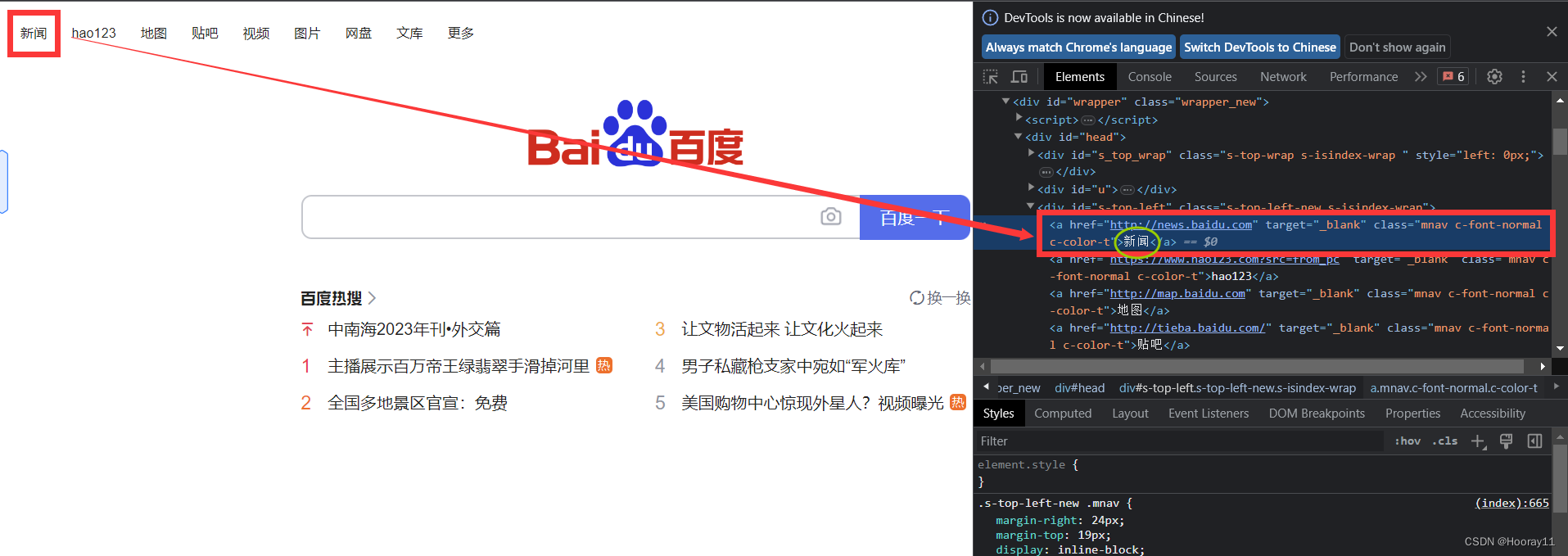
button = browser.find_element(by=By.LINK_TEXT,value='新闻')
print(button.text)
5.seleniu的交互
js_button = 'document.documentElement.scrollTop=100000'
button.execute_script(js_button)在网上跟着别人用的这个代码,就给报错了哈哈哈哈哈
AttributeError: 'WebElement' object has no attribute 'execute_script'
然后根据这篇文章改了一下。python学习之滚动页面函数execute_script-CSDN博客
js = 'window.scrollTo(0,document.body.scrollHeight)'
browser.execute_script(js)成功了!!!
最终代码就是这样了
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 尝试传参
path = 'chromedriver.exe'
s = Service(path)
browser = webdriver.Chrome(service=s)
url = 'https://www.baidu.com/'
browser.get(url)
import time
time.sleep(2)
# 获取文本框对象
input = browser.find_element(by=By.ID,value='kw')
# 在文本框输入周杰伦
input.send_keys('周杰伦')
time.sleep(2)
# 获取百度一下的按钮
button = browser.find_element(by=By.ID,value='su')
# 点击按钮
button.click()
time.sleep(2)
# 滑倒底部
js = 'window.scrollTo(0,document.body.scrollHeight)'
browser.execute_script(js)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element(by='xpath',value='//a[@class="n"]')
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
browser.back()
time.sleep(2)
# 回去
browser.forward()
time.sleep(3)
# 退出浏览器
browser.quit()
6.收藏一个大佬的分享
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!